「〇〇で歌ってみたシリーズ」の動画が好きなので、ふと、YouTube上での「〇〇で歌ってみたシリーズ」の人気動画の情報を収集してみたくなりました。
具体的な用途が浮かんでいるわけではないのですが、例えばどんな替え歌が多くの人に面白がられているのか、など色々解析してみると楽しそうだなと思いました。
そこで今回、PythonとYouTube Data API (v3)を使って、「〇〇で歌ってみたシリーズ」の動画情報を取得してみました。
正直、動画情報を収集するという点では、参考にさせていただいたサイト様に対する新規性は特にないのですが(せいぜい最後の出力情報の違いくらい)、初めてYouTube Data APIを使ってみたので、その覚書も兼ねて書いてみようと思います。
参考サイト
- Youtube Data APIを使ってPythonでYoutubeデータを取得する
- YouTube Data api v3をPythonから使って動画の閲覧数をごそっと取得する
- YouTube Data API
環境
Google Colaboratoryで動くことを確認しています(2020年2月23日時点)
下準備
YouTube Data API (v3)のAPIキーを取得します。手順は参考サイトなどにもあるので、こちらでは省略いたします。APIキーの制限は特にかけていません。
コード
指定したqueryによる検索結果に含まれる動画情報を取得して標準出力しています。
コードでは例として野球選手系の情報を収集しています。
from apiclient.discovery import build # pip install google-api-python-client
import datetime
YOUTUBE_API_KEY = '<APIキーを記入>'
query = '野球選手名で歌ってみた'
max_pages = 16 #取得するページ数
maxResults = 50 #1ページあたりに含める検索結果数。maxは50
# 動画情報を取得する関数
def search_videos(query, max_pages=10,maxResults=50):
youtube = build('youtube', 'v3', developerKey = YOUTUBE_API_KEY)
search_request = youtube.search().list(
part='id',
q=query,
type='video',
maxResults=maxResults,
)
i = 0
while search_request and i < max_pages:
search_response = search_request.execute()
video_ids = [item['id']['videoId'] for item in search_response['items']]
videos_response = youtube.videos().list(
part='snippet,statistics',
id=','.join(video_ids)
).execute()
yield videos_response['items']
search_request = youtube.search().list_next(search_request, search_response)
i += 1
# 取得した動画情報から欲しい情報を取り出してリストに入れる
# 今回はID、URL、投稿日時、投稿者のチャンネルID、動画タイトル、視聴回数、高評価数、低評価数、お気に入り回数を取得、またプログラム実行時刻も追加している
for items_per_page in search_videos(query, max_pages, maxResults):
for item in items_per_page:
obj = {}
obj['id'] = item['id']
obj['url'] = 'http://youtube.com/watch?v='+obj['id']
snippet = item['snippet']
for key in ['publishedAt','channelId','title']:
obj[key] = snippet[key]
statistics = item['statistics']
for key in ['viewCount','likeCount','dislikeCount','favoriteCount','commentCount']:
obj[key] = statistics[key] if key in statistics else "NA"
obj['timestamp'] = datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')
print(",".join(['"'+obj[v]+'"' for v in obj]))
今回はID、URL、投稿日時、投稿者のチャンネルID、動画タイトル、視聴回数、高評価数、低評価数、お気に入り回数、コメント数を取得しました。
「お気に入り回数」は何なのかよくわかっていません。データに含まれていたので念の為取得しましたが、全部0でした。
最終的な出力は標準出力(print)にして、そのままGoogleSpreadSheetにコピペしました。貼り付けたのが以下のような感じです
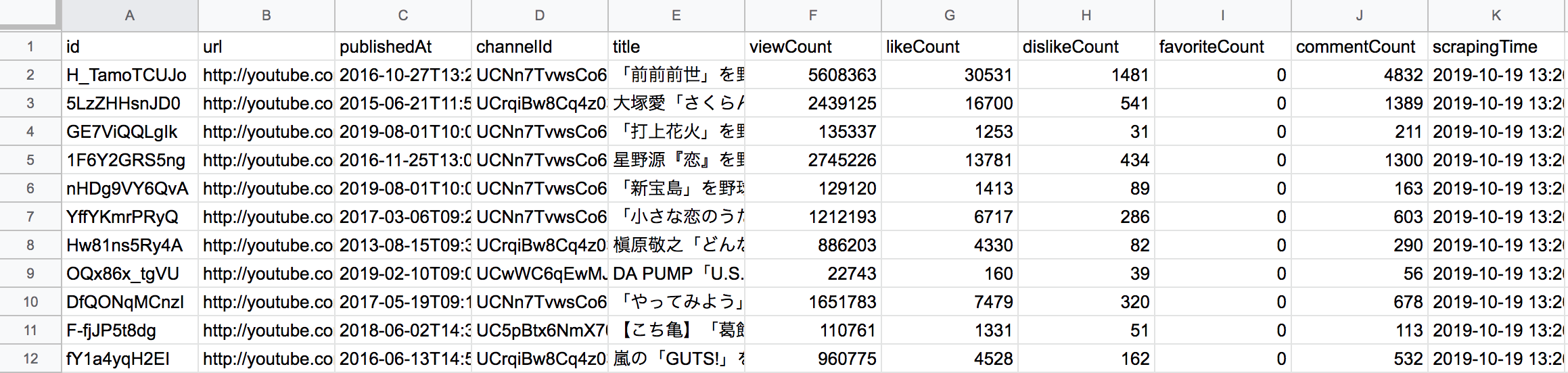
なお結果を目視したところ、ただの野球中継の動画や関係ない歌ってみたシリーズなどノイズが混じっていたようなので、それについては手動で除く必要があります。
またより網羅的に取得したい場合は「やきゅうた」など別の検索ワードでもプログラムを実行して、動画IDがそれまでの取得結果とかぶってないものだけ追加するとよさそうです。
コーディングに関しては以上です。
今後は替え歌歌詞に使われている単語などを書き起こして、どのような替え歌が人気になりやすいのかを解析すると面白いかなあなどと考えています(書き起こしの労力がかかりすぎるので早々実現はしなさそうですが)