はじめに
paiza1 の新作プログラミングゲーム「電脳少女プログラミング2088 ─壊レタ君を再構築─」を題材に、Rust と SQL の基本的な用語や使い方を解説します。
このゲーム2は、「プログラミング問題」と「データベース問題」を解きながらストーリーを進めていく形式で、プログラミング初心者でも楽しく学ぶことができます。
新しく言語を学ぶときに最初のハードル になるのが『環境構築』ですが、paiza では環境構築が不要で、ブラウザ上で実行できるため、手軽にプログラミング言語やデータベース言語を学ぶことができます。
対象読者
- 他のプログラミング言語の経験がある方を対象としています。
-
SQLは経験がなくても問題ありません。
本記事の構成
- 本記事は、大きく以下の 2 つのセクションで構成されています。
- プログラミング問題
- データベース問題
- 各セクションの冒頭で「前提知識」を解説し、その後、問題に取り組みます。
- 各問題は、以下の 3 つのステップで進めます。
- 必要な知識:問題を解くために必要な概念を解説
- 問題:実際の問題を提示
- 解答:正解例と詳しい解説
説明が長くなりましたので、全体の見やすさを考慮し、一部を折りたたんで表示しています。
プログラミング問題
プログラミング問題は全 10 問で、Python や Go などの 28 言語に対応しています。今回は近年注目を集める Rust を使用します。
前提知識
プログラミング問題を解くには以下の 3 つの要素が重要になります。
-
アルゴリズムとデータ構造
- 効率的に問題と解くために必要
-
プログラミング言語の基礎
- アルゴリズムを実装するために必要
-
標準入出力
- 入力値の受け取りと解答の出力のために必要
以下では前提知識としてこれらを解説していきます。
アルゴリズムとデータ構造
著名な計算機科学者であるニクラウス・ヴィルト氏の著書『Algorithms + Data Structures = Programs』のタイトルが示すように、プログラムを作成する上でアルゴリズムとデータ構造は不可欠な要素です。
データ構造とは
『データ構造』は、データを一定の規則に基づいて整理し、特定の操作を効率的に実行できるよう設計された構造です。例えば、『配列』ではデータを連続して並べることで高速なアクセスを実現しています。
アルゴリズムとは
一方、『アルゴリズム』とは、並べ替えや探索などの特定の目的を達成するための処理手順を指します。多くのアルゴリズムは、最適な性能を引き出すために特定のデータ構造と組み合わせて設計されています。
プログラミング問題はある程度パターンがあるため、 問題文中に特定のキーワード (例: 最短経路、最大値) を手がかりに適切なアルゴリズムとデータ構造を選択することができます。
Rust の基礎
Rust は学習難易度の高い言語とされています。その大きな要因のひとつが Rust 独自の概念である『所有権』です。所有権を正しく理解するためには、『メモリ管理』の仕組みについて理解が重要です。
メモリ管理
通常、メモリの管理は OS とアプリケーションで役割を分担して実現しています。
『物理的なメモリ』の管理は OS が担当します。OS は、実行中の各プログラムに対して、それぞれ独立した『仮想アドレス空間(仮想的なメモリ)』を割り当てます。
一方、アプリケーションは OS から割り当てられた仮想アドレス空間内で、プログラミング言語の機能を利用し、メモリの管理を行います。
仮想アドレス空間は『静的領域』や『スタック領域』、『ヒープ領域』などに分かれており、それぞれ異なる目的で使用されます。
-
静的領域
- 静的領域に格納する値はプログラム実行中に常に存在し、変更されません。定数の値などが格納されます。
-
スタック領域
- スタック領域に格納する値はコンパイル時にサイズが確定し、その値を使用する関数が実行されている間だけ有効です。
- ローカル変数や引数の値などが格納されます。
-
ヒープ領域
- ヒープ領域に格納する値はコンパイル時にサイズが確定しません。
- プログラムの実行中に必要な時に必要な量のメモリを割り当てることが可能です。
C や C++ ではヒープ領域のメモリを不要時に明示的に解放する必要がありますが、Rust では所有権の仕組みにより、メモリの管理が自動化されているため、解放忘れや二重解放などから生じる問題を防ぐことができます。所有権の主な目的がヒープ領域の管理です。3
所有権
所有権はメモリ上に格納された値の解放のタイミングを自動化し、効率的で安全なメモリ管理が実現する仕組みです。
『変数と値の関係』に注目すると、この仕組みが理解しやすくなります。
変数は、メモリ内の特定の位置に保存された値に識別子(変数名)を付けることで、ソースコード上でその値を利用しやすくするものです。
変数には型があり、これは変数に関連付ける値の種類(例: 整数、文字列など)を示します。
Rust では let 変数名: 型 で変数を宣言し、= で変数と値を結び付けます。変数はデフォルトで不変ですが、let mut 変数名: 型 とすることで後から値を変更できます。
所有権は基本的に以下の 3 つのルールによって成り立っています。
-
各値には変数がただ 1 つだけ結びつき、その変数がその値の所有者となります。
let s: String = String::from("hello"); // s が String 型の値の所有権を持つ -
変数(所有者)がスコープ(変数が有効な範囲)を抜けると、その変数が所有する値は自動的にメモリから削除されます。
{ let s: String = String::from("hello"); // スコープの開始時に所有権を持つ } // s がスコープを抜けると、自動的にメモリから値が削除される // println!("{}", s); // エラー:s はもう使用できない -
ある変数が所有する値の所有権を別の変数に『ムーブ(移動)』できます。ムーブされた後、元の変数はその値にアクセスできなくなります。
let s1: String = String::from("hello"); // s1 が所有権を持つ let s2: String = s1; // s1 の所有権が s2 にムーブされる // println!("{}", s1); // エラー:s1 はもう使用できない println!("{}", s2); // 正常に動作するただし、整数、浮動小数点数、論理値などはムーブではなくコピーされるため、元の変数もそのまま使えます。
let x: i32 = 42; let y: i32 = x; // `i32` は値がコピーされる println!("{}", x); // `x` はそのまま使える println!("{}", y); // `y` にコピーされた値を使用
このように所有権は、各値を所有する変数を明確にすることで、値のライフサイクル(生成から破棄まで)をコンパイル時に決定し、メモリリークや二重解放といった問題を防ぎます。
さらに、所有権をムーブするのではなく、変数の値を借りる(参照を作る)こともできます。
参照には不変参照と可変参照があり、借用中に値の変更やアクセスが制限されます。
-
不変参照(
&): 複数の変数が値を同時に借りることができるが、値は変更できない。 -
可変参照(
&mut): 1つの変数が値を可変に借りることができ、借用中は他の変数がその値を変更できない。
let s1: String = String::from("hello");
let s2: &String = &s1; // 不変参照
let s3: &String = &s1; // 不変参照
println!("{}", s1); // 正常に動作
println!("{}", s2); // 正常に動作
println!("{}", s3); // 正常に動作
let mut s1: String = String::from("hello");
let s2: &mut String = &mut s1; // 可変参照
s2.push_str(", world");
// println!("{}", s1); // エラー:所有権を持つ s1 も値にアクセスできない
println!("{}", s2); // "hello, world"
最初は難しく感じるかもしれませんが、どの変数がどの値の所有しているかを意識してコードを書くことで所有権に慣れてくると思います。
標準入出力
プログラミング問題では標準入力からデータを受け取り、標準出力に解答を出力する形式が基本となります。
標準入出力は、ユーザーや他のプログラムと簡単にやり取りするための仕組みです。プログラムの実行が開始されると、OS によって 3 つのストリーム(標準入力・標準出力・標準エラー)を自動的に用意され、プログラムはすぐに入出力を行えるようになります。45
ストリームとはファイルやデバイスとの入出力を統一的に扱うためのインターフェースです。これにより、プログラムがデータの具体的な入力元や出力先(例えば、ファイルから来るのか、キーボードから来るのか)を意識せずに、一連のバイトや文字を順番に読み書きできます。
Rust では、std::io モジュールを使って標準入出力を扱います。
標準入力
役割
標準入力は、プログラムが外部からデータを受け取るためのストリームです。通常、キーボード入力がこのストリームを通じてプログラムに渡されます。
操作方法
Rust では std::io::stdin() を使用して標準入力を操作し、データを受け取ることができます。
特に、lines() メソッドを利用すると、標準入力から 1 行ずつデータを読み取るイテレータが得られ、行単位での処理が簡単に行えます。
use std::io; // 標準ライブラリ (std) に含まれる io モジュール をインポート
let stdin = io::stdin(); // 標準入力のハンドルを取得
for line in stdin.lines() { // 標準入力から1行ずつ取得
match line {
Ok(input) => {
println!("入力された行: {}", input); // 入力された内容を表示
}
Err(e) => {
eprintln!("エラーが発生しました: {}", e); // エラーハンドリング
}
}
}
-
lineはResult型なので、その値がOkかErrかで分岐し、Okの場合は読み取った行(String)がinputに格納され、Errの場合はエラーメッセージが表示されます。
Result 型は、ファイルの読み込みなど、エラーが発生する可能性がある関数の返り値の型です。
match を使って成功と失敗のパターンを分岐させて処理を行います。
また、文字列から数値への変換 (parse::<i32>()) などの処理を理解しておくと、スムーズにコードが書けます。
標準出力
役割
標準出力は、プログラムの実行結果を出力するためのストリームです。通常、画面に結果を表示したり、ファイルにデータを書き込んだりする際に使います。
操作方法
Rust では、println! や std::io::stdout() を使用して標準出力を操作できます。
具体例 println!("Hello, world!");
-
println!: 末尾に改行を付け、標準出力にデータを送ります。
街外れの戦場跡(E ランク)
文字列を結合に関する問題です。
必要な知識
問題
文字列を結合した結果を求める問題です。Python でコードが記述されています。
a = "RE"
b = "IMI"
print(a+b)
解答
“REIMI”
特に説明することもないので、Rust のコードに書きかえた以下の例について解説します。
// エントリポイント は `main` 関数
fn main() {
let a: &str = "RE"; // &str 型
let b: &str = "IMI"; // &str 型
let result: String = format!("{}{}", a, b); // 文字列を連結
println!("{}", result); // 結果を出力
// println!("{}", a+b); // error: cannot add `&str` to `&str`
}
- Rust のプログラムは実行されると、まず
main関数が呼び出され、その内部のコードが実行されます。 - Rust で文字列を扱う場合、
&str型とString型の 2 つがよく使用されます。-
&str型は Python のように+演算子で連結できません。 - 代わりに、
format!を使うと、複数の文字列を簡単に連結できます。連結後の値はString型になります。
-
String 型 と &str 型
Rust で文字列は UTF-8 の配列(各文字は 1 ~ 4 バイト)として表現します。例えば "Rust" はメモリ上で 52 75 73 74(16進数表記)というバイト列として表現されます。
Rust で最もよく使用される 2 つの文字列型は String と &str です。
String 型
- 可変長の文字列型です。ユーザー入力など、実行時に変化する文字列を扱う場合に使用します。
- 文字列データはヒープ領域に格納され、そのデータのメタデータ(データの開始位置、長さ、容量)は通常スタック領域に格納されます。
&str 型
- 既存の文字列データへの不変の参照です。
- 文字列データのメタデータ(データの開始位置、長さ、容量)は通常スタック領域に格納され、実際のデータは別の場所(静的領域、ヒープ領域)に格納されます。
String 型と &str 型の例
// String 型の例
// `Hello` はヒープ領域に格納される
let mut s: String = String::from("Hello");
s.push_str(", world!"); // 文字列を変更できる
println!("String 型の s: {}", s);
// &str 型の例
// `Hello, Rust!` は静的領域に格納される
let literal: &str = "Hello, Rust!";
// literal.push_str(" more"); // コンパイルエラー:&str は変更できない
println!("&str 型の literal: {}", literal);
`let mut s = String::from("Hello");` で、
- 実際のデータ(`Hello`)はヒープ領域に配置
- このデータへアクセスするためのポインタはスタック領域に配置
スタック領域
+-------+------------+
| 変数 | 値 |
+-------+------------+
| s | Pointer | -> ヒープ上の `Hello` の先頭アドレス(ポインタ)
| | Length: 5 | -> `Hello` の長さ (バイト数)
| | Capacity: 5| -> ヒープ上に確保された容量
+-------+------------+
ヒープ領域
+---+---+---+---+---+
| H | e | l | l | o |
+---+---+---+---+---+
`s.push_str(", world!");` により、ヒープ上のデータが拡張される可能性があります。
新しい文字列の長さが既存の `Capacity` を超える場合、メモリが再確保されることがあります。
`let literal: &str = "Hello, Rust!";` で、
- `Hello, Rust!` は静的領域に格納
- `literal` はこのデータへの参照を保持
スタック領域
+----------+------------+
| 変数 | 値 |
+----------+------------+
| literal | Pointer | -> 静的領域上の `Hello, Rust!`の先頭アドレス(ポインタ)
| | Length: 12 | -> `Hello, Rust!` の長さ
+----------+------------+
静的領域
+---+---+---+---+---+---+---+---+---+---+---+---+
| H | e | l | l | o | , | | R | u | s | t | ! |
+---+---+---+---+---+---+---+---+---+---+---+---+
郊外のスラム街(D ランク)
整数の演算に関する問題です。
必要な知識
-
.read_line(): 標準入力の読み取り -
.trim(): 行頭・末尾の空白を削除 -
.parse(): 文字列を数値(整数、浮動小数点数)に変換 -
.unwrap(): エラー処理を簡略化
問題
- 入力される値:
n(300 ≦ n ≦ 10,000かつn は 10 の倍数) - 期待する出力: 入力値を
1/2にして、+100した値
解答
use std::io; // std::io モジュールをインポート
fn main() {
let mut input: String = String::new();
io::stdin().read_line(&mut input);
let n: u32 = input.trim().parse::<u32>().unwrap();
println!("{}", n / 2 + 100); // nを1/2にして、100足した結果を出力
}
- ユーザーの入力を保持するために
String型の変数inputを作成します。 -
read_line()メソッド は標準入力から 1 行を読み込み、inputに格納します。 -
inputはString型であるため、trim()メソッドで行頭・末尾の空白を削除し、parse()メソッドで数値に変換します。- 今回は
32ビットの符号なし整数型に変換するため、::<u32>と記述します。 -
parseは文字列を数値に変換しますが、失敗する可能性があるためResult型で返します。Result型の値に対するエラー処理を簡略化する便利な方法として、unwrap()メソッドが利用できます。
- 今回は
Rustでエラーは、回復可能なエラーと回復不可能なエラーの大きく 2 つに分類されます。
ファイルの読み込みや文字列の型変換など、回復可能なエラーが発生する可能性がある関数は Result 型を返します。Result 型は成功 Ok か、失敗 Err のいずれか 2 つの結果を返します。
match を使用してエラーを処理することが一般的ですが、expect() や unwrap() を利用することで簡潔に記述できます。
エラー処理の例
let number_str: &str = "15";
match number_str.parse::<i32>() {
// 変換が成功した場合、Ok の中に変換された数値が入って返されます。
Ok(num) => println!("{}", num),
// 変換が失敗した場合(例えば、number_str が "abc" のように数値に変換できない文字列だった場合)、
// Err の中にエラー情報(`e`)が入って返されます。
Err(e) => eprintln!("数値の変換に失敗しました: {}", e),
}
// .expect() は、
// Result型が Ok の場合は、Ok の中身を取り出して返します。
// Result型が Err の場合、パニック(回復不可能なエラー)を引き起こします。
let num_expect: i32 = number_str.parse::<i32>().expect("数値の変換に失敗しました");
println!("{}", num_expect);
// .unwrap() は、.expect() とほとんど同じですが、
// エラーメッセージをカスタマイズできないところが異なります。
let num_unwrap: i32 = number_str.parse::<i32>().unwrap();
println!("{}", num_unwrap);
カジノ(D ランク)
整数の演算に関する問題です。複数行の入力を処理します。
必要な知識
-
Vec型: 同じ型の要素からなる可変長の配列 -
for in文: イテレータのそれぞれの要素に対して処理に使用する -
.lines(): 標準入力を行単位で処理するためのイテレータにする -
if文: 条件分岐
問題
- 入力される値:
- 1 行目: 1 ドルの枚数
- 2 行目: 5 ドルの枚数
- 3 行目: 10 ドルの枚数
- 期待する出力: 合計の金額
解答
use std::io;
fn main() {
let mut inputs: Vec<u32> = vec![]; // 可変のベクタを定義
let stdin = io::stdin(); // 標準入力のハンドルを取得
// 標準入力を 1 行ずつ処理(各行は末尾に改行を含まない)
for line in stdin.lines() {
let number_str: String = line.unwrap();
match number_str.trim().parse::<u32>() {
Ok(num) => inputs.push(num), // ベクターに要素を追加
Err(_) => {
eprintln!("無効な入力: 数値を入力してください");
}
}
}
// Rust では条件式を括弧でくくる必要がない
if inputs.len() == 3 {
println!("{}", inputs[0] + 5 * inputs[1] + 10 * inputs[2]);
}
}
-
vec![]: ベクターを作成。 -
push(): ベクターに要素を追加 -
len(): ベクターの要素数を取得 -
v[index]: 指定したインデックスの要素にアクセス
Vec 型
- 同じ型の要素からなる可変長の配列
- ヒープ領域に要素を格納し、要素の追加・削除が可能
イテレータとは、データ列を順番に処理するための仕組みで for ループなどで使用します。
Vec 型は for in 文で使用すると、自動的にイテレータに変換されます。6
コード例
let values: Vec<i32> = vec![0, 1, 2, 3];
// valuesはi32型を要素とするVec型ですが、自動的にイテレータに変換される
for v in values { // vはi32型
println!("{}", v);
}
ネオン街の裏路地(D ランク)
最大値を求める問題です。
必要な知識
- 比較演算子(
==,!=,<,<=,>,>=):
比較する数値は同じ型である必要がある
問題
- 入力される値:
- 1 行目: 整数
n(1 ≦ n ≦ 20) - 残り
n行: 整数m(1 ≦ m ≦ 999)
- 1 行目: 整数
- 期待する出力: 2 行目以降の整数の中から最大の値
解答
use std::io;
fn main() {
let mut n_str = String::new(); // 数値の個数(文字列)を格納する変数
let stdin = io::stdin(); // 標準入力へのハンドルを取得
stdin.read_line(&mut n_str).unwrap(); // 1 行目の読み取り
let n: u32 = n_str.trim().parse::<u32>().unwrap(); // 文字列を数値に変換
let mut max_value: u32 = 0;
let mut i: u32 = 0;
for line in stdin.lines() {
let number_str: String = line.unwrap();
match number_str.trim().parse::<u32>() {
Ok(num) => {
if num > max_value { // 最大値か求める
max_value = num;
}
}
Err(_) => {
continue; // 残りの処理をスキップして次のループに移る
}
}
i += 1; // Rustではi++のような書き方はできない
if i >= n {
break; // 3行読み込んだらループを抜ける
}
}
println!("{}", max_value); // 最大値を出力
}
- 入力の 1 行目は
read_line、残りの行はlineで読み取ります。 - Rust でも
for in文の中で、continueとbreakを使用することができます。
自然の残る公園(C ランク)
現在の座標と複数のビーコンの座標が与えられ、現在の座標から最も近いビーコンを求める問題です。具体的には、ユークリッド距離(直線距離)を計算し、最小のビーコンを特定します。
必要な知識
-
.split_whitespace(): 文字列を空白で分割し、イテレータを作成 -
Option型: 値が存在しない可能性を表現するための型 -
.next(): イテレータを進め、次の値をSomeで包んで返す。次の値がない場合Noneを返す。 - 範囲式: 連続した整数列を生成
問題
- 入力される値:
- 1 行目: 以下の要素が半角スペース区切りで与えられる
- ビーコンの数を表す整数 N
- 現在の位置の y 座標を表す整数
- 現在の位置の x 座標を表す整数
- 残り N 行: 以下の要素が半角スペース区切りで与えられる
- ビーコンの位置の y 座標を表す整数
- ビーコンの位置の x 座標を表す整数
- 1 行目: 以下の要素が半角スペース区切りで与えられる
- 期待する出力: 最も近いビーコンの番号
- ※最も近いビーコンが複数存在することはない
解答
use std::io;
fn main() {
let mut input = String::new();
let stdin = io::stdin(); // 標準入力へのハンドルを取得
// 1 行目の読み取り
stdin.read_line(&mut input).unwrap();
// 読み込んだ文字列を空白で分割し、イテレータを作成
let mut iter = input.split_whitespace();
let n: usize = iter.next().unwrap().parse::<usize>().unwrap();
let current_y: i32 = iter.next().unwrap().parse::<i32>().unwrap();
let current_x: i32 = iter.next().unwrap().parse::<i32>().unwrap();
let mut closest_index = 0;
let mut min_distance = i32::MAX; // i32 型の最大値
for i in 0..n { // 0..n: 範囲式(range expression)
let mut line = String::new();
stdin.read_line(&mut line).unwrap();
let mut iter = line.split_whitespace();
let beacon_y: i32 = iter.next().unwrap().parse::<i32>().unwrap();
let beacon_x: i32 = iter.next().unwrap().parse::<i32>().unwrap();
// ユークリッド距離の平方を計算し、最小のものを探す
let distance: i32 = (beacon_y - current_y).pow(2) + (beacon_x - current_x).pow(2);
if distance < min_distance {
min_distance = distance;
closest_index = i + 1;
}
}
println!("{}", closest_index);
}
Option 型7
Option 型は「値が存在するかもしれないし、存在しないかもしれない」という状況を表現するための型です。
Option 型は、以下の2つのいずれかの状態を持つことができます。
-
Some(値): 値が存在する場合、その値をSomeで包んで表現します。 -
None: 値が存在しない場合、Noneで表現します。
Result 型と同様に、match を使用して Option 型 を処理することが一般的ですが、unwrap() や unwrap_or() を利用することで簡潔に記述できます。
コード例
let some_number = Some(5);
match some_number {
Some(value) => println!("{}", value),
None => println!("None"),
}
// .unwrap() は、
// Option型が Some の場合は、Some の中身を取り出して返します。
// Option型が None の場合、パニック(回復不可能なエラー)を引き起こします。
let value = some_number.unwrap();
println!("{}", value); // 出力: 5
廃マンションの一室(C ランク)
与えられた整数を特殊な三進法に変換する問題です。
必要な知識
- 平衡三進法
問題
- 入力される値: 整数
N(-100,000 ≦ N ≦ 100,000) - 期待する出力:
Nを特殊な三進法(具体的には2を-1の意味として扱う特殊な三進法)での数値表現に変換した値
解答
- この特殊な三進法は平衡三進法と呼ばれるものです。平衡三進法では、各桁の数字として
-1,0,1の3つの値を用います。 - 通常の三進法と同じく、
n桁目の数mは十進法で $m \times 3^{n-1}$(平衡三進法の場合、mは-1,0,1のいずれか)の数を表します。例えば、三進法で100は十進法で $1 \times 3^{3-1}$ (=9) です。 - この問題は、
2は本来の意味ではなく-1の意味として扱っています。例えば、平衡三進法で200は十進法で $-1 \times 3^{3-1}$ (=-9) です。
平衡三進法が持つ対称性を理解すると問題が解きやすくなります。
以下のように、十進法で、ある数を符号反転させる(反数にする)と、平衡三進法で 1 と 2 が入れ替わる形になります。
- 十進法で
6は平衡三進法で120 - 十進法で
-6は平衡三進法で210
なぜなら、「ある数の反数とは、元の数と反転後の数を足すと 0 になる数」であり、 平衡三進法で 1 と 2(= -1)は互いに「反数」であり、足し合わせると 0 になるからです。
6 と -6 の平衡三進法を各桁に注目して足すと、下記のようになり、すべての桁が 0 になります。
120 ... 6
+ 210 ... -6
------
000 ... 0
- 入力値が負の整数の場合、正の整数として平衡三進法に変換します。
- 十進法から平衡三進法への変換は、一般的な進数変換を同じように、元の数が
0になるまで3で割り続け、余りで下の桁から確定させていきますが、- 余りが
2の場合、本来の意味通りに2を使えないので、2=3-1のように、次の桁に繰り上げて、その桁の数字は2(つまり、-1)とします。
- 余りが
use std::io;
fn main() {
let mut input = String::new();
let stdin = io::stdin();
stdin.read_line(&mut input).expect("読込失敗");
let mut num: i32 = input.trim().parse().expect("整数を入力してください");
let is_negative: bool = num < 0;
if num == 0 { // 数値が0になるまで繰り返す
println!("0");
} else {
let mut result = String::new();
if is_negative {
num = -num;
}
while num != 0 {
let remainder: i32 = num % 3;
num /= 3; // num = num / 3;
if remainder == 2 {
num += 1; // 次の桁に繰り上げ
if is_negative {
result.push('1'); // 2 --> 1
} else {
result.push('2');
}
} else if remainder == 1 {
if is_negative {
result.push('2'); // 1 --> 2
} else {
result.push('1');
}
} else {
result.push('0');
}
}
println!("{}", result.chars().rev().collect::<String>());
}
}
この問題では、平衡三進法が持つ対称性を利用することで問題が解きやすくしました。プログラミング問題では、扱う対象の性質に注目することが重要です。
ギャングのアジト(B ランク)
N × N のグリッドを黒と白で塗ったピクセルアートが左右対称か判断する問題です。
必要な知識
問題
- 入力される値:
- 1 行目: ピクセルアートの大きさを表す整数
N - 残り
N行: 以下の要素が半角スペース区切りでN個与えられる-
0または1の数字
-
- 1 行目: ピクセルアートの大きさを表す整数
- 期待する出力: ピクセルアートが左右対称なら
YesをそうでないならNoを出力
解答
ピクセルアートが左右対称であるということは、各行の文字列を反転させても同じままということです。
use std::io;
fn main(){
// .skip(1)でイテレータの要素を1つスキップ
let inputs = io::stdin().lines().skip(1);
for input in inputs {
let line: String = input.unwrap();
if line != line.chars().rev().collect::<String>() {
println!("No");
return;
}
}
println!("Yes");
}
-
.chars().rev().collect::<String>()で文字列を反転させています。-
.chars()でchar型(1 文字)のイテレータに変換 -
.rev()でイテレータを反転 -
.collect::<String>()でイテレータをString型に戻す。
-
一番通りの繁華街(B ランク)
N × N の広さの地域の中にある建物同士を線で繋いだ時、正方形になる数を出力する問題です。
必要な知識
-
.enumerate(): イテレータの要素をインデックス付きで返す。 -
.nth(n): イテレータのn番目の要素を返します。返り値はOotion型です。
問題
- 入力される値:
- 1 行目: 地域の大きさを表す整数
N - 残り N 行:
#もしくは.からなるN文字の文字列-
.は、その場所は建物であることを表します。 -
#は、その場所はなにもないことを表します。
-
- 1 行目: 地域の大きさを表す整数
- 期待する出力:
.の場所を線で縦横に繋いだ時、正方形になる数(斜めは含まない)
5
.#.#.
#####
.#.#.
##.##
.###.
3
解答
- 左上から順に各マスを調べます。
- 建物発見したら、その位置を基準に、同じ行で基準の位置より右に建物があるか調べます。(左側を調べないのは正方形のカウントの重複を防ぐため)
- 見つかった場合、基準点と右側の点から同じ距離だけ下に離れた 2 つの建物を確認します。(上側を調べないのは正方形のカウントの重複を防ぐため)
- 基準の位置と同じ行に、他に建物があった場合、
2.の処理に戻り、なかった場合は、次の行に移って2.の処理を行います。
use std::io;
fn main() {
let mut n_str = String::new(); // 数値の個数(文字列)を格納する変数
let stdin = io::stdin(); // 標準入力へのハンドルを取得
stdin.read_line(&mut n_str).unwrap(); // 1 行目の読み取り
let n: usize = n_str.trim().parse::<usize>().unwrap(); // 文字列を数値に変換
let inputs = stdin.lines();
let mut rows: Vec<String> = Vec::new();
for input in inputs {
rows.push(input.unwrap());
}
let mut count: i32 = 0;
for (i, row) in rows.iter().enumerate() { // 行ごとに処理
for (j, cell) in row.chars().enumerate() { // 行内の文字を一つずつ処理
if cell == '.' { // 建物を発見した場合
for k in (j + 1)..n {
// 発見した位置よりも左で、新たに建物を発見した場合、
if row.chars().nth(k) == Some('.') {
let distance = k - j;
let new_row = i + distance;
// 正方形になるか確認
if new_row < n
&& rows[new_row].chars().nth(j) == Some('.')
&& rows[new_row].chars().nth(k) == Some('.')
{
count += 1;
}
}
}
}
}
}
println!("{}", count);
}
上記のコードは for ループが 3 重になっているので戒厳の余地があります。(先に、建物位置を Vec に保存するなど)
新都心のハイウェイ(A ランク)
最短経路を求める問題です。
必要な知識
- 幅優先探索: 最短経路を求めるのに適しています。
- 関数
問題
縦 H マス、横 W マスのグリッドがあり、「道マス」と「壁マス」で構成されています。A と B は道マスのいずれかに配置されています。
A は、今いるマスの上下左右方向のいずれかのマスに B がいて、かつ A と B の間に壁マスがない時に限り、B を見つけることができます。(なお、1 回の移動により上下左右に隣接する道マスに移動することができます。)
- 入力される値:
- 1 行目: 縦方向のマス数
Hと横方向のマス数を表す整数Wが半角スペース区切りで与えられる - 残り
H行:- 英字大文字
A,Bおよび半角記号.,#からなる長さWの文字列 - "." は道マスであることを表し、"#" は壁マスであることを表します。"A" と "B" は入力に 1 つずつ存在します。
- 英字大文字
- 1 行目: 縦方向のマス数
- 期待する出力:
-
AがBを見つけるために必要な最小の移動回数 - 見つけることができない場合は
-1を出力
-
3 5
A....
.#.#.
....B
2
解答
-
幅優先探索を使用して、開始点
AからゴールBまでの最短距離を求めます。 - ただし、ゴールは単なる点ではなく、
Bから上下左右に壁#に当たるまでの範囲が探索対象となります。 - そのため、下記のコードでは
determine_goals関数で、ゴール位置Bから上下左右に障害物#に当たるまでの範囲を探索対象のゴール集合として求めています。 - その後、
bfs_maze関数を呼び出し、開始点から最も近いゴールまでの距離を計算します。
use std::io;
use std::collections::{VecDeque, HashSet};
// DXとDYを定数配列として定義し、4方向の移動を記述。
const DX: [isize; 4] = [1, 0, -1, 0]; // const で定数を宣言できます。型を省略することは不可です。
const DY: [isize; 4] = [0, 1, 0, -1]; // [] は配列で、Vec と異なり、不変です。
fn main(){
let mut inputs = io::stdin().lines();
let first_line = inputs.next().unwrap().unwrap();
let parts: Vec<usize> = first_line.split_whitespace()
.map(|s| s.parse().unwrap())
.collect();
let (h, w) = (parts[0], parts[1]);
let mut maze = vec![vec![' '; w]; h];
let mut start = (0, 0);
let mut goal = (0, 0);
for i in 0..h {
let line = inputs.next().unwrap().unwrap();
for (j, c) in line.chars().enumerate() {
maze[i][j] = c;
if c == 'A' {
start = (i, j);
} else if c == 'B' {
goal = (i, j);
}
}
}
let goals = determine_goals(&maze, goal);
let result = bfs_maze(&maze, start, &goals);
println!("{}", result);
}
// 関数の返り値は -> の後に記述します。
fn determine_goals(maze: &Vec<Vec<char>>, goal: (usize, usize)) -> HashSet<(usize, usize)> {
// HashSet 型を使用して、ゴールの座標を記録します。
let mut goals = HashSet::new();
let (gx, gy) = goal;
let h = maze.len();
let w = maze[0].len();
let mut y = gy;
while y > 0 && maze[gx][y - 1] != '#' {
y -= 1;
goals.insert((gx, y));
}
let mut y = gy;
while y + 1 < w && maze[gx][y + 1] != '#' {
y += 1;
goals.insert((gx, y));
}
let mut x = gx;
while x > 0 && maze[x - 1][gy] != '#' {
x -= 1;
goals.insert((x, gy));
}
let mut x = gx;
while x + 1 < h && maze[x + 1][gy] != '#' {
x += 1;
goals.insert((x, gy));
}
goals
}
fn bfs_maze(maze: &Vec<Vec<char>>, start: (usize, usize), goals: &HashSet<(usize, usize)>) -> isize {
let h = maze.len();
let w = maze[0].len();
let mut queue = VecDeque::new();
let mut distances = vec![vec![-1; w]; h];
let mut visited = vec![vec![false; w]; h];
queue.push_back(start);
distances[start.0][start.1] = 0;
visited[start.0][start.1] = true; // 訪問済みフラグ。
while let Some((x, y)) = queue.pop_front() {
let current_distance = distances[x][y];
if goals.contains(&(x, y)) {
return current_distance;
}
for d in 0..4 {
let nx = x as isize + DX[d];
let ny = y as isize + DY[d];
if nx >= 0 && ny >= 0 && (nx as usize) < h && (ny as usize) < w {
let nx = nx as usize;
let ny = ny as usize;
if maze[nx][ny] != '#' && !visited[nx][ny] {
queue.push_back((nx, ny));
distances[nx][ny] = current_distance + 1;
visited[nx][ny] = true;
}
}
}
}
-1
}
思い出の屋上(S ランク)
必要な知識
- マンハッタン距離
問題
街は縦 `H` マス、横 `W` マスのグリッドで表され、既存の `M` 個のギャングの縄張りがあります。各縄張りは中心 `(r, c)` からマンハッタン距離 `S` 以下の座標で構成されます。新たに縄張りを作る際、既存の縄張りと重ならず、可能な限りサイズ S を大きくしたいです。
- 入力される値:
- 1 行目: エリアの行数
Hと列数W、すでにある縄張りの中心の個数Mがこの順に半角スペース区切りで与えられる - 残り M 行: 以下の要素が半角スペース区切りで与えられる
- 張りの中心の座標を表す行番号
- 張りの中心の座標を表す列番号
- 縄張りのサイズ
- 1 行目: エリアの行数
- 期待する出力: 新しい縄張りの最大サイズ
S(作れない場合は-1)。
5 6 3
3 2 2
4 4 0
5 5 1
3
解答
use std::io;
fn main() {
let mut inputs = io::stdin().lines();
let first_line = inputs.next().unwrap().unwrap();
let nums: Vec<isize> = first_line
.split_whitespace()
.map(|s| s.parse().unwrap())
.collect();
let (h, w, m) = (nums[0], nums[1], nums[2]);
let mut grid = vec![vec![0; w as usize]; h as usize]; // 0: 空き, 1: 縄張り
// 縄張り(領域)のマーキング
for _ in 0..m {
let line = inputs.next().unwrap().unwrap();
let nums: Vec<isize> = line
.split_whitespace()
.map(|s| s.parse().unwrap())
.collect();
let (r, c, s) = (nums[0] - 1, nums[1] - 1, nums[2]);
grid[r as usize][c as usize] = 1;
for i in 0..=s {
for d in 0..i {
let moves = [
(r - i + d, c - d), // 1
(r + d, c - i + d), // 2
(r + i - d, c + d), // 3
(r - d, c + i - d), // 4
];
for (x, y) in moves {
if x >= 0 && x < h && y >= 0 && y < w {
grid[x as usize][y as usize] = 1;
}
}
}
}
}
// 新たな縄張りの最大サイズの計算
let mut max_size = -1;
for r in 0..h {
for c in 0..w {
if grid[r as usize][c as usize] == 0 {
// 空いている場所
let mut s = 0;
'outer: loop {
for d in 0..=s {
let moves = [
(r - s + d, c - d), // 1
(r + d, c - s + d), // 2
(r + s - d, c + d), // 3
(r - d, c + s - d), // 4
];
for (x, y) in moves {
if x >= 0
&& x < h
&& y >= 0
&& y < w
&& grid[x as usize][y as usize] == 1
{
break 'outer;
}
}
}
s += 1;
}
if max_size < s - 1 {
max_size = s - 1;
}
}
}
}
println!("{}", max_size);
}
データベース問題
データベース問題は全 5 問で、すべて SQL に関する問題です。
前提知識
まずは SQL の概要を紹介します。
SQL は『リレーショナルデータベース』のデータを操作するための言語です。
リレーショナルデータベースは関連するデータを『テーブル』という形式で管理するデータベースです。
テーブルは『レコード(行)』と『カラム(列)』で構成されています。表計算ソフトを利用したことがある方は馴染みのある形式だと思います。
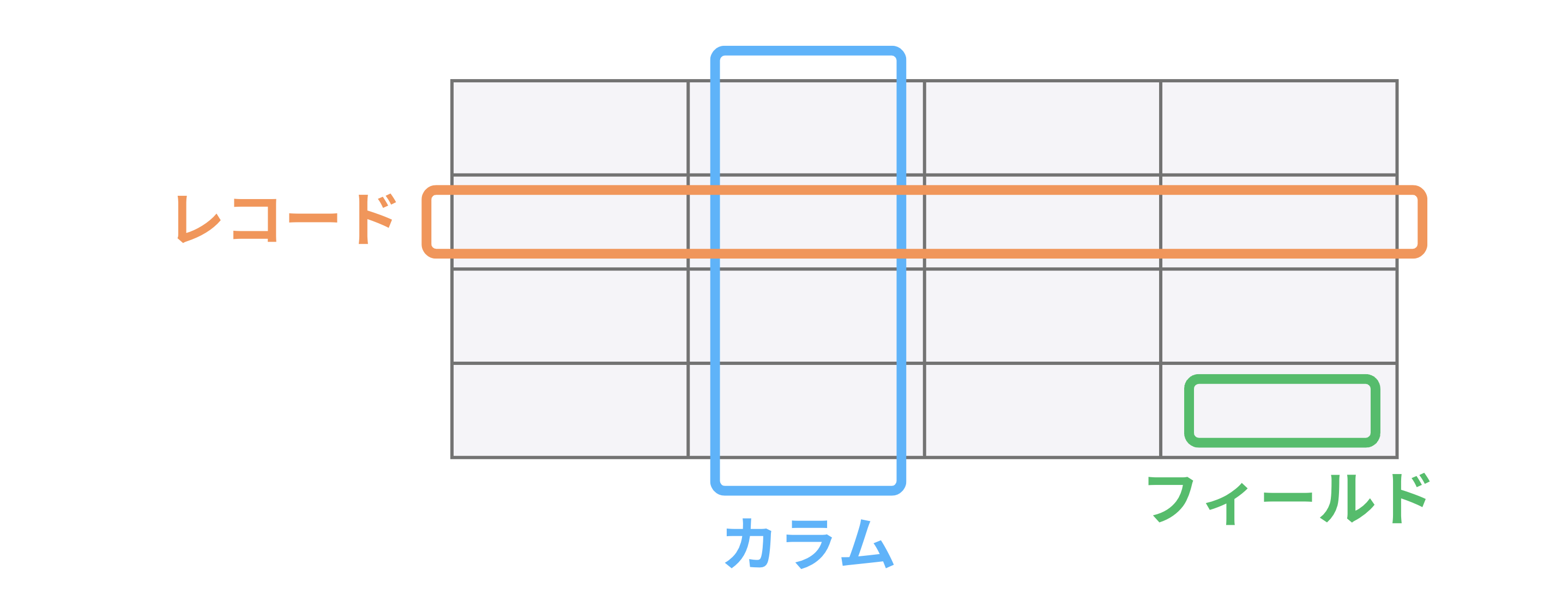
SQL を利用することでデータの追加や削除、更新などの様々な操作を実行できますが、今回は『テーブルからデータを抽出する際に使用する SELECT 』について解説します。
例えば、以下のような employees テーブルがあるとします。
+-----+-----------+---------------+------------+---------+
| id | name | department_id | hire_date | salary |
+-----+-----------+---------------+------------+---------+
| 1 | 田中 太郎 | 1 | 2023-04-01 | 300000 |
+-----+-----------+---------------+------------+---------+
| 2 | 山田 花子 | 2 | 2024-06-15 | 350000 |
+-----+-----------+---------------+------------+---------+
employees テーブルから id, name, salary のカラム(列)を取得するには以下のような SQL 文を実行します。
SELECT id, name, salary FROM employees;
-
SELECT カラム名1, カラム名2, ...: 取得したいカラムの名前を指定 -
FROM テーブル名: データを取得するテーブルの名前を指定
(SELECT や FROM はキーワードと呼ばれ、SQL 文で特別な意味を持つ単語です。キーワードは記述する順番に決まりがあります。)
+-----+-----------+---------+
| id | name | salary |
+-----+-----------+---------+
| 1 | 田中 太郎 | 300000 |
+-----+-----------+---------+
| 2 | 山田 花子 | 350000 |
+-----+-----------+---------+
それでは、実際に問題を解きながらより複雑な SQL について解説していきます。
データセンター(D ランク)
必要な知識
- カラムの指定:
SELECT カラム名 - テーブルの指定:
FROM テーブル名
問題
person テーブルの id と name をすべて出力してください。
+-------------+------------+-------------------+
| カラム名 | データ型 | 説明 |
+-------------+------------+-------------------+
| id | int | ID |
| name | text | 人物名 |
| biography | text | 詳細 |
| created_at | date | 出会った日 |
| deleted_at | date | 亡くなった日 |
+-------------+------------+-------------------+
(問題で memory テーブルも与えられていますが今回は使用しません。)
解答
さきほどの例と同じく SELECT カラム名 FROM テーブル名 でデータを抽出します。
SELECT id, name FROM person;
テーブル名.カラム名 という形式で、どのテーブルのどのカラムを取得するのかを明示的に指定することもできます。
SELECT person.id, person.name FROM person;
二人が通った教室(Cランク)
必要な知識
- 並びかえ:
ORDER BY カラム名 ASC|DESC - レコード数の制限:
LIMIT レコード数
問題
memory テーブルのうち id の小さい順(昇順)に 10 件レコードを取得し、それぞれの id と talk を出力してください。
+-------------+------------+-------------------+
| カラム名 | データ型 | 説明 |
+-------------+------------+-------------------+
| id | int | ID |
| talk | text | 会話内容 |
| importance | int | 重要度 |
| person_id | int | 人物のID |
| category_id | int | カテゴリのID |
| created_at | date | 記録日 |
+-------------+------------+-------------------+
(問題で person テーブルも与えられていますが今回は使用しません。)
解答
今まではすべてのレコード(行)を取得していましたが、この問題では id で昇順に並びかえた後、先頭の 10 件のレコードを抽出します。
SELECT memory.id, memory.talk FROM memory ORDER BY id ASC LIMIT 10;
- レコードの順番の並びかえは
ORDER BY カラム名 ASC|DESCという形式で行います。(ASCは昇順、DESCは降順) - 取得するレコード数の制限は
LIMIT レコード数という形式で行います。
会員制ジム(C ランク)
必要な知識
- 主キー・外部キー
- テーブル結合:
JOIN テーブル名 ON 結合条件 - データを絞り込むための条件を指定:
WHERE 条件式
問題
memory テーブルのうち importance が 3 以上で、 category の name が "悲しみ" の memory.id, memory.talk を出力してください。
+-------------+------------+-------------------+
| カラム名 | データ型 | 説明 |
+-------------+------------+-------------------+
| id | int | ID |
| name | text | 記憶カテゴリ名 |
+-------------+------------+-------------------+
(memory テーブルの概要は『二人が通った教室(Cランク)』で書いたので省略)
解答
この問題は複数のテーブル(memory と category)を結合し、特定の条件(memory.importance >= 3 かつ category.name = "悲しみ")を満たすレコードを抽出するというものです。
データを絞り込むための条件が複数のテーブルに渡っているため、テーブルを結合してからデータを絞り込む必要があります。
SELECT memory.id, memory.talk
FROM memory
JOIN category ON memory.category_id = category.id
WHERE category.name = "悲しみ" AND memory.importance >= 3
-
JOIN テーブル名 ON 結合条件: 2つのテーブルに共通のデータが存在する場合に、そのデータを持つレコードのみを結合(内部結合) -
WHERE 条件式:データを絞り込むための条件を指定
テーブルの結合条件として、memory テーブルのカラムに category_id を使用しています。これは category テーブルの id を指し示す外部キーです。
主キー・外部キー
各レコードには、テーブル内の各レコードを一意に識別するための主キーがあります。(category テーブルでは id が主キーです。)
また、主キーは他のテーブルとのリレーションシップ(関係性)を表現するためにも使用されます。他のテーブルの主キーを指し示すカラムは外部キーと呼ばれます。(memory テーブルでは category_id が外部キーです。)
外部キーは複数のテーブルを結合する上で重要な役割を果たします。
以下は memory テーブルの category_id と category テーブルの id をもとに結合(JOIN)した例です。
SELECT memory.id, memory.talk, memory.importance, memory.category_id, category.name
FROM memory
JOIN category ON memory.category_id = category.id;
-- memory テーブルのデータ --
+----+--------------------+------------+-----------+-------------+------------+
| id | talk | importance | person_id | category_id | created_at |
+----+--------------------+------------+-----------+-------------+------------+
| 1 | 失敗して落ち込んでいる | 4 | 101 | 2 | 2024-01-10 |
+----+--------------------+------------+-----------+-------------+------------+
| 2 | 楽しかった旅行の話 | 5 | 102 | 1 | 2024-01-11 |
+----+--------------------+------------+-----------+-------------+------------+
| 3 | 友達と喧嘩してしまった | 3 | 103 | 2 | 2024-01-12 |
+----+--------------------+------------+-----------+-------------+------------+
-- category テーブルのデータ --
+----+--------+
| id | name |
+----+--------+
| 1 | 喜び |
+----+--------+
| 2 | 悲しみ |
+----+--------+
-- テーブル結合の結果 --
+----+--------------------+------------+-------------+-------+
| id | talk | importance | category_id | name |
+----+--------------------+------------+-------------+-------+
| 1 | 失敗して落ち込んでいる | 4 | 2 | 悲しみ |
+----+--------------------+------------+-------------+-------+
| 2 | 楽しかった旅行の話 | 5 | 1 | 喜び |
+----+--------------------+------------+-------------+-------+
| 3 | 友達と喧嘩してしまった | 4 | 2 | 悲しみ |
+----+--------------------+------------+-------------+-------+
WHERE を使用することでデータを絞り込むことができます。複数の条件をすべて満たすデータを抽出したい場合、AND を使います。
WHERE category.name = "悲しみ" AND memory.importance >= 3
打ち捨てられた図書館(Bランク)
必要な知識
- テーブル結合:
JOIN テーブル名 ON 結合条件
問題
log テーブルの created_at が 2085-08-01 〜 2087-10-20 の期間の memory.id, memory.talk, battle.result を出力してください。
+-------------+------------+-------------------+
| カラム名 | データ型 | 説明 |
+-------------+------------+-------------------+
| memory_id | int | ID |
| battle_id | int | カテゴリのID |
| created_at | date | 記録日 |
+-------------+------------+-------------------+
+-------------+------------+-------------------+
| カラム名 | データ型 | 説明 |
+-------------+------------+-------------------+
| id | int | ID |
| importance | int | 重要度 |
| result | text | 結果 |
| created_at | date | 記録日 |
+-------------+------------+-------------------+
(memory テーブルの概要は『二人が通った教室(Cランク)』で書いたので省略)
解答
SELECT memory.id, memory.talk, battle.result
FROM log
JOIN memory ON log.memory_id = memory.id
JOIN battle ON log.battle_id = battle.id
WHERE log.created_at >= "2085-08-01" AND log.created_at <= "2087-10-20"
-
logテーブルのcreated_atが 2085-08-01 〜 2087-10-20 の期間であるという条件はWHEREで表現します。 -
JOINは複数回使用できます。今回取得するカラムはmemoryテーブルとbattleテーブルにあるので、この 2 つのテーブルをlogテーブルに結合します。
log テーブルには 結合条件 で使用する memory と battle のテーブルの id がどちらもあるので JOIN memory、JOIN memory どちらを先に記述しても問題ありません。
SELECT memory.id, memory.talk, battle.result
FROM memory
JOIN log ON log.memory_id = memory.id
JOIN battle ON log.battle_id = battle.id
WHERE log.created_at >= "2085-08-01" AND log.created_at <= "2087-10-20"
FROM log ではなく FROM memory にした場合、JOIN log を JOIN battle より先に記述しなければ、memory テーブルに battle_id カラムがないのでエラーが発生します。
巨大コーポの最上階(Aランク)
必要な知識
-
JOINの順番
問題
log, memory, battle, category, person のテーブルがあります。
person のうち重要度が 5 の人物の person.deleted_at と同じ battle の battle.created_at から memory と battle と person の memory.id, memory.talk, person.name, battle.created_at を出力してください。
解答
依存関係に基づいて、結合する順番を決めることが重要です。
問題文から category テーブルは使用しないことがわかるので、 このテーブル以外の依存関係を考えます。
person テーブルには外部キーがない一方、他のテーブルには person_id のカラムが存在します。今回は person テーブルを基準にテーブルを結合します。
SELECT memory.id, memory.talk, person.name, battle.created_at
FROM person
JOIN battle ON battle.person_id = person.id
JOIN log ON log.person_id = person.id
JOIN memory ON log.memory_id = memory.id
WHERE person.importance = 5 AND person.deleted_at = battle.created_at;
-
JOIN memory ON log.memory_id = memory.idはlogテーブルを先に結合しないとlog.memory_idを見つけることができないため、エラーが発生します。 -
personのうち重要度が 5 の人物のperson.deleted_atと同じbattleという条件はWHEREで表現。
SELECT memory.id, memory.talk, person.name, battle.created_at
FROM log
JOIN person ON log.person_id = person.id
JOIN battle ON battle.person_id = person.id
JOIN memory ON log.memory_id = memory.id
WHERE person.importance = 5 AND person.deleted_at = battle.created_at;
依存関係に基づいて JOIN の順番に気をつければ、他のテーブルを基準にテーブル結合(内部結合)を行なっても同じ結果になります。
おわりに
本記事では「電脳少女プログラミング2088 ─壊レタ君を再構築─」を題材に、Rust と SQL の基礎を解説しました。
Rust では 標準入出力や、よく使用される型(文字列型や数値型、Vec 型、イテレータ)の基本的な扱い方を中心に解説しました。より詳しく学びたい方は、有志によって翻訳されている Rustの日本語ドキュメントを参考にしてください。
SQL では SELECT のみを扱いましたが、INSERT、UPDATE、DELETE などのデータ操作も学ぶことで、より実践的なデータベース操作が可能になります。
-
paiza は、IT エンジニア・プログラマ向けの総合的な転職・学習プラットフォームです。 ↩
-
ゲームに参加するには、アカウント登録とニックネーム設定が必要です。 ↩
-
参考: Standard I/O Streams | The Open Group Base Specifications Issue 8 ↩
-
参考: std::iter - Rust ↩