はじめに
パラメータを変えながらLambdaを繰り返し実行したくてDynamoDB Streamを使いました。参考までにと思い投稿してみました。
この記事ではAWS LambdaからDynamoDBに日付などの数字を書き込んだのち、DynamoDB Streamを用いて同じLambda関数を呼び出し、書き込んだ日付について処理を行う実装をします。
ランタイムはPython3.8を選択しています。
Lambdaの設定で「ハンドラ」は「lambda_function.lambda_handler」であるものとし、
LambdaのロールにはDynamoDBFullAccess権限が付与されています。
この方法を使ってよかったこと
自分の場合はS3でyyyymmddフォルダに入ったファイルを処理する必要に迫られましたが、
Lambdaの性質上+自分の技能上の都合で、「どのファイルを処理するか/したか」をどこかに持たないと再実行は実装できませんでした。が、大量のファイル名をリクエストに手書きする訳にもいかず・・・
そんな悩みをここに書いてある方法で解決することが出来ました。
SQSでも出来そうですが、元々DynamoDBの権限がある処理だったので、ロールに権限を追加しないで済みましたし、
どの日付で処理を入れたかを見ながら実装を進められたので楽に実装することが出来ました。
また、仕組みが単純であり実装のイメージが湧きやすかったため、実装にどれくらい時間がかかるかあらかじめ予測することができました。
また、DynamoDBに入れた内容が永続化されるため、やろうと思えばどの日時について処理したかを後から参照することも出来ます(本記事ではそこまでは扱いません)。
この記事でやること
- DynamoDBにテーブルを作成し、DynamoDB Streamを有効化
- Lambda上でDynamoDBトリガーを有効化
- 試しにDynamoDBに値を挿入し、イベントの内容を見る
- イベントを処理できるよう、分岐をコードに書く
- LambdaからDynamoDBに値を挿入する
- Lambdaが呼び出されることを確認する
- Lambda関数を繰り返し呼び出す
- DynamoDBへの挿入を日付でループすることによって、日付別の処理を行う
DynamoDBにテーブルを作成
- AWSマネジメントコンソールにログインし、DynamoDBのページを出す(下図)。
その後、画面左側ナビゲーションペインの「テーブル」をクリック。
さらに、下図赤枠部分の「テーブルの作成」ボタンをクリック。

- 下図赤枠部分の「テーブル名」「プライマリキー」テキストボックスにすきな値を入力し、「作成」ボタンをクリック。
以後、この記事のサンプルでは下図の値を使用する。なので、よく分からない場合はhello_table、keyとする。

- 下図のような画面が表示されるので、作成したテーブルが増えており、「状態」が「有効」になっていることを確認する。

DyanoDB Streamを有効化
- 上図赤枠①のラジオボタンをクリックし、赤枠②の「ストリームの管理」をクリック。
- 下図のようなモーダルダイアログが表示されるので、「表示タイプ」を選択し「有効化」をクリック。
レコードが作られた時にlambdaを呼び出したいので、表示タイプは今回は「新しいイメージ」を選択。

Lambda上でDynamoDBトリガーを有効化
-
AWSマネジメントコンソールで対象のLambda関数のページを開く。
-
ロールに以下に示すものかそれ以上の権限があることを確認する。
-
[
-
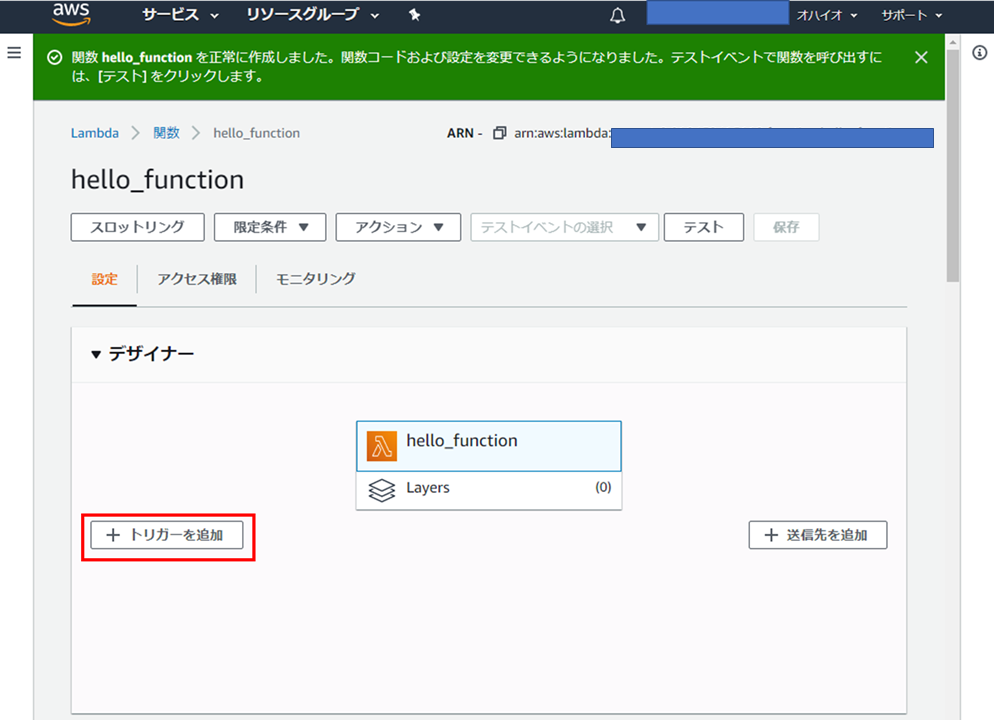
「設定」タブの「トリガーを追加」をクリック
-
コンボボックスで「DynamoDB」を選択

- 「DynamoDB テーブル」テキストボックスをクリックし、上述の手順で作成したテーブルを選択。
この例では「再試行」を0に設定する。
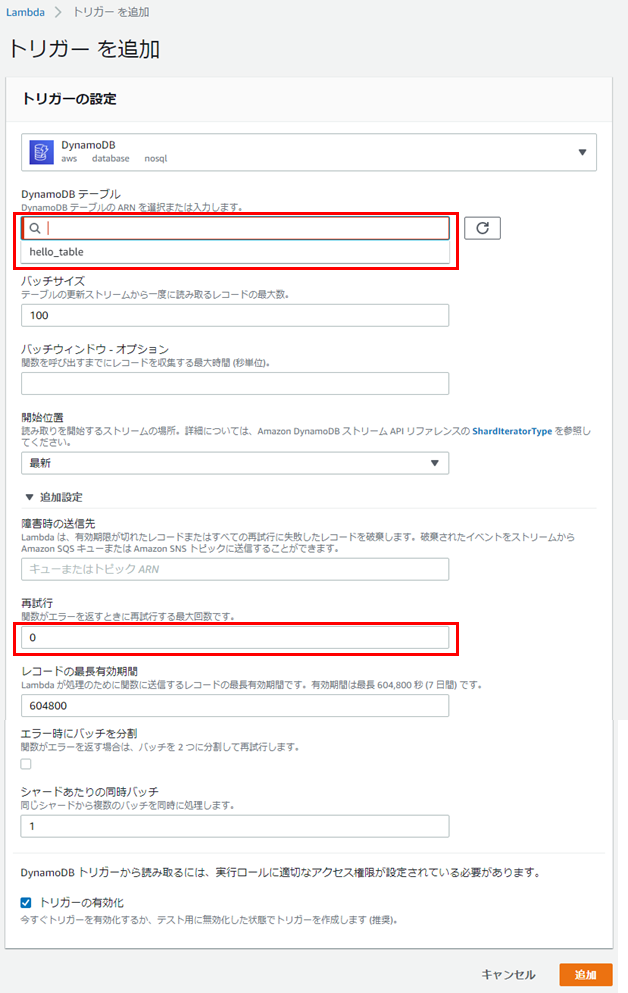
7.「追加」ボタンをクリック
![]()
イベントの内容を見てみる
- 上記手順によって以下の画面が表示されるはずなので、下図赤枠部分のLambda関数の部分をクリックする

- ページをスクロールすると「関数コード」と書いてある部分がある。

この画面からコードを編集したりアップロードすることが出来る。
イベントの内容が見れるサンプルコードを以下に示す。
def lambda_handler(event, context):
print(event)
return {
'statusCode': 200,
'body': 'success'
}
-
DynamoDBのテーブルのページを出し、「項目」タブをクリック。
その後、下図赤枠部分の「項目の作成」ボタンをクリック
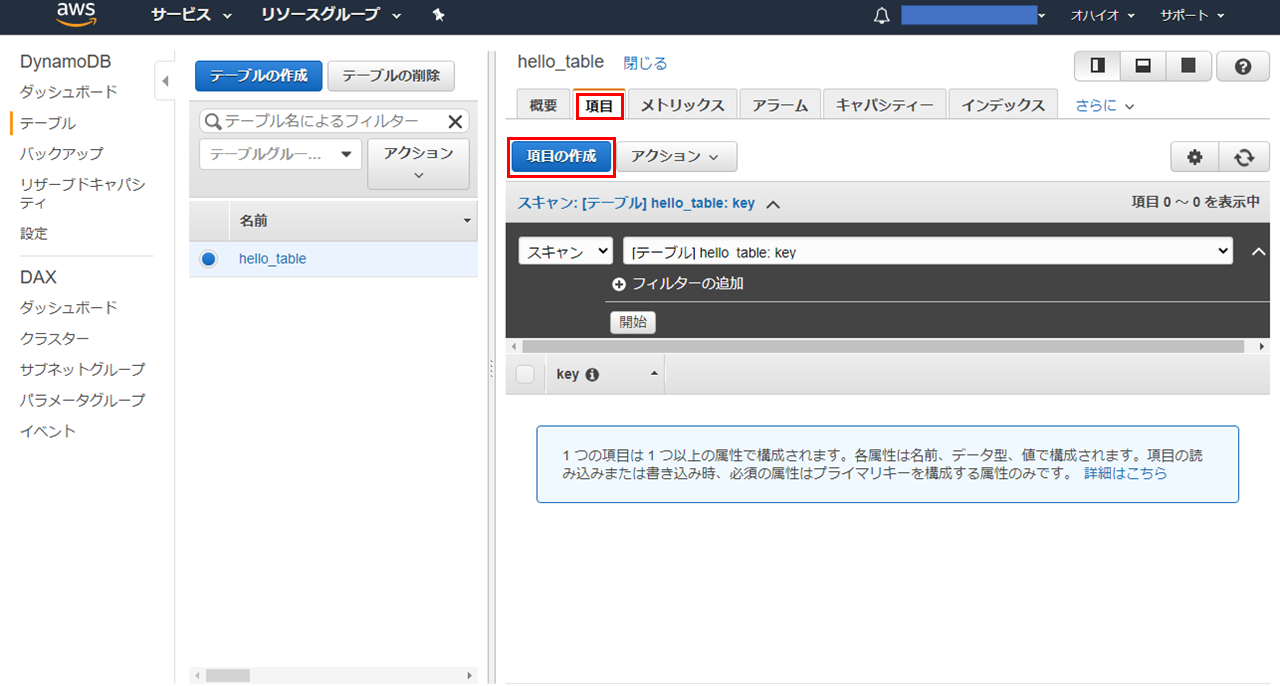
-
 ボタンをクリックし、「Append」をクリック。
ボタンをクリックし、「Append」をクリック。
すきなデータ型を選ぶ。(例ではStringを選んでいる)
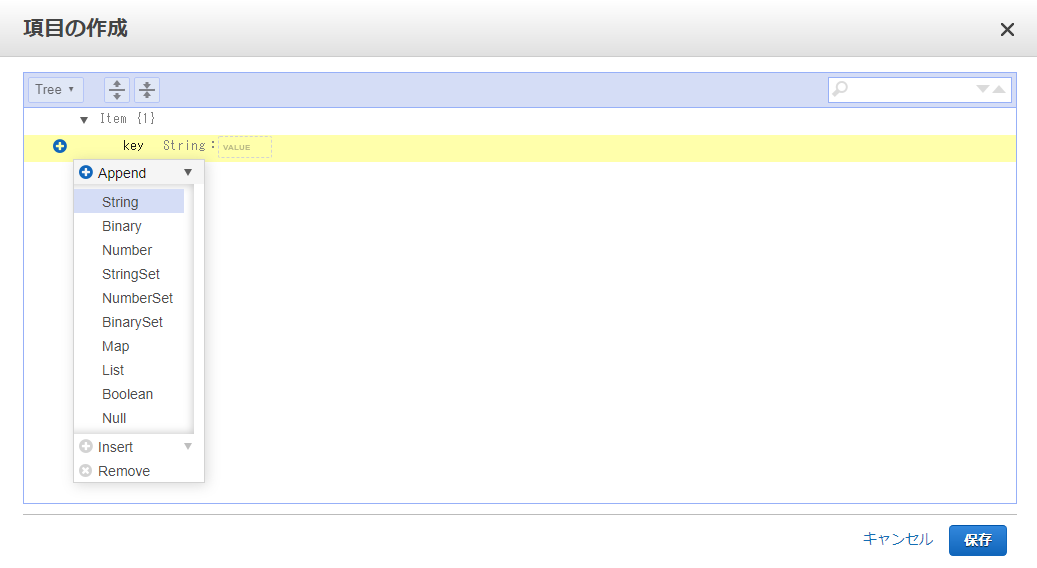
この操作で「項目」に「属性」を追加することが出来る。(=レコードにカラムを追加)
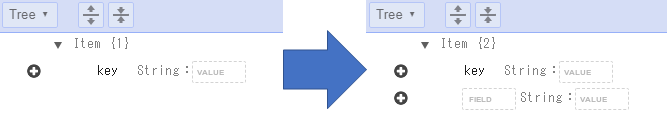
-
「FIELD」に名前を記入し、「VALUE」に値を記入する。
(例ではNumber型の属性をさらに1つ追加し、以下のように記入する。)
-
 ボタンをクリックする。
ボタンをクリックする。
この操作で「項目」の追加を実行するが、DynamoDB Stream有効化と、LambdaでのDynamoDBトリガー設定が前述の手順で行われているため、Lambda関数が呼び出されるはずである。
次の手順では、この項目追加によってLambda関数が呼び出され、追加した値がLambda関数内で使えることを確認していく。 -
Lambdaのページに戻り、「モニタリング」タブをクリックする。

その後、「CloudWatch のログを表示」ボタンをクリック
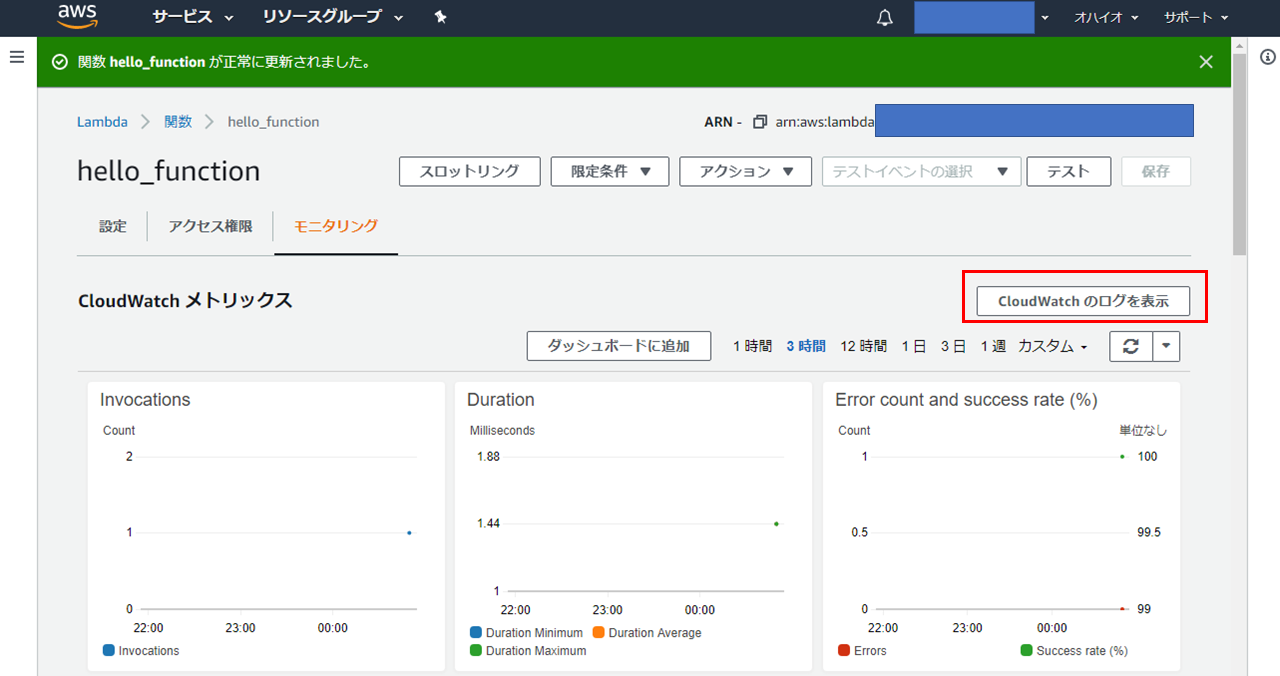
-
下図赤枠部分にログが追加されているはずである。適切な(DynamoDBへの項目追加操作で生成された)リンクをクリックする

-
下図赤枠部分に示すように、Python辞書を文字列化したものが出力されている。当該箇所をクリックすると中身が見れる。
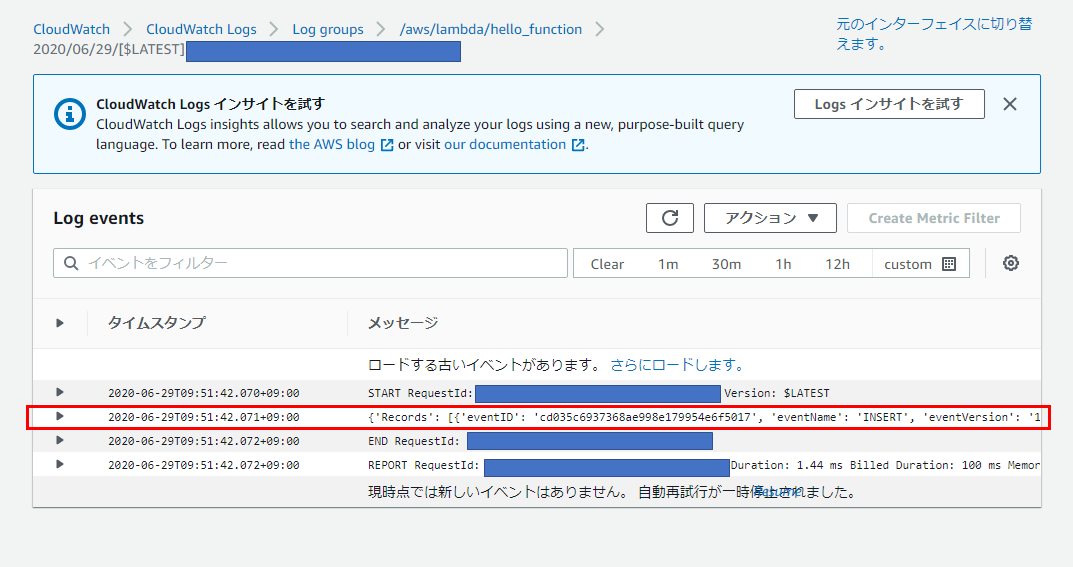
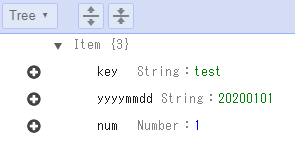
下記のような文字列が出力されているはずである。このデータからDynamoDBの値(例ではyyyymmddとnumの値)を抜き出すことによって、日付に応じて処理を実行したりすることが出来る。
{
'Records': [
{
'eventID': 'cd035c6937368ae998e179954e6f5017',
'eventName': 'INSERT',
'eventVersion': '1.1',
'eventSource': 'aws:dynamodb',
'awsRegion': 'us-east-2',
'dynamodb': {
'ApproximateCreationDateTime': 1593391901,
'Keys': {
'key': {
'S': 'test'
}
},
'NewImage': {
'yyyymmdd': {
'S': '20200101'
},
'num': {
'N': '1'
},
'key': {
'S': 'test'
}
},
'SequenceNumber': '13825400000000001685841274',
'SizeBytes': 35,
'StreamViewType': 'NEW_IMAGE'
},
'eventSourceARN': 'arn:aws:dynamodb:us-east-2:010452415112:table/hello_table/stream/2020-06-28T23:03:03.953'
}
]
}
この中で最低限知っておくべき箇所とその説明を以下に示す。
| 名前 | 説明 |
|---|---|
| eventName | 挿入であれば「INSERT」、更新であれば「MODIFY」となる。 |
| eventSource | DynamoDBがトリガーだった場合「aws:dynamodb」となる。 |
| NewImage | DynamoDBに「挿入」「更新」された場合に、操作後の値が入る。 |
| OldImage | DynamoDBに「削除」「更新」された場合に、操作前の値が入る。 |
イベントを処理する
上記手順により、DynamoDBに挿入した際にLambda関数を自動的に呼び出し、さらに挿入した値を使えることが分かった。
ここでは、イベントのPython辞書から実際に値を取り出す実装と、DynamoDBトリガーであることを確認する実装を行う。
Lambdaコードの例を以下に示す。
def lambda_handler(event, context):
if 'Records' in event:
# Recordsの値はリストなのでループする
for msg in event['Records']:
# DynamoDBからトリガーされたことを確認する
if msg['eventSource'] == 'aws:dynamodb':
# 「dynamodb」には「NewImage」「OldImage」を含む辞書が格納されている。
dynamoevent = msg['dynamodb']
# 「削除」時は処理したくないので、「NewImage」があることを確認する
if 'NewImage' not in dynamoevent:
continue
else:
# 「NewImage」にアクセスし、変更後の「項目」の辞書を取り出す
image = dynamoevent['NewImage']
# 「属性」の名前をkeyとする辞書になっている。
# 以下のコードで「値」を取り出すことができる。
yyyymmdd = list(image['yyyymmdd'].values())[0]
num = list(image['num'].values())[0]
print(yyyymmdd, num)
return {
'statusCode': 200,
'body': 'success'
}
このコードが実行されると、yyyymmdd、numの値がログストリームに出力される。
値を変数に入れることが出来たので、あとは文字列結合してファイル名を生成する等いくらでも応用できる。
LambdaからDynamoDBに値を挿入する
DynamoDBからLambdaを起動できたが、手で項目を追加するのは大変。
ここでは、DynamoDBに挿入する値を自動で生成できるようになるために、LambdaからDynamoDBに値を挿入する実装を行う。
上述のコードに、DynamoDBに挿入するコードを追記したものを以下に示す。
※boto3モジュールをimportしている点にも注目
追記したコードは、eventの辞書に「Records」キーがない場合に、以下のようなのレコードを2件DynamoDBに挿入する。
- key:[タイムスタンプ]_[numの値]
- yyyymmdd:20200101
- num:[数字]
(Lambda関数は、Lambdaのページの「テスト」ボタン等から実行することができる。)
import boto3
from datetime import datetime as dt
def lambda_handler(event, context):
if 'Records' in event:
# Recordsの値はリストなのでループする
for msg in event['Records']:
# DynamoDBからトリガーされたことを確認する
if msg['eventSource'] == 'aws:dynamodb':
# 「dynamodb」には「NewImage」「OldImage」を含む辞書が格納されている。
dynamoevent = msg['dynamodb']
# 「削除」時は処理したくないので、「NewImage」があることを確認する
if 'NewImage' not in dynamoevent:
continue
else:
# 「NewImage」にアクセスし、変更後の「項目」の辞書を取り出す
image = dynamoevent['NewImage']
# 「属性」の名前をkeyとする辞書になっている。
# 以下のコードで「値」を取り出すことができる。
yyyymmdd = list(image['yyyymmdd'].values())[0]
num = list(image['num'].values())[0]
print(yyyymmdd, num)
else:
# keyに入れるタイムスタンプを指定
timestamp = dt.now().isoformat()
data = []
# 試しに2レコード挿入
for j in range(1, 2 + 1):
# keyが被らないようにするために、keyの頭にタイムスタンプの文字列を付与しておく。
rec = {
'key': timestamp + "_{0}".format(j)
,'yyyymmdd':'20200101'
,'num': j
}
# 「属性:値」な辞書が入ったリストを作成する。
data.append(rec)
dynamodb = boto3.resource('dynamodb') #Dynamodbアクセスのためのオブジェクト取得
table = dynamodb.Table("hello_table") #指定テーブルのアクセスオブジェクト取得
for x in data:
table.put_item( #put_item()メソッドで追加・更新レコードを設定
Item=x
)
return {
'statusCode': 200,
'body': 'success'
}
実行すると、DynaomDBに項目が2件増えていることが分かる。

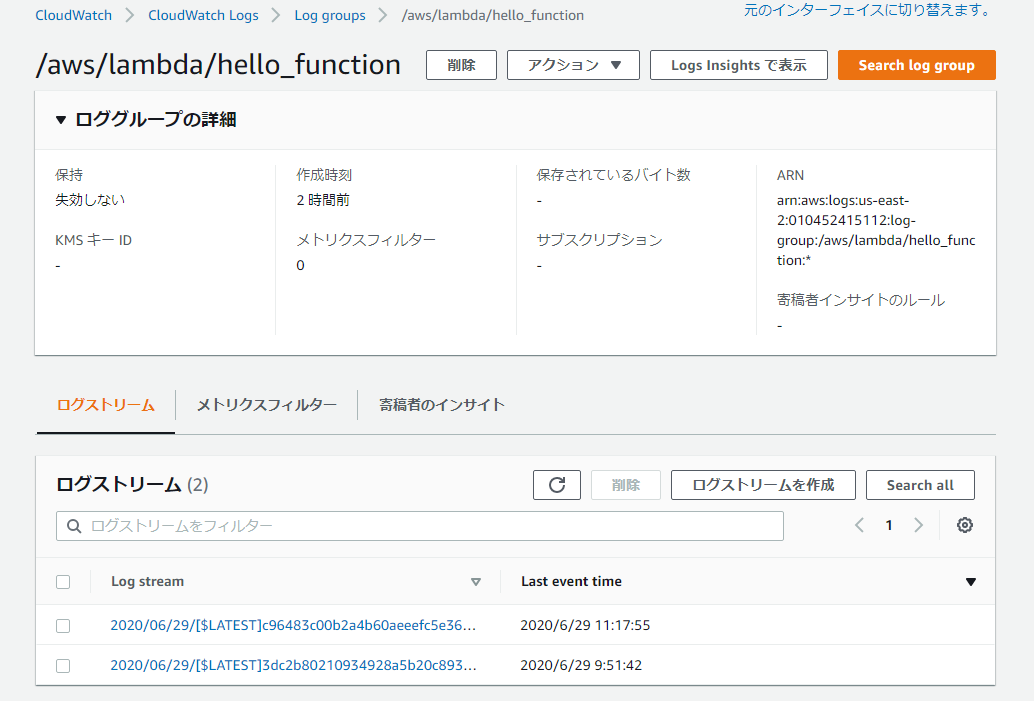
Lambdaが呼び出されていることを確認
CloudWatch ログを確認すると、DynamoDBへの挿入の直後にLambda関数が呼び出され、yyyymmdd、numの値が取得出来ていることが分かる。

日付別の処理を行う
yyyymmddを変えながらLambdaを呼び出す実装を行う。
まず、datetime.timedeltaモジュールをインポートする
from datetime import timedelta
次に、上記コードのelse句を以下のもので置き換え、DynamoDB挿入項目を生成する処理をyyyymmddでループする。
else:
#期間の始点終点を生成
start_org = event['start']
end_org = event['end']
start = dt.strptime(start_org, '%Y%m%d')
end = dt.strptime(end_org, '%Y%m%d')
#対象日付生成
days = [start + timedelta(x) for x in range((end - start).days + 1)]
#keyに入れるタイムスタンプを指定
timestamp = dt.now().isoformat()
data = []
for i, day in enumerate(days):
yyyymmdd = day.strftime('%Y%m%d')
for j in range(1, 2 + 1):
rec = {
'key': timestamp + "_{0}_{1}".format(yyyymmdd, j)
,'yyyymmdd':yyyymmdd
,'num': j
}
data.append(rec)
開始日と終了日を指定するため、以下のように実行時のイベントはstart、endを指定する。
{
"start": "20200101"
,"end": "20200105"
}
この例では、yyyymmddは2020年1月1日~1月5日の日付、numは1~2の数字となる。
これを実行するとDynamoDBには以下のように10件の項目が追加される。
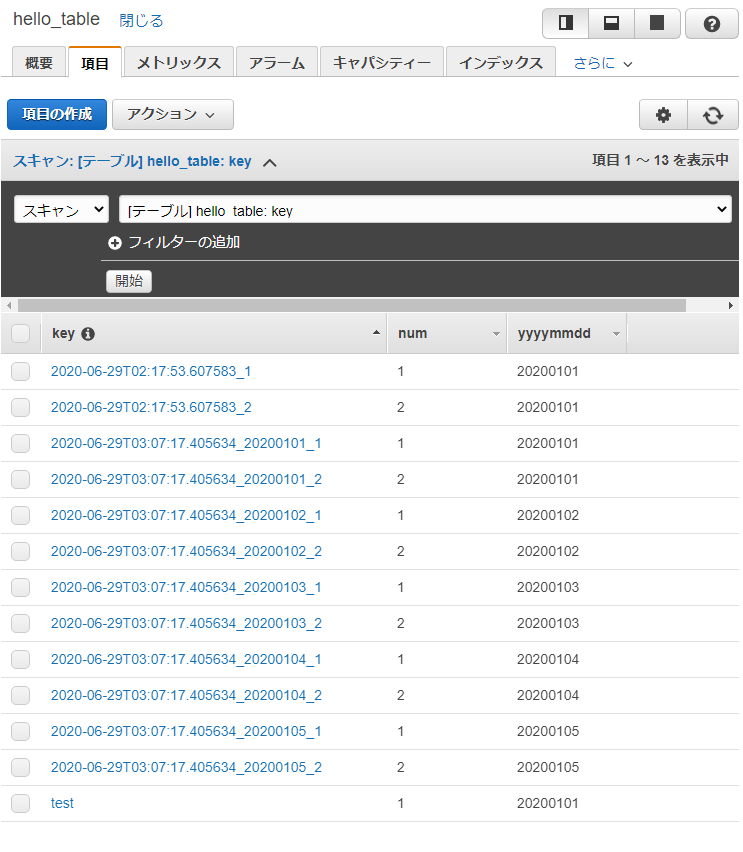
Lambdaのログを確認すると、Lambda関数が2回呼び出され、1回目では20200101-1~20200105-1、2回目では20200105-2の、合わせて10項目分の処理が実行されていることが分かる。

ハマったところ
処理が遅かった・・・!
下図は、1日3000件の項目(yyyymmdd, num)を1か月分DynamoDBに挿入してLambdaを実行した際のCloudWatch メトリクスのグラフである。
※IteratorAgeは、Streamに書き込まれたデータをLambdaが処理しきれない時に大きくなる。
参考:https://aws.amazon.com/jp/premiumsupport/knowledge-center/lambda-iterator-age/
※Concurrent Executionsはその時にLambdaが同時に実行されている数を示す。

①の箇所ではIteratorAgeが上がりっぱなしで、かつ高い数値である一方で、Concurrent executionsが少ない。
これはLambdaの実行数が少なすぎるため処理が追い付かず、Streamに処理待ちが溜まってしまうことにより、処理が始まるまでに時間がかかるレコードが発生したためであると考えられる。
※①の終わり際に残りの処理を中断している
これは、DynamoDBのトリガーの設定で「シャード当たりの実行バッチ」を増やすことで改善できる。
改善後の値は上記グラフの②の箇所であり、Concurrent Executionsが増えたことによって処理が追い付くようになり、IteratorAgeの値が劇的に改善した。
(①は「シャード当たりの実行バッチ」が1の時の結果で、②は10の時の結果である。)
「シャード当たりの実行バッチ」はトリガーの設定画面、下図の赤枠部分にある。
※DynamoDBトリガーの設定はなぜか変更できず、Lambdaのページからトリガーを一旦削除して作成しなおす必要がある。

DynamoDBに項目を追加したのにトリガーされない!?!?
私の時は出力ファイルが一部出力されない状況になりました。
いくつかの状況からDynamoDB Streamの問題であると勘違いしていてハマっていましたが、
Pythonで自分が書いた処理に問題があってエラーが発生していただけでした。
トリガーするためだけにDynamoDBに書き込んだけれど、項目が増え続けるとストレージ料金がかかってしまいそうだな・・・。
テーブル名を指定して全件削除するコードを使いました。
※Lambda等の料金に加え、DynamoDB書き込みキャパシティと書き込み料金が発生します。
[AWS][boto3] DynamoDBテーブルのデータを全削除する。 - Qiita
テーブルを削除→作成でも全件削除できますが、DynamoDB Stream有効化とLambdaへのトリガー追加を都度やり直す必要があります。
まとめ
これで、日付と連番をたくさん入れたDynamoDBからLambdaを呼び出し、任意日付で繰り返しLambdaを呼び出すことが出来ました。