こんにちは、shiibassです。
PvPというとストリートファイターやスプラトゥーン、フォートナイト、ポケモンなどさまざまなジャンルのゲームがあります。どれであってもある程度プレイすると自身のプレイヤースキルの限界を感じて、レーティングの頭打ちに悩まされる経験はあると思います。さらに高みを目指すなら分析→練習→試合→分析・・・のサイクルが私は必要だと考えていて、敗因を分析する方法の一つとしてデータサイエンスがあります。
PvPのデータサイエンス活用事例として、ポーカーやブラックジャックなどのカードゲーム、麻雀やリバーシなどのボードゲームは代表的ですが、計算リソースと最適化するための手法が増えてきたことで最近ではこういうのもあります。
【ぷよぷよ電脳戦】kamestry vs niina(最強AI)
https://www.nicovideo.jp/mylist/38239061
OpenAI vs HUMANS - AI vs 99.95% BEST PLAYERS 5v5 DOTA 2
https://www.youtube.com/watch?v=eaBYhLttETw
たいていのゲームはゲーム内最小単位時間の中で意思決定を繰り返す問題とみなすことができ、それを研究することは自身のプレイヤースキルの向上やオートプレイの開発につながります。こういった問題の計算量としてはゲーム内単位時間あたり選択肢の数だけあるので、全体の計算量としてはとてつもないことになるのは明らかで、どういう課題設定をするか、どういう分析をするかは各自で考える必要があります。そういったことをふまえて、私の研究事例を紹介します。所属している会社とは一切関係ありません。
トレードの最適化
トレードは金融商品を買ったり売ったりすることで資産価値を増やしたり減らしたりできます。大まかなルールとしては、価値は需要供給によって変動すること、自分は買うか売るかの選択をできる、という非常にシンプルでQiita向きのテーマです。投資というと、難しい印象が強いと思いますし実際私もよくわかっていないのですが、アルゴリズムを開発すればプレイできるのはうれしい限りです。社会人になるとぷよぷよや麻雀などの時間を確保できず、できなくなってしまいますがこれなら自分のペースで進められます。とはいえAIファンドや個人投資家も参戦しているので、アルゴリズムだけで勝負するなら企業とも競うことになって生き残るのは容易ではないです。
概要
今回想定した課題は以下のような感じです。
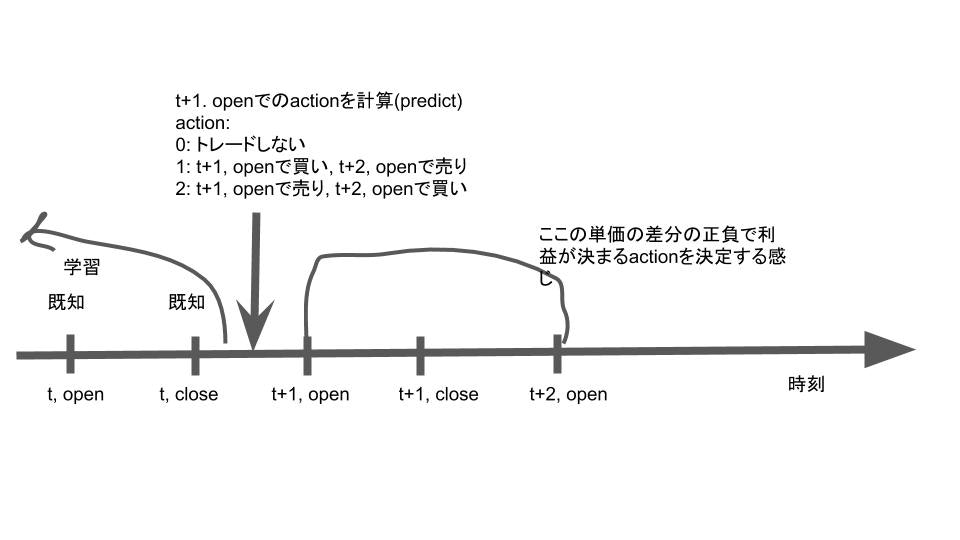
日次トレードを想定し、当日の市場が閉まったら(close)計算バッチを動かし、翌日の寄り(open)での行動を計算します。注意点としては時刻tのcloseと時刻t+1のopenは値が一緒ではありません。なので例えば、$(t.close, t+1.open, t+1.close)=(100,102,101)$と変化したとすると、t.close(既知)からみればt+1.closeは上がっていますが、買いを選択すると102で買うことになるので資産価値は下がります。また、以下の2つを仮定します。
-
zero impact
自身の行動が市場に影響を与えない -
zero slippage
取引しようと思ったらその瞬間にその瞬間の値段で取引が成立する
次に、この記事で出てくるアルゴリズムのフローを記すとこんな感じです。
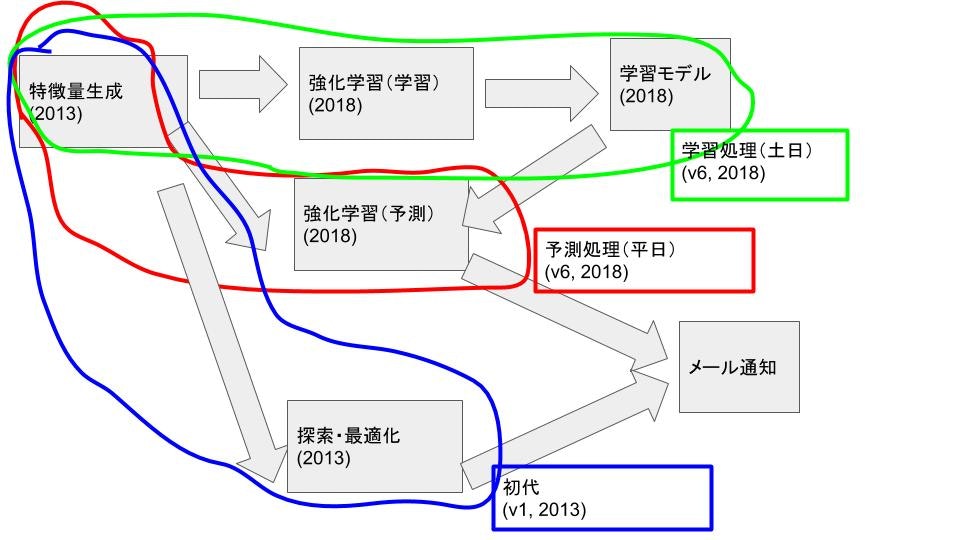
緑で囲ったものが学習バッチで、これは時間的に余裕のある土日に回します。赤で囲ったものが予測バッチで平日の市場が閉まってから計算し、朝メールを確認してその指示に従った行動をとります。自分の意思決定は信頼できないうえに、勝手に判断して失敗するとメンタルを保てなくなりますが、アルゴリズムに全面的に頼ることで自分はアルゴリズム開発に集中しさえすればよくなります。
緑と赤で開発期間は2017/11から2018/03までで、2018/03から2018/10までは実験期間でした。ゴールはv1よりも高火力・高守備力を持った高安定性アルゴリズムを開発することです。
特徴量生成
取得できるデータやそこから生成した指数を特徴量として使っています。トレードでは特徴量の選択肢が多すぎて厳選が必要で、上場銘柄だけで数千種類、使い方によっては為替市場やSNS、ニュースサイトなども使えるかもしれません。選択肢が多いからといってむやみに特徴量を増やしても、全然精度が上がらないということは多々ありました。その理由としては、特徴量同士の相関が高くて(例えば日経平均に連動しすぎる)数を増やしても効果が薄いというのがあると思っています。そこで自分流のくっそダサいアルゴリズムを作って特徴量を生成、探索、選択できる処理をしています。この処理によって少ない特徴ベクトルでそれらが張る空間を広くできて、最適化においては小規模な計算力でも計算可能に、機械学習においては汎化性能の向上を可能にしています。
強化学習
サンプルコードを用意しました。
https://github.com/shiibashi/qiita/tree/development/6
主にgym,keras,keras-rl,tensorflowを使っています。gymの使い方に関しては過去の記事で書いておきました。その他の細かいコードについていくつか記すと、
アクション
self.action_space = gym.spaces.Discrete(1+2*len(self.code_dict)) # stay + {long|short}*n_code
選択できる行動は0: 様子見, 1: 買い, 2: 売り です。サンプルで買うのは日経平均に連動する1銘柄のみですが、増やそうと思えばほかの銘柄を買うことを選択肢に加えたり、通貨を加えるのもありだと思います。寄り以外にも分刻み、秒刻みで行動できるように拡張することもできます。ここで重要なのは制御可能にしておくことで、実現できない選択肢をアクションに加えるのは無意味だということです。自動車の運転がいい例で、人間が操作できるのはハンドルやペダルなどなのでトルクや回転数を変数にしたところで、それを制御できるかどうかはまた別問題です。強化学習は機械学習というよりは制御最適化に近く、最適化の業務では役に立つ手法ではないでしょうか。
リワード
def calc_profit(self, action, time):
# Returns: profit, reward
if action == 0:
return 0, 0
elif action % 2 == 1:
position = 1 # long
elif action % 2 == 0:
position = -1 # short
code_id = int((action + 1) / 2)
code = self.code_dict[str(code_id)]
open_2tomorrow = self.data["{}_open_2tomorrow".format(code)][time]
open_1tomorrow = self.data["{}_open_tomorrow".format(code)][time]
profit = position * (open_2tomorrow - open_1tomorrow) / open_1tomorrow
if profit < 0:
return profit, profit * 1.3255 # 損益にペナルティ
return profit, profit
アクションに対して最適化させる指標を返しますが、利益と報酬を別々にしています。一つ目の返り値は利益そのままで、二つ目は最大化させる報酬で、負の値になったときに1.3255倍しています。これはprofitの絶対値の大きさを無視したときに勝率5.7割以上のときに勝負してくれることを願って設定しました$(0.57 * 1 >= (1- 0.57) * 1.3255)$が効いているかわかりません。他の関数の設定方法としては、以下のように利益に手数料や税金などのフィーを引いても似たような挙動を得られると思います。
profit = position * (open_2tomorrow - open_1tomorrow) / open_1tomorrow
fee_rate = 0.002 # フィー倍率
if profit < 0:
return (1+fee_rate)*profit, (1+fee_rate)*profit
return (1-fee_rate)*profit, (1-fee_rate)*profit
ネットワーク
どうするのがベストなのかわかりませんでした。この項目を実験していて気付いたこととしては、ネットワークを複雑にすると学習データに対しては高い精度は出せるようになったものの、評価データで極端に精度が悪くなる現象が起きていました。調整しながら設定せざるを得なかったですが、いまだにあんまりうまくいっていない箇所です。
def sample_model(self, observation_space):
model = Sequential()
model.add(Flatten(input_shape=(1,) + observation_space.shape))
model.add(Dense(32))
model.add(Activation('relu'))
model.add(BatchNormalization())
model.add(Dense(32))
model.add(Activation('relu'))
model.add(BatchNormalization())
model.add(Dense(env.action_space.n))
model.add(Activation('linear'))
self.model = model
return model
バックテスト
扱っているのは時系列データなので学習データとテストデータは時間軸の矛盾がないように分けてテストします。なのである日の行動はその日以前のデータで学習したモデルで計算した結果になります。
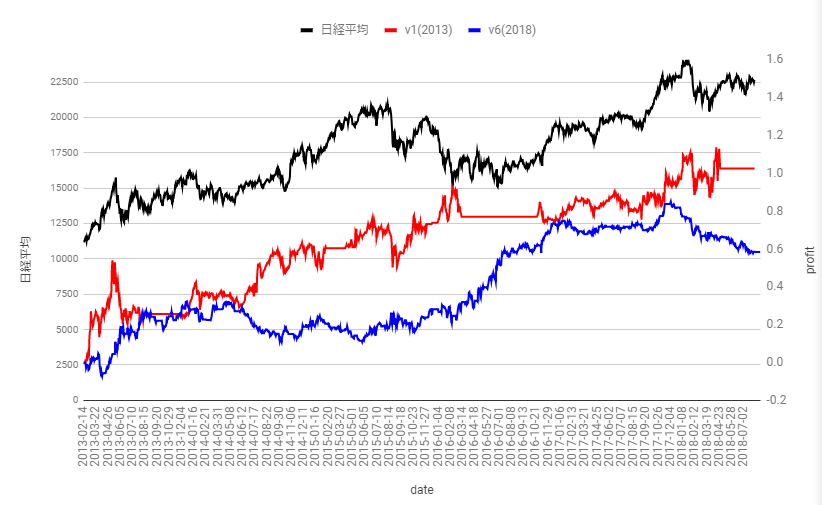
データやパラメータ系の値を本番用にしてバックテストした結果が下図です。2013年以前は学習用データとして扱っています。フィーは0、横軸が日付、黒が日経平均で左縦軸、赤と青がアルゴリズムによる利益$(時刻tの資産/時刻0の資産-1)$の推移で右縦軸を使います。結果としては2013年に作ったv1のアルゴリズム(ただし実運用において人間の意思決定部分があって完成品とは言えない)は1.02です。今年作ったv6は0.58でプラスですが2014年,2015年で利益が下がっているのは許せないので失敗作です。パラメータの最適化ができれば性能を向上できるかもしれないのですが、一回のバックテストで500時間近くかかるため容易ではないというのも失敗の要因でした。
論文紹介
私が読んだ論文の中でおすすめを紹介します。
-
A Deep Reinforcement Learning Framework for the Financial Portfolio Management Problem
https://arxiv.org/pdf/1706.10059.pdf
仮想通貨のポートフォリオ最適化フレームワークを開発したという内容です。github(https://github.com/ZhengyaoJiang/PGPortfolio)
にソースを公開しているのでこれをベースに開発していくのはありです。 -
Cryptocurrency Portfolio Management with Deep Reinforcement Learning
https://arxiv.org/pdf/1612.01277.pdf
仮想通貨トレードの強化学習アルゴリズムを開発したという内容です。数式が比較的少なくて慣れていない人にも読みやすく、バックテストでの利益もすごいのでとりあえずおすすめ。 -
Stock Chart Pattern recognition with Deep Learning
https://arxiv.org/pdf/1808.00418.pdf
ディープラーニングで特定の形状を検出するという内容です。内容的には一番知られているディープラーニングの使い方なので読むのも簡単だと思います。ただし、形状を検出するだけなので、どんな形状を検出するか、それをどう使うかは課題として残ります。
投資関連のアルゴリズムは事例やソースコードなど公開されないことが多く、論文をベースにしたり独自に考えたりしてアルゴリズムを開発する必要があります。論文を理解する・自分の課題に応用する、実装するという3工程は楽ではないですがデータサイエンス業務では確実に役立ちます。
最後に
強化学習を使ったシステムトレードの事例を紹介しました。機械学習を気軽に実行できるようになった昨今では気軽に始められると思いますのでおすすめです。ただし、アルゴリズム主体のプレイスタイルにするなら中途半端な勉強では全く役に立たないのでやるなら本気でやったほうがいいです。