概要
ドワンゴは、定期的に、ニコニコ動画のデータセットを公開した。こちらで公開された情報を見ることができる。
| 前回提供版 | 今回の更新版 | |
|---|---|---|
| 対象期間 | 2007年3月6日-2018年11月8日 | 2007年3月6日-2021年9月30日 |
| 総動画数 | 16,703,325(約1,670万) | 19,712,836(約2,000万) |
| 総コメント数 | 3,773,083,461(約38億) | 4,126,253,731(約41億) |
動画データは、2000万件ある。2000万件であれば、DBに入れられるが、コメント情報は、41億件あるため、BigQueryなどの大規模なデータ集計が得意なものに入れたほうが良いだろう。
今回は、GCPのDataFlowを利用して、BigQueryにニコニコ動画のデータを入れることにする。
結論
- ニコ動画のコメント情報は、41億件あるため、DataFlowなどを用いて、大規模分散システムで入れるのに適している。
- ニコ動のコメント情報は、動画IDがjson内に無く、アーカイブされたファイル名にあるため、そちらを取得してdataflowにデータを入れる。
Dataflowを用いてGCSにおいたzipファイルから、データをロードする。
サンプルコードはこちらにある。
コメントのロードのREADME
ビデオ情報の README
Dataflowはgzファイルをロードすることに向いている。
ニコニコデータセットのコメント情報は次のようになっている。zipファイルの中に、動画IDを含むjsonlファイルが入っており、その中に、コメントをした日付、コメント本文、コマンド、動画上の秒数位置、などが入る。
下記のようなフォーマットになっている。
sm9345107.jsonl
{"date": "2010-01-11T03:53:47+09:00", "content": "0", "command": "184", "vpos": 387, "easy": false, "owner": false}
{"date": "2010-01-11T04:08:03+09:00", "content": "かっけえぇぇぇええ", "command": "184 ue", "vpos": 5254, "easy": false, "owner": false}
{"date": "2010-01-11T04:11:08+09:00", "content": "違和感ないのが笑えるw", "command": "184", "vpos": 10858, "easy": false, "owner": false}
例えばこれが、video_idが含まれた形式でかつ、gzであれば、以下の形式の圧縮ファイルは、
{"video_id":"sm9345107","date": "2010-01-11T03:53:47+09:00", "content": "0", "command": "184", "vpos": 387, "easy": false, "owner": false}
{"video_id":"sm9345107","date": "2010-01-11T04:08:03+09:00", "content": "かっけえぇぇぇええ", "command": "184 ue", "vpos": 5254, "easy": false, "owner": false}
{"video_id":"sm9345107","date": "2010-01-11T04:11:08+09:00", "content": "違和感ないのが笑えるw", "command": "184", "vpos": 10858, "easy": false, "owner": false}
TextIO.Read.from("gs://foo.bar/*gz").withCompressionType(TextIO.CompressionType.GZIP)
で読み出すことができる。
しかし今回は、zipファイルであり、動画IDはjsonlの中ではなく、ファイル名に含まれるため、ファイル名から、動画ID、jsonlの各行からコメントを取得する。
dataflowでzipファイルを読み込む
こちらにサンプルコードがあるが、
Pipeline p = Pipeline.create(options);
PCollection<TableRow> tRows = p.apply(FileIO.match().filepattern(options.getInputFile()))
.apply(FileIO.readMatches().withCompression(Compression.ZIP))
.apply(new ZipToTableRow());
FileIO.match().filepattern("gs://foobar/*.zip) でマッチをして、FileIO.readMatches().withCompression(Compression.ZIP)でzipファイルが取得できる。
それを、
String filename = f.getMetadata().resourceId().toString();
こちらで、0107/sm9345107.jsonl が取得でき、各zipファイル内のファイルは、zipInputStream で取得できる。
ReadableByteChannel readableByteChannel = FileSystems.open(f.getMetadata().resourceId());
ZipInputStream zipInputStream= new ZipInputStream(Channels.newInputStream(readableByteChannel));
ZipEntry zipEntry = null;
while ((zipEntry = zipInputStream.getNextEntry()) != null) {
String zip_names = zipEntry.getName();
BufferedInputStream bis = new BufferedInputStream(zipInputStream);
BufferedReader r = new BufferedReader(new InputStreamReader(bis,"UTF-8"));
r.lines().forEach(json -> {
//各jsonlの中の一行ごとのjsonが取得できる
System.out.println("json"+json);
});
}
その際に、 InputStreamReader(bis,"UTF-8") と UTF-8 を指定しないと文字化けした。
その他の注意点
BigQueryのパーテションテーブルは最大 4000パーテーションなので、デイリーで分割した場合、5000を超えてしまう(2007年から2021年の間なので、5000日を超える)。そのため、パーテーションの分割単位を MONTHLY とした。
new TimePartitioning().setField("created_at").setType("MONTH"))
とすることで、MONTH になる。パーテーションは、170位の分割になる。
動画情報のロード
コメントと違い、動画情報は、jsonl形式で提供される。
細かいやり方は、こちらのREADME.mdにある。
動画タグの件数を調べる。
動画タグは、arrayの方式で入っているため、selectする。このSQLは、MMD を含む年ごとの動画数を調査する。
select format_timestamp("%Y",upload_time,"Japan") as dt,count(1) as cnt
from nico_test.video a
where "MMD" in UNNEST(a.tags)
group by dt
order by dt
MMDタグを含む動画のコメントを抽出する。
with video_info as (
select video_id,
from <your_dataset>.video a
where "MMD" in UNNEST(a.tags)
and date(upload_time,"Japan")=date("2021-01-01")
),
comment_mmd as (
select video_id,content,vpos,created_at
from <your_dataset>.comment
where date(created_at,"Japan")=date("2021-01-01")
)
select a.video_id,created_at,vpos,content
from comment_mmd a
join video_info b
on a.video_id=b.video_id
order by vpos
limit 200
結果のコメント
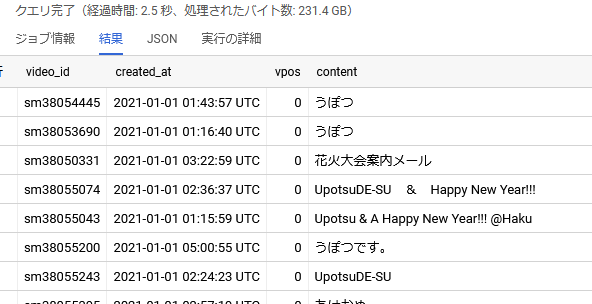
bqに入れたため、複雑な条件の抽出もできる。
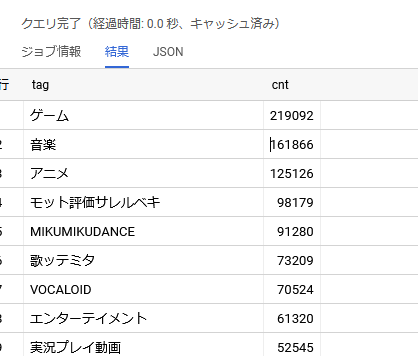
例えば、マイリストが100件以上ある動画に含まれるタグの人気度は次のように求められる。
WITH tag_list AS (
select tag,video_id FROM <foobar>.video,UNNEST(tags) AS tag
where
mylist_num >= 100
group by tag,video_id
)
select tag,count(distinct(video_id)) as cnt
from tag_list
group by tag
order by cnt desc
limit 100
結果