ニコニコデータセット概要
ニコニコデータセットは、ニコニコ動画とニコニコ大百科に関するデータだ。ドワンゴが提供し、NII(国立情報学研究所)で配布している。商用利用の禁止等幾つか制約があるが、基本的にだれでも自由に使えるデータになっている。
含まれているデータは、以下のようになる。
-
ニコニコ動画コメント等データ
- 2012年11月初旬までに投稿された全動画情報を含んでいる
- 動画メタデータ.動画のタイトル、タグ、登録日、再生数、コメント数等のデータ。約800万件
- コメントデータ.コメント本文、登録日、書き込み再生位置などのデータ。約23億コメント
- ちなみに、ユーザーIDの情報は削除されている
-
ニコニコ大百科データ
- 2014年2月までに投稿された全記事(約20万記事)とそれに対する掲示板データを含んでいる
- 記事ヘッダデータ 記事ID,記事タイトル、記事種類、記事作成日のデータ
- 記事本文データ 記事ID,記事本文、記事更新日のデータ
- 掲示板データ 記事ID,レス番号、レス投稿日、レス本文などのデータ
- ちなみに、コメントデータと同じくユーザIDは削除されている。
ニコニコデータセットの入手方法
ニコニコデータセットの入手は、簡単だ。
下記のURLに行き、申請のページからメールアドレスや氏名等を入力すれば、データを取得するページに行ける(ちなみに野生の研究者でもデータを取得できる)。
コメントデータはtar.gzで圧縮されて約50GB程度、大百科のデータはtar.gzで圧縮されて5GB程度あるので、太い回線でダウンロードをおすすめする。
また、複数のファイルに分割されているのでそれ用のダウンローダーを使ったほうが良いだろう。
データコンバートの方法
ニコニコ動画のコメントデータには、smidが含まれていない。jsonデータを含めているファイル名にsmid情報がくっついている。コメントのjsonデータにsmidが含まれないので、そのままではコメント情報が使いにくい。そのため、jsonデータにsmidを含めるスクリプトを書いた。
もともと、hadoop-hiveでの利用を想定しているため、jsonにsmidを含めた跡、hiveのsequenceファイル形式に変換している。下記のURLを参考にしてほしい。
pythonとjavaで書かれていて、pythonを使ってjavaで書かれたjsonにsmidを追加するプログラムを呼び出している。
ニコニコデータセットをhiveに入れる
コメントデータが23億件もあったり、大百科の本文が5GB程度あったりで、そのままgrepなどで、分析を行うのは大変だ。hadoopやbigqueryなどの大規模データの処理に向いたシステムにデータを入れてから分析することになる。hiveにデータを入れる方法を説明する。
先に見たように、コメント情報はjsonで表現されている。しかしhiveやmysqlなどのSQL-likeなデータベースは、表で表現されるので、扱いにくい。そのため、hiveではjson形式にで読み込んだ跡、get_json_objectを使って各カラム用にデータを変更する。
手順としては、一行のstring型としてjsonを読み込み、そのjsonに対してget_json_objectで各カラム向けにデータを吸い出す。
ニコニコデータセットの使い方
先ほどhiveに入れたニコニコデータセットを使って、集計をしてみよう。
例えば、コメントにwwwwwを含む動画はどのような動画多いのか?
sql
select smid,count(*) as cnt from nicodata.comment_data where comment_string like "%wwww%" group by smid order by cnt desc limit 10;
結果
| SMID | コメント数 | タイトル |
|---|---|---|
| sm2555194 | 211422 | ニコニコ動画教科書STEP1【コメント投稿編】 |
| sm8558825 | 129609 | 【何が始まるんです?】 ★おっぱい♂チャーハン★ ぷる~んぷるん! |
| nm9795214 | 62554 | 【マリオ64】カオスに改造してゲームプレイしてみた |
| sm1890440 | 43305 | ハイポーション作ってみた。 |
| sm1010644 | 39224 | ガチで吹いたスレタイ集 その1 |
| nm2579285 | 36824 | wwwwwwwwwwwwww |
| sm1323828 | 30570 | wwwwwwwwwwwwwwwwwwwwwwwwwwwwwwww |
| sm8440787 | 29730 | 【寝下呂企画】magnetを普通に歌ってみたはずだった【ねる×Gero】 |
| sm6188097 | 28502 | 【マリオ64実況】 奴が来る 伍【幕末志士】 |
| sm1553251 | 25813 | amazonの「恋空」のレビューがひどい件 |
と、wwwを多く含んでいる動画を集計できた。
nicodat.infoでらくらく分析
今までニコニコデータセットの利用方法を書いてきたが、もっと手軽に使える方法がある。ニコニコデータセット分析環境というwebサービスを作った。
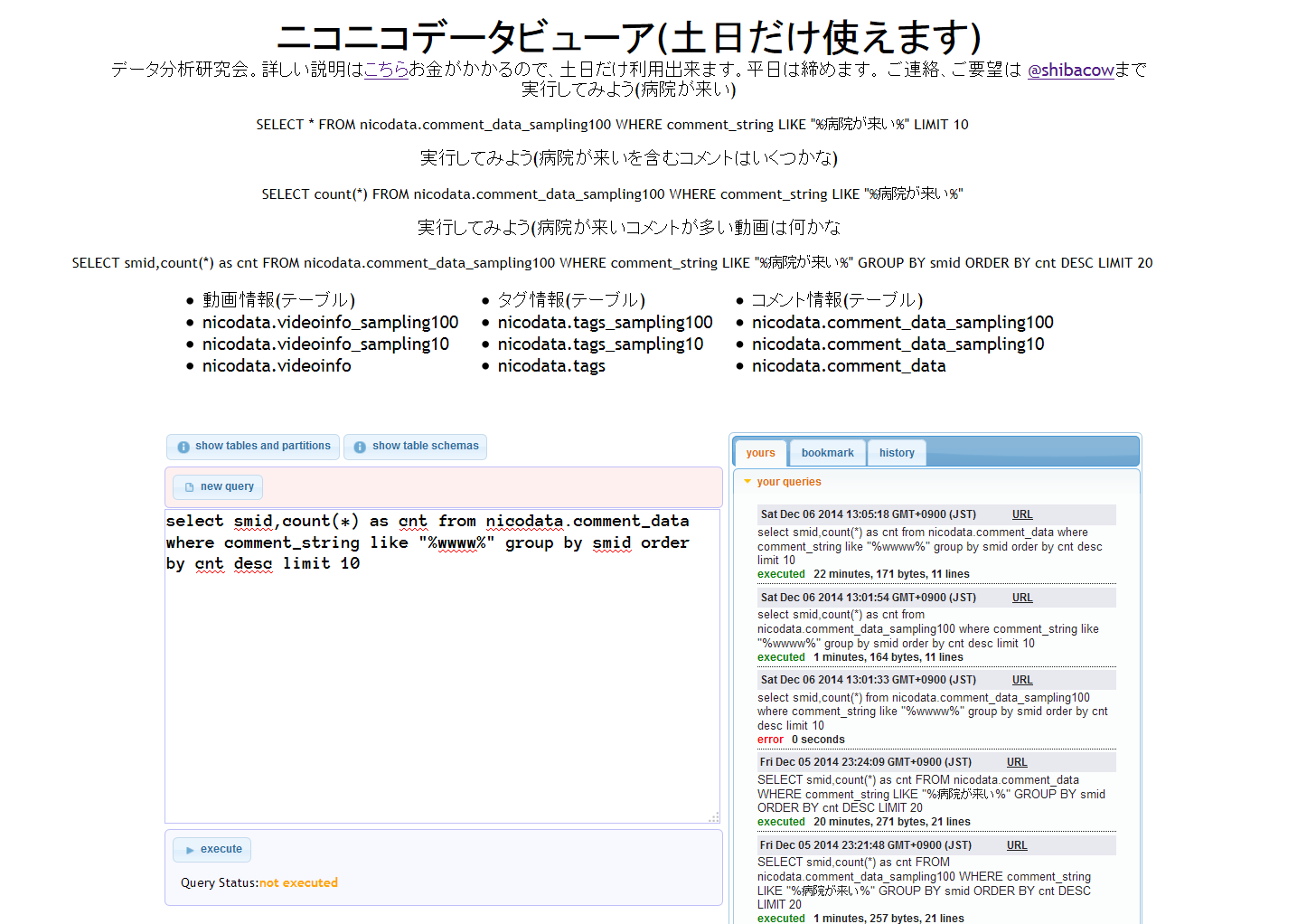
このwebサービスのコンセプトは、煩わしい準備なしに手軽にデータ分析が行えるといったものだ。
利用者は、webからhive用のSQLを打ち込んで実行(execute)すれば良い。そうすれば、集計した結果が帰ってくる。
右のタブのhistoryの項目には、他の人がどのような集計をしたかの例が載っている。参考にしてほしい。簡単だが、作例も載っている。
nicodata.infoの進化
nicodata.infoはサービスを開始して、1年ちょっとが経過した。
当初は手軽に分析できる環境を目指していたが、使っていく内に幾つか不満だ出てきた。
一番大きな不満は、集計のバックエンドで使っているhiveが遅いという点だ。例えば、コメントを集計する際に20分以上かかる。
nicodata.infoの集計時間を早くする試みを進めていたが、その中でGoogleの新しい大規模データ集計環境のGoogle BigQueryを試用する機会があり、試したところ想定より随分集計時間が短かったので、BigQueryへの乗り換えを検討している。
Google BigQueryはGoogleの提供しているデータ分析環境である。他のデータ分析システムと違いケタ違いにマシンを並列化することで集計時間の短縮を図っている。
上の例であるようなhiveで20分かかった集計がBigQueryだと5秒で済む場合がある。圧倒的な早さだ。
おわりに
ビックデータと世間では騒がれているが、掛け声ばかりで、野生の研究者が手軽に扱えてかつ面白いデータはなかなか無いのが実情だ。そうした中、ニコニコデータセットは、21世紀初頭の若者文化を担うものであり、そのコメントデータは将にその若者たちの文化のアーカイブになっている。このような面白いデータを公開してくれたドワンゴに感謝したい。できれば、コメントデータをどんどん公開していってほしい。
また、この文を読んで、ニコニコデータセットに興味をもった方は是非 @shibacowをフォローしてほしい。協力者は常時募集している。
この文章が、読者の皆様のデータ分析の一助に成れば幸いだ。