Cursor で開発した劔“Tsurugi”シンクの性能測定レポート
先日の記事「Cursor による Vector の劔“Tsurugi”シンク開発」では、Vector に対する TsurugiDB 向けシンクコンポーネントを AI 支援で実装した手順を紹介しました。本記事ではその続編として、実装した tsurugidb シンクを実際にベンチマークし、どの程度のスループットが出るのかを計測した結果をまとめます。
実験はあくまで「初期実装を、軽くチューニングした段階」でのスナップショットであり、最適化済みの値ではありません。どの条件で頭打ちになるか、どこから列数増大の影響が効いてくるか、といった挙動の傾向を把握することを目的にしています。
測定環境
-
クラウド環境: AWS
c5d.24xlarge- vCPU: 96 / メモリ: 192 GiB / NVMe 一時 SSD
- OS: Ubuntu 24.04
- TsurugiDB: 1.7.0
- Vector: 0.52.0
-
測定スクリプト:
src/sinks/tsurugidb/measure/run_measurements.py -
測定計画:
src/sinks/tsurugidb/measure/plan.md準拠 -
制約:
- 計測時間はすべて 10 秒
- 想定イベントレートは最大 100,000 events/sec まで
(plan.md上は 120 秒 / 200k events/sec なども想定しているが、本稿の測定では簡略版)
測定シナリオ
plan.md に定義したシナリオのうち、今回実際に走らせたのは以下です。
-
ベースライン (5.1)
-
baseline_cols1_p1_r10k- 列数: 1 列
- Vector 並列数 (
in_flight_limit): 1 - 想定イベントレート: 10,000 events/sec
- 計測時間: 10 秒
-
-
イベント発生速度スケーリング (5.2)
- 対象テーブル: 10 列 (
log_events_10) - Vector 並列数: 4
- 想定イベントレート: 100 / 1,000 / 10,000 events/sec
- 対象テーブル: 10 列 (
-
Vector 並列数スケーリング (5.3)
- 対象テーブル: 10 列 (
log_events_10) - 想定イベントレート: 100,000 events/sec
- Vector 並列数: 4 / 8 / 16 / 32
- 対象テーブル: 10 列 (
-
列数スケーリング (5.4)
- 想定イベントレート: 100,000 events/sec
- Vector 並列数: 4
- 列数: 1 / 10 / 100 列
測定結果
以下は測定結果です。
| シナリオ | 列数 | 想定レート_events_per_sec | 並列度 | 計測時間_sec | 送信件数 | 実測時間_sec | 実効レート_events_per_sec | ステータス |
|---|---|---|---|---|---|---|---|---|
| baseline_cols1_p1_r10k | 1 | 10000 | 1 | 10 | 100000 | 25.02 | 3997 | ok |
| rate_scaling_cols10_p4_r100 | 10 | 100 | 4 | 10 | 1000 | 10.08 | 99 | ok |
| rate_scaling_cols10_p4_r1000 | 10 | 1000 | 4 | 10 | 10000 | 10.32 | 969 | ok |
| rate_scaling_cols10_p4_r10000 | 10 | 10000 | 4 | 10 | 100000 | 32.97 | 3033 | ok |
| parallel_scaling_cols10_p4_r100000 | 10 | 100000 | 4 | 10 | 100000 | 30.26 | 3305 | ok |
| parallel_scaling_cols10_p8_r100000 | 10 | 100000 | 8 | 10 | 100000 | 27.75 | 3604 | ok |
| parallel_scaling_cols10_p16_r100000 | 10 | 100000 | 16 | 10 | 100000 | 30.20 | 3311 | ok |
| parallel_scaling_cols10_p32_r100000 | 10 | 100000 | 32 | 10 | 100000 | 30.57 | 3272 | ok |
| column_scaling_cols1_p4_r100000 | 1 | 100000 | 4 | 10 | 100000 | 27.29 | 3664 | ok |
| column_scaling_cols10_p4_r100000 | 10 | 100000 | 4 | 10 | 100000 | 29.64 | 3374 | ok |
| column_scaling_cols100_p4_r100000 | 100 | 100000 | 4 | 10 | 100000 | 63.43 | 1576 | ok |
観点別の結果と考察
ベースライン (1 列, 並列 1)
- 想定レート: 10,000 events/sec
- 実効レート: 約 4,000 events/sec
ベースライン用のシンプルな 1 列テーブルに対して、並列度 1・短時間 10 秒で計測したところ、スクリプト側のレート制御やスケジューラの影響もあり、目標値に対してやや低めのレートで投入されました。
機能および安定性の確認という観点では問題なく、TsurugiDB への書き込みがエラーなく完了することを確認できています。
イベントレート増加によるスケーリング (列数 10, 並列 4)
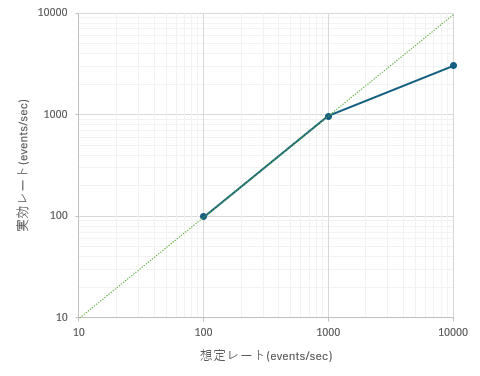
- 想定レート 100 / 1,000 events/sec では、ほぼ目標どおりのレートが達成できています。
- 想定レート 10,000 events/sec では、実効レートは約 3,000 events/sec 程度で頭打ちになります。
- この構成(10 列・並列 4)では、おおよそ 3,000 events/sec 付近が実効上限とみなせます。
Vector 並列度のスケーリング (列数 10, レート 100,000)
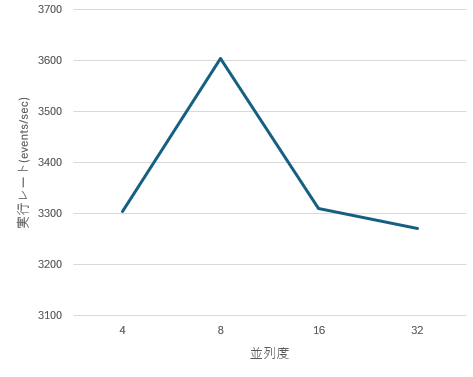
- 並列度 4 → 8 に増やすと、実効レートは約 3,305 → 3,604 events/sec とわずかに向上します。
- それ以上(16, 32)に増やしても、スループットはほぼ横ばいで、3,300 events/sec 付近から伸びません。
- このことから、今回の条件では
-
in_flight_limitを 8 程度までは増やす価値があるものの、 - それ以上は Vector 内部処理または Tsurugi 側処理のボトルネックにより、並列度を増やしてもスケールしない 状態になっていると推測できます。
-
列数スケーリング (列数 1 / 10 / 100, 並列 4, レート 100,000)
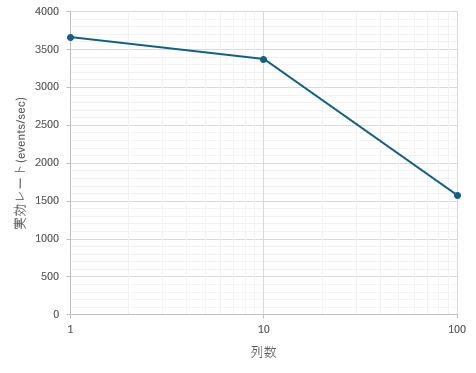
- 1 列: 約 3,665 events/sec
- 10 列: 約 3,374 events/sec
- 100 列: 約 1,576 events/sec
傾向としては:
- 1 列 → 10 列への増加では、スループット低下は 約 8% 減 にとどまり、10 列程度までは列数の影響は小さいと言えます。
- 一方、100 列ではスループットが約半分以下に低下しており、
- 1 イベントあたりのペイロード増大
- JSON シリアライズや SQL 生成コスト
- TsurugiDB 側の INSERT 処理負荷
など、列数増大によるコストが顕在化していると考えられます。
まとめ
今回の環境(AWS c5d.24xlarge / Ubuntu 24.04 / TsurugiDB 1.7.0 / Vector 0.52.0)と単一 Vector プロセスの構成において、初期状態の tsurugidb シンクは以下のような特性を示しました。
- 列数 10 / 並列 4〜8 の構成では、おおよそ 3,000〜3,600 events/sec 程度で安定して書き込み可能。
- 列数 100 では 1,600 events/sec 前後 に低下し、カラム数増大の影響が明確に表れる。
-
in_flight_limitを 8 以上に増やしてもスループットはほぼ伸びず、単純な並列度拡大では超えられないボトルネックが存在する。
今後の検討ポイント
本記事の結果は「素の設定+短時間試験」によるものなので、実運用レベルで使うには以下のような追加検証が必要です。
-
バッチ・トランザクション設定のチューニング
batchサイズ、transaction_type(OCC / LTX)、request.in_flight_limit、retry_*系パラメータを系統的に変え、スループットとレイテンシのトレードオフを確認する。 -
高レート・長時間試験
100,000 events/sec 以上、数分〜数時間の連続書き込みによる CPU・メモリ・I/O 使用率や、エラー率・バックプレッシャー発生状況を観測する。 -
より現実的なスキーマでの評価
DOUBLE 以外の型を含むスキーマや、100 列を超える複雑なイベントスキーマなど、実運用に近い条件で列数スケーリングの影響を再評価する。 -
プロファイリングによるボトルネック特定
-
Vector プロセス側:
CSV パース、JSON 変換、バッチング処理 -
Tsurugi クライアント (
tsubakuro) 側:
セッション管理、トランザクション開始/コミット -
Tsurugi サーバ側:
ロック・トランザクション処理などをプロファイルし、どのレイヤーがスループットを支配しているかを明確にする。
-
Vector プロセス側:
現時点でも、数千 events/sec クラスの書き込み負荷に対しては安定して動作することが確認できました。
一方で、10 万 events/sec クラス以上の高負荷を単一パイプラインで処理するには、設定チューニングだけでなく、パイプライン分割や複数 Vector インスタンス併用といったアーキテクチャ設計が必要になると考えています。