昨今画像生成AIの新しい技術が次々と出てきており、より想定に近い形の画像が生成しやすくなっています。
今回は画像生成AIの仕組みを理解するため、昨年流行した画像生成技術のルーツとも言われるGANについて調べました。
GANとは?
- GAN(Generative Adversarial Network / 敵対的生成ネットワーク)
- Generator と Discriminator の2つのネットワーク構造により成り立っている
- Generator: ランダムなノイズから偽データを生成する。より本物データに近いデータを生成できるよう学習する
- Discriminator: 偽データと本物データを判別できるよう学習する
- Generator と Discriminator をそれぞれ競わせるようにして学習させるため敵対的生成ネットワークと呼ばれる
- 特徴の定量化ができるため、特定のデータに対する特徴の足し引きが可能
- Generator と Discriminator の2つのネットワーク構造により成り立っている
GANの派生手法
- DCGAN(Deep Convolutional GAN)
- Discriminator で畳み込み層(画像からベクトルに落とし込む)を使用(GANは全結合層使用)
- Generator で転置畳み込み層(ベクトルから画像を生成する)を使用
- GANよりも自然な画像生成が可能
- LSGAN (Least Square GAN)
- GANと比べて学習が安定、高品質な画像生成が可能
- 恒等関数と平均二乗誤差を使用(GANはシグモイド関数と二値交差エントロピー)
- GANはxの値が大きくなると学習がうまく進まなくなる弱点あり。LSGANはそこを改善
GAN自体は2014年に発表されたアルゴリズムで、現在では他にもCycleGAN, StyleGAN, PGGAN, ACGANなど数百種類の派生があるようです。
以下は基本的なGANについての説明になります。
GANの仕組み
Generator: 偽データを生成する
↓
Discriminator: 偽データと本物データを判別できるよう学習
1. 本物のデータを入力。正解は1
2. 判定結果と正解の値の誤差を算出
3. パラメータの更新を行う
4. 偽物のデータを入力。正解は0
5. 判定結果と正解の値の誤差を算出
6. パラメータの更新を行う
↓
Generator: 偽データのDiscriminatorでの判別結果が「本物」となるよう学習
1. ランダムノイズを入力
2. 偽画像データを出力
3. Discriminatorの判定結果と正解の値の誤差を算出。偽データを本物と誤認させたいため正解は1
4. Generatorのみパラメータの更新を行う
GANを用いて手書き数字を生成する
Google Colaboratoryで実際にコードを書いて動きを確認しました。
(Python自体不慣れなため自分用メモも兼ねて細かく説明を入れていきます)
https://colab.research.google.com/
まず、画像処理を行うため「ランタイム > ランタイムのタイプを変更」で「GPU」を選択します。

コードセルを追加し、必要なプラグインを読み込みます。
import matplotlib.pyplot as plt # 画像表示に使用
import numpy as np # 行列計算に使用
from keras.datasets import mnist # 手書き数字データセット
from keras.layers import Dense, Flatten, Reshape, LeakyReLU # Dense: 全結合, Flatten: 平坦化, Reshape: 画像のシェイプに戻す, LeakyReLU:活性化関数。0以下も切り捨てない
from keras.models import Sequential # 線形モデル。分岐しないため扱いやすい
- matplotlib: Python用描画ライブラリ
- pyplot: グラフ生成用モジュール
- numpy: 数値計算を効率的に行うためのライブラリ
- Keras: オープンソースニューラルネットワークライブラリ
- mnist: 手書き数字を白黒画像にしたデータセット
- Dense: 全結合層を表現できるクラス
- 全結合層: 全てのノードを結合する層
- Flatten: 平坦化層を表現できるクラス
- 平坦化層: 入力画像を全て1次元配列に変換して出力する層
- Reshape: 入力を指定された形状に再形成できるクラス
- LeakyReLU: 活性化関数。次のノードに伝える情報を調整する役割。0以下も切り捨てない
- Sequential: ニューラルネットワークの各層を積み重ねたモデル
img_shape = (28, 28, 1) # サイズ:28x28、色:1次元(白黒)
z_dim = 100 # ランダムノイズの次元数
Generatorモデルを生成する関数を用意します。
# Generator 偽画像データを生成するモデル
def build_generator(img_shape, z_dim):
model = Sequential() # 空のモデル
model.add(Dense(128, input_dim = z_dim)) # 全結合
model.add(LeakyReLU(alpha=0.01)) # 活性
model.add(Dense(28*28*1, activation="tanh")) # 活性化関数tanh: -1から1の間にマッピングし直して出力する
model.add(Reshape(img_shape)) # 画像の形にする
return model
Discriminatorモデルを生成する関数を用意します。
# Discriminator 画像真偽判別をするモデル
def build_discriminator(img_shape):
model = Sequential() # 空のモデル
model.add(Flatten(input_shape=img_shape)) # 全結合層に入力するため1次元にする
model.add(Dense(128)) # 全結合
model.add(LeakyReLU(alpha=0.01)) # 活性
model.add(Dense(1,activation="sigmoid")) # 本物か偽物か判別のため2値分類。活性化関数sigmoid: 0から1の間にマッピングし直して出力するため2値分類に適している
return model
GANモデルを生成する関数を用意します。
# GAN 画像生成トレーニングをするモデル
def build_gan(generator,discriminator):
model = Sequential() # 空のモデル
model.add(generator) # Generatorで偽画像生成
model.add(discriminator) # Discriminatorで画像が本物か判別
return model
Discriminator と Generator それぞれの学習を行います。
discriminator = build_discriminator(img_shape) # Discriminatorモデルを生成
discriminator.compile( # モデルのコンパイル
loss = "binary_crossentropy", # 損失関数 二値交差エントロピー。2値分類に適している
optimizer = "adam", # 1度にどの程度重み(判断基準の係数)を変えるかの方法
metrics = ["accuracy"]
)
discriminator.trainable = False # GeneratorとDiscriminator連結時にDiscriminatorが学習しないようにする
generator = build_generator(img_shape, z_dim) # Generatorモデルを生成
gan = build_gan(generator, discriminator) # GANモデルを生成
gan.compile( # モデルのコンパイル
loss = "binary_crossentropy", # 損失関数 二値交差エントロピー。2値分類に適している
optimizer = "adam", # 1度にどの程度重み(判断基準の係数)を変えるかの方法
)
- 損失関数: 損失値(正解値と予測値とのズレ)を計算するための関数
- 交差エントロピー: 2つの確率分布が似ているほど値が0に近くなる。モデルを最適化する→交差エントロピー誤差を最小にする
- optimizer: 最適化手法。適切な重み(勾配が0となる地点)を求める方法
- adam(Adaptive Moment Estimation): 最適化手法の1つ。Momentum と Adagrad を融合させた手法
- Momentum: 勾配を記憶する
- Adagrad: 勾配の二乗を記憶する
mnistデータセットの画像読み込み、ラベルの作成をします。
batch_size = 128
(X_train,_),(_,_) = mnist.load_data() # mnistの画像を読み込む。(訓練用データ,訓練用ラベル),(テストデータ,テストラベル)の構成。X_train(訓練用データ)だけ使用する
X_train = X_train/127.5-1.0 # 結果が0-1の範囲になるようにする
X_train = np.expand_dims(X_train, axis=3) # 3次元目を追加
# ラベル作成
real = np.ones((batch_size, 1)) # 正解時のラベル
fake = np.zeros((batch_size, 1)) # 不正解時のラベル
トレーニングを行い、結果を出力していきます。
for i in range(10000): # 1周でDiscriminator, Generatorそれぞれの学習をする。エポック数分繰り返し学習
idx = np.random.randint(0,X_train.shape[0],batch_size) # 本物データの中からランダムにデータを抜き出す
imgs = X_train[idx] # ピックアップしたデータをimgsに入れる
z = np.random.normal(0,1,(batch_size, 100)) # ランダムノイズ。バッチサイズ分だけ作る
fake_imgs = generator.predict(z) # Generatorで偽画像データを生成
# Discriminator側の学習。片方ずつ学習するためtrain_on_batch使用
discriminator.train_on_batch(imgs,real) # 本物画像。ラベルreal
discriminator.train_on_batch(fake_imgs,fake) # 偽画像。ラベルfake
# Generator側の学習
gan.train_on_batch(z,real) # 偽物画像もラベルはreal。見破れなかった時を損失として扱う
# 500回に1回画像出力
if i%500 == 0:
rows = 5
columns = 5
noise = np.random.normal(0,1,(rows*columns,z_dim))
sample_img = generator.predict(noise)
sample_img = sample_img * 0.5 + 0.5
fig, axes = plt.subplots(rows,columns,figsize=(5, 5),sharey=True,sharex=True) # 5x5サイズの描画領域を生成
fig.suptitle(i+500,x=0.5,y=0.92) # 描画領域のタイトル、タイトル表示座標を指定
for row in range(rows):
for column in range(columns):
axes[row, column].imshow(sample_img[column,:,:,0], cmap="gray") # 描画領域に生成画像を出力
axes[row, column].axis("off") # 座標は表示しない
出力結果
エポック1000辺りまではほとんどただのノイズ画像のような状態です。


徐々に「0」に近い形が浮かび上がり始めました。

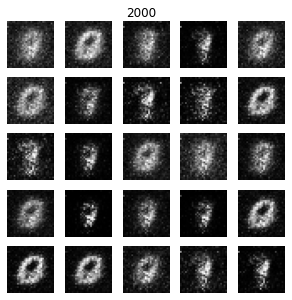
「0」「3」「9」に見える画像が生成されるようになりました。


(省略)
「1」「4」「7」「8」に見える画像の生成も確認できます。



(省略)
今回はとりあえずエポック数10000としましたが、はっきりと数字に見える画像もあれば数字に見えない画像もあります。
5,6000辺りから大幅な精度向上はしていないように感じるので、もう少し手前で学習を止めても良さそうです。





