はじめに
- 仕事柄、オンプレミス/クラウドに関わらずITインフラに関わる方々とお話をする機会が多くあります。
- 最近そのような方々のお話を聞いていると、ITインフラのコスト増加が課題となっているケースが多く、中には経営層から現場に対してITコストの改善を求められているといった声も聞こえてきます。
- 前々回の記事でクラウドコストを最適化するための考え方である「FinOps」ついて調べ、前回の記事でFinOpsの最初のフェーズである「可視化」について考えてみたので、今回は「ITインフラのコストを最適化したい」シリーズの最終回として実際に可視化してみます。
- 今回は、私が所属するNetAppが提供している「Cloud Insights」というインフラ可視化サービスが手元にあったので、それを使ってみました。
NetApp Cloud Insightsとは:ハイブリッドクラウドインフラの統合可視化サービス
- 今回使うツールであるCloud Insightsについて、簡単にご紹介します。
- Cloud Insightsは、ハードウェア、ハイパーバイザー、OS、コンテナ、ミドルウェア、パブリッククラウドなどのマルチベンダーの幅広いレイヤーの製品・サービスのメトリクスを統合的に収集して可視化することができるSaaS型のサービスです。収集対象のリストはこちら。
- ちなみに、情報を収集するだけではなく、VMとスイッチ、ストレージなどの各レイヤーのリソースの関連性の紐づけを自動で行ってくれたり、ストレージに対する異常アクセスを検知してランサムウェア攻撃等からの被害を最小化したりするセキュリティ関連の機能も備わっています。
- こちらでパブリッククラウド(今回はAWSのAmazon EC2とAmazon EBSの環境)とオンプレミス(今回はVMware vSphereの環境)を可視化してみます。
パブリッククラウドの可視化
無駄なコストの垂れ流しを可視化
- パブリッククラウドのコストで最も無駄なものといえば、消し忘れている不要なリソースですよね。無駄・オブ・ザ・無駄、まさに無駄の極みです。
- というわけで、手っ取り早くコスト改善が可能な「消し忘れている不要なリソース」を可視化してみます。
ダッシュボードの例
- Cloud Insightsでは好きなようにダッシュボードを作ることができるので、Amazon EC2/Amazon EBSの無駄の可視化に特化したダッシュボードを作ってみました。
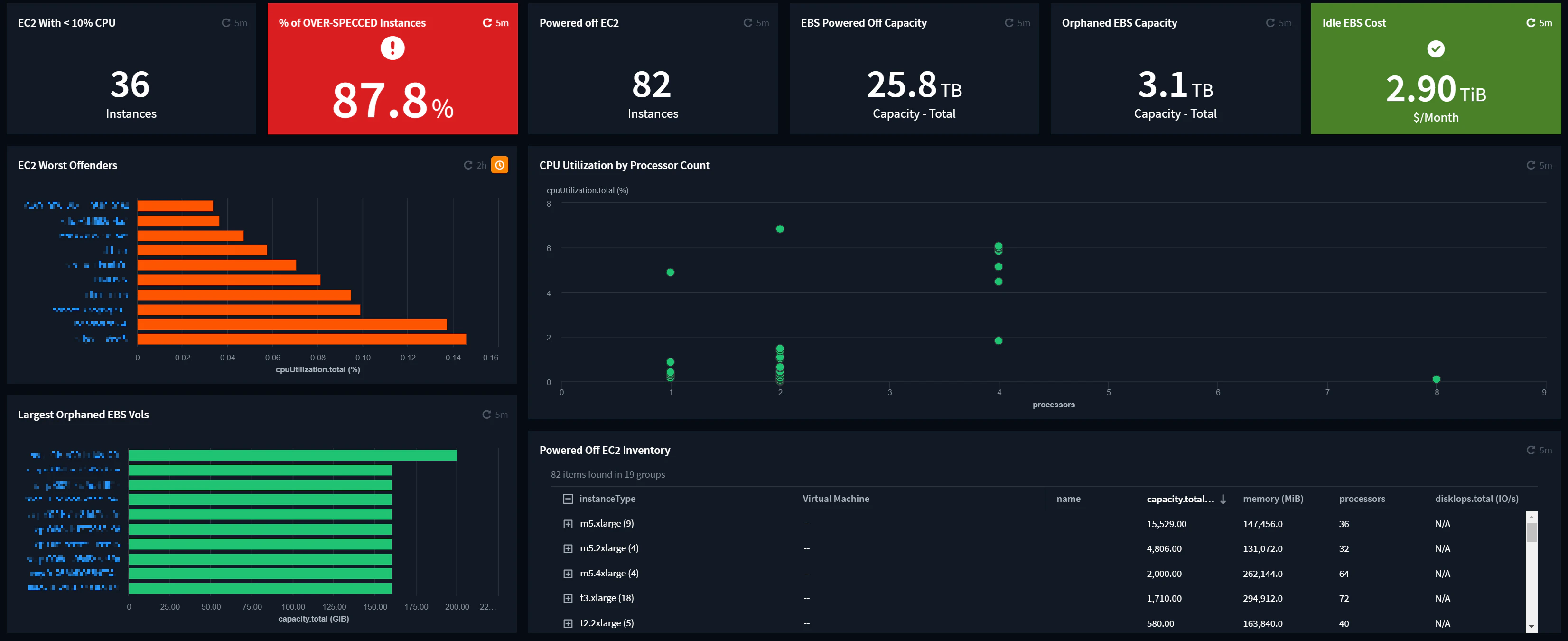
停止中のEC2インスタンス台数
- ダッシュボード最上部の真ん中あたりの「Powered off EC2」という項目では、82台のEC2インスタンスが停止していることがわかります。これ、全て残しておく必要はあるでしょうか?
停止しているEC2インスタンスにアタッチされているEBSボリュームのサイズ
- その右隣の「EBS Powered off Capacity」という項目では、その停止しているEC2インスタンスにアタッチされているEBSボリュームのサイズが25.8TBあることがわかります。これが垂れ流され続けるとコストへの影響はそこそこ大きいですね。

どのEC2インスタンスにもアタッチされていないEBSボリュームのサイズ
- さらにその右隣の「Orphaned EBS Capacity」では、どのEC2インスタンスにもアタッチされていないEBSボリュームのサイズが3.1TBもあることがわかります。これはかなりの高確率でEC2インスタンスの削除と同時にEBSボリュームの削除ができていなかったパターンの消し忘れですね。あるあるです。

無駄なリソース一覧を表示
- 上記のEC2インスタンスの台数やEBSボリュームのサイズの数字をクリックすると、そのEC2インスタンスやEBSボリュームの一覧が表示されるので、その中で削除してもよいものを見つけて削除するだけで無駄なコストの垂れ流しを防止することができます。

その他の項目
- その他、CPU使用率が10%以下のEC2インスタンス一覧(「EC2 With<10% CPU」)や、EC2インスタンスのCPU使用率ワースト10(「EC2 Worst Offenders」)、何にもアタッチされていないEBSボリュームのサイズトップ10(「Largest Orphaned EBS Vols」)などもこのダッシュボードで確認することができます。
誰が何をどれくらい使っているを可視化
- そして、「誰が何をどれくらい使っているか」というのも重要なポイントでしたので、こちらも可視化してみます。
ダッシュボードの例
- ユーザー毎の使用量にフォーカスしたダッシュボードを作ってみました。
- これは、「Annotation」というCloud Insightsの機能を使っています。AWSでいう「タグ」のようなもので、各リソースにメタ情報を付加して、Annotation毎にメトリクスを集計したり分類したりすることができます。

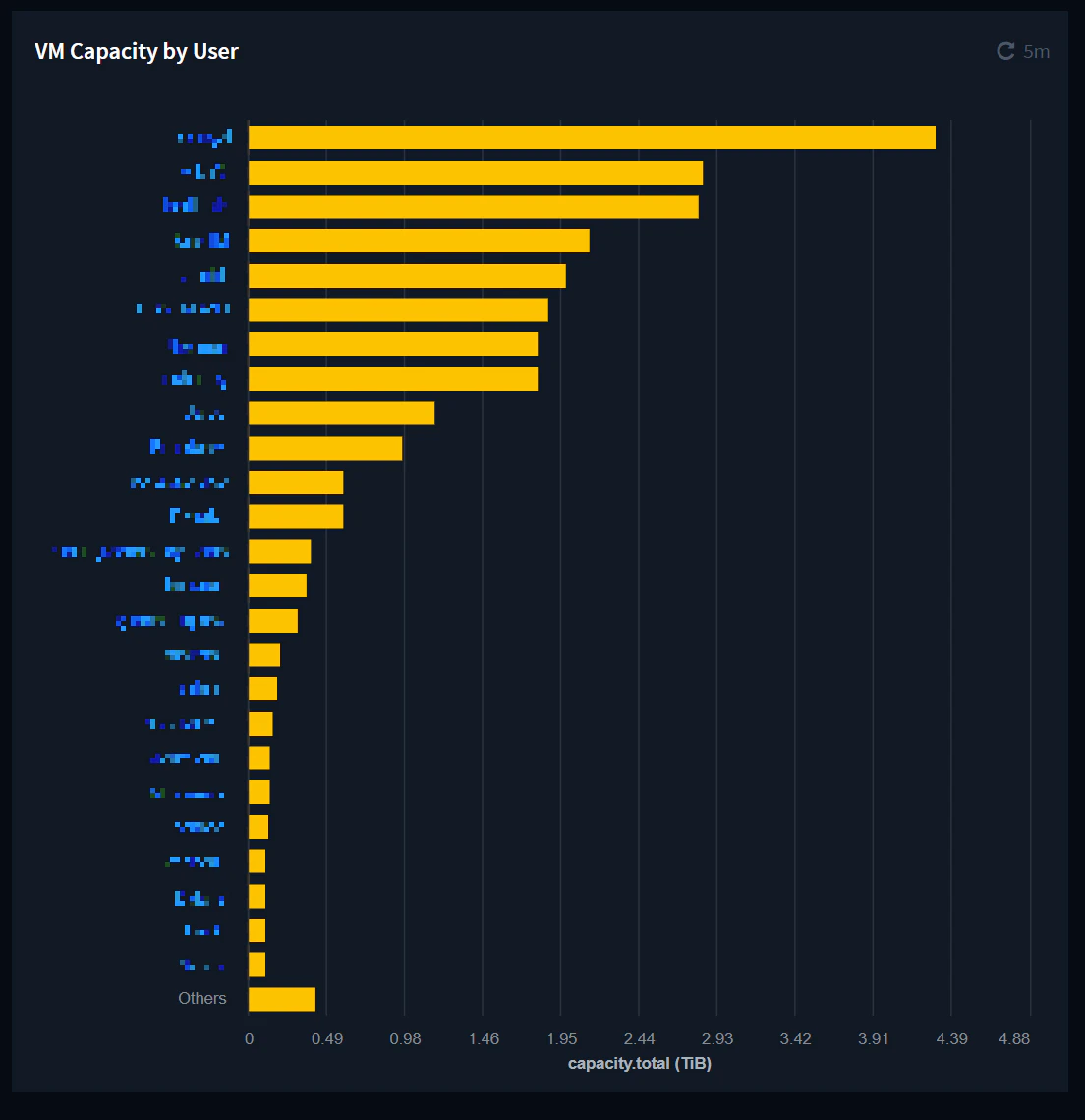
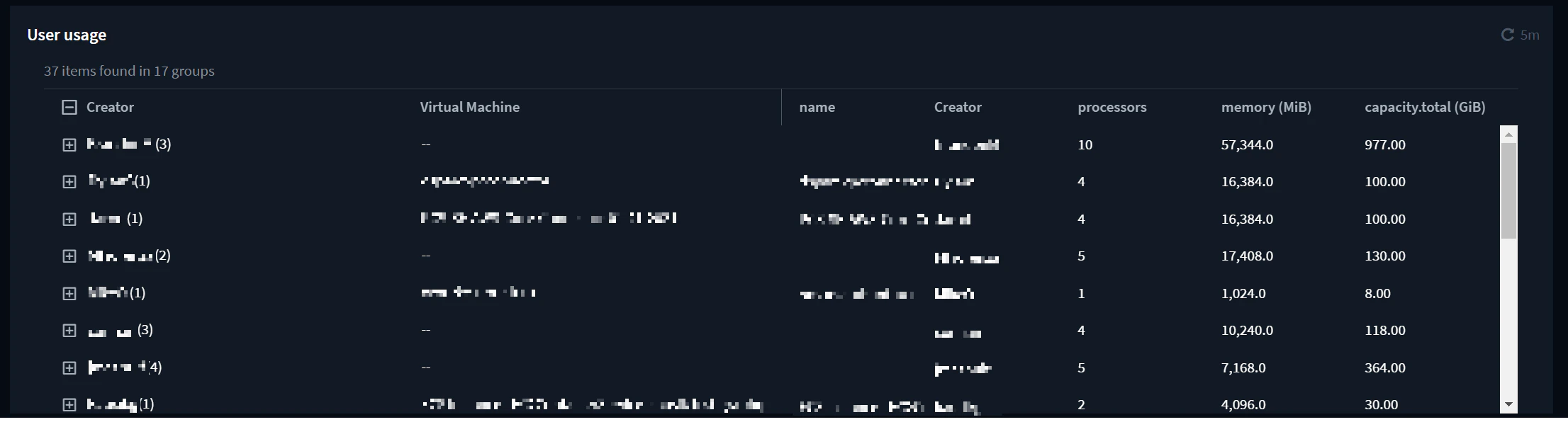
ユーザー毎のストレージ利用量
- 左の黄色い棒グラフの「VM Capacity by User」という項目が、ユーザー毎のEC2インスタンスにアタッチされているEBSボリュームのサイズ総量です。
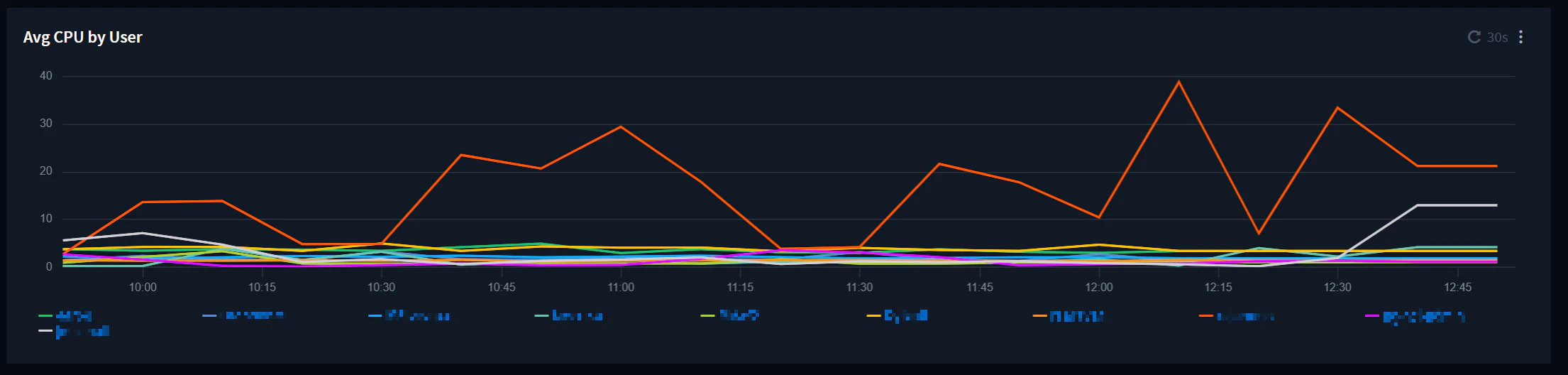
ユーザー毎の平均CPU使用率
- 右上の線グラフの「Avg CPU by User」という項目が、ユーザー毎のEC2インスタンスの平均CPU使用率です。
「誰が何をどれくらいつかっているのか」の一覧表
- 右下の表が、ユーザー毎のCPU、メモリ、ディスクの使用量で、所謂「誰が何をどれくらいつかっているのか」を可視化することができました。
Annocationの設定例
- ちなみに、Annotationはこんな感じで設定できます。
- こちらが特定のEC2インスタンスにフォーカスした画面なのですが、右側の「User Data」という部分がこのEC2インスタンスに設定されているAnnocationです。
- こちらの例では、「Aplication(s)」、「Creator」、「WorkingEnvironment」というAnnotationが付与されており、それぞれ値が設定されています。「Creator」がリソースを作成した人=「誰が使っているか」に相当します。

オンプレミスの可視化
環境全体でのリソース使用状況を可視化
- 「誰が何をどれくらい使っているか」はオンプレミスでもパブリッククラウドでもAnnotationの機能により同じように可視化できるので省略して、環境全体でのリソース使用状況を可視化するところをやってみます。
- オンプレミスの投資計画を立てる際には、個々のリソースの使用量だけではなく環境全体での使用率や余剰を把握する必要があります。
ダッシュボードの例
- ということで、このようにVMware vSphere環境全体の使用状況を可視化するダッシュボードを作ってみました。
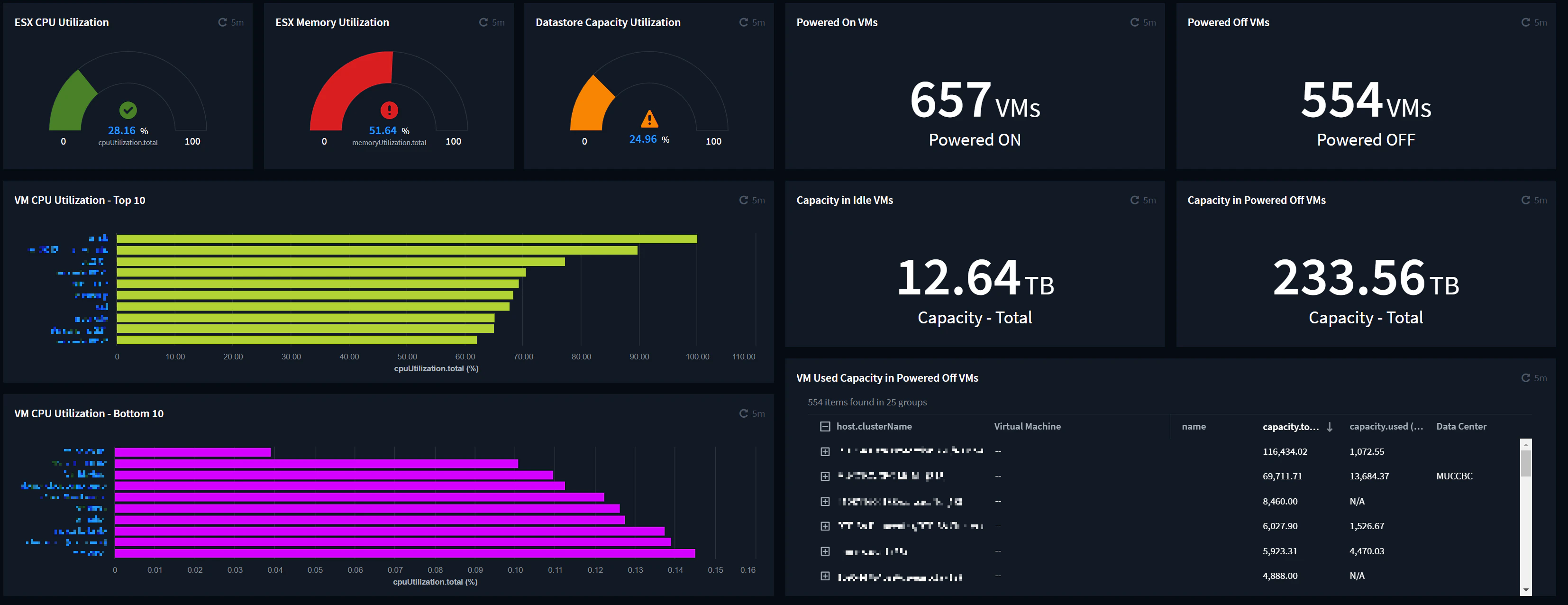
環境全体のESXiホストのCPU、メモリの使用率、データストアの使用率
- 画面上部の半円グラフ3つで、VMware vSphere環境全体のリソース(CPU、メモリ、ストレージ)の使用率を可視化することができます。
- カツカツ過ぎるとホスト障害時にリソースが足りなくなってしまうので、メモリはあまり余裕がありませんがCPUやデータストアはまだ余裕がありそうです。今後の需要予測次第ではリプレース時に調達するコストを削減できるかもしれません。

その他の項目
- その他、起動中のVM(「Powered On VMs」)や停止中のVM(「Powered Off VMs」)、VM毎CPU使用率トップ10/ワースト10(「VM CPU Utilization - Top 10」、「VM CPU Utilization - Bottom 10」)、停止中のVMのストレージ使用量(「VM Used Capacity in Powered Off VMs」)などもパブリッククラウドと同様に可視化することができました。
- こちらのダッシュボードにはありませんが、当然Annotationの機能を利用してユーザー毎の使用状況についても可視化することが可能です。
まとめ
- NetApp Cloud Insightsを使って、ITインフラのコスト最適化の観点で必要な「誰が何をどれくらい使っているのか」を可視化してみました。
- パブリッククラウドもオンプレミスを1つのツールで可視化できたので良い感じでした。
- 継続的にコスト最適化をしていくためには、可視化して終わりではありません。可視化したものから改善点を見つけて改善目標を定める「Optmimize」、実際に改善策を実行する「Operate」のフェーズ、といったFinOpsのフィードバックループを回していくことが重要です。俺たちの戦いはこれからだ!