# 初めに
全部で4本の記事に分けて書いています!
- 第1回 株価予測_可視化編
- 第2回 株価予測_LSTM ver.1
- 第3回 株価予測_LSTM ver.2
- 第4回 株価予測_アプリ化編
実装コード
今回は金曜日の終値が木曜日の終値よりも上がるか下がるかの2値分類をPythonで実装していきたいと思います。使用するモデルはLSTMです。LSTMは時系列データを解析することに長けているため、株価データのような時系列データにはとても効力を発揮します。LSTMについては以前の私の記事を参照してください。
このシリーズで行っている株価のチャート分析は意思決定のためのテクニカル指標に過ぎません。なので、予測に絶対は無いことと、株やFXで損する・得することの判断は自己責任でお願いします。ちなみに私は過去にFX(レバレッジ20倍)でテクニカル指標を過信し過ぎて。。。。なので皆さんも実際に取引する時はファンダメンタルズ分析もしっかり取り入れつつ、楽しく取引しましょう!!
今回の章立て
- 株価データを取得
- 前処理
- 株価予測_LSTM ver.1で作成する予測モデルのコンセプト
- 学習データと検証データに分割
- LSTM構築
- 最後に
- 参考文献
株価データを取得
まず初めに、前回同様株価データの取得を行い、csvファイル(Z_Holdings.csv)に保存します。
start = '2005-01-01'
end = '2022-01-01'
df = data.DataReader('4689.JP', 'stooq', start, end)
df.to_csv('Z_Holdings.csv')
データの確認をします。
df = pd.read_csv('Z_Holdings.csv')
df
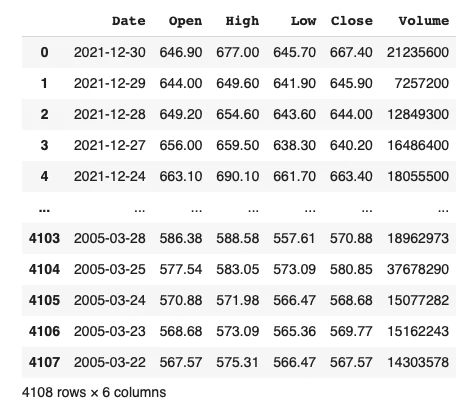
データを取得できているので前処理を行っていきたいと思います。
前処理
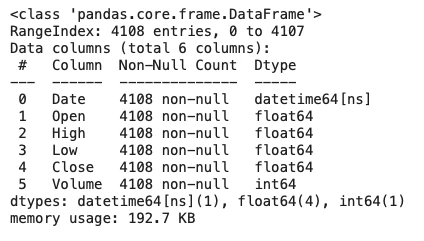
Dateデータがobject型なので、datetime64型へ変更(利便性が高いため)します。
df['Date'] = pd.to_datetime(df['Date'])
df.info()
次に曜日情報を(月曜日:0, 火曜日:1, 水曜日:2, 木曜日:3, 金曜日:4, 土曜日:5, 日曜日:6)として追加します。
df['weekday'] = df['Date'].dt.weekday
今回のデータについて、初めの月曜日として3/21を基準に週を追加します。ここではDateから2005/3/21を引いた値を週の数で割り算した商を求めています。
start = datetime(2005,3,21)
df['weeks'] = (df['Date'] - start) // timedelta(weeks=1)
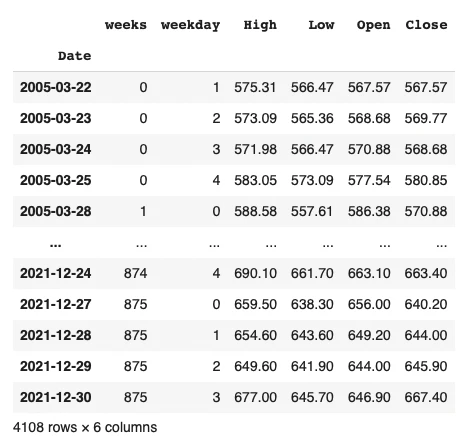
カラムの並び替え、sort_valuesで日付順に並び替え、日付のDateをインデックスにセット(今回のような時系列データを処理する際はset_indexを使用して日付をインデックスに設定)を行います。
df = df[['Date', 'weeks', 'weekday', 'High', 'Low', 'Open', 'Close']]
df.sort_values(by='Date', ascending=True, inplace=True)
df.set_index(keys="Date", inplace=True)
df
先ほど作成したweeksとweekdayのカラムが、日付順に並んで追加されていることが確認できます。
今回予測したい終値のカラムを作成します。
カラム情報を1行上にずらしたデータフレームを作成します。
df_shift = df.shift(-1)
次に、翌日の終値と本日の終値の差分を追加します。
df['delta_Close'] = df_shift['Close'] - df['Close']
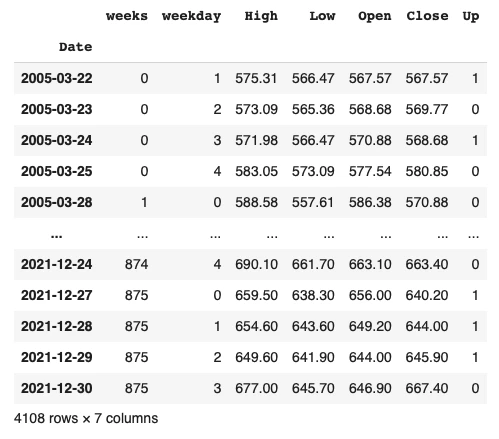
目的変数Upを追加します(翌日の始値が上がる場合1、それ以外は0とする)。
df['Up'] = 0
df['Up'][df['delta_Close'] > 0] = 1 # delta_Closeが0以上なら1を、それ以外は0を返すカラムを追加します
df = df.drop('delta_Close', axis=1) # 必要ないので削除します
df
一度データを確認します。
次に、High, Low, Open, Closeをグラフ化するためにカラム抽出を行い、時系列の折れ線グラフを作成します。
df_new = df[['Open', 'High', 'Low', 'Close']]
df_new.plot(kind='line')
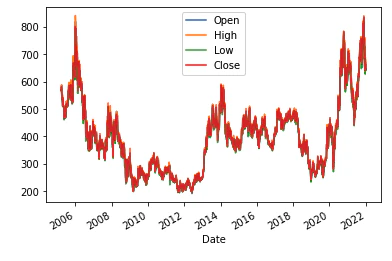
次に、終値の前日比率(本日の終値が前日の初値から何%変化したかを表す値 :(今日の終値 - 前日の終値)/前日の終値)と始値・終値の差分を作成します。
df_shift = df.shift(1)
df['Close_ratio'] = df['Close'] - df_shift['Close'] / df_shift['Close']
df['Body'] = df['Open'] - df['Close']
df
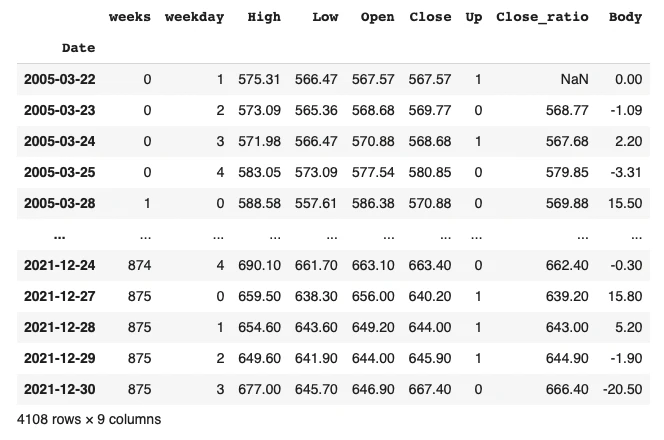
# 株価予測_LSTM ver.1で作成する予測モデルのコンセプト
やりたいこととしては、月曜日から木曜日までの情報をもとに、金曜日の初値が上がるか下がるかの予測モデルの作成します。そこで、月曜日から金曜日までのデータが揃っている週のデータのみを利用するために前処理をします。まず週番号をリストに格納します。
list_weeks = []
list_weeks = df['weeks'].unique()
次に、週番号を数えてデータフレームに追加します。
df['week_days'] = 0
for i in list_weeks:
df['week_days'][df['weeks'] == i] = len(df[df['weeks'] == i])
df
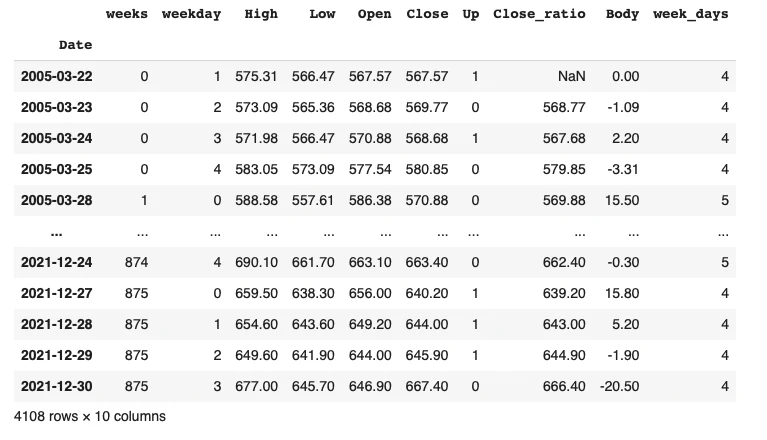
月曜日〜金曜日まで5日分データがある週だけデータを取り出します。
df = df[df['week_days'] == 5]
今回は金曜日(4)を予測したいので、4のカラムの削除をします。
df = df[df['weekday'] != 4]
最後に不要カラムの削除と並び替えをしてデータを見てみます。
df = df[['weekday', 'High', 'Low', 'Open', 'Close', 'Close_ratio', 'Body', 'Up']]
df
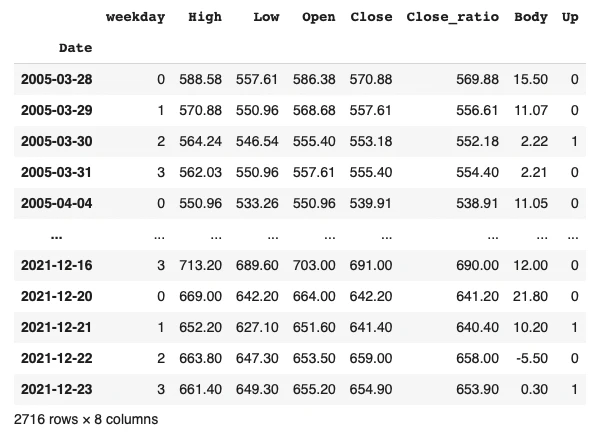
# 学習データと検証データに分割
ここから学習を行なっていきます。
学習データ(2006/1/1~2019/12/31)をdf_train、検証データ(2020/1/1~2021/12/31)をdf_valに分割します。
df_train = df['2006-01-01' : '2019-12-31']
df_val = df['2020-01-01' : ]
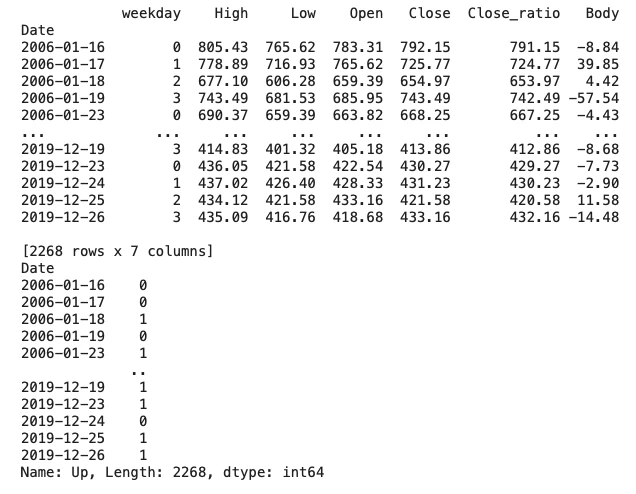
次に、学習データを説明変数(X_train)と目的変数(y_train)に分けて、学習データの説明変数と目的変数を確認します。
X_train = df_train[['weekday', 'High', 'Low', 'Open', 'Close', 'Close_ratio', 'Body']]
y_train = df_train['Up']
print(X_train)
print(y_train)
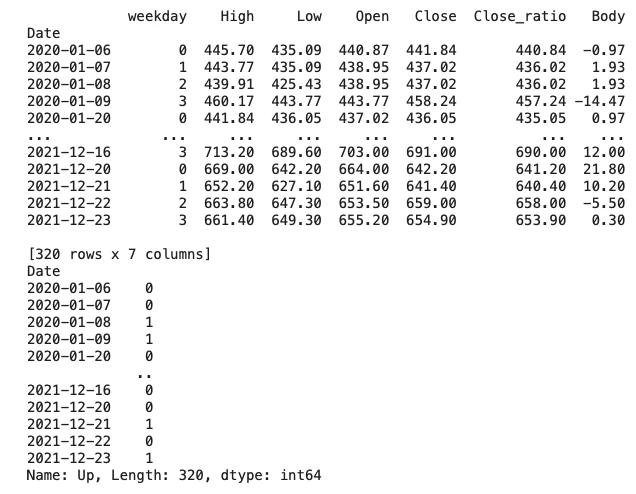
同様に、検証データを説明変数(X_train)と目的変数(y_train)に分けて、検証データの説明変数と目的変数を確認します。
X_val = df_val[['weekday', 'High', 'Low', 'Open', 'Close', 'Close_ratio', 'Body']]
y_val = df_val['Up']
print(X_val)
print(y_val)
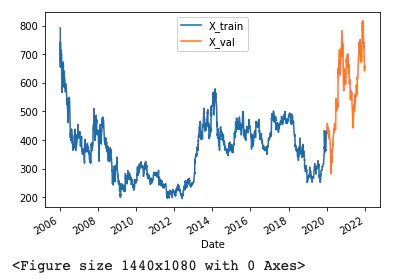
作成した学習データと検証データの終値(Close)の折れ線グラフ作成していきます。
X_train['Close'].plot(kind='line')
X_val['Close'].plot(kind='line')
# グラフの凡例を設定
plt.legend(['X_train', 'X_val'])
# グラフ表示
plt.figure(figsize=(20,15))
plt.show()
説明変数と目的変数のデータ量を揃えるために、月曜日から木曜日までを1セットとして処理します。また、株価を抜き出す期間によって、金額や変動量が異なるのでデータの標準化をする関数を作成します。LSTMではNumpy配列で処理するのでNumpy配列に処理します。
# 4日ごとにデータを抜き出して、標準化とNumpy配列に変換する関数(SS_to_np)の定義
def SS_to_np(df):
df_list = []
df = np.array(df) # 入力されたdfをnumpy配列に変換する
for i in range(0, len(df) -3, 4): # 最後の4日分のデータまで以下の処理を繰り返す
df_s = df[i:i+4] # 4日ずつのデータを抜き出してdf_sに入力する
SS = StandardScaler() # SSとしてインスタンス化する
df_SS = SS.fit_transform(df_s) # 標準化した結果を格納
df_list.append(df_SS) # 標準化をおこなった結果をappendメソッドで追加
return np.array(df_list) # 最後の処理が終了したらdf_listをnumpy配列で出力する
学習データと検証データの説明変数に作成した関数(SS_to_np)を実行します。X_train_np_arrayは2268日分のrowsが567に、X_val_np_arrayは320日分あったrowsが80になっていることが確認できました。
X_train_np_array = SS_to_np(X_train)
X_val_np_array = SS_to_np(X_val)
print(X_train_np_array.shape)
print(X_val_np_array.shape)
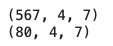
ここで学習データと検証データの目的変数を確認します。
print(X_train)
print(X_val)
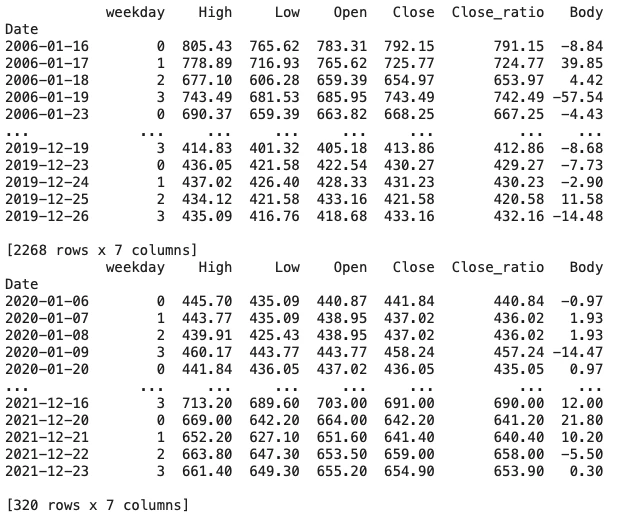
最後に学習データ、検証データの目的変数の間引き・週の4日目(木曜日)のデータだけ抜き出し、間引き後の学習データと検証データを確認します。
y_train_new = y_train[3::4]
y_val_new = y_val[3::4]
print(len(y_train_new))
print(len(y_val_new))

# LSTM構築
LSTM構築とコンパイル関数の作成をします。
def lstm_comp(df):
# 入力層/中間層/出力層のネットワーク構築
model = Sequential()
model.add(LSTM(256, activation='relu', batch_input_shape=(None, df.shape[1], df.shape[2])))
model.add(Dropout(0.2))
model.add(Dense(256, activation='relu'))
model.add(Dropout(0.2))
model.add(Dense(1, activation='sigmoid'))
# ネットワークのコンパイル
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=["accuracy"])
return model
時系列分割交差検証を作成します。
valid_scores = [] # 4回分の交差検証の結果を代入する空のリストを作成
tscv = TimeSeriesSplit(n_splits=4) # TimeSeriesSplitのインスタンス化を行い変数に代入する
# for文で交差検証を4回行う、、splitメソッドを用いて学習データを分割して交差検証用の学習データと検証データを作成する
for fold, (train_indices, valid_indices) in enumerate(tscv.split(X_train_np_array)):
X_train, X_valid = X_train_np_array[train_indices], X_train_np_array[valid_indices]
y_train, y_valid = y_train_new[train_indices], y_train_new[valid_indices]
# LSTM構築とコンパイル関数にX_trainを渡し、変数modelに代入
model = lstm_comp(X_train)
# モデル学習
model.fit(X_train, y_train, epochs=10, batch_size=64)
# 予測
y_valid_pred = model.predict(X_valid)
# 予測結果の予測結果の2値化
y_valid_pred = np.where(y_valid_pred < 0.5, 0, 1)
# 予測精度の算出と表示
score = accuracy_score(y_valid, y_valid_pred)
print(f'fold {fold} MAE: {score}')
# 予測精度のスコアをリストに格納
valid_scores.append(score)
print(f'valid_scores: {valid_scores}')
cv_score = np.mean(valid_scores)
print(f'CV score: {cv_score}')

実行結果を確認します。CV score: 0.5464601769911503は2値分類では悪く無いので、一応オッケーということで次に行きます。
LSTM構築とコンパイル関数にX_train_np_arrayを渡し、変数変数modelに代入しモデルの学習を実行します。
model = lstm_comp(X_train_np_array)
result = model.fit(X_train_np_array, y_train_new, epochs=10, batch_size=64)
作成したモデルより検証データを用いて予測を行います。
pred = model.predict(X_val_np_array)
pred[:10]
予測結果を0もしくはは1に修正(0.5を境にして、1に近いほど株価が上昇、0に近いほど株価が下落)し、修正した予測結果の先頭先頭10件を確認します。
pred = np.where(pred < 0.5, 0, 1)
pred[:10]
実際の結果から予測値の正解率を計算していきます。
print('accuracy = ', accuracy_score(y_true=y_val_new, y_pred=pred))
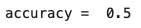
最後に混同行列を表示して今回の結果を可視化します。
cm = confusion_matrix(y_val_new, pred)
cmp = ConfusionMatrixDisplay(cm)
cmp.plot(cmap=plt.cm.Reds)
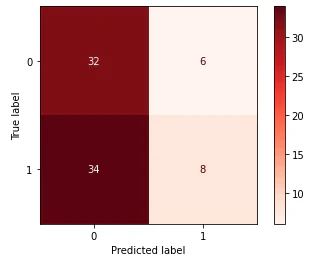
正しく予測できている真陰性(左上)は32、真陽性(右下)は8となりました。
精度を上げるために特徴量の改善かモデルの改善をした方がよさそうですね。
最後に
株価の予測は上がるか下がるかの2値分類なのでaccuracyが50を上回っていれば、精度として基準点はまずクリアだと思います。リスクヘッジをうまくすれば50%の勝率でも利益は十分に上げられますし、潤沢な資産を持っていればレバレッジをせずとも堅実に利回り3%を取りに行くことも可能でしょう!私も老後のために頑張るので皆さんも良い投資ライフを!
参考文献
FXデイトレード・スイングトレード
東大院生が考えたスマートフォンFX
ザ・トレーディング──心理分析・トレード戦略・リスク管理・記録管理
ガチ速FX 27分で256万を稼いだ“鬼デイトレ"
デイトレード
株とPython─自作プログラムでお金儲けを目指す本
Pythonで将来予測