はじめに
「LangChainとLangGraphによるRAG・AIエージェント[実践]入門」の第7章で私がつまずいたことのメモです。
(このメモのほかの章へ:1章 / 2章 / 3章 / 4章 / 5章 / 6章 / 7章 / 8章 / 9章 / 10章 / 11章 / 12章 / まとめ)
この記事は個人で作成したものであり、内容や意見は所属企業・部門見解を代表するものではありません。
第7章 LangSmithを使ったRAGアプリケーションの評価
前章に続き大嶋さんが担当された章です。
7.1 第 7 章で取り組む評価の概要
今回はRAGの評価のお話です。本では前章と同様にLangChainの公式ドキュメントを使っていますが、英語が苦手な私は日本語で挑戦することにしました。
7.2 LangSmithの概要
LangSmithの料金プランの説明で「本書の範囲であれば、Developerプランでも実施可能です」とありますが、私は日本語に挑戦して試行錯誤していたら月間の制限にひっかかりました……(後述)
7.3 LangSmithとRagasを使ったオフラン評価の構成例
発生料金の注意書きがありますが、GPT-4o miniにランクを落としていても試行錯誤していたらOpenAIで数ドルかかりますので注意しましょう……(後述)
7.4 Ragasによる合成テストデータの生成
パッケージのインストール
本で使っているRagas v0.1.14では日本語のテストデータの生成がうまくいかず、最新のv0.2.9で挑戦しました。
!pip install langchain-core==0.3.28 langchain-openai==0.2.14 \
langchain-community==0.3.13 ragas==0.2.9 nest-asyncio==1.6.0 \
"protobuf>=3.20.3,<5.0.0dev" "tokenizers<0.22,>=0.21" rapidfuzz==3.11.0
ここではバージョンを指定していますが、最初はバージョン指定なしでインストールし、バージョンの互換がないぞ!と怒られる度にバージョン指定を追加して、最後に!pip listで調べ直して指定したものです。rapidfuzzは確か途中でライブラリがない!と怒られて追加したものだったかと思います。
また、これでも以下のエラーが表示されるのですが、動作したので気づかなかったことにしました。有識者の方、フォローお願いします![]()
ERROR: pip's dependency resolver does not currently take into account all the packages that are installed. This behaviour is the source of the following dependency conflicts.
gcsfs 2024.10.0 requires fsspec==2024.10.0, but you have fsspec 2024.9.0 which is incompatible.
この記事では結局Ragas v0.2+LangChain v0.3で最後までやり切ることはできず途中で環境を戻してしまうのですが、@TommyTommy7さんよりコメントいただき、最後までやり切るための情報をいただきました!有用な情報ありがとうございます!
これから試される方は、この記事のコメントも合わせてご参照ください!
検索対象のドキュメントのロード
検索対象の日本語ドキュメントは、拙作の【初心者向け】本当にわかりやすいAI入門にしました。Qiitaに投稿している以下の7つのMarkdownファイルが対象です。たったの7ファイルしかなくRAGでの検索対象には物足りないのですが、あくまでも評価方法を理解することが目的なのでよしとしましょう。
| 対象ページ | MarkdownのURL |
|---|---|
| 第1章 AIはなぜ人間みたいなことができるのか? | https://qiita.com/segavvy/items/9e7e4ab4b253599ac58a.md |
| 第2章 脳はすごい | https://qiita.com/segavvy/items/875b8c5643389c35e8fd.md |
| 第3章 伝わりやすさと境界の決め方 | https://qiita.com/segavvy/items/6459c5de2bb973442919.md |
| 第4章 細胞増やすだけではダメだった | https://qiita.com/segavvy/items/5702a4620c43bfb0c87e.md |
| 第5章 時間も手間もお金もかかる | https://qiita.com/segavvy/items/903e60bb7579f9d45273.md |
| 第6章 文章生成の大規模化による進化 | https://qiita.com/segavvy/items/2f2b46acb36d53a0eded.md |
| 第7章 AIのこれから | https://qiita.com/segavvy/items/b20fb22c612702ec9178.md |
検索対象にしたいファイルを後から追加しやすいように、今回はこれらのファイルをGoogle Driveに入れて、そこから読み込むことにしました。
まず、対象のファイルをGoogle Driveの適当なフォルダに入れます。

そして、Google ColabからGoogle Driveをマウントしてアクセスできるようにします。
from google.colab import drive
drive.mount('/content/drive')
そうすると、Google Driveへのアクセスを許可するかどうかを聞いてきます。

「Google ドライブに接続」を選択します。

続いて使っているアカウントを選択します。

情報が共有される旨の確認が表示されるので、問題なければ「次へ」。
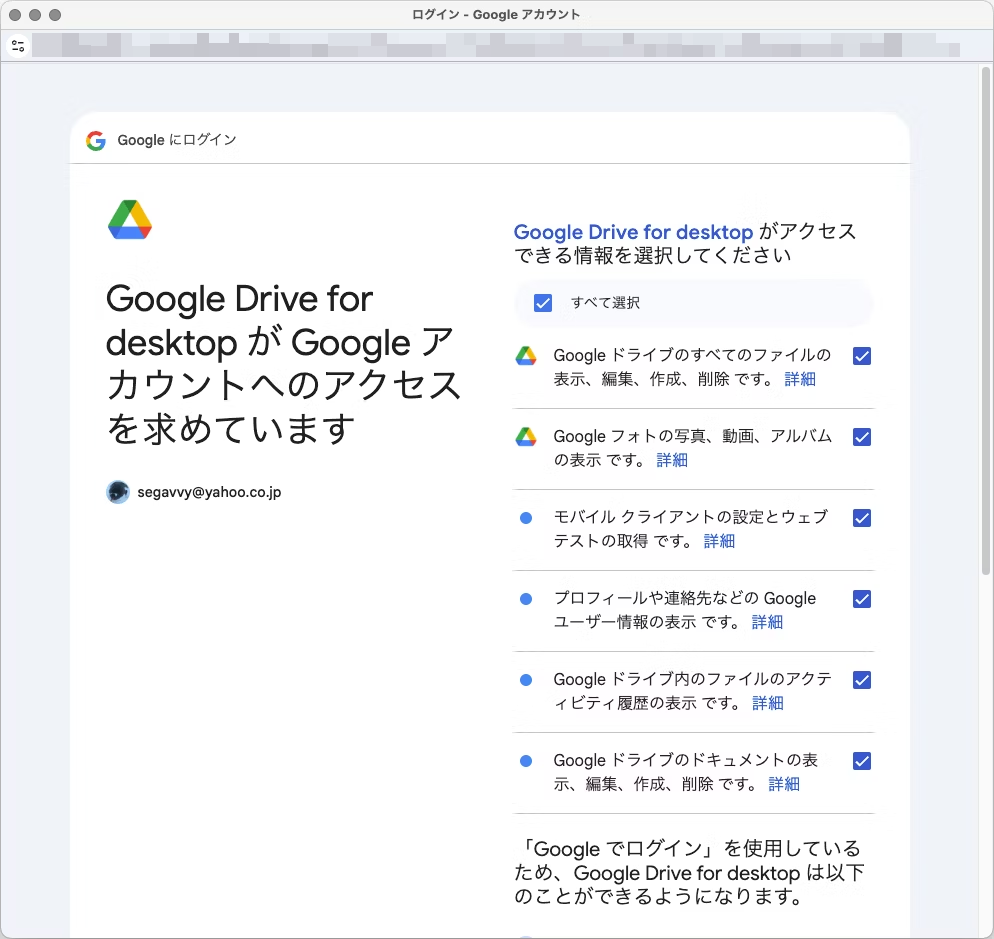
ここで、細かい項目が指定できます。「すべて選択」ではやり過ぎかも知れませんので、気になる方は必要なもののみに絞りましょう。
なお、設定したアクセス権は、Googleアカウントの設定画面の左のメニューから「セキュリテイ」を選び、「サードパーティ製のアプリとサービス」の「Google Drive for desktop」から解除できます。
これでlsするとファイルが見えるようになり、Google Colabからアクセスできるようになりました。
!ls /content/drive/MyDrive/Colab\ Notebooks/RAG・AIエージェント[実践]入門/第7章テストデータ/AI入門
AI入門1章.md AI入門2章.md AI入門3章.md AI入門4章.md AI入門5章.md AI入門6章.md AI入門7章.md
次にドキュメントをロードします。本ではGitLoaderを使っていますが、ディレクトリ下のテキスト形式のファイルを読み込むため、DirectoryLoaderとTextLoaderを使います。
from langchain.document_loaders import DirectoryLoader
from langchain.document_loaders import TextLoader
loader = DirectoryLoader(
path="/content/drive/MyDrive/Colab Notebooks/RAG・AIエージェント[実践]入門/第7章テストデータ/AI入門",
glob="**/*.md",
loader_cls=TextLoader
)
documents = loader.load()
print(len(documents))
7
これで7件のファイルの読み込み完了です。
Ragasによる合成テストデータ生成の実装
Ragasのバージョンを上げてしまって本の手順が使えないので、ここからはRagas公式ページのNon-English Testset Generation - Ragasの手順で進めます。
まず、必要なモデルの初期化です。
from ragas.llms import LangchainLLMWrapper
from ragas.embeddings import LangchainEmbeddingsWrapper
from langchain_openai import ChatOpenAI
from langchain_openai import OpenAIEmbeddings
generator_llm = LangchainLLMWrapper(ChatOpenAI(model="gpt-4o-mini"))
generator_embeddings = LangchainEmbeddingsWrapper(OpenAIEmbeddings())
そして、ペルソナ(想定利用者)を設定します。今回検索の対象にしているAI入門は、AIにあまり詳しくない企業のシステム担当の方などを想定しているので、Google翻訳さんを駆使して指定してみました。なお、nameやrole_descriptionは日本語でも書けるみたいですが、実行した時にnameに対するKeyErrorが時々発生するので、LLMの気分に振り回されないように英語にしておくのが無難な模様です。
from ragas.testset.persona import Persona
personas = [
Persona(
name="System Manager of General Company",
role_description="I am a systems manager at a general company and don't know much about AI, but I have received a proposal for a system that uses AI from an AI vendor and I am trying to understand the details.",
),
]
次にナレッジグラフの変換処理の指定です。Ragas v0.2からは検索対象のデータからさまざまなナレッジグラフを生成し、そのナレッジグラフを融合して、そこからテストデータを生成する仕組みになっている模様です。踏み込むと奥が深そうなので、ここでは写経でサラッと流します。
from ragas.testset.transforms.extractors.llm_based import NERExtractor
from ragas.testset.transforms.splitters import HeadlineSplitter
transforms = [HeadlineSplitter(), NERExtractor()]
続いてテストデータを生成してくれるTestsetGeneratorの初期化です。これまでに用意したものをセットするだけです。
from ragas.testset import TestsetGenerator
generator = TestsetGenerator(
llm=generator_llm, embedding_model=generator_embeddings, persona_list=personas
)
最後にテストデータのクエリーを生成するQuery Synthesizerの設定です。本では「単純な質問」(simple)、「推論が必要な質問」(reasoning)、「複雑な情報元が必要な質問」(multi_context)が組み合わされていますが、Ragas v0.2からはQuery Synthesizerを組み合わせる形に変わっています。
この組み合わせをデフォルトに任せるとTestset Generation for RAG - RAGASの「Testset Generation」で解説されているように、1/2がSingleHopSpecificQuerySynthesizer(1つの情報元の単純な質問)、1/4がMultiHopAbstractQuerySynthesizer(複数の情報元に基づく推論が必要な質問)、1/4がMultiHopSpecificQuerySynthesizer(複数の情報元が必要な質問)になって本の内容に近くなるのですが、残念ながら「ValueError: No clusters found in the knowledge graph. Try changing the relationship condition.」のエラーになってしまい前に進めませんでした。どうやら、対象データが少な過ぎるので、ナレッジグラフを作ってもクラスタ(意味的なかたまり)が作りだせなかった模様です。
from ragas.testset.synthesizers import default_query_distribution
distribution = default_query_distribution(llm=generator_llm)
for query, _ in distribution:
prompts = await query.adapt_prompts("japanese", llm=generator_llm)
query.set_prompts(**prompts)
そのため、今回は参考にしているNon-English Testset Generation - RagasのコードそのままのSingleHopSpecificQuerySynthesizerのみで進めました。
from ragas.testset.synthesizers.single_hop.specific import (
SingleHopSpecificQuerySynthesizer,
)
distribution = [
(SingleHopSpecificQuerySynthesizer(llm=generator_llm), 1.0),
]
for query, _ in distribution:
prompts = await query.adapt_prompts("japanese", llm=generator_llm)
query.set_prompts(**prompts)
ちょっと脱線しますが、この辺で試行錯誤を繰り返していたら、LangSmithの月間利用制限にひっかかってしまいました![]()
WARNING:langsmith.client:Failed to multipart ingest runs: langsmith.utils.LangSmithRateLimitError: Rate limit exceeded for https://api.smith.langchain.com/runs/multipart. HTTPError('429 Client Error: Too Many Requests for url: https://api.smith.langchain.com/runs/multipart', '{"detail":"Monthly unique traces usage limit exceeded"}')trace=xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx,id=xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx
Monthlyとあるので、月が変わる(年も変わる)1月まで待つことに。そして、年明け早々に再開し、なんとか無料のDeveloperプランで乗りきって今に至ります。少し興味を持って複雑なことをやろうとするとすぐに課金ゾーンに入りますね。サンデープログラマ(死語?)にとっては、なかなかやっかいな値付けです。
話を戻していよいよ実行です。本と同じように4件作成させてみました。
testset = generator.generate_with_langchain_docs(
documents[:],
testset_size=4,
transforms=transforms,
query_distribution=distribution,
)
実行すると、以下のようなエラーがいくつか起きます。どうやら変換処理で指定していたHeadlineSplitterが上手く見出しを抽出できなかった模様です。WARNINGじゃないところが気になりますが、処理は進みますので気づかずにおきましょう。
ERROR:ragas.testset.transforms.engine:unable to apply transformation: 'headlines' property not found in this node
しばらくすると処理が終わりました。さっそく結果を見てみます。
testset.to_pandas()

おぉ、AIに詳しくない企業のシステム担当の方っぽい質問のテストデータができました!
ただ、よく見るとuser_inputとかreference_contextsとか、本とは項目名が全然違いますね。From v0.1 to v0.2 - Ragasによるとv0.2からはこれまでのHuggingFaceの構造から独自のものに変わったそうです。
データ互換のないことがわかったので、このまま本のバージョンを無視して突き進むべきかどうかを悩みましたが、v0.2系のRagasの評価メトリクスをLangchainで使うための解説が見つけられなかったため、この後の評価は本のバージョンへ戻して実施することにしました。
ちなみにRagas公式のLangsmith - Ragasには以下の記載がありました。
The langsmith + ragas integrations offer 2 features 1. View the traces of ragas evaluator 2. Use ragas metrics in langchain evaluation - (soon)」
(機械訳)langsmith + ragas 統合には 2 つの機能があります。1. ragas エバリュエーターのトレースを表示する 2. langchain 評価で ragas メトリックを使用する - (近日提供予定)
どうやら、LangChainの評価でRagasのメトリクスを使うための解説も近日掲載されるそうです。ちょっと試すタイミングが早過ぎました。
LangSmithのDatasetの作成
これは本のコードまんまで問題ありません。
合成テストデータの保存
生成したデータセットを保存する際は、この後の評価のために本と同じフォーマットに変換しておきます。なお、metadata > sourceは生成結果に該当するものがなく、この後も特に使わなそうだったので省略しています。また、metadata > evolution_typeは使っているQuery Synthesizerの名前をそのまま入れることにしました。
inputs = []
outputs = []
metadatas = []
for testset_record in testset:
inputs.append(
{
"question": testset_record.eval_sample.user_input,
}
)
outputs.append(
{
"contexts": testset_record.eval_sample.reference_contexts,
"ground_truth": testset_record.eval_sample.reference,
}
)
metadatas.append(
{
# "source": testset_record.eval_sample.metadata[0]["source"],
"evolution_type": testset_record.synthesizer_name,
}
)
client.create_examples(
inputs=inputs,
outputs=outputs,
metadata=metadatas,
dataset_id=dataset.id,
)
実行できたらLangSmithで見てみます。

いい感じ!
7.5 LangSmithとRagasを使ったオフライン評価の実装
ここから先は、LangChainやRagasのバージョンを本の指定のものに戻して進めます。Google Colabの「ランタイム」メニューで「ランタイムを接続解除して削除」を選び環境をリセットしてから、本のバージョンでpip installしなおしましょう。
基本的には本のコードのままでいけますが、一度ランタイムをリセットしているのでnest_asyncio.apply()の実行が必要です。また、私の環境ではOpenAIの制限がUsage tier 1のためなのかGPT-4o miniでも時々以下のエラーが発生するので、同時実行数を1に落として実行しています。
ERROR:langsmith.evaluation._runner:Error running evaluator <DynamicRunEvaluator evaluate> on run xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx: APIConnectionError('Connection error.')
import nest_asyncio
from langsmith.evaluation import evaluate
nest_asyncio.apply() # ランタイムをリセットしているので再実行
evaluate(
predict,
data="agent-book",
evaluators=evaluators,
max_concurrency=1 # 同時実行数を抑える
)
ちなみに、Easier evaluations with LangSmith SDK v0.2によると、これまでは同時実行数を指定しないと無制限になっていたそうなのですが、LangSmith v0.2からはデフォルトが同時実行なし(max_concurrency=0)に変わっている模様です。
またまた脱線ですが、この辺をいろいろ試している時に、途中からエラーで動かなくなってしまいました。
RateLimitError: Error code: 429 - {'error': {'message': 'You exceeded your current quota, please check your plan and billing details. For more information on this error, read the docs: https://platform.openai.com/docs/guides/error-codes/api-errors.', 'type': 'insufficient_quota', 'param': None, 'code': 'insufficient_quota'}}
GPT-4o miniを使っているのでそんなに費用はかかっていないのかと思っていたのですが、エラーメッセージに従ってOpenAIのBillingを見にいったらまさかの借金生活に😅

本を買った時に$10入金したのですが、本をまだ半分くらいしか読んでいないのに使い切ってしまったことになります。試行錯誤するとあっという間に使ってしまうので注意しましょう。
話を戻して、評価を3回実行した結果です。

Context precisionは振り切っていて、Answer similarity1も悪くなさそうです。ただ、単純な質問しか生成させていない上に対象ファイルも極端に少ないので当然の結果かもしれません。
7.6 LangSmithを使ったフィードバックの収集
所属会社のチャットのサービスでもフィードバックボタンを設ける機能があったりしますが、悲しいことに驚くほどクリックされません。利用者に負担をかけず、あわよくば利用者に意識すらさせずにフィードバックを収集するための工夫が実際のサービスでは重要です。
7.7 フィードバックの活用のための自動処理
LangSmithにはいろいろな機能が備わっていますね。ホント便利そうです。
7.8 まとめ
というわけで、思いつきで日本語での評価に挑戦してしまったばっかりに、Ragasのバージョン間の非互換に振り回された章でした。数ヶ月経ったらまた状況が変わっていそうですね。
RAGのお話はここまでで、次回からはいよいよAIエージェントのお話です。
(このメモのほかの章へ:1章 / 2章 / 3章 / 4章 / 5章 / 6章 / 7章 / 8章 / 9章 / 10章 / 11章 / 12章 / まとめ)