はじめに
「LangChainとLangGraphによるRAG・AIエージェント[実践]入門」の第2章で私がつまずいたことのメモです。
(このメモのほかの章へ:1章 / 2章 / 3章 / 4章 / 5章 / 6章 / 7章 / 8章 / 9章 / 10章 / 11章 / 12章 / まとめ)
この記事は個人で作成したものであり、内容や意見は所属企業・部門見解を代表するものではありません。
第2章 OpenAIのチャットAPIの基礎
StudyCoを運営されている大嶋さん1の担当された章です。
2.1 OpenAIのチャットモデル
モデルの説明を読んでいて思ったのは、進化の速度のすさまじさです。
2023年春頃のGPT-3.5 turboの最大トークン数は4,096だったのですが、現在のGPT-4oは128,000です。トークン数を抑えるための苦労が過去のものになってきましたね。
2.2 OpenAIのチャットAPIの基本
値段も同様で、トークン単価が爆下がりしています。ただし、人間の要求もより高度になって消費するトークン数も増えていきますので、コストはあまり変わらずにできることがどんどん高度になる、という形に進むのかもしれません。
2.3 入出力の長さの制限や料金に影響する「トークン」
日本語はトークン数をたくさんつかってしまうというお話がありますが、「なぜ日本語は英語よりたくさん食うの?」という解説をあまり目にすることがないので、ここで少し補足してみます。
LLMは文章を直接扱うのではなく、前処理で単語や文字に分解しています。単語や文字に数値のIDを割り振って、数値の羅列に変換して処理しているのです。この分解した1つ1つが「トークン」で、分解作業をやってくれるのが「トークナイザー」です。
トークナイザーの実装は日本語だと大変です。英語の場合は単語の境界に空白があるので簡単に分解できるのですが、日本語の場合は空白がないので区切りがわかりません。実はこの課題は最近のLLMブームよりもずっと前からあるもので、全文検索エンジンの開発でよく話題になっていたテーマなのです。
日本文をトークンに分解する方法は大きく2つあります。全文検索で索引を作る時にも全く同じことをするので、その説明資料2からの解説を抜粋してみました。オレンジの四角が元の文章、青い四角が分解後のトークンです。
a. 用語の辞書を使ってトークンに分解する方法

この場合、英語と同じように1単語が1トークンにできるので理想なのですが、解析ミスの問題がつきまといます。たとえば、「Honda Cars 東京都」という文章があった場合、一般的な解析では次のように分解します。

一見、正しいように思えますが、実はこのHonda Cars 東京都さんの「東京都」は「ひがしきょうと」で京都にあります。そのため、このような解析ミスがあると、LLMは「京都」とは関係ない文章だと理解してしまうのです。
b. 何も考えずに切り刻む方法
もう1つは、何も考えずに固定の文字数で切り刻む方法です。

この例では2文字ずつ切り出していますが、これは全文検索の資料から引用してしまった(全文検索では後工程を効率化するために通常は2文字以上で切り出す)ためで、LLMで使う場合は1文字ずつ切り出すのが基本です。
1文字ずつ切り出すと単語で切り出すよりもトークン数が増えてしまいます。また、ばらばらにしてしまった文字を、その並びを見て意味のある単語だと解釈するのはLLMの仕事になってしまいますから、LLMによる理解や生成の精度低下にもつながってしまいます。
最近のLLMはどうしてるの?
b.の方式や、そこからさらにByte Pair Encoding(BPE)というアルゴリズムで圧縮をかけることが多いようです。そのため、日本語の場合はほぼ1文字1トークンになってしまい、バラバラの文字から単語を認識させる作業までLLMに任せており、英語と比べると精度も出しにくいしトークン数も増えてしまうというわけですね。
なお、a.を選択しない理由は、切り出し時の単語を判定するために使う用語辞書のメンテナンスが必須になってしまうためです。辞書をメンテナンスしてしまうとトークンの切り出し方が変わってしまうため、トークンに割り振るIDも変わってしまいます。LLMはIDの羅列で学習しているので、LLMの学習そのものをやり直さないといけなくなってしまうのです。
この辺りの詳細は、「東大松尾・岩澤研究室 | LLM開発 プロジェクト[GENIAC]」の以下の記事がわかりやすかったので、ご興味のある方はぜひこちらを。
実際の切り出し
本にあるようにGPT-4oではトークナイザーが改良されて、日本語のトークン数がGPT-4よりも減っています。実際にどう変わったのか、本のコードをちょっとだけ変えて見てみましょう。
import tiktoken
text = "LLMを使ってクールなものを作るのは簡単だが、プロダクションで使えるものを作るのは非常に難しい。"
encoding = tiktoken.encoding_for_model("gpt-4")
tokens = encoding.encode(text)
for token in tokens:
print(encoding.decode([token]), end="/")
| モデル | LLMを使ってクールなものを作るのは簡単だが、プロダクションで使えるものを作るのは非常に難しい。 |
|---|---|
| GPT-4 | LL/M/を/使/って/ク/ール/な/も/の/を/作/る/の/は/�/�/�/�/�/だ/が/、/プ/ロ/ダ/ク/シ/ョ/ン/で/使/え/る/も/の/を/作/る/の/は/非/常/に/�/�/し/い/。/ |
| GPT-4o | LL/M/を/使/って/ク/ール/な/もの/を/作/る/の/は/簡/単/だ/が/、/プロ/ダ/ク/ション/で/使/える/もの/を/作/る/の/は/非常/に/難/しい/。/ |
「�」は文字として表示できないコードに分解されている部分です。GPT-4の時は1文字1トークンどころか、「簡単」が5トークンになっていたり「難」が2トークンになっていたりと、1文字がさらにバラバラにされることもありました。これでは、生成する文章が崩れてしまうことがあるのもうなずけます。
GPT-4oではこういった事象が解消されていますね。また、「プロ」や「ション」や「非常」などの複数文字が1トークンになっています。この辺が改良ポイントのようです。
OpenAIのトークナイザーの詳細は、「IIJ Engineers Blog」の以下の記事がわかりやすかったので、ご興味がありましたらぜひ。
2.4 Chat Completions APIを試す
ここからは、実際にGoogle Colabで試しながら読み進めます。
なお、本の第1章よりも前のページviiiに、この本のコードを掲載したGitHubリポジトリが案内されています。ここからコード持ってくればコードを打ち込む手間が省けて便利なので、ざっと流れをご説明します。
まず、本で案内されている「GenerativeAgents / agent-book」にいきましょう。そして、ちょっと下にスクロールすると各章のソースコード一覧があります。ここで「Open in Colab」をクリックするとその章のコードをGoogle Colabで表示してくれます。いたせりつくせり!

Google Colabで表示されたら「ドライブにコピー」を選んで、自分のドライブにコピーしてきましょう。なお、「ドライブにコピー」はメニューを隠していると出てこないので、表示されない場合は右上の「v」を選んでメニューを表示してみてください。
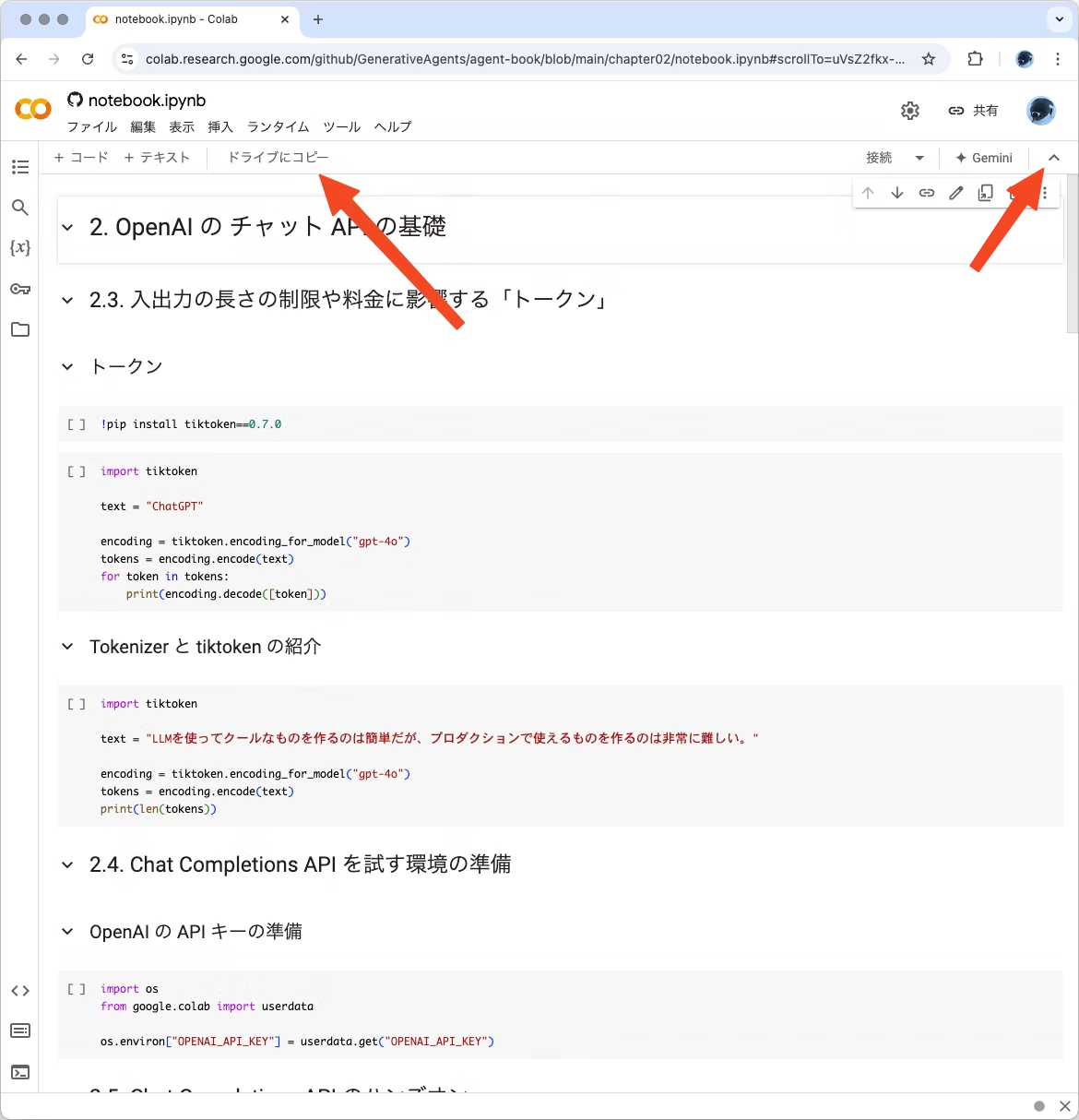
コピーが終わった時に、私の手元のChromeではポップアップウインドウをブロックしてしまいましたが、コピーは完了しているので「新しいタブで開く」を選べばOKです。

これで好き勝手にコードを編集しながら学べる環境が整いました。
なお、どこにコピーされたのかを確認するには、「ファイル」メニューの「ドライブで探す」を選んでください。これで場所がわかります。必要に応じて好きな場所に移動したり名前を変えたりしましょう。

2.5 Chat Completions APIのハンズオン
テキストによる会話は仕事でも使っているのですが、画像は試したことがなかったので、先日の刊行イベントで書籍にいただいたサインの写真を渡してみました。
from openai import OpenAI
client = OpenAI()
image_url = "https://qiita-image-store.s3.ap-northeast-1.amazonaws.com/0/139624/ca10c374-a9d9-4149-0f73-d0058ccaa952.png"
response = client.chat.completions.create(
model="gpt-4o",
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": "画像を説明してください。"},
{"type": "image_url", "image_url": {"url": image_url}},
],
}
],
)
print(response.choices[0].message.content)

| LLM | 結果 |
|---|---|
| GPT-4o mini | 画像には、赤いページの上に書かれた手書きのメッセージが映っています。メッセージは日本語と英語の両方が含まれており、特に「AI Agent is All You Need!」というフレーズが目立ちます。また、その下には「Lang Charm / Lang Graph」という文字と、「太坂 夕子」という名前らしきサインもあります。ページのデザインや内容から、本の中の特定のページやサイン入りのページであることが窺えます。背景は木目調のテーブルのようです。 |
| GPT-4o | この画像は、本の見開きにメッセージが手書きで書かれているところを写したものです。ページは赤色で、メッセージには「これからも未来を切り開きましょう!!」といった日本語の文章や、「AI Agent is All You Need!」という英語の文などが含まれています。また、何名かのサインも見られます。 |
す、すごい!
GPT-4o miniだと著者の大嶋さんの名前が「太坂」さんになってしまいましたが、そんなことよりも、書籍にサインしてもらったページであることを認識していることが驚きです。いやぁ、ホントすごい時代になりました。AIの進化はすさまじいです。
2.6 Function calling
本のサンプルでは決め打ちの温度を返す形になっていますが、実際に気象庁のページに情報を取りにいくようにget_current_weather()を改造してみましょう。
import json
import requests
def get_area_code(area_name):
# 気象庁の予報区コードの一覧を取得
url = "https://www.jma.go.jp/bosai/common/const/area.json"
response = requests.get(url)
data = json.loads(response.text)
# 指定されたarea_nameのコードを探索
for code, info in data["offices"].items():
if info["name"] == area_name:
return code
return None # 見つからなかった……
def get_current_weather(location):
# 気象庁の予報区コードを調べる
area_code = get_area_code(location)
if area_code is not None:
# 概観取得
url = f"https://www.jma.go.jp/bosai/forecast/data/overview_forecast/{area_code}.json"
response = requests.get(url)
data = response.json()
overview = data['text']
else:
overview = "その地域の予報はわかりませんでした。"
return overview
tools = [
{
"type": "function",
"function": {
"name": "get_current_weather",
"description": "Get the current weather in a given location",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "The city, e.g. 東京都",
}
},
"required": ["location"],
},
},
}
]
get_current_weather()を改造して、指定した都道府県の天気の概観を取得するようにしてみました。
気象庁のページから取得するには予報区コードに変換する必要があるので、その変換をget_area_code()でやっています。また、get_current_weather()のパラメーターからunitは削除しちゃいました。
このコードは気象庁ホームページにアクセスして情報を取得する流れになっています。利用する際は気象庁ホームページ利用規約を守ってください。
エラー処理やテストは省きまくっています。動かす時は自己責任でお願いします。
unitを消してしまったので、関数を実行する部分からもunitの受け渡しを削除します。
available_functions = {
"get_current_weather": get_current_weather,
}
# 使いたい関数は複数あるかもしれないのでループ
for tool_call in response_message.tool_calls:
# 関数を実行
function_name = tool_call.function.name
function_to_call = available_functions[function_name]
function_args = json.loads(tool_call.function.arguments)
function_response = function_to_call(
location=function_args.get("location")
)
print(function_response)
# 関数の実行結果を会話履歴としてmessagesに追加
messages.append(
{
"tool_call_id": tool_call.id,
"role": "tool",
"name": function_name,
"content": function_response,
}
)
これで、実際の天気を教えてくれます。「千葉県の天気はどうですか?」と聞いてみました。
{
"id": "chatcmpl-APLsScWQX42OONZWoj1e30A7gqqmu",
"choices": [
{
"finish_reason": "stop",
"index": 0,
"logprobs": null,
"message": {
"content": "千葉県の天気は現在晴れています。3日は高気圧に覆われるため晴れるでしょう。4日は晴れますが、昼過ぎから時々曇りとなる所がある見込みです。また、海上では波が高くなるため、船舶は高波に注意が必要です。",
"refusal": null,
"role": "assistant"
}
}
],
"created": 1730605660,
"model": "gpt-4o-2024-08-06",
"object": "chat.completion",
"system_fingerprint": "fp_45cf54deae",
"usage": {
"completion_tokens": 75,
"prompt_tokens": 197,
"total_tokens": 272,
"completion_tokens_details": {
"reasoning_tokens": 0
},
"prompt_tokens_details": {
"cached_tokens": 0
}
}
}
いい感じ!
なお、都道府県名から予報区コードに変換する部分はやっつけなので、うまく変換できない地域もあるかもしれません。実装に当たっては「TECH+」の以下の記事を参考にさせていただきましたので、詳細はこちらをご参照ください。
2.7 まとめ
実際に動かしながら読み進めると楽しいですね。
ということで、この章は以上です。誤りなどありましたら、ご指摘いただけますとうれしいです。
(このメモのほかの章へ:1章 / 2章 / 3章 / 4章 / 5章 / 6章 / 7章 / 8章 / 9章 / 10章 / 11章 / 12章 / まとめ)
-
著者の大嶋さんはUdemyの講師としても有名な方です。大嶋さんが運営されているStudyCoの勉強会では私も登壇機会をいただき、貴重な経験をすることができました。最先端のAIを学び続けるだけでなく、それを教え続けているのがすごいです。 ↩
-
拙作の「誰でもわかる全文検索入門」より。 ↩