注意
この記事には画像生成AIが生成した画像を貼っているので、人によっては不気味に見えるものや不安定な気持ちになるものが含まれているかもしれません。そういうのが苦手な人は読まない方がいいかもです。
はじめに
弊社では幼稚園保育園を中心に運動会をはじめとした季節行事の写真の撮影・販売をするサービスを運営しているのだが、そのサービスの中ではいろいろな写真が売られている。
1人のこどもがアップで写っているもの、何人かのこどもが走っている姿を写したもの、何十人ものこどもが一緒に写った集合写真、などなど...。
しかし、いつも自分が手元でやるテストではネットで拾ってきたフリー素材の写真を利用しており、画像の構図などはあまり気にしたことがない。
正直、これは全然リアリティがない。
特に集合写真は一番リアリティがない。
集合写真って言ってるのに、実態に即した写真(つまり20人くらいが写っている写真)でテストをした記憶がない。
というのも、そもそも何十人もの人間が写っている写真があまりネット上に素材として転がっていない。
でも、そもそも現代の技術を使えばネットで探す必要すらないんじゃないか?
ということで、画像生成AI(StableDiffusion)を用いて高画質な集合写真を生成するチャレンジをしてみた。
StableDiffusionとは
StableDiffusionはいわゆる画像生成AIの一種で、使った感じで雑に説明するとPromptと呼ばれる文章(こんな画像を作ってね)とNegativePromptと呼ばれる文章(でもこんな要素は入れないでね)の2つを渡したらいい感じの画像を生成してくれるやつだ。
例えば
Prompt:
fluffy dog,pekingese
NegativePrompt:
big dog
を渡したらこんな感じの画像が返ってくる。

紛れもなくふわふわの短頭種の小型わんちゃんだ。
これを使えばいい感じに思い通りの画像が吐けそうだ。
実際に使ってみた
ここからは実際に高画質な集合写真を吐くためにやったことを書いていく。
とりあえずやってみる
手持ちのMacでローカルでの動作をやってみたのだが、スペックの問題でうまくいかなかったのでGoogleColaboratoryを使ってクラウド上で環境を構築する方針でやってみた。
課金しないとStableDiffusionが使えないようになっているらしいので、とりあえずColabProに課金してStableDiffusionをインストールしてみる。
今回はStableDiffusionをGUIで使えるようにするStableDiffusionWebUIと呼ばれるものの中でも人気が高そうなAUTOMATIC1111版StableDiffusionWebUIを導入することにした。
まずはColaboratory上で新しいNotebookを作成して以下のコマンドを記述し実行。
!git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui
%cd /content/stable-diffusion-webui
!python launch.py --share --enable-insecure-extension-access --xformers
そしたらウニョウニョとそれっぽい出力がされてRunning on public URL: https://hogehoge.gradio.liveみたいなURLが出力される。
gradioはAI界隈のngrokみたいなものっぽいです。(ちゃんと知りたい人は自分で調べてみてね。)
それを押すとStableDiffusionWebUIの画面が開かれる。
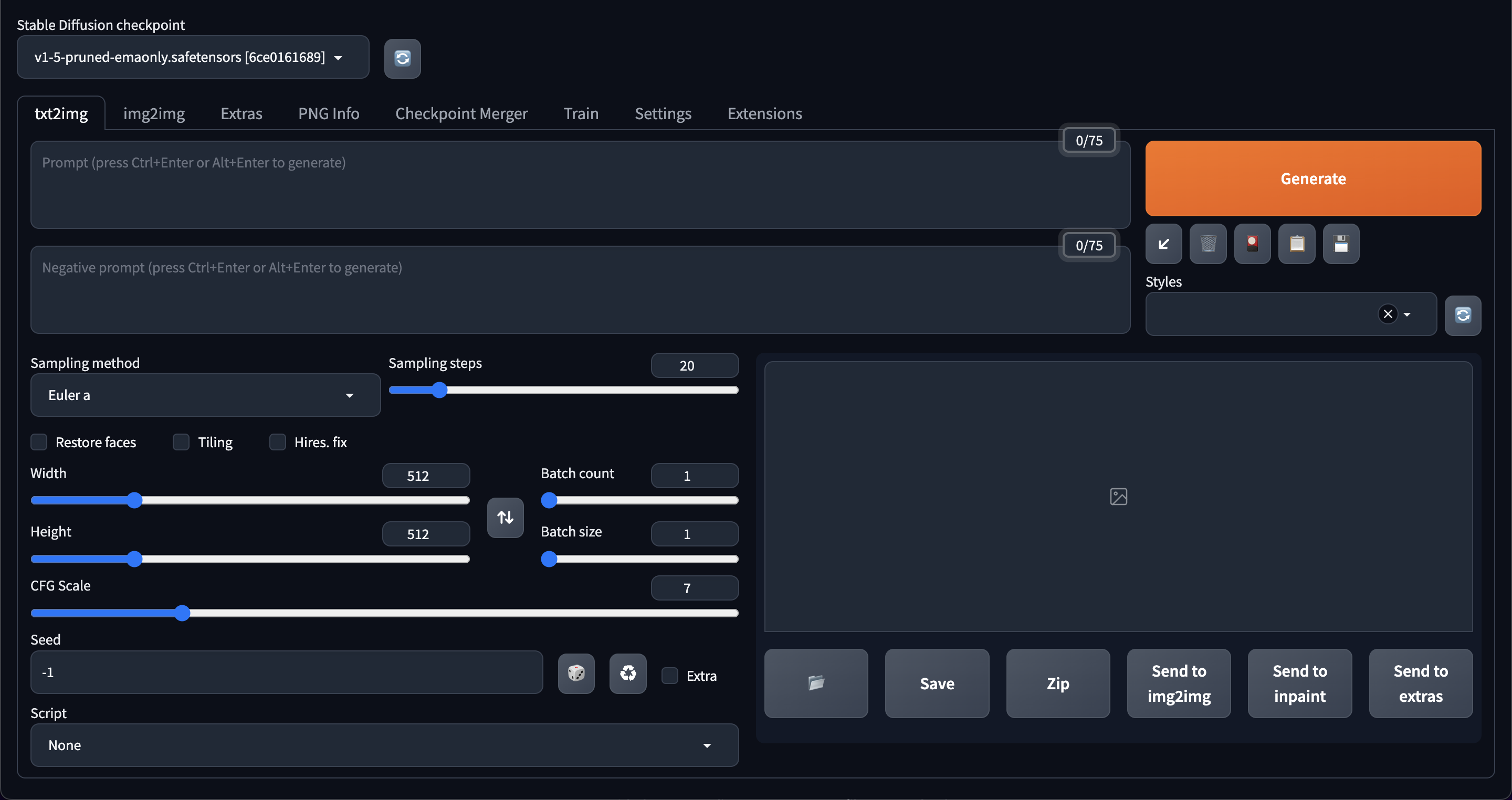
ちゃんと起動できてるっぽいので、とりあえずそれっぽいPromptを渡して吐いてみる。
Prompt:
10 people, students
その結果、吐かれた画像がこちら。

人間を馬鹿にするのも大概にしてほしい。
まず、15人いる。
そして、全然studentsじゃない。
あと、顔が怖い。
もしかしたら純正だとうまくいかないのかもしれないと思いもう少し調べてみた。
Modelを導入
画像生成AIは適切なModel(強化された学習データと思っとけばよさそう)を入れることでより強力な画像が生成できるらしい。
このModelはHuggingFaceっていうところにゴロゴロ転がってるみたいなので、今回は権利とかも問題なさそうでいい感じに実績もあって写真っぽく人物が生成できそうなBRAv6を使っていく。
さっきのNotebookの記述を
!git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui
%cd /content/stable-diffusion-webui
!wget -O /content/stable-diffusion-webui/models/Stable-diffusion/Brav6.safetensors https://huggingface.co/BanKaiPls/AsianModel/resolve/main/Brav6.safetensors
!python launch.py --share --enable-insecure-extension-access --xformers
に変えて実行。
起動したのでさっき追加したModelを選択して前回と同じPromptで画像を吐いてみる。

よさそう。相変わらず10人じゃないがこれは紛れもなく学生だ。
Modelの導入1つでここまで話が分かるやつになってくれた。
高画質化
ここまでは512x512の画像を出力してきたが、最終的にほしいのはある程度高画質の集合写真なので最低でも3600x2400くらいでは出力する必要ある。
実はいきなり100段飛ばしでいけるんじゃないかと思い、いきなり3600x2400の画像を生成しようと思ったがさすがにOut Of Memoryだった。
正面突破は無理そうなので他の方法でアプローチすることにする。
Hires.fix & Extras
AUTOMATIC1111版に標準搭載されているアップスケールの機能であるHires.fixとExtrasを利用して拡大をしてみることにする。
一旦SamplingMethodとかPromptとかNegativePromptとかをいい感じに調整して、まず600x400の画像を吐くように設定してみる。
Prompt:
best quality,masterpiece,ultra high res,(photo realistic:1.4),10 girls,group picture,autumn,japanese,wide shot
NegativePrompt:
(nsfw:2),painting,sketches,logo,watermark,txt,(worst quality:2),(low quality:2),(normal quality:2),monochrome,grayscale,ugly face,bad hands,bad arms,missing fingers
一応Promptの意図としては
best quality,masterpiece,ultra high res -> 綺麗な画像を出してね
(photo realistic:1.4) -> 写真風で出してね(この要素は通常の1.4倍強調)
10 girls,group picture -> 女の子の集合写真を出してね(性別を固定にした方が出力が安定したから)
autumn -> 秋っぽい画像出してね(上下とも肌が比較的隠れていて帽子なども被っていない率が高いから)
japanese -> 日本人の画像を出してね
wide shot -> 引きの画像を出してね
といった感じだ。
NegativePromptはそれっぽいのを色々つけているのだが、NSFW(Not Safe For Work)をつけないと記事に載せられない画像を平気で生成してくるので強めに指示しておく。
結果、まず吐かれたのがこちら。

相変わらず10人というこちらの指示は無視しているし顔は怖いが、最終的に意図していた集合写真の見た目に近いのでこれを採用することにする。
これをHires.fixで3倍の1800x1200にアップスケールしたものがこちらだ。

3倍にアップスケールする過程でかなりいい感じに情報が補完され始めている。
後ろの木々もいい感じに緻密になったし、みんなの顔もだんだん判別できるようになってきた。
これをさらにExtrasという別の方式のアップスケーラーに食わせて2倍の3600x2400までアップスケールしたものがこちらだ。

ちゃんと画像は大きくなったが、木々はぼやけているし、顔は歪んでいるし、エッジはガビガビだ。
ちょっとこれで完成ですと出すわけにはいかないので他のアプローチをしてみる。
TiledDiffusion
調べてみるとTiledDiffusionと呼ばれる拡張を用いると画像のアップスケールが可能なようだ。
これも同じように600x400->1800x1200->3600x2400にする方針で試してみる。
元となる画像は前回作った600x400の画像とする。
ということで、TiledDiffusionに食わせて一旦1800x1200にアップスケールしたものがこちら。

多少画像の構造が変わったりしているが比較的いい方だと思われる。
相変わらずこの時点では顔は歪んだままだ。
ここでさらにこいつをTiledDiffusionに食わせて3600x2400にアップスケールしたものがこちら。

かなり綺麗に出ているんじゃないだろうか。
木々も鮮明だし、顔もちゃんと認識できるし、エッジも綺麗だ。
これなら高画質の集合写真を吐けるようになったと言えるのではないだろうか。
困ったところ
無事高画質の集合写真を吐くことができるようなったが困った部分はいろいろあったので、せっかくなので書き出しておく。
人数が安定しない
当初から問題だったのだが、10 girlsで指定しても平気で1人や30人、果てには遠近的に画面を埋め尽くすほどの人間を出力してくるときもあった。
検索しても上記の方法で人数が指定できるとしている情報が多く、なぜ出力が安定しないのかが本当に不明だ。
強調するために(10 girls:1.5)などの記述もしてみたが、結果に特に影響を与えているとは思えなかった。
また、メンバーから「10ではなくtenで指定したら単語として認識できるのでは?」という意見があったため試してみたのだが、結果は変わらず人数は安定しなかった。
Modelによってはもっと文章として渡してあげると出力が安定するという話も聞いたためten girls are linking arms and laughingといった感じの描写を与えてみたが、これも変わらず人数は安定しなかった。
これがModelの問題なのか、何かしらの指定の仕方があるのかは謎だ。
個人的に推しているのは「AIは人数という概念をまだよくわかっていない」という説だ。
もし正しい指定の仕方を知っている人がいたら教えてほしい。
画像が崩壊する
TiledDiffusionを利用して画像を高画質にするときに画像が崩壊することが頻繁に発生していた。
完全に崩壊することもあるし、画像の内容がクリティカルに変更されるときもあった(5人の画像が8人の画像になるなど)。
実際に完全崩壊を起こした画像の例を挙げると

上記の画像はもう説明不要にむちゃくちゃだ。
高画質にする際のノイズ除去率を高く設定しすぎると、描写が緻密になるかわりにAIがいい感じに補完するところが増えるためおかしくなるようだ。
特に上記に記載したように人数指定が1かmanyかでしか理解できていないとなると、人のパーツっぽい描写に見えるところは人のパーツとして描写してしまうようだ。
ここに関しては崩壊するギリギリのノイズ除去率に調整することで限界まで描写を緻密にしつつむちゃくちゃな画像が出ないようにすることで回避することができた。
また、AIは人体構造を理解してはいないので腕や脚が3本あったり、誰の手かもわからない手が肩に置かれていたり、服の途中から髪の毛が生えていたりという人体構造上あり得ない出力がされたりする。
それを制御するためのNegativePromptの記述をしているのだが、どうもこの人数になってくるとそれで制御するのは難しいようだった。
狙った顔が出せない
一番の問題はこれだ。
結局複数人が写っている写真で同じ人間がいろんな場面に登場するみたいな写真を複数枚生成する方法が分からなかった。
なので当初の目的でもあった、よりリアリティのある写真を生成するというところはまだ半分ほどしか達成しきれていない。
これももし集合写真のような形式の画像に特定の人物を狙って混ぜる方法を知っている人がいたら教えてほしい。
おわりに
今回はStableDiffusionでの画像生成にチャレンジしてみた。
よりリアリティのある画像でローカルのテストをしたいという願望を満たすためにはまだ解決するべきことが多くあるようだが、触る機会を逃していた画像生成AIに触れる機会が得られたことは大きな収穫であったと思う。
より画像生成AIの使い方に詳しくなれば、より実際に取り扱っている写真に近い構図の写真を生成できるはずなので、そういったリアリティを再現するべく今後もAIで遊んでいきたいと思う。