Watson Studioを使用して類似画像検索を試して見たので、手順を記載しておきます。
参照先
方法やコードは以下リンク先の情報をだいぶ活用させていただきました。
https://jifuzhao.github.io/2018/04/13/landmark.html
https://github.com/JifuZhao/Landmark-Recognition
データセット
上記リンク先の通り Google Landmark Recognition Dataset を使用しています。こちらのデータセットには世界各地のランドマーク(名所等)の画像(約11万箇所、120万枚)が提供されており、トレーニングデータ(train.csv)には以下のようなフィールドが含まれています。
| 列名 | 説明 | 例 |
|---|---|---|
| id | 各画像に固有のid | 97c0a12e07ae8dd5 |
| url | 画像のダウンロード先 | http://lh4.ggpht.com/-f8xYA5l4apw/RSziSQVaABI/AAAAAAAAASE/V8rWCdC0cvI/s1600/ |
| landmark_id | ランドマーク毎に固有のid | 6347 |
ここではデータセットのサブセット(1000箇所、1万枚、224x224にリサイズ)を使用して類似画像検索を実装します。
1. データの準備
以下から上記に記載のデータのサブセットdata.zipをダウンロードします。
https://ibm.box.com/shared/static/edtoxjtlvtvd1jdlyls2hqzwoey0js6q.zip
Watson Studioで新規プロジェクトを作成後に、以下のURLからNotebookを作成します。
https://github.com/schiyoda/ImageSimilaritySearch/blob/master/1_Data_Preparation.ipynb
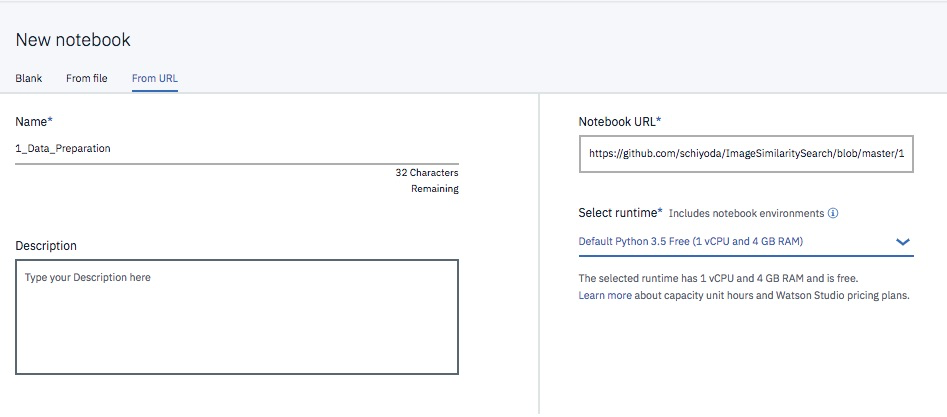
Notebook右側のDataパネルから先ほどダウンロードしたdata.zipを追加します。
Notebook一番上の空のセルにカーソルを合わせ、追加したデータの "Insert to code" -> "Insert Credentials" を選択します。
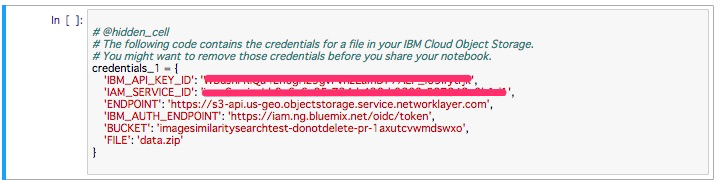
以下のようにNotebookにcredentialが追加されます。(credential名が"credential_1"になっていない場合は修正します)
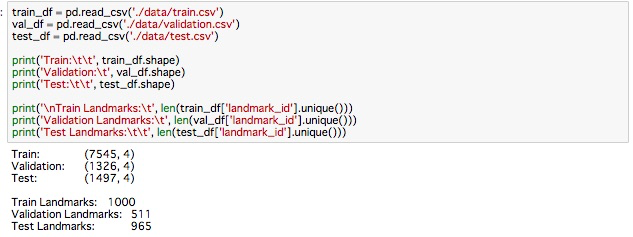
Notebookのセルを全て実行し、データの中身を確認します。
2. 学習済みモデルを使用した類似画像検索
ここではCNNで学習済みのモデルInception V3を使用して画像の類似検索を実装します。学習済みのモデルに画像を投入すると、特徴量をベクトルとして抽出することができます。K-NN(K近傍法)でベクトル間の距離を計算することで、距離が短いほど類似しているとみなすことができます。
2.1. 特徴ベクトルの抽出
特徴ベクトルの計算は計算量が多く時間がかかるため、Watson Studioに実装されたディープラーニング機能(DLaaS)を使用します。
まず、先ほどダウンロードしたdata.zipをDLaaSで使用できるようにObject Storageにアップロードします。アップロードの仕方は以下のリンク先等を参照してください。
https://qiita.com/ishida330/items/b093439a1646eba0f7c6#icosibm-cloud-object-storage%E5%81%B4
https://qiita.com/schiyoda/items/c1fe7438e50087ff97ef
私はCyberduckでアップロードしましたが、アップロード後にバケットの直下にdata.zipが置かれています。
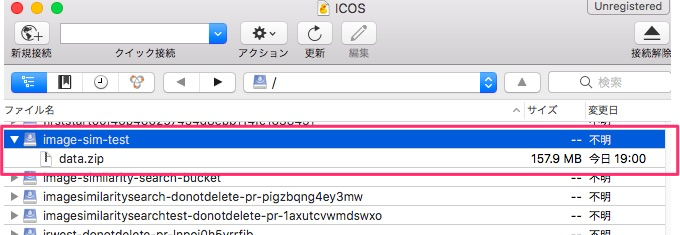
以下のpython のコードをダウンロードして zip に圧縮します。こちらのコードでは Train、Validation、Test の各画像から各々2048次元の特徴ベクトルを抽出し、NumPy array としてObject Storageに保存します。
https://raw.githubusercontent.com/schiyoda/ImageSimilaritySearch/master/2.1_extractFeatureInceptionV3.py
Watson Studioで新規experimentを作成します。
Machine Learning Serviceは新規あるいは既存のサービスを設定します。
"Cloud Object Storage bucket for storing training source files" の "Select"をクリック -> "New Connection" タブで適当な名前を指定します。さらに、source dataとしてdata.zipをアップロードしたバケットを指定します。
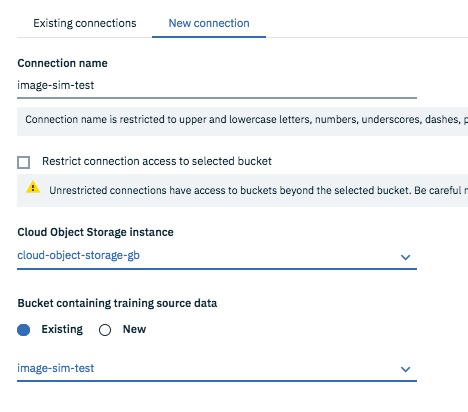
"Cloud Object Storage bucket for storing results"も同じものを指定すればOKです。
右側の をクリックします。
をクリックします。
適当な名前をつけて、"Training source code"に先ほどzip にしたコードを指定、"Framework"は "tensorflow 1.5"、"Execution command" は以下のように指定します。
python3 2.1_extractFeatureInceptionV3.py
右側のCompute planを選択し、"Create"を選択します。
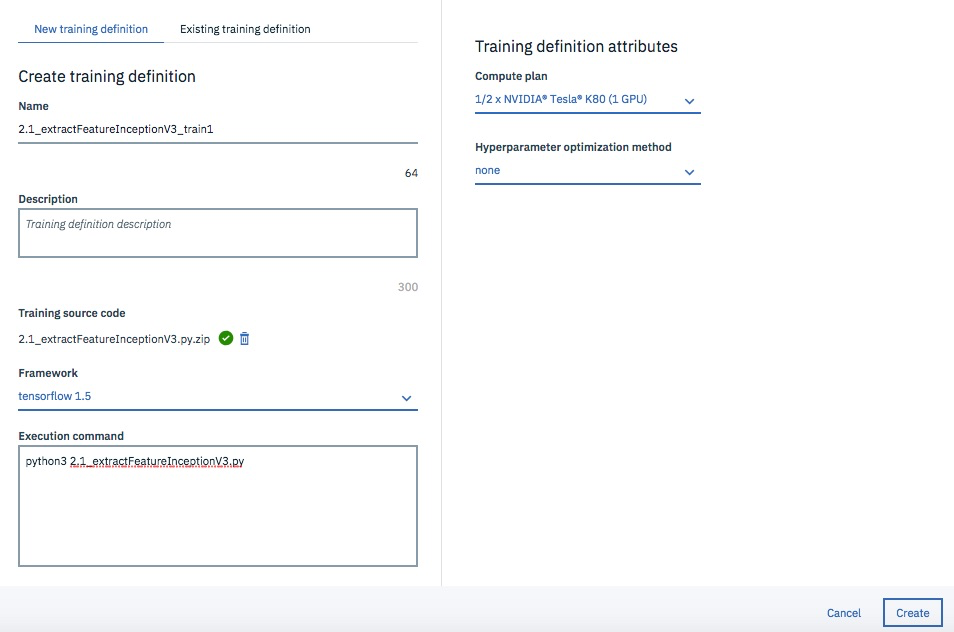
さらに次の画面で"Create and run"を選択すると、処理が待ち行列に入り(Queued)、しばらくすると実行中(In progress)になります。
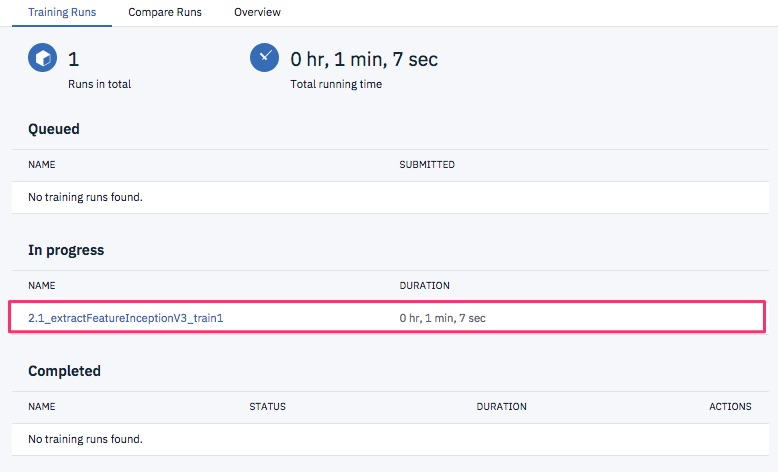
処理が完了すると、以下のように表示されます。

Object Storageに特徴ベクトルが保存されたようです。
エラーになった場合はログを確認し、エラー箇所を修正した上で、"Add training runs"で再度 training definition を作成します。
2.2 画像類似度の算出
抽出された各画像の特徴ベクトルから、画像間の類似度を算出します。
以下のURLから新規Notebookを作成します。
https://github.com/schiyoda/ImageSimilaritySearch/blob/master/2.2_predictInceptionV3.ipynb
Notebook一番上の空のセルにカーソルを合わせ、Connectionsの "Insert to code"を選択します。
以下のようにNotebookにcredentialが追加されます。(credential名が"credential_1"になっていない場合は修正します)

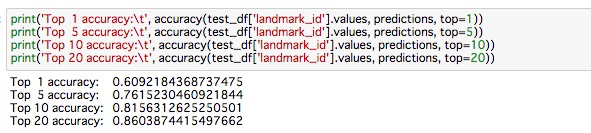
2つ目のセルでバケット名を指定した上で、セルを全て実行します。以下のように Accuracy が表示されます。
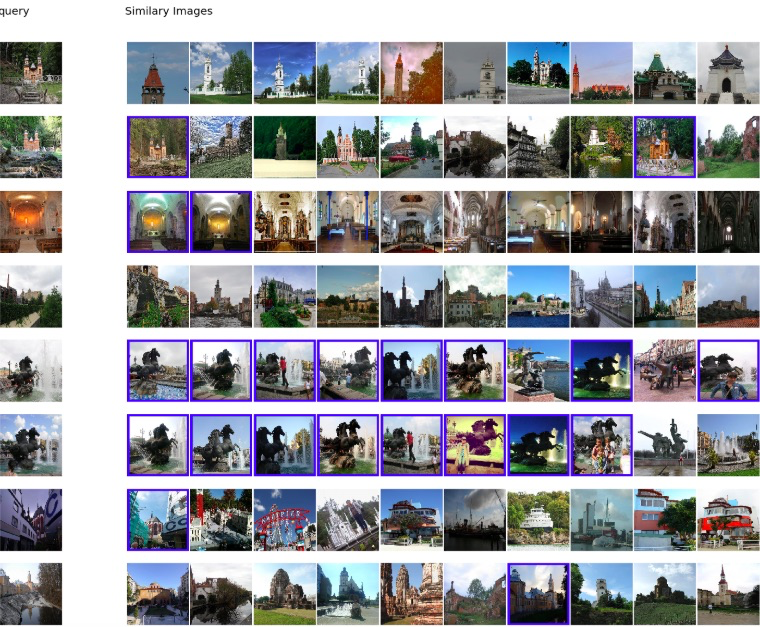
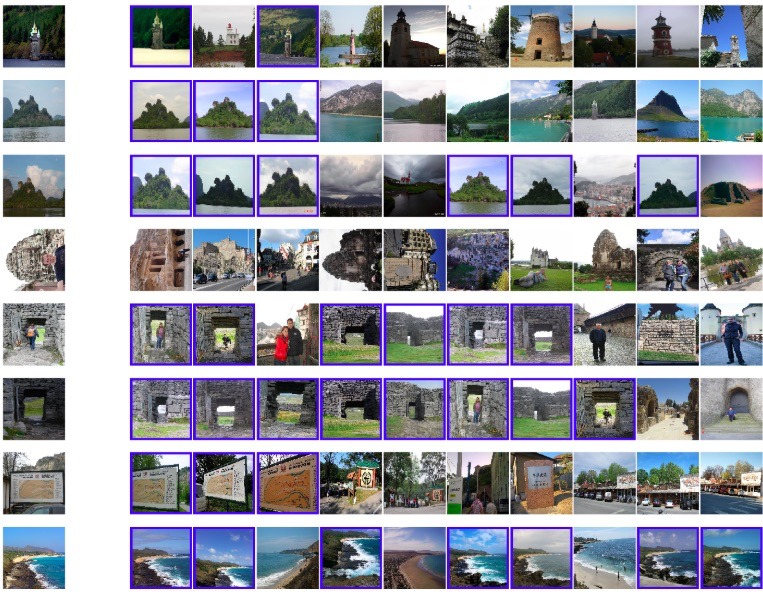
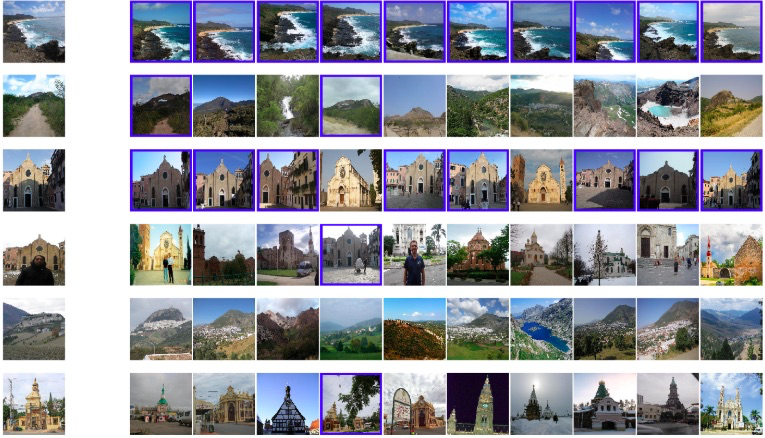
検索された画像は以下の通りです。一番左の画像が Queryの画像で、左から類似度が高い順に10件表示しています。青枠で囲った画像がQuery画像と同じlandmark_id(同じ場所)を表しています。