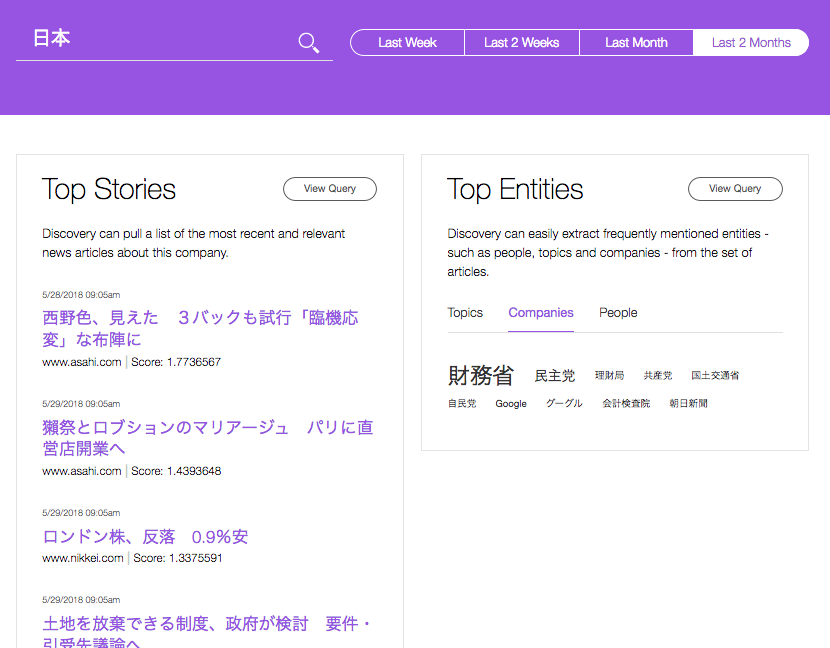
前回は Watson Discovery で Webクローリングを試して、ニュース記事を Discovery に投入してみました。ただ、ニュース記事だけでなく、周りのメニュー等のテキストも入ってきてしまっているので、今回は Web ページの必要な箇所のみ切り出す方法については考えてみたいと思います。
Apatch Nutch ではプラグインで必要な機能を拡張できるような仕組みになっています。「Discovery にデータを投入する」機能も indexer をプラグインで拡張しているものになります。今回は 「Web ページの必要な箇所のみ切り出す」機能をプラグインで実装しようと思います。
設定手順
今回は既存の jsoup-extractor プラグインが使いやすそうだったので、こちらを使ってみます。これは cssSelector で Webページ(HTML) の特定の箇所を抽出できるプラグインで parser の機能を拡張するものになります。
ソースコードの取得&ビルド
jsoup-extractor プラグインを含むソースコードを Github 上に作成したので、以下のように取得します。
git clone https://github.com/schiyoda/nutch-indexer-discovery.git
前回と同じように buildPlugin まで進めます。
$ ./gradlew
$ ./gradlew setupHbase
$ ./start-hbase.sh
conf/nutch-discovery/nutch-site.xml の修正
$ ./gradlew setupNutch
$ ./gradlew buildPlugin
少し解説
前回使用したソースコードとの違いを解説します。今回はこちらにある jsoup-extractor を使用するために、nutch の build/apache-nutch-2.3.1/src/plugin フォルダに jsoup-extractor を含めた上でビルドをしています。jsoup-extractor を使用するために nutch-site.xml 以下のような設定をしています。
<property>
<name>plugin.includes</name>
<!-- do **NOT** enable the parse-html plugin, if you want proper HTML parsing. Use something like parse-tika! -->
<value>protocol-httpclient|urlfilter-regex|parse-(text|tika|js)|jsoup-extractor|index-(basic|anchor)|query-(basic|site|url)|response-(json|xml)|summary-basic|scoring-opic|urlnormalizer-(pass|regex|basic)|indexer-discovery</value>
</property>
<property>
<name>jsoup.extractor.property.file</name>
<value>jsoup-extractor.xml</value>
</property>
また、Web ページによっては Nutch が取得するサイズの最大サイズのデフォルトに引っかかる場合があるので、最大サイズを無制限(-1)に変更しています。
<property>
<name>http.content.limit</name>
<value>-1</value>
</property>
クロールの設定
seed/url.txt、build/apache-nutch-2.3.1/runtime/local/conf/regex-urlfilter.txt、crawlスクリプト は前回と同じように設定します。
http://www.asahi.com/news/
https://www.nikkei.com/news/category/
+^https?://www.asahi.com/news/$
+^https?://www.asahi.com/articles/[0-9a-zA-Z_]+\.html$
+^https?://www.nikkei.com/news/category/$
+^https?://www.nikkei.com/article/[0-9a-zA-Z_]+/$
# accept anything else
# +.
# Generate a new set of URLs to fetch. topN parameter decides how many pages nutch should crawl per depth. If you estimate a website to have 3000 pages then you can specify a depth value of 3 and a topN value of 1000 for a successful crawl of 3000 documents.
echo "Generate urls: "
__bin_nutch generate -topN 100
今回は新たに jsoup-extractor プラグインの設定ファイル build/apache-nutch-2.3.1/runtime/local/conf/jsoup-extractor.xml を修正します。このファイルでは cssSelector で HTML からの抽出箇所を指定することができ、例えば asahi.com の記事のソースを見ると、記事のテキスト部分は "div.ArticleText" で指定することができます。
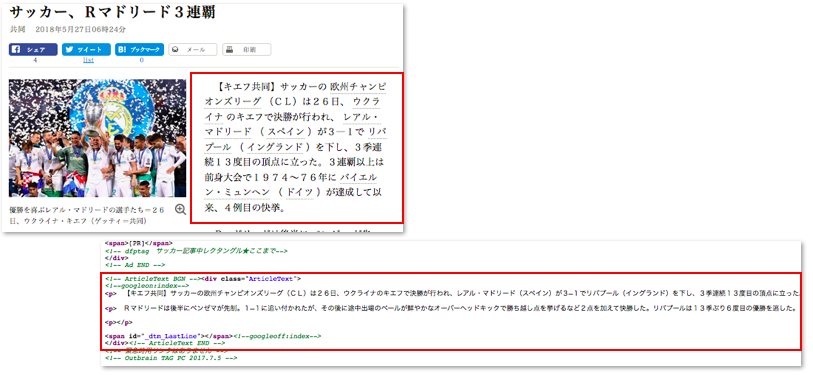
今回は以下のように設定してみました。
<documents>
<document url-pattern=".*//www.asahi.com/articles/.*" >
<field name="text2">
<css-selector>div.ArticleText</css-selector>
<normalizer>simpleNormalizer</normalizer>
</field>
</document>
<document url-pattern=".*//www.nikkei.com/article/.*" >
<field name="text2">
<css-selector>div.cmn-article_text</css-selector>
<normalizer>simpleNormalizer</normalizer>
</field>
</document>
</documents>
Discovery の Collection 設定
この設定により抽出したニュース記事は"text2"フィールドに保存されるので、Discovery の Configurationでは "text2" フィールドのエンリッチ対象を "cotegories" と "concepts" を選択します。
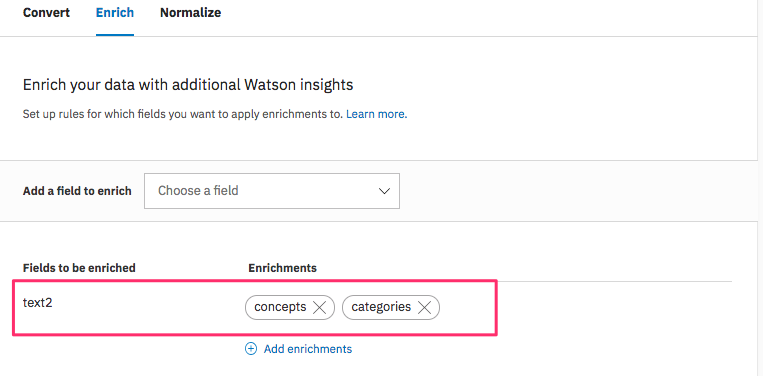
クロール実施
crawl コマンドで取得すると、"text2" フィールドに必要なニュース記事が取得できたことが分かります。また、"cotegories" や "concepts" も抽出できていました。

おまけ
Nutch のプラグインの仕組みをうまく使用すると、Discovery に取り込むデータをよりリッチにすることができます。ニュース記事の場合、記事の日付や固有表現(人名、組織名)等も合わせて取り込むことで、より高度な記事の活用につなげることも可能です。以下リンク先ではそのようなデモも紹介していますのでご参照ください。