初めに
どうも、クソ雑魚のなんちゃてエンジニアです。
本記事はコロナ禍になり急激に増えていたフィッシング詐欺に着目し、
今後のフィッシングメールの増加傾向を機械学習を用いて予測してみようといった記事である。
昨今のフィッシングメールの詳細な傾向については過去記事の以下のものを参考にしてほしい。
※今回は1フィッシングメールに着目するというより、大局的に世の中でどのようにフィッシングの傾向があるのか分析する。
簡単★フィッシングサイト構築
フィッシング詐欺を様々なWebサイトを用いて見破る方法
目次
- 調査するためのデータ源
- 使用する機械学習
- Prophet
- 環境構築
- Pythonコード
- 実行結果
- 手順
- 結果
- まとめ
調査するためのデータ源
今回調査するために用いるのは「フィッシング対策協議会」の月次報告で逐次報告されているフィッシング報告件数を源とする。
APIやスクレイピングで取ってくることも考えたが、基本的に画像データであることと、データ数もそこまで多くないことから
手動でデータをCSVに叩き込んだ(笑)
※いけてない
使用する機械学習
Prophet
Facebookさんが開発した時系列データ分析特価の機械学習パッケージである。
Pythonで動くので今回はDocker上にAnaconda環境を構築し、そこで分析していく。
以下のQuiita達を参考にしてみてもいいと思う。
環境構築
Docker上にAnaconda環境を構築し、Jupyterを起動させて分析を行っていく。
環境構築のために以下のDockerfile, docker-compose.ymlを作成した
FROM continuumio/anaconda3:2021.05
RUN mkdir /code && \
pip install --upgrade pip && \
conda update conda && \
conda install -c conda-forge pystan && \
conda install -c conda-forge fbprophet && \
pip install optuna
WORKDIR /code
EXPOSE 8888
ENTRYPOINT ["jupyter-lab", "--ip=0.0.0.0", "--port=8888", "--no-browser", "--allow-root", "--NotebookApp.token=''"]
CMD ["--notebook-dir=/code"]
※パッケージはcondaやpipで直でインストールしている。
version: '3.7'
services:
learn:
build: ./Anaconda
volumes:
- ./code:/code
ports:
- "8080:8888"
※上記のようにローカル環境にcodeのディレクトリ階層を作成し、この配下にPythonコードを書いていく。
DockerfileはAnaconda階層に格納している。
Pythonコード
モデルを通常のパラメータを用いたモデル(Model1)とパラメータ探索を用いて、最適化されたパラメータを用いたモデル(Model2)の2つを用意した。
import pandas as pd
from fbprophet.diagnostics import cross_validation
from fbprophet.diagnostics import performance_metrics
from matplotlib import pyplot as plt
from matplotlib.dates import MonthLocator, num2date
from matplotlib.ticker import FuncFormatter
import Model_Class as MC
def Model_1(months):
#PandasでDBの値を読み込み
df_db = pd.read_csv('./DB/Phishing.csv')
#モデル作成
Nomal_model = MC.Model_Nomal_Prophet(months)
#モデルフィット
model_on_code = Nomal_model.model.fit(df_db)
#予測していく
future_data_on_code = Nomal_model.Nomal_FutureFrame()
forecast_data_on_code = model_on_code.predict(future_data_on_code)
#プロット
fig0 = model_on_code.plot(forecast_data_on_code)
fig1 = model_on_code.plot_components(forecast_data_on_code)
※「code/DB/」階層にあるフィッシング対策協議会から拝借したCSVデータをPandasで読み込み、別Pythonファイルで記述したモデルClassファイルへ渡す。
帰ってきた予測データをプロットしていくまでがこのファイルのお仕事である。
import pandas as pd
from fbprophet.diagnostics import cross_validation
from fbprophet.diagnostics import performance_metrics
from matplotlib import pyplot as plt
from matplotlib.dates import MonthLocator, num2date
from matplotlib.ticker import FuncFormatter
import numpy as np
import Model_Class as MC
def Model_2(months, train_time):
#PandasでDBの値を読み込み
df_db = pd.read_csv('./DB/Phishing.csv')
df_db = df_db.astype({'y': int})
#ハイパーパラメータに合わせたモデル作成
cap = int(np.percentile(df_db.y,95))
floor = int(np.percentile(df_db.y,5))
#モデル作成
Hyper_model = MC.hyper_search_model(months, train_time)
Hyper_model.Create_Model(df_db)
df_db['cap']=cap
df_db['floor']=floor
#モデルフィット
model_on_code = Hyper_model.model
model_on_code.fit(df_db)
#予測していく
future_data_on_code = Hyper_model.Hyper_FutureFrame()
future_data_on_code['cap'] =cap
future_data_on_code['floor'] =floor
forecast_data_on_code = model_on_code.predict(future_data_on_code)
#プロット
fig0 = model_on_code.plot(forecast_data_on_code, xlabel='Date', ylabel='Phishing_Count')
fig1 = model_on_code.plot_components(forecast_data_on_code)
※Model1と違い、ハイパーパラメータ探索を用いたモデルがこのModel2である。
from fbprophet import Prophet
from matplotlib import pyplot as plt
from matplotlib.dates import MonthLocator, num2date
from matplotlib.ticker import FuncFormatter
import numpy as np
import optuna
from sklearn.model_selection import train_test_split
# 簡易なデフォルトモデル
class Model_Nomal_Prophet(object):
def __init__(self, days):
self.__days = days
self.model = Prophet(mcmc_samples=300)
#グラフプロット関数のラベル変更
def plot(self, fcst, ax=None, uncertainty=True, plot_cap=True, xlabel='ds', ylabel='y', figsize=...):
xlabel = 'Date'
ylabel = 'Phishing_Count'
return self.model.plot(fcst, ax=ax, uncertainty=uncertainty, plot_cap=plot_cap, xlabel=xlabel, ylabel=ylabel, figsize=figsize)
#予測期間における、フレーム作成
def Nomal_FutureFrame(self):
future = self.model.make_future_dataframe(periods=self.__days, freq = 'm')
return future
# 簡易評価グラフプロット
class figure_draw(object):
#MSE、MAPEのプロット
def plot_MSE_MAPE(self, data):
fig = plt.figure()
ax1 = fig.add_subplot(2, 1, 1)
ax1.plot(data['horizon'], data['mse'])
ax1.set_xlabel("days elapsed")
ax1.set_ylabel("MSE")
ax2 = fig.add_subplot(2, 1, 2)
ax2.plot(data['horizon'], data['mape']);
ax2.set_xlabel("days elapsed")
ax2.set_ylabel("MAPE")
return fig
# ハイパーパラメータ探索モデル
class hyper_search_model(object):
def __init__(self, days, train_time):
self.__days = days
self.__train_time = train_time
def __objective_variable(self, train,valid):
'''`ハイパーパラメータ策定関数
'''
train = train.astype({'y': int})
valid = valid.astype({'y': int})
cap = int(np.percentile(train.y,95))
floor = int(np.percentile(train.y,5))
def objective(trial):
#ハイパーパラメータ定義
params = {#探索範囲指定
'changepoint_range' : trial.suggest_discrete_uniform('changepoint_range',0.8,0.95,0.001),
'n_changepoints' : trial.suggest_int('n_changepoints',20,35),
'mcmc_samples' : trial.suggest_int('mcmc_samples',30,66),
'changepoint_prior_scale' : trial.suggest_discrete_uniform('changepoint_prior_scale',0.001,0.5,0.001),
'seasonality_prior_scale' : trial.suggest_discrete_uniform('seasonality_prior_scale',1,25,0.5),
'yearly_fourier' : trial.suggest_int('yearly_fourier',5,15),
'quaterly_fourier' : trial.suggest_int('quaterly_fourier',3,10),
'yearly_prior' : trial.suggest_discrete_uniform('yearly_prior',1,25,0.5),
'quaterly_prior' : trial.suggest_discrete_uniform('quaterly_prior',1,25,0.5)
}
# モデル作成
m=Prophet(
changepoint_range = params['changepoint_prior_scale'],
n_changepoints=params['n_changepoints'],
changepoint_prior_scale=params['changepoint_prior_scale'],
seasonality_prior_scale = params['seasonality_prior_scale'],
yearly_seasonality=False,
weekly_seasonality=False,
daily_seasonality=False,
growth='logistic',
seasonality_mode='additive',
mcmc_samples=params['mcmc_samples'])
m.add_seasonality(name='yearly', period=365.25, fourier_order=params['yearly_fourier'],prior_scale=params['yearly_prior'])
m.add_seasonality(name='quaterly', period=365.25/4, fourier_order=params['quaterly_fourier'],prior_scale=params['quaterly_prior'])
train['cap']=cap
train['floor']=floor
#モデルフィット
m.fit(train)
#予測範囲のフレーム作成
future = m.make_future_dataframe(periods=len(valid))
future['cap']=cap
future['floor']=floor
#モデルでの予測
forecast = m.predict(future)
valid_forecast = forecast.tail(len(valid))
#MAPEに従って実値と比較評価
val_mape = np.mean(np.abs((valid_forecast.yhat-valid.y)/valid.y))*100
return val_mape
return objective
def __optuna_parameter(self, train,valid):
#optunaクラス定義
study = optuna.create_study(sampler=optuna.samplers.RandomSampler(seed=42))
#指定したtrain_timeの間探索する
study.optimize(self.__objective_variable(train,valid), timeout=self.__train_time)
#最適なハイパーパラメータのセッティング
optuna_best_params = study.best_params
return study
def Create_Model(self, df_tmp):
#train, testで分割し、ハイパーパラメータを適用したモデル作成
df_train, df_test = train_test_split(df_tmp)
study = self.__optuna_parameter(df_train, df_test)
model = Prophet(
changepoint_range = study.best_params['changepoint_prior_scale'],
n_changepoints=study.best_params['n_changepoints'],
seasonality_prior_scale = study.best_params['seasonality_prior_scale'],
changepoint_prior_scale=study.best_params['changepoint_prior_scale'],
yearly_seasonality=False,
weekly_seasonality=False,
daily_seasonality=False,
growth='logistic',
seasonality_mode='additive',
mcmc_samples = study.best_params['mcmc_samples'])
model.add_seasonality(name='yearly', period=365.25, fourier_order=study.best_params['yearly_fourier'],prior_scale=study.best_params['yearly_prior'])
model.add_seasonality(name='quaterly', period=365.25/4, fourier_order=study.best_params['quaterly_fourier'],prior_scale=study.best_params['quaterly_prior'])
self.model = model
def Hyper_FutureFrame(self):
future = self.model.make_future_dataframe(periods=self.__days, freq = 'm')
return future
※モデルのクラス定義である。Model2ではOptunaのパッケージを用いてハイパーパラメータ探索を行っている。
※以下のQuiitaを参考にしてほしい。
また、今回のフィッシング対策協議会のデータは月単位データなのでマルコフ連鎖モンテカルロ法(MCMC)を用いて欠損値をサンプリングし乱数生成しています。
参考程度の予測と考えてください。
実行結果
手順
上記コードは以下のGitHubに公開しているのでまずCloneを行い、docker-compose.ymlを起動。
$git clone https://github.com/schecthellraiser606/Phishing_count_Predict
$cd Phishing_count_Predict/
$docker-compose up -d
Docker起動を確認出来たらブラウザから「localhost:8080」へ接続し、Jupyterへ接続する。
接続すると以下のような画面が出てくるはずである。
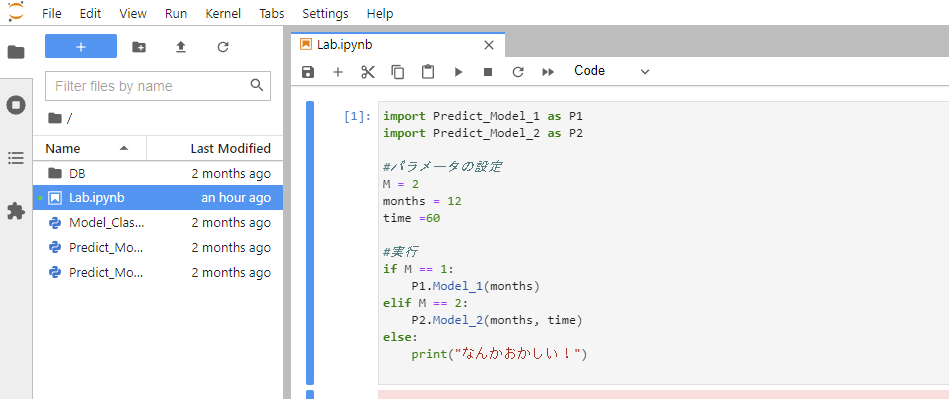
起動後は「▶」ボタンを押して機械学習開始である。
結果


こんな感じである。
【グラフ説明】
黒点:実データ
青線:予測線
青枠:信頼区間80%
※上の図が実予測で、下図がトレンド曲線である。
コロナが発生した時期から急速にフィッシングの件数が伸び始めたことがわかる。
だが、だんだんと件数は高い水準で落ち着いてくるようである。
まとめ
第十回の投稿はいかがだったでしょうか?
今回はフィッシング件数の今後の傾向(大局)を機械学習を用いて予測してみた。
今後もセキュリティエンジニアの皆さんの助けになればなと思います。
※もう少しデータ数があれば週単位、月単位での予測が可能なので、フィッシング対策協議会の皆さんにはAPI機能の提供やスクレイピングできるようにデータを画像形式から変更していただきたい。。
データ出してくれるだけでありがたいのですが。。