こんにちは!SCのムロです。JEPX東京エリアのスポット価格予測シリーズ、第2回へようこそ。第1回では、モデルを作る前にまずデータと仲良くなろうということで、探索的データ分析(EDA: Exploratory Data Analysis)——データをひたすらプロットしてパターンを探す作業——を行いました。そこで見えてきたのは次の5点でした。
- 年単位のパターン(年次の季節性):夏と冬、つまり誰もが冷暖房をフル稼働させる時期に価格がピークを迎える。
- 週単位のパターン:工場やオフィスが多くの電力を使う平日は、週末より価格が高い。
- 1日単位のパターン(日内プロファイル):1日の中で価格は決まった形を描く。深夜は安く、日中にかけて高くなり、朝と夕方あたりにピークが来る。
- JEPXの日次平均価格は「非定常(non-stationary)」:つまり日次平均と分散が時間とともに変化するということ。価格の水準も振れ幅も一定の場所に留まらず、移ろっていきます。
- 価格は天候と結びついている:気温と日射量が価格をはっきりと動かしており、これは後でより良い予測を得るのに役立ちます。
第2回では、この知識を活かして、いよいよ最初の予測モデルを作っていきます。考えうる最も素朴な予測から始め、最終的には誤差をほぼ半減させるSARIMAXモデルにたどり着きます。先にお伝えしておくと、ARIMAやSARIMAXはかなり古い手法で、実務で使われることはもう多くありません。でもそれで構いません——ここでのゴールは実用レベルのモデルを作ることではなく、時系列予測がどう動くのかを肌で感じることだからです。一つずつ、アイデアを積み上げていきましょう!
(※本連載のコードはすべてこちらのGitHubリポジトリで公開しています)
第1回からの変更点が2つあります。
-
データセット → 2024年度(2024年4月〜2025年3月):2022年度はエネルギー危機の年で、予測不可能な極端なスパイク(価格は200円/kWhに達しました)がありました。2024年度ははるかに穏やかでクリーンなので、一握りの異常イベントに誤差指標が支配されることなく、モデルの挙動を学ぶのに向いています。

FY2022(赤)とFY2024(青)の30分価格の重ね合わせ。FY2022の夏の約200円/kWhへのスパイクが、FY2024の狭い0〜50円の値動きを圧倒しています。
-
解像度 → 30分(半時間):これは前日市場(day-ahead market)が実際に約定する粒度で、1日48コマあります。後で見るように、この1日の周期こそが最も正確に捉えるべき要素になります。
def load_jepx(path):
s = pd.read_csv(path, index_col=0, parse_dates=True)
s.index = s.index.tz_localize(None) # タイムゾーンを外しJSTの時刻を保持
s.index.name = "datetime"
return s.asfreq("30min")["price"]
y = load_jepx("data/jepx_tokyo_2024.csv") # 2024年度 — 予測対象
新しいEDA:半時間データのACF / PACF
何かを作り始める前に、もう1枚だけプロットを見てみましょう。それは「どの種類のモデルを使えばいいか」を教えてくれるプロットです。**ACF(自己相関関数)**は、価格が「何ステップか前(ラグ)の自分自身」とどれくらい似ているかを測るものです。第1回では日次平均に対して計算しましたが、今回は多くの方が予測したいと思っているであろう生の30分系列に対して計算してみます。すると、その姿はずっと劇的になります。

ラグ350までのACF。ラグ48・96・144…で山を作るきれいな波が見え、ラグ336付近に週次のエコーがある。PACFはラグ1に大きなスパイク。
結果は、48ラグ(=24時間)ごと、さらにラグ336(=7日)付近でスパイクする、ゆっくり減衰する美しい波です。平たく言えば、今の価格は24時間前の価格によく似ていて、さらに1週間前の価格にも似ているということ。この強く繰り返す日次のリズムこそ、モデルが捉えるべき主役であり、周期s = 48(1日48コマ)の**季節(seasonal)**モデルが必要だと教えてくれます。でもその前に、まずはARIMAと出会いましょう。
おさらい——ARIMAとは? 名前は3つのアイデアをくっつけただけです。
- AR(自己回帰):直近の過去の値の重み付き和から今日を予測する。
- I(和分/差分):系列がドリフトし続けるなら、生の値ではなくステップ間の変化量を扱う。そうすると系列が落ち着く(定常になる)。
- MA(移動平均):モデル自身の直近の誤差を使って予測を微調整する。
SARIMAは、ちょうど1季節前(ここでは1日前)を見る、これら3つのコピーをもう1組追加したものです。SARIMAXはXを追加します——天候のような**外生(eXogenous)**変数です。
この後のセクションでは、これらのアイデアを一つずつ見ていき、それらがどう組み合わさって良い時系列予測モデルになっていくのかを追っていきます!
予測の枠組み
タスクと、各モデルをどう採点するかをはっきりさせておきましょう。すべてのモデルに同じルールを適用することで、フェアな勝負にします。
私たちは市場が実際に動く形、すなわち**翌日予測(day-ahead)**で予測します。各日の終わりに立って、それまでに分かっている情報をすべて使い、次の24時間(48コマ)を予測します。これを直近14日間について繰り返します——ローリング・バックテスト、つまり履歴を1日ずつ進みながら予測し、実際に起きたことと突き合わせる方法です。学習はそのつど直前の8週間で行います。
予測の採点にはMAEとRMSE(JPY/kWh単位の平均的な外し幅。RMSEは大外しをより強く罰します)、さらにsMAPE(価格がゼロ近くに下がっても暴れにくいパーセント誤差。JEPX価格は実際にゼロ近くまで下がります)を使います。
S, TEST_DAYS, TRAIN_WEEKS = 48, 14, 8
test_n, train_n = TEST_DAYS * S, TRAIN_WEEKS * 7 * S
y_train = y.iloc[-(test_n + train_n):-test_n]
y_test = y.iloc[-test_n:]
Train : 2025-01-21 00:00:00 -> 2025-03-17 23:30:00 (2688 slots)
Test : 2025-03-18 00:00:00 -> 2025-03-31 23:30:00 (672 slots, day-ahead)
ステップ0:最も単純な予測——過去を繰り返す
意外なほどよく効く、最も簡単な予測とは? **「明日は今日と同じだろう」と仮定することです。各30分コマについて、ちょうど24時間前の同じコマの値をそのまま使います(またラグ48ですね)。この季節ナイーブ(seasonal-naive)**な予測はコストゼロでモデルも要りません——そして、これこそが「ちゃんとした」モデルが価値を示すために超えるべき基準線になります。
full = pd.concat([y_train, y_test])
naive = [full.iloc[len(y_train) + i - S] for i in range(test_n)] # 48コマ前(=24時間前)の値
Naive (seasonal, lag 48):
Naive (lag 48) MAE= 3.086 RMSE= 4.368 sMAPE= 36.6%
結果:MAE = 3.09、RMSE = 4.37、sMAPE = 36.6 %。 この3.09を覚えておいてください——これから作るモデルが超えるべき数字です。
ステップ1:ARIMA(そしてなぜここでつまずくのか)
ARIMAがまず問うのはIのこと:系列は定常か?(だいたい一定の水準に留まるのか、それともドリフトするのか) 第1回の日次系列はドリフトしており、1回の差分(d = 1)が必要でした。では、半時間系列をADF検定(定常性を調べる標準的な統計検定)でチェックしてみましょう。
def adf(series, name):
r = adfuller(series.dropna(), autolag="AIC")
verdict = "stationary ✓" if r[1] < 0.05 else "NON-stationary ✗"
print(f" {name:22s} stat={r[0]:8.3f} p={r[1]:.4f} -> {verdict}")
print("ADF test (training window):")
adf(y_train, "levels")
adf(y_train.diff(), "1st difference")
adf(y_train.diff(S), "seasonal diff (lag 48)")
ADF test (training window):
levels stat= -7.177 p=0.0000 -> stationary ✓
1st difference stat= -12.426 p=0.0000 -> stationary ✓
seasonal diff (lag 48) stat= -8.734 p=0.0000 -> stationary ✓
意外なことに、半時間系列はそのままで既に定常です(検定のp値は約0で、「定常です」という意味)。8週間の窓の中では緩やかなドリフトはなく、強い日次の上下動が平均を一定に保っています。そこでd = 0とします——必要な差分の回数は経験則ではなくデータ次第だという良い例です。続いてauto_arimaに最適なARとMAの設定を自動探索させると、**ARIMA(2, 0, 2)**が選ばれました。
この3つの数字は何を意味するのでしょう? これらは先ほどのおさらいに出てきた**(p, d, q)の次数です。最初の2(p)はARの部分:モデルは各値を直近2つの過去の値**から予測します。真ん中の0(d)は先ほど決めた差分——ここでは不要です。そして最後の2(q)はMAの部分:直近2つの予測誤差を使って予測を微調整します。つまり「ARIMA(2, 0, 2)」は、直近2つの値を見て、直近2つの誤差で補正し、差分はしないと読めます。
auto = auto_arima(y_train, seasonal=False, d=0, max_p=4, max_q=4, stepwise=True)
# → ARIMA(2, 0, 2)
ARIMA Results
==============================================================================
Dep. Variable: y No. Observations: 2688
Model: SARIMAX(2, 0, 2) Log Likelihood -3883.562
Date: Wed, 10 Jun 2026 AIC 7779.124
Time: 17:57:31 BIC 7814.503
Sample: 01-21-2025 HQIC 7791.921
- 03-17-2025
Covariance Type: opg
==============================================================================
coef std err z P>|z| [0.025 0.975]
------------------------------------------------------------------------------
intercept 0.4637 0.039 11.960 0.000 0.388 0.540
ar.L1 1.7479 0.029 59.667 0.000 1.691 1.805
ar.L2 -0.7820 0.027 -28.687 0.000 -0.835 -0.729
ma.L1 -0.7132 0.031 -22.973 0.000 -0.774 -0.652
ma.L2 0.1105 0.014 8.131 0.000 0.084 0.137
sigma2 1.0520 0.014 77.553 0.000 1.025 1.079
===================================================================================
Ljung-Box (L1) (Q): 0.01 Jarque-Bera (JB): 7148.51
Prob(Q): 0.93 Prob(JB): 0.00
Heteroskedasticity (H): 1.87 Skew: 0.18
Prob(H) (two-sided): 0.00 Kurtosis: 10.98
===================================================================================
Warnings:
[1] Covariance matrix calculated using the outer product of gradients (complex-step).
Selected non-seasonal order: (2, 0, 2)
次に、これを翌日予測のバックテストにかけます。下のヘルパーはモデルを一度だけ学習し、その後テスト期間を1日ずつ歩いていきます:次の48コマ(翌日の全30分)を予測し、その日の実際の値をモデルに渡してから次へ進む——実務の予測者が持っているのとまったく同じ情報の使い方です。
def rolling_forecast(order, seasonal_order=(0,0,0,0), exog=None, label=""):
res = SARIMAX(y_train, exog=ex_tr, order=order, seasonal_order=seasonal_order,
enforce_stationarity=False, enforce_invertibility=False).fit(disp=False)
out = []
for d in range(TEST_DAYS):
out.append(res.get_forecast(S, exog=ex_day).predicted_mean)
res = res.append(y_test.iloc[d*S:(d+1)*S], exog=ex_day, refit=False) # 再推定しない
return np.concatenate(out)
ARIMA(2, 0, 2) — day-ahead rolling backtest:
ARIMA(2, 0, 2) MAE= 4.150 RMSE= 5.156 sMAPE= 46.3%
結果:MAE = 4.15——単に昨日を繰り返すより悪い(3.09)! なぜこんなに悪いのか? 素のARIMAは、1日に24時間のリズムがあることを知りません。48ステップ先を予測しろと言われると、すぐに諦めて全体の平均へとドリフトし、横ばいになって朝と夕方のピークを完全に無視してしまいます。後ろの予測プロットでも見えます:ARIMAは約8円/kWhへとだらりと下がる滑らかな線で、一方の実際の価格は12〜21円の間を行き来しています。この失敗こそ、次の材料——季節性——が必要な理由そのものです。
ステップ2:SARIMA——日次サイクルを教え込む
SARIMAは、ちょうど1季節前——ここでは1日(s = 48)——を見る2組目の項を加えたARIMAです。季節差分D = 1は24時間前の値を引き算し(日次サイクルを取り除いて、モデルが残りに集中できるようにする)、季節AR/MA項は1日のパターンが翌日へどう受け継がれるかを学習します。非季節の部分は軽く保ちます(d = 0)。
fc, sarima_res = rolling_forecast((2,0,2), (1,1,1,48))
SARIMA(2, 0, 2)(1, 1, 1, 48) — day-ahead rolling backtest (this takes ~1-2 min):
SARIMA MAE= 2.734 RMSE= 3.774 sMAPE= 30.7%
結果:MAE = 2.73、RMSE = 3.77、sMAPE = 30.7 %。 大きな飛躍です——SARIMAはナイーブ基準(3.09)も素のARIMA(4.15)もはっきり上回りました。横ばいになる代わりに、予測がちゃんと日次の形をなぞっています。半時間の電力価格では、24時間サイクルを正しく捉えることが何よりも効くのです。
これで完成でしょうか? 良い習慣は、残差——残った誤差——を点検することです。モデルが構造をすべて捉えていれば、残差は純粋なランダムノイズのように見えるはずです。Ljung-Box検定と残差のACFで確認します。

SARIMA残差のACF。ほぼ平坦で、すべてのバーが信頼区間の内側に収まっている。
Ljung-Box: ラグ48 → p = 0.28 ラグ336 → p = 0.20 (どちらも > 0.05)
残差は本当にランダムノイズです——AR/MA項をこれ以上足してつかみ取れるパターンは残っていません。それでも誤差はまだそれなりに大きい(MAE 2.73):モデルは昼間の深い谷と最も鋭いピークを取りこぼし続けています。この残りの誤差は隠れたサイクルではなく、価格自身の履歴では決して見えない外部の力の影響です。それこそが、SARIMAXのXの出番です。
ステップ3:SARIMAX——外部情報を取り込む
SARIMAXは、価格自身の過去に加えて追加の変数(「外生(exogenous)」入力と呼ばれます)をモデルに与えられるようにします。2種類を試してみましょう。
3a. カレンダー特徴量(小さな上積み)
まずは簡単なものから:非稼働日フラグ(週末と日本の祝日。これらは安くなりがち)と、いくつかの週次フーリエ項——日次(s = 48)の季節項だけでは捉えられない7日周期の形をなぞる、滑らかなsin/cosの波です。
def calendar_exog(index, K=2):
nonworking = ((index.dayofweek >= 5) | index.normalize().astype(str).isin(JP_HOLIDAYS)).astype(float)
df = pd.DataFrame({"nonworking": nonworking}, index=index)
slot = ((index - index[0]) / pd.Timedelta("30min")).to_numpy()
for k in range(1, K + 1):
df[f"wk_sin{k}"] = np.sin(2*np.pi*k*slot/(7*S))
df[f"wk_cos{k}"] = np.cos(2*np.pi*k*slot/(7*S))
return df
SARIMAX(2, 0, 2)(1, 1, 1, 48) + calendar exog — rolling backtest (~2 min):
SARIMAX (calendar) MAE= 2.581 RMSE= 3.683 sMAPE= 29.6%
Exogenous coefficients:
==============================================================================
coef std err z P>|z| [0.025 0.975]
------------------------------------------------------------------------------
nonworking -0.2332 0.171 -1.362 0.173 -0.569 0.102
wk_sin1 0.7740 0.452 1.711 0.087 -0.113 1.661
wk_cos1 -0.2528 0.340 -0.743 0.457 -0.919 0.414
wk_sin2 0.2721 0.377 0.722 0.470 -0.466 1.010
wk_cos2 -0.1930 0.352 -0.548 0.583 -0.883 0.497
ar.L1 1.7113 0.108 15.831 0.000 1.499 1.923
ar.L2 -0.7282 0.102 -7.112 0.000 -0.929 -0.528
ma.L1 -0.8241 0.108 -7.613 0.000 -1.036 -0.612
ma.L2 0.0881 0.013 6.711 0.000 0.062 0.114
ar.S.L48 2.416e-05 0.013 0.002 0.999 -0.026 0.026
ma.S.L48 -1.1010 0.011 -102.815 0.000 -1.122 -1.080
sigma2 0.6803 0.015 44.360 0.000 0.650 0.710
==============================================================================
結果:MAE = 2.58——SARIMA(2.73)からわずかに前進しました。正直なところ上積みは小さく、統計的にも新しい変数は弱いものでした(非稼働日フラグは有意ではありませんでした)。季節項が既にカレンダーの信号の大半を吸収していたうえ、今回の静かな3月下旬のテスト期間には平日・週末のドラマがあまりないのです。これ自体が一つの教訓です:特徴量を盛れば自動的に良くなる、わけではない。
3b. 天候(決定的な一手)
いよいよ、ドメイン知識が「効くはずだ」と告げる変数です。半時間ごとの気温と日射量(solarGHI)を加えます。
exog_w = pd.concat([calendar_exog(y.index), weather.reindex(y.index).ffill()], axis=1)
fc, smxw_res = rolling_forecast((2,0,2), (1,1,1,48), exog=exog_w)
SARIMAX(2, 0, 2)(1, 1, 1, 48) + calendar + weather — rolling backtest:
SARIMAX (cal+weather) MAE= 1.864 RMSE= 2.526 sMAPE= 24.9%
Exogenous coefficients:
===============================================================================
coef std err z P>|z| [0.025 0.975]
-------------------------------------------------------------------------------
nonworking -0.3656 0.164 -2.225 0.026 -0.688 -0.044
wk_sin1 0.2659 0.346 0.768 0.442 -0.413 0.944
wk_cos1 -0.1447 0.268 -0.540 0.589 -0.670 0.380
wk_sin2 0.1084 0.287 0.378 0.706 -0.454 0.670
wk_cos2 -0.1227 0.269 -0.456 0.649 -0.651 0.405
temperature -0.3045 0.045 -6.835 0.000 -0.392 -0.217
solarGHI -0.6159 0.157 -3.917 0.000 -0.924 -0.308
ar.L1 1.3767 0.290 4.740 0.000 0.807 1.946
ar.L2 -0.4230 0.269 -1.574 0.115 -0.950 0.104
ma.L1 -0.5186 0.291 -1.781 0.075 -1.089 0.052
ma.L2 0.0630 0.021 3.051 0.002 0.023 0.103
ar.S.L48 1.958e-05 0.013 0.001 0.999 -0.026 0.026
ma.S.L48 -0.9175 0.009 -104.431 0.000 -0.935 -0.900
sigma2 0.8047 0.010 77.144 0.000 0.784 0.825
===============================================================================
結果:MAE = 1.86、RMSE = 2.53、sMAPE = 24.9 %。 これが目玉です。天候を加えると誤差は2.58から1.86へ低下——ナイーブ基準の3.09と比べると、およそ40 %の削減です。しかもモデルの係数は現実に即した意味を持ち、どちらも強く有意です:
temperature coef = -0.30 p < 0.001
solarGHI coef = -0.62 p < 0.001
nonworking coef = -0.37 p = 0.026
天候の係数はどちらも負で、これはメリットオーダー効果の現れです:日差しが強いと、限界費用ほぼゼロの太陽光発電がどっと流れ込み、高コストの火力発電を電源構成の外へ押し出して、特に昼間のスポット価格を押し下げます。(気温は、この春の期間で需要が穏やかになる側面を捉えています。)これは価格自身の過去には決して含まれない情報であり、適切な入力を与えられたSARIMAXがこれほど明確に勝つ理由です。
比較とまとめ

モデル別のMAE棒グラフ。ナイーブ3.09(破線の基準)、ARIMA 4.15(基準を上回る=悪い!)、SARIMA 2.73、SARIMAX+カレンダー 2.58、SARIMAX+天候 1.86。
| モデル | MAE | RMSE | sMAPE |
|---|---|---|---|
| ナイーブ(昨日を繰り返す) | 3.09 | 4.37 | 36.6 % |
| ARIMA(2,0,2) | 4.15 | 5.16 | 46.3 % |
| SARIMA(2,0,2)(1,1,1)₄₈ | 2.73 | 3.77 | 30.7 % |
| SARIMAX + カレンダー | 2.58 | 3.68 | 29.6 % |
| SARIMAX + 天候 | 1.86 | 2.53 | 24.9 % |
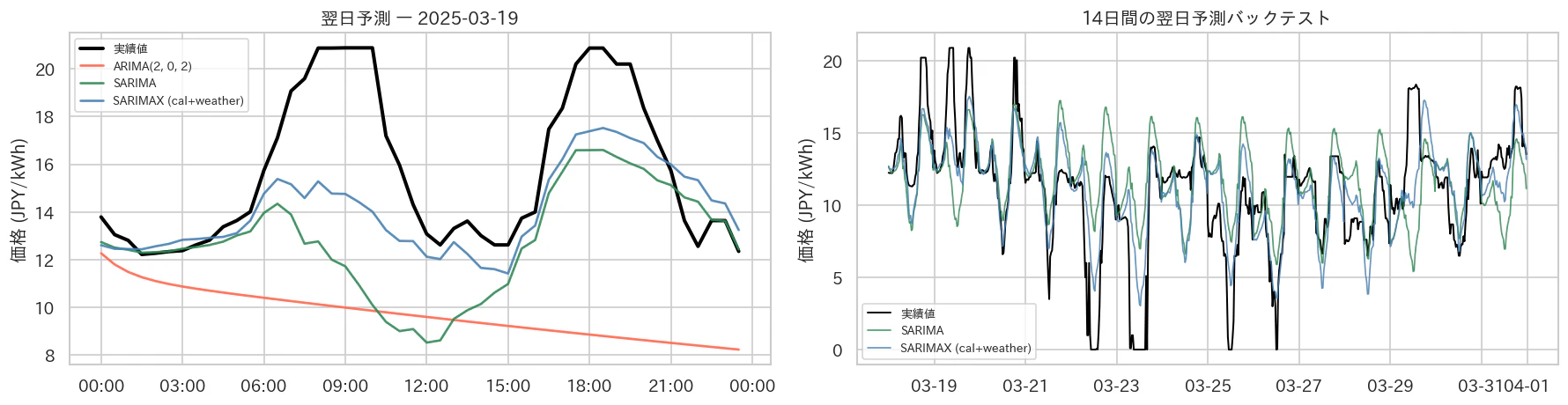
左:代表的な1日。ARIMAが横ばいになる一方、SARIMAとSARIMAX+天候は実際の二峰型に寄り添う。右:14日間のバックテスト。SARIMAX+天候がSARIMAの取りこぼす深い谷を捉えている。
一言でまとめると:単純から複雑へ進むことには価値がある——ただし、各ステップが前のステップの弱点を埋めるときに限る。
- 日次の季節性を加えたのは、素のARIMAが「昨日を繰り返す」にすら勝てなかったから。これが予測を使えるものにしたステップです。
- 天候を加えたのは、SARIMAの残差が——既にランダムノイズだったとはいえ——まだ多くの説明されない振れを隠していたから。これが予測を良いものにしたステップです。
- 間にあったカレンダー特徴量はほとんど効きませんでした——問題を理解することは、闇雲に列を足すことに勝るというリマインダーです。
この**「特定 → 推定 → 診断」を繰り返すループは、古典的なBox-Jenkins法**そのもので、その考え方はこれから作るあらゆる予測モデルに通じます。
限界
- これらは線形モデルなので、U字型の気温効果や、複数の変数の相互作用によって価格に生じる複雑な交互作用は、部分的にしか捉えられません。
- s = 48でのSARIMAは遅い(1回の学習に1〜2分)ので、自由にグリッドサーチはできませんし、より細かい解像度や多数の系列へのスケールも効きません。今回も週次サイクル(s = 336)を、2つ目の季節層を足す代わりに外生特徴量に任せざるを得ませんでした。季節性をもっと効率的に学習できるモデルは、確かに存在します。
次回(第3回)予告
次は機械学習の回帰モデル——線形回帰や木ベースのモデル——に切り替えます。これらは多数の外生特徴量や複数の季節サイクルを、SARIMAのような計算上の天井なしに、安く柔軟に飲み込んでくれます。それでは、次回の記事でお会いしましょう!