私がまだ大学でエネルギー工学を学んでいた少し前のこと、最も感銘を受けた科目の1つが「時系列予測(Time Series Forecasting)」でした。エネルギー市場価格や電力需要、太陽光や風力発電量といった未来の情報を、統計ツールを使ってこれほど高い精度で予測できるとは、それまで思いもしませんでした。
その時の感動が忘れられず、私は最近キャリアの焦点をAIに移し、喜ばしいことにShizen Connectに参画してAI予測モデルの開発に取り組んでいます。
改めて、初めまして!ケンジです。
この記事から始まる連載では、時系列予測の問題に取り組む際のプロセスをご紹介したいと思います。
この記事の読者の多くは定額制や時間帯別の電力プランをご利用かもしれませんが、最終的に私たちは皆、日々のJEPX(日本卸電力取引所)スポット市場で決まる価格の影響を受けています。そのため、本連載ではさまざまな予測ツールを使用し、その仕組みを学び、Pythonでの実装方法を確認して、その結果を検証していきます。
今回は、東京エリアの 2022年度(2022年4月〜2023年3月)のJEPXスポット市場価格データ を使用し、さらに気温や日射量が予測の精度向上にどのように役立つかを見ていきます。
第1回となる本記事では、探索的データ分析(EDA: Exploratory Data Analysis) から始め、データのトレンドや相関関係など、データからどのような興味深い事実が読み取れるかを確認します。そして第2回以降では、エネルギー市場価格などの時系列データに利用できる伝統的でよく使われる統計モデルである「ARIMA」と「SARIMAX」を実際に適用していきます。
(※本連載のコードはすべてこちらのGitHubリポジトリで公開しています)。
1. JEPXとは? データセットの概要
JEPX(Japan Electric Power eXchange:日本卸電力取引所)は、日本国内で電力の売買が行われる唯一の卸電力市場です。日々の電力需要と供給のバランスによって、30分コマごとに「スポット価格」が決定されます。
本記事で使用するデータセットは以下の通りです。
- JEPX価格データ:30分ごとのJEPXスポット価格(JPY/kWh)— 2022年4月1日〜2023年3月31日
- 気象データ:東京エリアの30分ごとの気温(℃)および全天日射量・GHI(W/m²)
これらのデータはJEPXおよび気象庁のウェブサイトから取得し、事前に結合しやすいように前処理されたCSVファイルを使用します。
まずはデータをロードし、結合するコードを見てみましょう。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib.dates as mdates
import seaborn as sns
# ── Plot defaults ──────────────────────────────────────────
plt.rcParams.update({
"figure.dpi": 120,
"font.size": 11,
"axes.titlesize": 12,
"axes.labelsize": 11,
"legend.fontsize": 10,
})
sns.set_theme(style="whitegrid", palette="muted")
# ── データの読み込み ─────────────────────────────────────────
jepx = pd.read_csv("data/jepx_tokyo.csv", index_col=0, parse_dates=True)
jepx.index = jepx.index.tz_localize(None)
jepx.index.name = "datetime"
weather = pd.read_csv("data/weather_tokyo.csv", index_col=0, parse_dates=True)
weather.index = weather.index.tz_localize(None)
weather.index.name = "datetime"
# ── JEPXデータの期間に合わせてフィルタリング・結合 ────────────
weather = weather.loc[jepx.index[0] : jepx.index[-1]]
df_30min = jepx.join(weather, how="inner")
df_30min = df_30min.asfreq("30min")
第2回でのARIMA/SARIMAXモデリングの計算を扱いやすくしつつ、週次サイクルや年次トレンドといった予測に重要な季節構造を維持するため、30分ごとのデータを 日次(Daily)解像度 に集約します。
(※EDAの可視化において日中の解像度が重要な場面では、30分データも併用します)
# ── 日次データへの集約 ──────────────────────────────────────
# price -> 1日の平均価格 (JPY/kWh)
# temperature -> 1日の平均気温 (℃)
# solarGHI -> 1日の合計日射量 (W/m²)
df_daily = df_30min.resample("D").agg(
price=("price", "mean"),
temperature=("temperature", "mean"),
solarGHI=("solarGHI", "sum"),
)
df_daily = df_daily.asfreq("D")
2. 探索的データ分析 (EDA) ウォークスルー
2.1 時系列の概要 (Time-Series Overview)
まずは、1年間のデータの全体像を30分単位で眺めてみましょう。
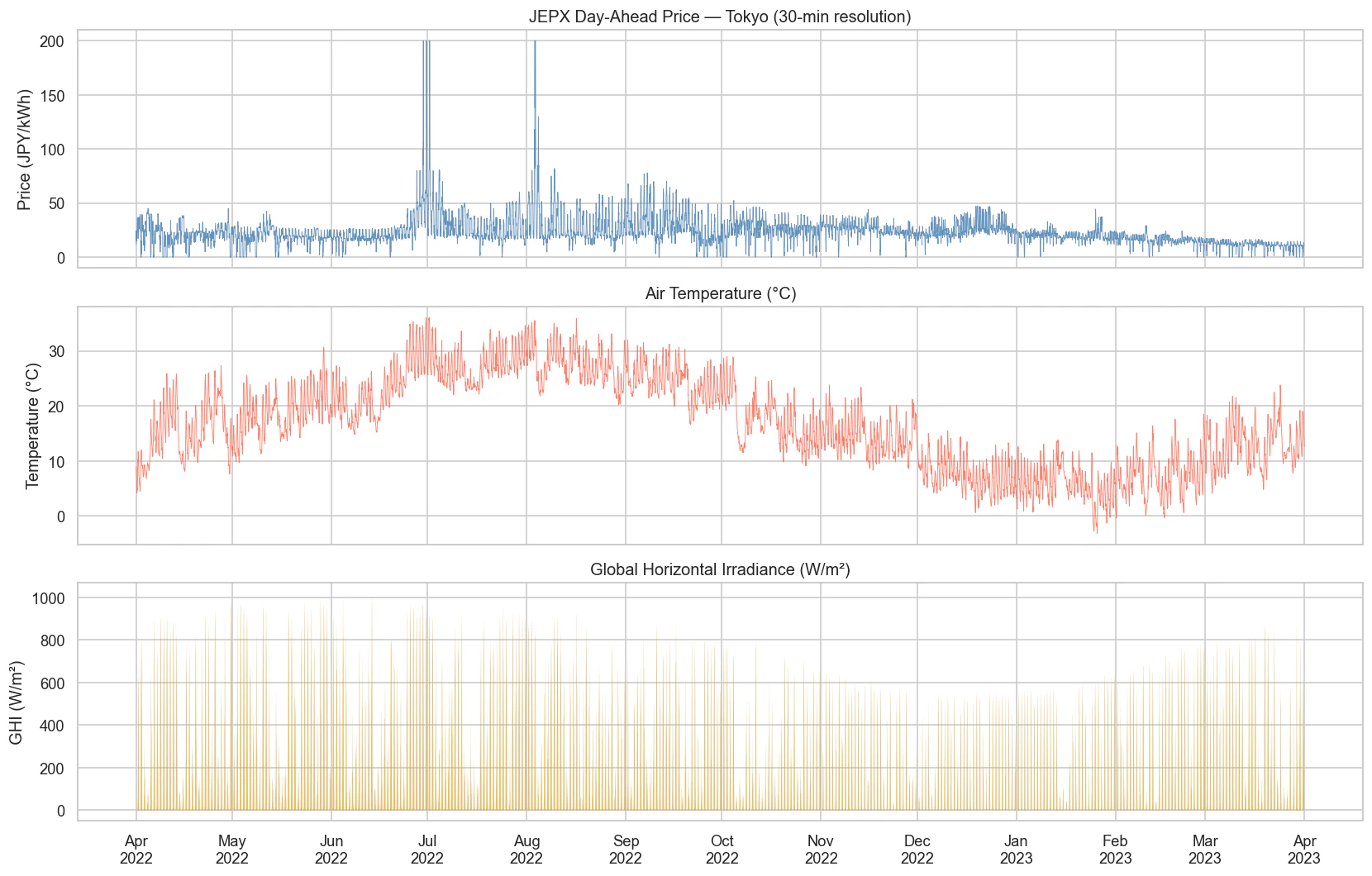
- JEPX価格のパネル を見ると、日本の高温多湿な夏における冷房需要の急増を反映した 夏のピーク(7〜8月) と、暖房需要や日照時間の短さに起因する 冬の上昇(12〜1月) が確認できます。
- 短期的なボラティリティも非常に高く、1日の中で価格が急激に変動します。全く同じ波形を描く日は2日とありません。
- 個人的な特記事項:2022年度はエネルギー価格にとって特に厳しい年でした。猛暑による冷房需要の高まりと、LNG(液化天然ガス)輸入価格の高騰が重なり、プロットでも200 円/kWhという異常なピークが確認できます。
-
気温のパネル は価格の変動と密接に連動しており、次回のSARIMAXモデルにおいて「気温」が有用な外生変数になることを強く示唆しています。
また、太陽光GHIのパネル と見比べると、悪天候などで日射量が低い日が続いた場合、限界費用ゼロの太陽光発電が減ることで日中のボラティリティが低下し、価格が高止まりする「メリットオーダー効果」の影響が確認できます。
fig, axes = plt.subplots(3, 1, figsize=(14, 9), sharex=True)
# ── Price (30-min) ────────────────────────────────────────────────────────────
axes[0].plot(df_30min.index, df_30min["price"],
color="steelblue", lw=0.5, alpha=0.85)
axes[0].set_ylabel("Price (JPY/kWh)")
axes[0].set_title("JEPX Day-Ahead Price — Tokyo (30-min resolution)")
# ── Temperature ───────────────────────────────────────────────────────────────
axes[1].plot(df_30min.index, df_30min["temperature"],
color="tomato", lw=0.5, alpha=0.85)
axes[1].set_ylabel("Temperature (°C)")
axes[1].set_title("Air Temperature (°C)")
# ── Solar GHI ─────────────────────────────────────────────────────────────────
axes[2].fill_between(df_30min.index, df_30min["solarGHI"],
color="goldenrod", alpha=0.7, lw=0)
axes[2].set_ylabel("GHI (W/m²)")
axes[2].set_title("Global Horizontal Irradiance (W/m²)")
for ax in axes:
ax.xaxis.set_major_locator(mdates.MonthLocator())
ax.xaxis.set_major_formatter(mdates.DateFormatter("%b\n%Y"))
plt.tight_layout()
plt.show()
2.2 価格の分布 (Price Distribution)
日次平均価格がどのように分布しているかをヒストグラムと箱ひげ図で確認します。
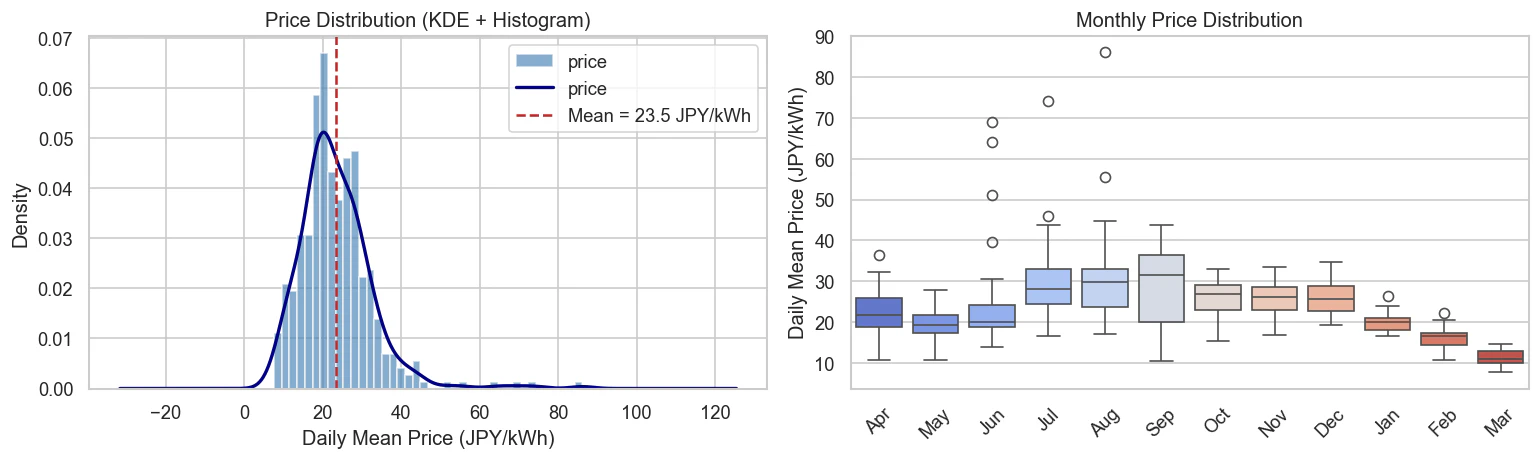
左の分布図を見ると、日次平均価格の分布は 右に裾が長い(right-skewed) 形状をしています。大部分の日は中程度の価格帯に集中していますが、供給ショックや極端な需要によって価格が通常の何倍にも跳ね上がるエネルギー市場特有の非対称性が表れています。
右の月別の箱ひげ図からは、冷暖房需要が減る春と秋に価格が下がる傾向が見られます。ただし、夏の高騰が極端に突出しており、冬は予想以上に温暖でピークが低かったため、綺麗なU字型にはなっていません。一方、夏の箱の高さ(四分位範囲)が広がっていることから、市場が逼迫するほど価格の変動性(ボラティリティ)が高まることは明確に読み取れます。
fig, axes = plt.subplots(1, 2, figsize=(13, 4))
# ── Histogram + KDE ───────────────────────────────────────────────────────────
df_daily["price"].plot.hist(bins=40, density=True, ax=axes[0],
color="steelblue", alpha=0.65, edgecolor="white")
df_daily["price"].plot.kde(ax=axes[0], color="navy", lw=2)
mean_price = df_daily["price"].mean()
axes[0].axvline(mean_price, color="firebrick", ls="--", lw=1.5,
label=f"Mean = {mean_price:.1f} JPY/kWh")
axes[0].set_xlabel("Daily Mean Price (JPY/kWh)")
axes[0].set_title("Price Distribution (KDE + Histogram)")
axes[0].legend()
# ── Monthly boxplot ───────────────────────────────────────────────────────────
month_label = [
pd.Timestamp(2022 if m >= 4 else 2023, m, 1).strftime("%b")
for m in df_daily.index.month
]
df_plot = df_daily.copy()
df_plot["month"] = month_label
month_order = ["Apr", "May", "Jun", "Jul", "Aug", "Sep",
"Oct", "Nov", "Dec", "Jan", "Feb", "Mar"]
sns.boxplot(data=df_plot, x="month", y="price",
order=month_order, ax=axes[1], palette="coolwarm")
axes[1].set_xlabel("")
axes[1].set_ylabel("Daily Mean Price (JPY/kWh)")
axes[1].set_title("Monthly Price Distribution")
axes[1].tick_params(axis="x", rotation=45)
plt.tight_layout()
plt.show()
print(f"Skewness : {df_daily['price'].skew():.3f}")
print(f"Kurtosis : {df_daily['price'].kurt():.3f}")
2.3 日中の価格プロファイル (Intraday Price Profile)
次に、1日の中での価格変動(48個の30分スロット)を見てみます。
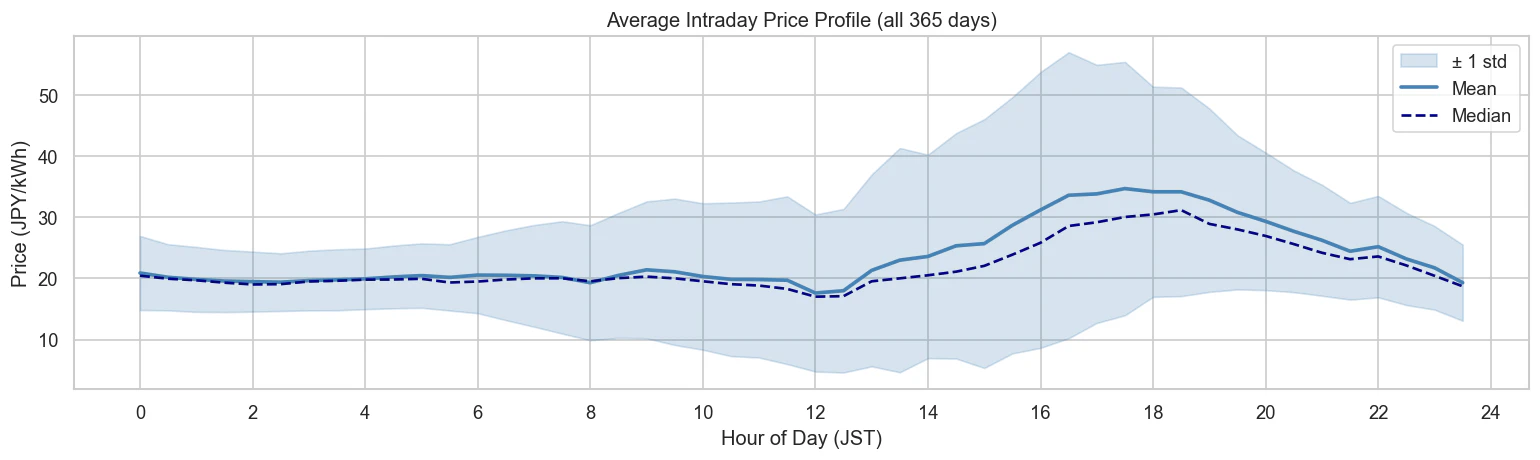
平均プロファイルを見ると、他の電力市場でよく見られる「双峰型」とは異なり、2022年度の本データにおいては明確な 「夕方の単一ピーク」 と昼間の価格低下が特徴的な形状を示しています。
- 深夜の安定期(0〜5時):ボラティリティ(変動性)が最も小さく、価格も低い水準で安定しています。
- 朝の立ち上がり(6〜9時):価格のボラティリティは拡大し始めますが、平均価格自体は深夜帯とほぼ同じ水準に留まっています。
- 昼間の最安値(12時前後):太陽光発電の出力がピークを迎える影響で、平均価格がわずかに下がり、1日の中で最も安価なポイントになります。
- 夕方の高騰ピーク(16〜19時):価格が大きく上昇して1日の最高値を記録し、同時にボラティリティも最大になります。
- 夜間の落ち着き(20時以降):ピークを過ぎると、価格は再び深夜の平均的な水準に向けて低下していきます。
夕方のピーク時間の周囲にある広い標準偏差の帯は、他の時間帯に比べて「日ごとの価格水準の違い」が極めて大きい(日によって著しく高騰する)ことを示しています。
# Average price profile over the 48 half-hour slots of the day
hour_float = df_30min.index.hour + df_30min.index.minute / 60
hourly_profile = df_30min["price"].groupby(hour_float).agg(["mean", "std", "median"])
fig, ax = plt.subplots(figsize=(13, 4))
ax.fill_between(
hourly_profile.index,
hourly_profile["mean"] - hourly_profile["std"],
hourly_profile["mean"] + hourly_profile["std"],
alpha=0.22, color="steelblue", label="± 1 std"
)
ax.plot(hourly_profile.index, hourly_profile["mean"],
color="steelblue", lw=2.2, label="Mean")
ax.plot(hourly_profile.index, hourly_profile["median"],
color="navy", lw=1.6, ls="--", label="Median")
ax.set_xlabel("Hour of Day (JST)")
ax.set_ylabel("Price (JPY/kWh)")
ax.set_title("Average Intraday Price Profile (all 365 days)")
ax.set_xticks(range(0, 25, 2))
ax.legend()
plt.tight_layout()
plt.show()
2.4 曜日パターンと時間×月のヒートマップ
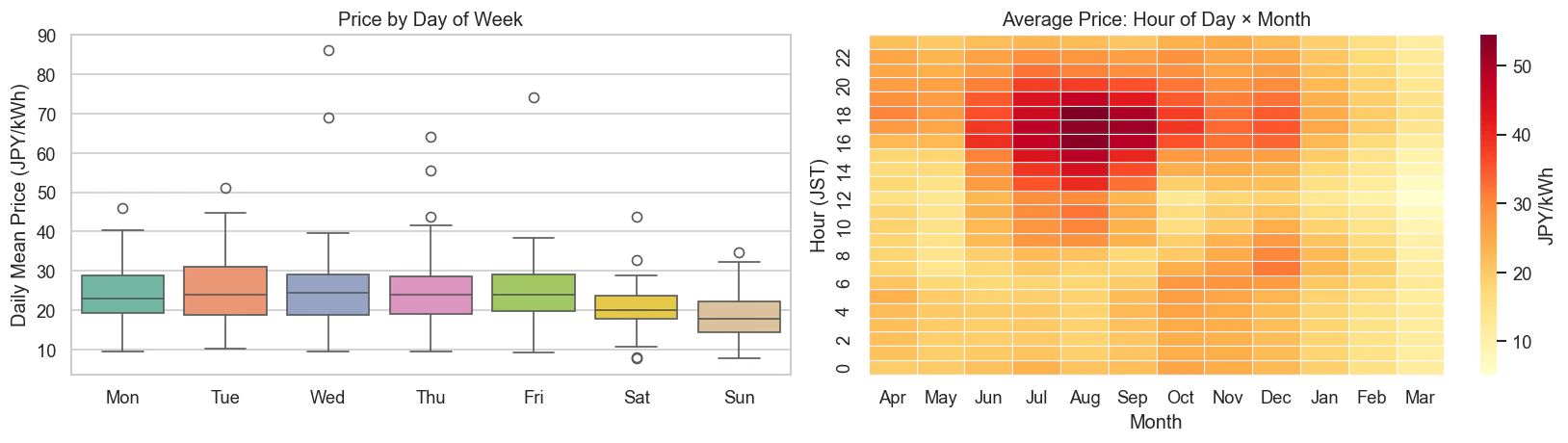
曜日の箱ひげ図(左)からは、明確な 平日・休日の違い が見て取れます。土日の価格は平日よりも一貫して低くなっています。この週次リズムこそが、次回構築するSARIMAモデルの季節変動成分(s=7)として捉えられるものです。
ヒートマップ(右)では、月と時間の2次元の相互作用が非自明であることがわかります。
-
特記事項: 通常、冬の朝(6〜9時)は暖房需要でかなり高価になりますが、このデータにおける2023年の晩冬は、予想以上に気温が高かったこととLNGの価格が大幅に低くなったことにより、シリーズ中で最も安い価格帯になっています。
単に「月」や「時間」単体で価格を予測することはできず、両方の組み合わせが必要になることが視覚的にわかります。
fig, axes = plt.subplots(1, 2, figsize=(14, 4))
# ── Day-of-week boxplot ───────────────────────────────────────────────────────
df_plot2 = df_daily.copy()
df_plot2["dow"] = df_plot2.index.day_name().str[:3]
dow_order = ["Mon", "Tue", "Wed", "Thu", "Fri", "Sat", "Sun"]
sns.boxplot(data=df_plot2, x="dow", y="price",
order=dow_order, ax=axes[0], palette="Set2")
axes[0].set_title("Price by Day of Week")
axes[0].set_xlabel("")
axes[0].set_ylabel("Daily Mean Price (JPY/kWh)")
# ── Hour × Month heatmap (mean price) ────────────────────────────────────────
df_30min_plot = df_30min.copy()
df_30min_plot["hour"] = df_30min_plot.index.hour
df_30min_plot["month_label"] = [
pd.Timestamp(2022 if m >= 4 else 2023, m, 1).strftime("%b")
for m in df_30min_plot.index.month
]
pivot = df_30min_plot.pivot_table(
values="price", index="hour", columns="month_label", aggfunc="mean"
)
pivot = pivot[["Apr", "May", "Jun", "Jul", "Aug", "Sep",
"Oct", "Nov", "Dec", "Jan", "Feb", "Mar"]]
sns.heatmap(pivot, ax=axes[1], cmap="YlOrRd",
cbar_kws={"label": "JPY/kWh"}, linewidths=0.3)
axes[1].set_title("Average Price: Hour of Day × Month")
axes[1].set_xlabel("Month")
axes[1].set_ylabel("Hour (JST)")
axes[1].invert_yaxis()
plt.tight_layout()
plt.show()
2.5 季節変動の分解 (Seasonal Decomposition)
時系列データを「トレンド」「季節性」「残差」に分解(Additive decomposition)して構造を確認します。
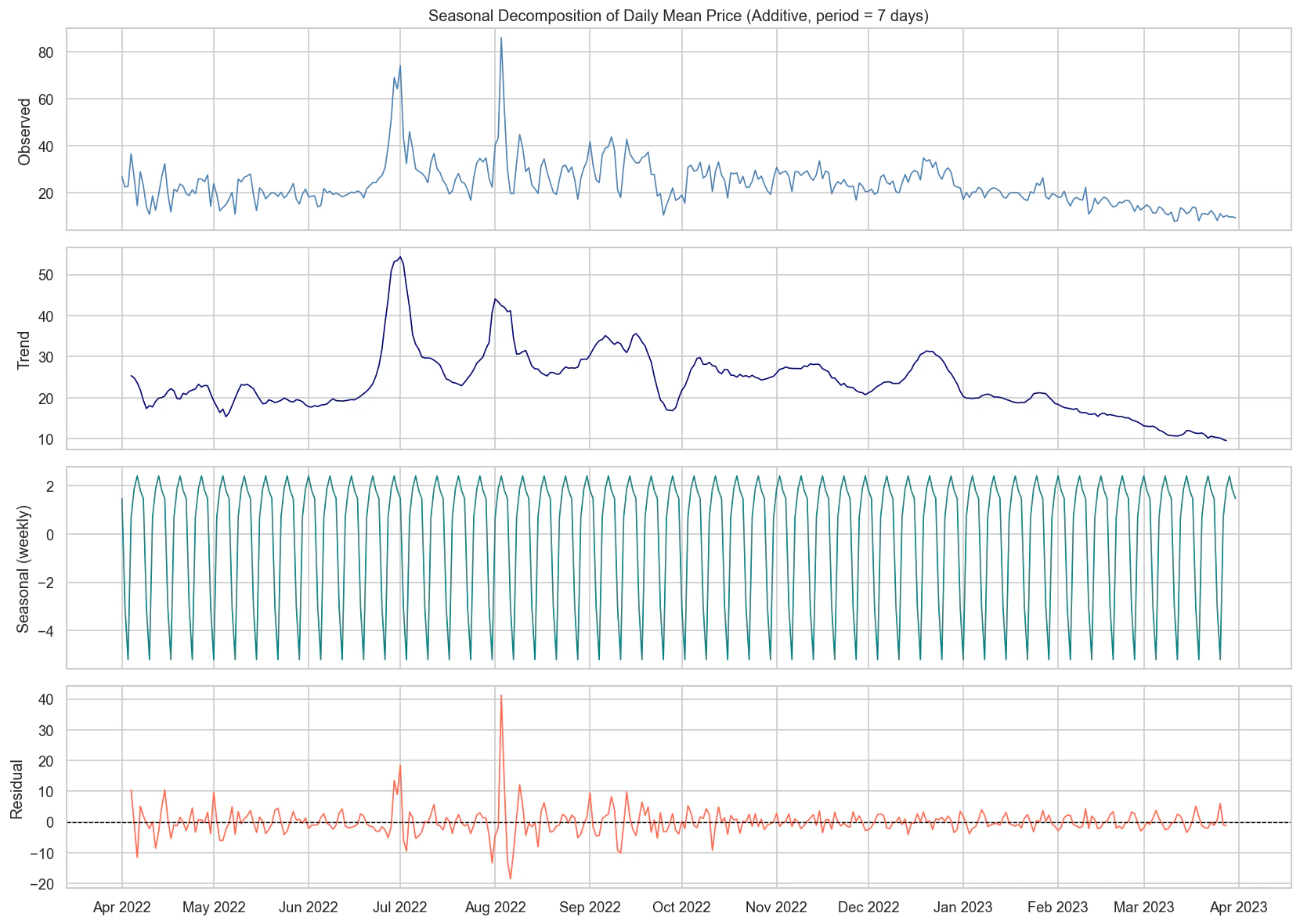
- トレンド成分:マクロな視点での価格の推移を物語っています。6月と8月の高止まり(エネルギー危機)から、穏やかな秋を経て冬に再び上昇し、春に落ち着くという長期的傾向です。
- 季節成分:毎週末に相対的に下落する、一貫した「週次サイクル」が年間を通じて繰り返されていることが確認できます。
- 残差成分:トレンドと週次季節性を除いた後のノイズです。2022年7月と8月に極端なスパイクが見られ、純粋な統計モデルの限界を思い起こさせます。
この分解により、ARIMA/SARIMAXモデルにおいてトレンドを扱うための 差分項(d=1) と、週次サイクルを扱うための 季節成分(s=7) が正当化されます。
decomp = seasonal_decompose(df_daily["price"], model="additive", period=7)
fig, axes = plt.subplots(4, 1, figsize=(14, 10), sharex=True)
components = [
(df_daily["price"], "Observed", "steelblue"),
(decomp.trend, "Trend", "navy"),
(decomp.seasonal, "Seasonal (weekly)", "teal"),
(decomp.resid, "Residual", "tomato"),
]
for ax, (data, label, color) in zip(axes, components):
ax.plot(data, color=color, lw=1.0)
ax.set_ylabel(label)
if label == "Residual":
ax.axhline(0, color="black", ls="--", lw=0.8)
axes[0].set_title("Seasonal Decomposition of Daily Mean Price (Additive, period = 7 days)")
axes[-1].xaxis.set_major_locator(mdates.MonthLocator())
axes[-1].xaxis.set_major_formatter(mdates.DateFormatter("%b %Y"))
plt.tight_layout()
plt.show()
2.6 定常性 — ADF検定 (Stationarity)
ARIMAモデルを構築する上で、時系列が「定常(平均や分散が時間経過で一定)」であることは非常に重要です。拡張ディッキー・フラー検定(ADF検定)を行った結果、以下の結論が得られました。
── ADF Test : Daily price (levels) ──────────────────────────────────
Test statistic : -2.6813
p-value : 0.0773 → Non-stationary ✗
Lags used : 15
Critical 1% : -3.449
Critical 5% : -2.870
Critical 10% : -2.571
── ADF Test : Daily price (1st difference) ──────────────────────────────────
Test statistic : -6.7637
p-value : 0.0000 → Stationary ✓
Lags used : 13
Critical 1% : -3.449
Critical 5% : -2.870
Critical 10% : -2.571
- 生の価格データ(レベル系列):p値が0.05を上回り、非定常であることが判明しました(トレンドやレベルシフトが存在するため)。
- 1階差分をとった系列:p値が0.05を下回り、定常になりました。
これにより、絶対的な価格ではなく、日々の「価格の変化量」を予測するために d = 1 の妥当性が示唆されました。
def adf_test(series: pd.Series, name: str = "") -> None:
r = adfuller(series.dropna(), autolag="AIC")
print(f"── ADF Test : {name} ──────────────────────────────────")
print(f" Test statistic : {r[0]:>10.4f}")
print(f" p-value : {r[1]:>10.4f} → "
f"{'Stationary ✓' if r[1] < 0.05 else 'Non-stationary ✗'}")
print(f" Lags used : {r[2]}")
for k, v in r[4].items():
print(f" Critical {k} : {v:.3f}")
print()
adf_test(df_daily["price"], "Daily price (levels)")
adf_test(df_daily["price"].diff().dropna(), "Daily price (1st difference)")
2.7 自己相関 (ACF) と 偏自己相関 (PACF)
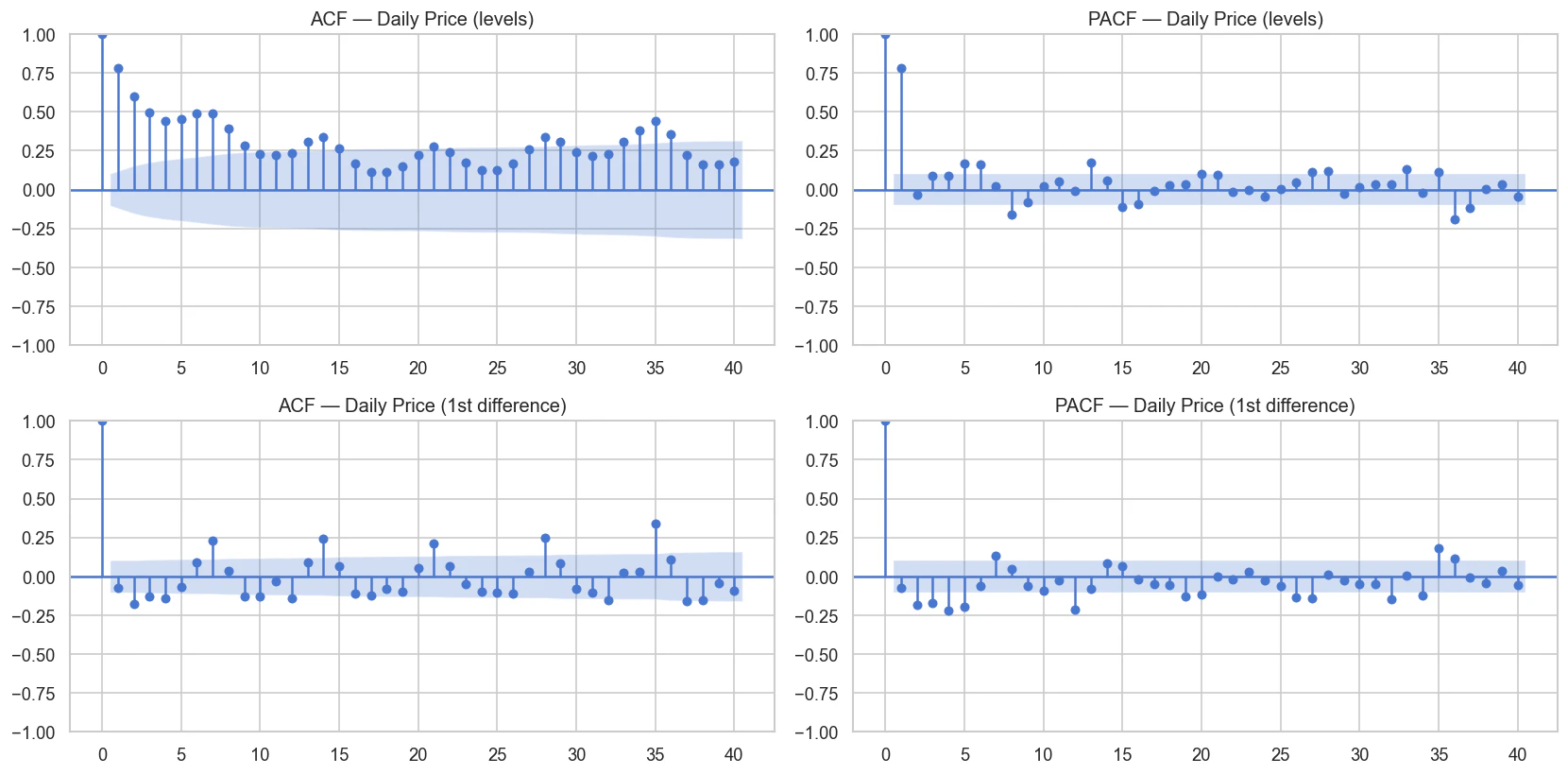
ARIMA/SARIMAXモデルは目的変数自身の過去の値から予測を作成するため、ACFおよびPACF分析が不可欠です。
差分系列のACFプロットを見ると、ラグ7、14、21... に有意なスパイクが見られます。これは、非季節性ARIMAだけでは除去できない「週次の季節的自己相関構造」が存在することを示しており、季節成分(s=7)の必要性を直接的に裏付けています。これらはBox-Jenkins法に基づくモデルの次数(p, q)決定の基礎となります。
price_diff = df_daily["price"].diff().dropna()
fig, axes = plt.subplots(2, 2, figsize=(14, 7))
plot_acf(df_daily["price"].dropna(), lags=40, ax=axes[0, 0],
title="ACF — Daily Price (levels)")
plot_pacf(df_daily["price"].dropna(), lags=40, ax=axes[0, 1],
title="PACF — Daily Price (levels)")
plot_acf(price_diff, lags=40, ax=axes[1, 0],
title="ACF — Daily Price (1st difference)")
plot_pacf(price_diff, lags=40, ax=axes[1, 1],
title="PACF — Daily Price (1st difference)")
plt.tight_layout()
plt.show()
2.8 外生変数との相関 (Weather Correlations)
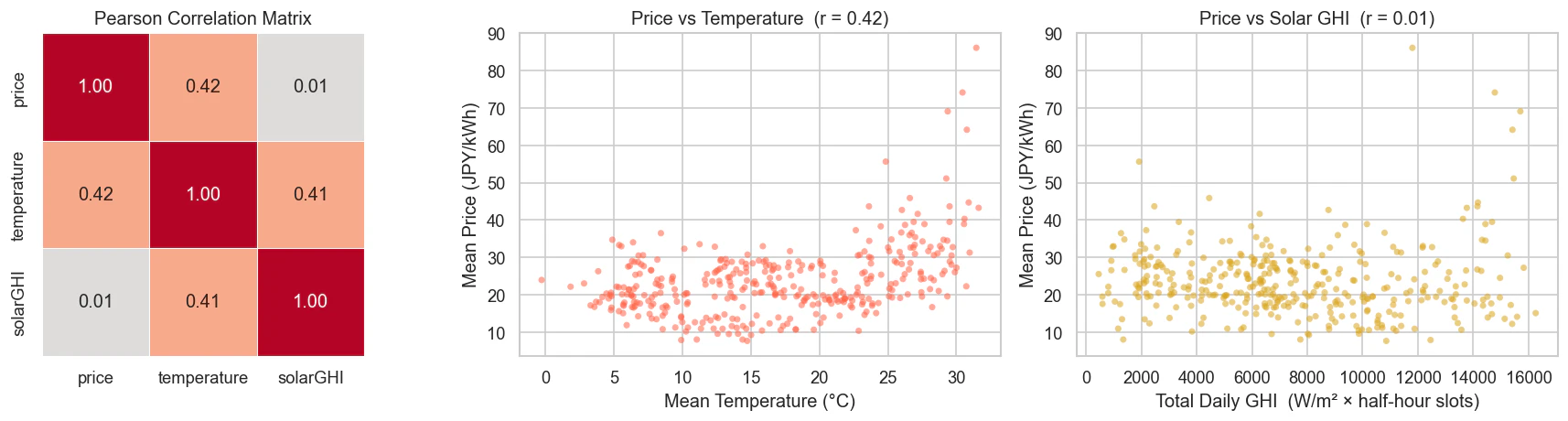
最後に、気象データとの関係です。
-
気温:散布図は狭いU字型を示しています。極端に寒い日も高い価格をもたらしますが、6月・8月の異常なピークにより、高い気温は低い気温に比べてはるかに高い価格を引き起こしていることがわかります。ピアソン相関係数は0.42となっており、電力価格と中程度の相関があることから、良好な予測結果を得るための非常に価値のある変数であることが確認できます。
-
太陽光GHI:日次レベルの散布図は非常にばらつきがあり、ピアソン相関係数は0.01と、直線的な相関がほとんどないことが示されています。しかし、たとえば日射量は夜間の価格変動を説明できないことなどを考慮すると、この結果は理にかなっています。相関を評価するためのより興味深い指標として、特徴量重要度(Feature Importance)やVIF(分散拡大要因)テストなどがあり、これらについては今後の記事で取り上げるかもしれません。
相関があるからといって必ずしも有用な予測入力になるとは限りませんが、気温が予測に役立つ可能性は十分に確認できました。
fig, axes = plt.subplots(1, 3, figsize=(15, 4))
# ── Correlation heatmap ───────────────────────────────────────────────────────
corr = df_daily[["price", "temperature", "solarGHI"]].corr()
sns.heatmap(corr, annot=True, fmt=".2f", cmap="coolwarm", center=0,
ax=axes[0], square=True, cbar=False, linewidths=0.5)
axes[0].set_title("Pearson Correlation Matrix")
# ── Price vs Temperature ──────────────────────────────────────────────────────
axes[1].scatter(df_daily["temperature"], df_daily["price"],
alpha=0.55, color="tomato", s=18, edgecolors="none")
axes[1].set_xlabel("Mean Temperature (°C)")
axes[1].set_ylabel("Mean Price (JPY/kWh)")
axes[1].set_title(f"Price vs Temperature (r = {corr.loc['price','temperature']:.2f})")
# ── Price vs Solar GHI ────────────────────────────────────────────────────────
axes[2].scatter(df_daily["solarGHI"], df_daily["price"],
alpha=0.55, color="goldenrod", s=18, edgecolors="none")
axes[2].set_xlabel("Total Daily GHI (W/m² × half-hour slots)")
axes[2].set_ylabel("Mean Price (JPY/kWh)")
axes[2].set_title(f"Price vs Solar GHI (r = {corr.loc['price','solarGHI']:.2f})")
plt.tight_layout()
plt.show()
Part 1 のまとめ & 次回予告
今回の探索的データ分析により、JEPX東京エリアの価格について以下の5つの事実が明確になりました。
- 年次季節性: 春と秋に価格が落ち着く一方、夏には極端な高騰(ピーク)を迎え、冬のピークは気温の影響で変動する(2022年度は比較的穏やかだった)という特徴がある。
- 週次季節性: 平日の価格は休日よりも一貫して高い。
- 強い日中構造: 一般的な「双峰型」ではなく、深夜に安定し、昼間に最安値をつけ、夕方に単一の巨大なピークと高いボラティリティを迎える特徴的なプロファイルを持つ。
- 非定常性: 価格系列は平均が変動しており、定常化に1階差分(d=1)が必要。
- 気象との関連: 気温(ピアソン相関0.42)が価格変動と適度な相関を持つほか、悪天候時の日射量低下が価格の高止まりを招く(メリットオーダー効果)など、気象データが有用な外生変数として期待できる。
今回行った分析はARIMA/SARIMAXモデル開発に焦点を当てていますが、これらのテクニックを知ることでデータへの理解が深まり、どんな時系列モデルを選ぶ際にも適切なアプローチができるようになります。
第2回(Part 2) では、今回得られた「d=1」「s=7」「外生変数の追加」といった知見をそのまま活用し、実際にPythonで ARIMAモデルおよびSARIMAXモデルを構築し、予測精度の評価 を行っていきます。
それでは、次回の記事でお会いしましょう!