はじめに
以前こちらの記事でAWS Lambda上でPlaywrightを動かして図書館の貸出情報を取得するコードなどを書いていましたが、今回はそれを応用して返却期限や予約受取期限を自動でGoogle Taskに登録する仕組みを作ったので、まとめていきます。
ここでお話しすること
- Google Tasks APIの使い方
- LambdaでGoogle Tasks APIを叩く方法
環境
Windows10 Home 22H2
Python 3.12
動機
もともとLambdaで取得した貸出情報はjsonでS3に保存しておき、個人用のLINE botで参照して利用していたのですが、いちいち問い合わせるのが面倒なので直接予定表に反映させてしまえば楽なんじゃないか?と思って作ってみることにしました。
Google Tasks APIの使い方
公式ドキュメントを参考に、以下の操作を実行します。
- GCPでAPIを有効にする
- OAuth 同意画面を構成する
- デスクトップ アプリケーションの認証情報を承認する
途中で生成されるcredentials.jsonはこの後利用するためダウンロードしておきます。
トークンの作成
適当なPython仮想環境などにライブラリをインストールします。
pip install --upgrade google-api-python-client google-auth-httplib2 google-auth-oauthlib
そのうえで公式ドキュメントに記載のquickstart.pyをVSCodeなどで実行すると、初回はGoogleアカウント認証画面に遷移します。ここで認証を行うと'token.json'が保存され、以降、認証する必要はありません。
ちなみに公式サンプルでは読み取り専用権限のスコープでtoken.jsonを作成していますが、書き込みを行う場合はSCOPESを変更してtoken.jsonを作成しておく必要があります。
# 読み取り専用
SCOPES = ["https://www.googleapis.com/auth/tasks.readonly"]
# 書き込みも可能
SCOPES = ["https://www.googleapis.com/auth/tasks"]
今回は自分用のアプリケーションを作成する目的のためcredentials.jsonとtoken.jsonをアプリケーションに組み込んで使用します。
Lambdaアプリケーションコードの作成
まずはGoogle Tasks APIをいじるためのモジュールを作成します。
ポイントは、Lambdaはステートレスのためtoken.jsonとcredentials.jsonを保持できないことから、それらをあらかじめS3に格納しておき、Lambdaで書き込み可能な/tmpディレクトリにコピーしてくることです。
import os.path
import boto3
from google.auth.transport.requests import Request
from google.oauth2.credentials import Credentials
from google_auth_oauthlib.flow import InstalledAppFlow
from googleapiclient.discovery import build
# If modifying these scopes, delete the file token.json.
SCOPES = ["https://www.googleapis.com/auth/tasks"]
s3_bucket = "****S3バケット名を入力****"
s3_key = "token.json"
token_path = "/tmp/token.json"
s3_cred_key = "credentials.json"
credential_path = "/tmp/credentials.json"
def download_token():
s3 = boto3.client("s3")
try:
s3.download_file(s3_bucket, s3_key, token_path)
print("Token downloaded from S3.")
except Exception as e:
print(f"No existing token found in S3: {e}")
def download_creds():
s3 = boto3.client("s3")
try:
s3.download_file(s3_bucket, s3_cred_key, credential_path)
print("Creds downloaded from S3.")
except Exception as e:
print(f"No existing creds found in S3: {e}")
class MyCalendar:
def __init__(self):
"""Shows basic usage of the Tasks API.
Prints the title and ID of the first 10 task lists.
"""
self.creds = None
download_token()
download_creds()
# The file token.json stores the user's access and refresh tokens, and is
# created automatically when the authorization flow completes for the first
# time.
if os.path.exists(token_path):
self.creds = Credentials.from_authorized_user_file(token_path, SCOPES)
# If there are no (valid) credentials available, let the user log in.
if not self.creds or not self.creds.valid:
if self.creds and self.creds.expired and self.creds.refresh_token:
self.creds.refresh(Request())
else:
flow = InstalledAppFlow.from_client_secrets_file(
credential_path, SCOPES
)
self.creds = flow.run_local_server(port=0)
# Save the credentials for the next run
with open(token_path, "w") as token:
token.write(self.creds.to_json())
self.service = build("tasks", "v1", credentials=self.creds)
def get_tasklists(self) -> list:
result = self.service.tasklists().list().execute()
tasklists = result.get("items", [])
if not tasklists:
print("タスクリストが見つかりません")
return
else:
return tasklists
def get_tasks(self, tasklist_id: str):
tasks_result = self.service.tasks().list(tasklist=tasklist_id).execute()
tasks = tasks_result.get("items", [])
if not tasks:
print(" No tasks found.")
else:
return tasks
def insert(self, tasklist_id, body) -> None:
result = self.service.tasks().insert(tasklist=tasklist_id, body=body).execute()
print(f"登録完了: {result['title']}(ID: {result['id']})")
def delete(self, tasklist_id, task_id) -> None:
self.service.tasks().delete(tasklist=tasklist_id, task=task_id).execute()
print(f"削除しました: (ID: {task_id})")
次にアプリケーションコード側では、図書館ごとのIDやS3からのjsonの読み取り、タスク削除・登録処理などを作っていきます。
import json
import boto3
from datetime import datetime
from task import MyCalendar
LOCATION_CARD = [
("area_name", "card_number", "●●図書館"),
("area_name", "card_number", "●●図書館"),
("area_name", "card_number", "●●図書館")
]
HASHTAG = "#library_reminder"
def clear_tasks():
mycal = MyCalendar()
tasklists = mycal.get_tasklists()
tasklist_id = tasklists[0]["id"]
tasks = mycal.get_tasks(tasklist_id)
# 登録済みのタスクを削除
for task in tasks:
print(task)
if HASHTAG in task["title"]:
print("delete task", task["id"])
mycal.delete(tasklist_id, task["id"])
def register_task(body):
mycal = MyCalendar()
tasklists = mycal.get_tasklists()
tasklist_id = tasklists[0]["id"]
mycal.insert(tasklist_id=tasklist_id, body=body)
def lambda_handler(event, context):
clear_tasks()
for location, card, area in LOCATION_CARD:
response = get_library_status(location, card)
# 貸出中
lent_items = json.loads(response)["body"]["lent_items"]
# {返却日:タイトルのリスト}にまとめる
return_dates = {}
for i, item in enumerate(lent_items):
# キーがない場合は初期化
if item["return_date"] not in return_dates.keys():
return_dates.update({item["return_date"]: []})
val = return_dates[item["return_date"]]
val.append(f"📕{item['title']}")
return_dates.update({item["return_date"]: val})
# 返却日ごとにタスクを生成
for date, item in return_dates.items():
# datetimeオブジェクトに変換
dt = datetime.strptime(date, "%Y/%m/%d")
# ISO 8601形式(UTC)に変換
iso_format = dt.strftime("%Y-%m-%dT%H:%M:%S.000Z")
notes = "\r\n".join(item)
new_task = {
"title": f"[返却期限]{area} {HASHTAG}",
"notes": notes,
"due": iso_format,
}
register_task(new_task)
# 予約中
reserve_items = json.loads(response)["body"]["reserve_items"]
# {予約期限日:タイトルのリスト}にまとめる
reserve_expire_dates = {}
for i, item in enumerate(reserve_items):
# 値が無い場合はスキップ
if not item["reserve_expire_date"]:
continue
# キーがない場合は初期化
if item["reserve_expire_date"] not in reserve_expire_dates.keys():
reserve_expire_dates.update({item["reserve_expire_date"]: []})
val = reserve_expire_dates[item["reserve_expire_date"]]
val.append(f"📘{item['title']}")
reserve_expire_dates.update({item["reserve_expire_date"]: val})
# 予約期限日ごとにタスクを生成
for date, item in reserve_expire_dates.items():
# datetimeオブジェクトに変換
dt = datetime.strptime(date, "%Y/%m/%d")
# ISO 8601形式(UTC)に変換
iso_format = dt.strftime("%Y-%m-%dT%H:%M:%S.000Z")
notes = "\r\n".join(item)
new_task = {
"title": f"[予約期限]{area} {HASHTAG}",
"notes": notes,
"due": iso_format,
}
register_task(new_task)
return {"statusCode": 200}
# 図書館の利用状況を調べる
def get_library_status(location, card):
LIBRARY_STATUS_BUCKET_NAME = "****図書館の利用状況をjsonでダウンロードしてあるバケット名****"
s3 = boto3.resource("s3")
bucket = s3.Bucket(LIBRARY_STATUS_BUCKET_NAME)
object_key_name = f"{location}_{card}.json"
try:
# 対象のjsonを取得し中身を取り出す
obj = bucket.Object(object_key_name)
response = obj.get()
body = response["Body"].read()
# json -> 辞書型へ変換
json_data = json.loads(body.decode("utf-8"))
except Exception:
print("指定したファイルは存在しません")
json_data = {}
return json_data
以上まとめて、Google Tasks APIを操作するためにサードパーティライブラリを使用することから、Lambda関数はコンテナイメージで作成することとします。
task.pyとapp.pyはsrcフォルダにまとめておき、コンテナイメージを作るためのDockerfileを書きます。以前にPlaywrightでやったのと似ていますが、FROMの部分を変えるなどして作っていきます。
フォルダ構成はこのようになります
(root)
+src
| +app.py
│ +task.py
|
+Dockerfile
# Define custom function directory
ARG FUNCTION_DIR="/function"
FROM python:3.12 AS build-image
# Include global arg in this stage of the build
ARG FUNCTION_DIR
# Copy function code
RUN mkdir -p ${FUNCTION_DIR}
# COPY . ${FUNCTION_DIR}
COPY src/* ${FUNCTION_DIR}
# Install the function's dependencies
RUN python -m pip install --upgrade pip
RUN python -m pip install --target ${FUNCTION_DIR} boto3 awslambdaric
RUN python -m pip install --target ${FUNCTION_DIR} google-api-python-client google-auth-httplib2 google-auth-oauthlib
# Use a slim version of the base Python image to reduce the final image size
FROM python:3.12-slim
# Include global arg in this stage of the build
ARG FUNCTION_DIR
# Set working directory to function root directory
WORKDIR ${FUNCTION_DIR}
# Copy in the built dependencies
COPY --from=build-image ${FUNCTION_DIR} ${FUNCTION_DIR}
# Set runtime interface client as default command for the container runtime
ENTRYPOINT [ "/usr/local/bin/python", "-m", "awslambdaric" ]
# Pass the name of the function handler as an argument to the runtime
CMD [ "app.lambda_handler" ]
Dockerfileができたら、ECRにリポジトリを作り、ビルド、タグ付け、プッシュまではECRの説明通りに行います。
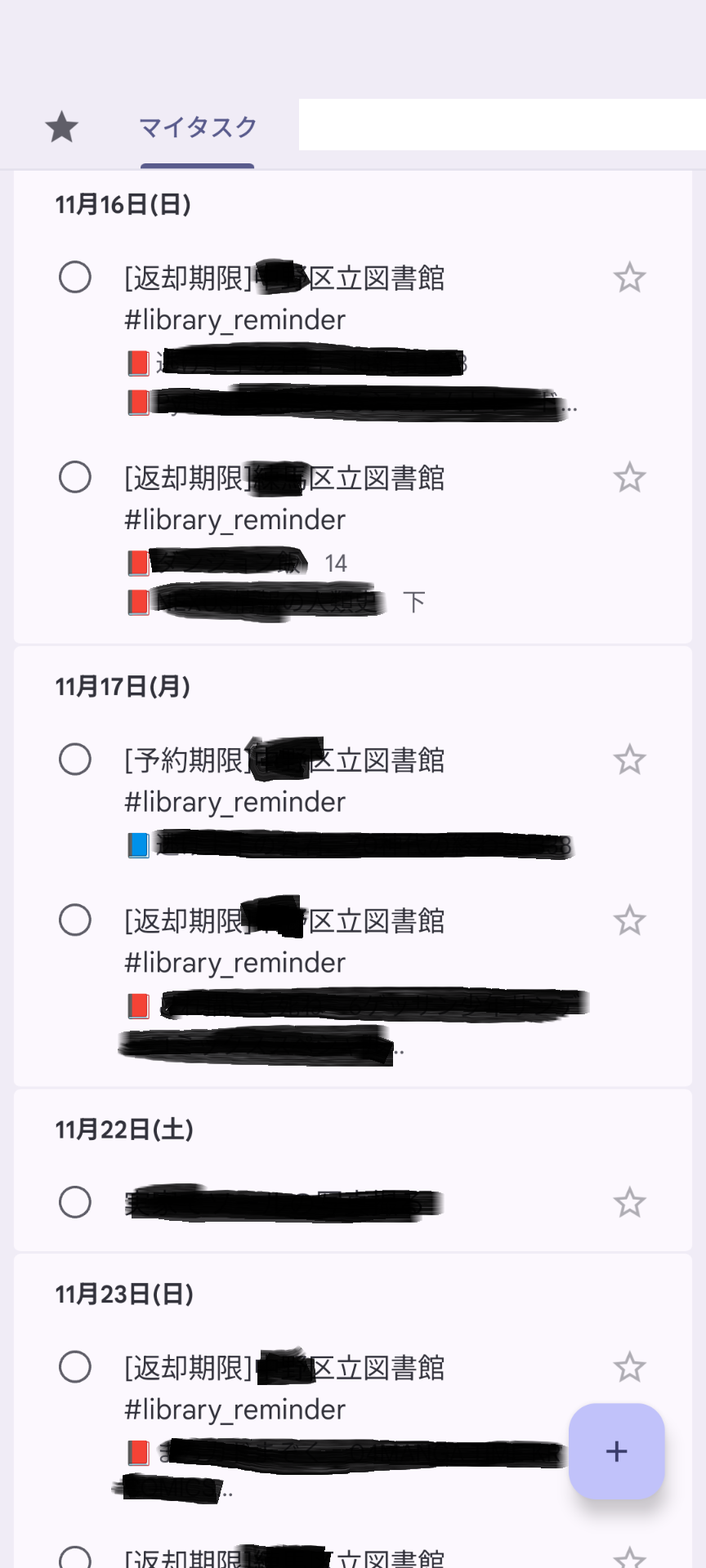
動作イメージ
ECRにプッシュしたらLambda関数を作成し、プッシュしたコンテナイメージを使うように設定します。S3ReadOnlyとLambdaBasicExecutionの権限を付与しておきます。無事動作すると、自分のGoogle Taskにこのように反映されます。(自治体名と書名はマスクしています)
#library_reminderという文字列をキーにしてタスクを全消去、再作成しているので、返却期限の延長や新たな貸出があっても自動で反映します。EventBridgeで数時間おきに動かすようにしておけば情報の鮮度としても問題ないでしょう。