クラッシュロワイヤルに出てくるゴブリンをトラッキングしたった ①データ取得
クラッシュロワイヤルに出てくるゴブリンをトラッキングしたった ②アノテーション追加
の続きです。
What is Amazon ReKognition?
Amazon ReKognition とはクラウド上でDeepLearningにもとづいた画像・動画分析ができるサービスです。何もしなくても顔やテキストを抽出することができるみたいですが、今回のテーマであるゲームキャラクタなどの任意のオブジェクトもアノテーション(ラベリング)をつけて学習・推論をかけることができます。

Preparetion
必要なものとして、S3とmanifestファイルの2つが必要です。S3は学習や推論をかけたい画像を格納するのに使います。manifestファイルは画像内にあるオブジェクトの情報であるアノテーションが集約されたReKognition用のファイルです。 クラッシュロワイヤルに出てくるゴブリンをトラッキングしたった ②アノテーション追加ではPASCAL VOC 1.1形式に変換してエクスポートしていますが、ここからmanifestファイルを作成します。
s3 upload
学習に使った画像をs3にアップロードします。
ml-clashroyal/ (←バケット)
├ annotation/ (マニフェストファイル保存先)
├ learn/ (学習用画像)
└ evaluate/ (評価用画像)
create manifest file
PASCALからmanifestファイルを出力するのにpascalgtというライブラリを追加します。
このライブラリはDaikiTanakが個人で作成されたものです。
pip install pascalgt
pascalgtをもとにスクリプトを作成しました。
コマンド実行時に追加する引数は
- プロジェクト名
- ReKognitionでプロジェクトを作るときに使います
- S3パス
- s3://xxxxx
- マニフェストファイルの出力先
- PASCAL内のxmlファイル場所
-
Annotationsの中にあります。
-
の4つです。
import argparse
from pascalgt.transformer import Pascal2GT
def main():
parser = argparse.ArgumentParser()
parser.add_argument("--pj_name", default="pj_name", help="プロジェクト名")
parser.add_argument("--s3_path", default="s3://", help="s3パス")
parser.add_argument("--output", default="./output.manifest", help="マニフェストファイルの出力先")
parser.add_argument("--xml_path", default="./Annotations", help="PASCAL内のxmlファイル場所")
args = parser.parse_args()
pascal2gt = Pascal2GT(project_name=args.pj_name, s3_path=args.s3_path)
pascal2gt.run(path_target_manifest=args.output, path_source_xml_dir=args.xml_path)
if __name__ == "__main__":
main()
python main.py --pj_name="track_goblins" --s3_path="s3://ml-clashroyal/learn" --xml_path="./track_goblin/Annotations/"
実行後はマニフェストファイルができるので、このファイルをs3に格納します。
ここではml-clashroyal/annotationに入れてます。
Method
材料がそろったのでAmazon Rekognitionを使ってモデルを作成しようと思います。
「カスタムラベルを使用」をクリック
「Projects」をクリック

「Create project」をクリック
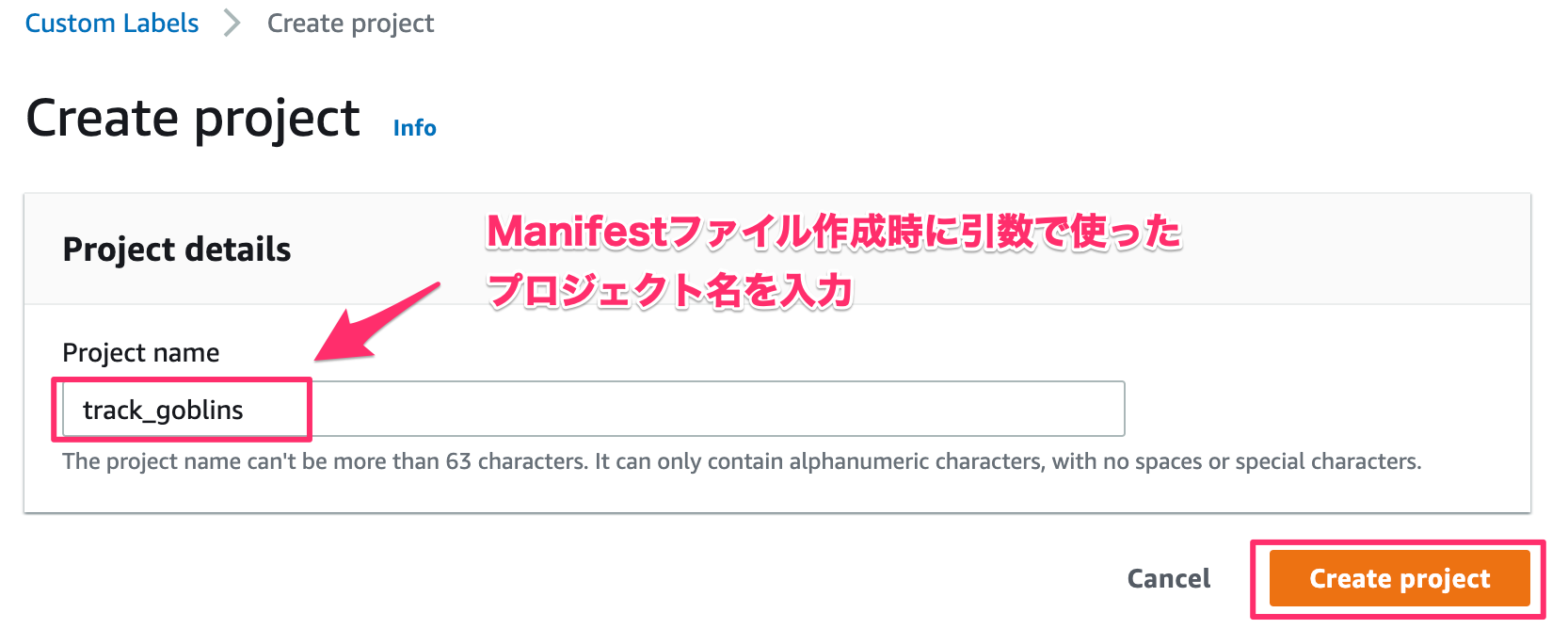
プロジェクト名を追加する。
ここでは、 create manifest fileでスクリプトを実行したときに使ったプロジェクト名を入力します。
「Create project」をクリック。
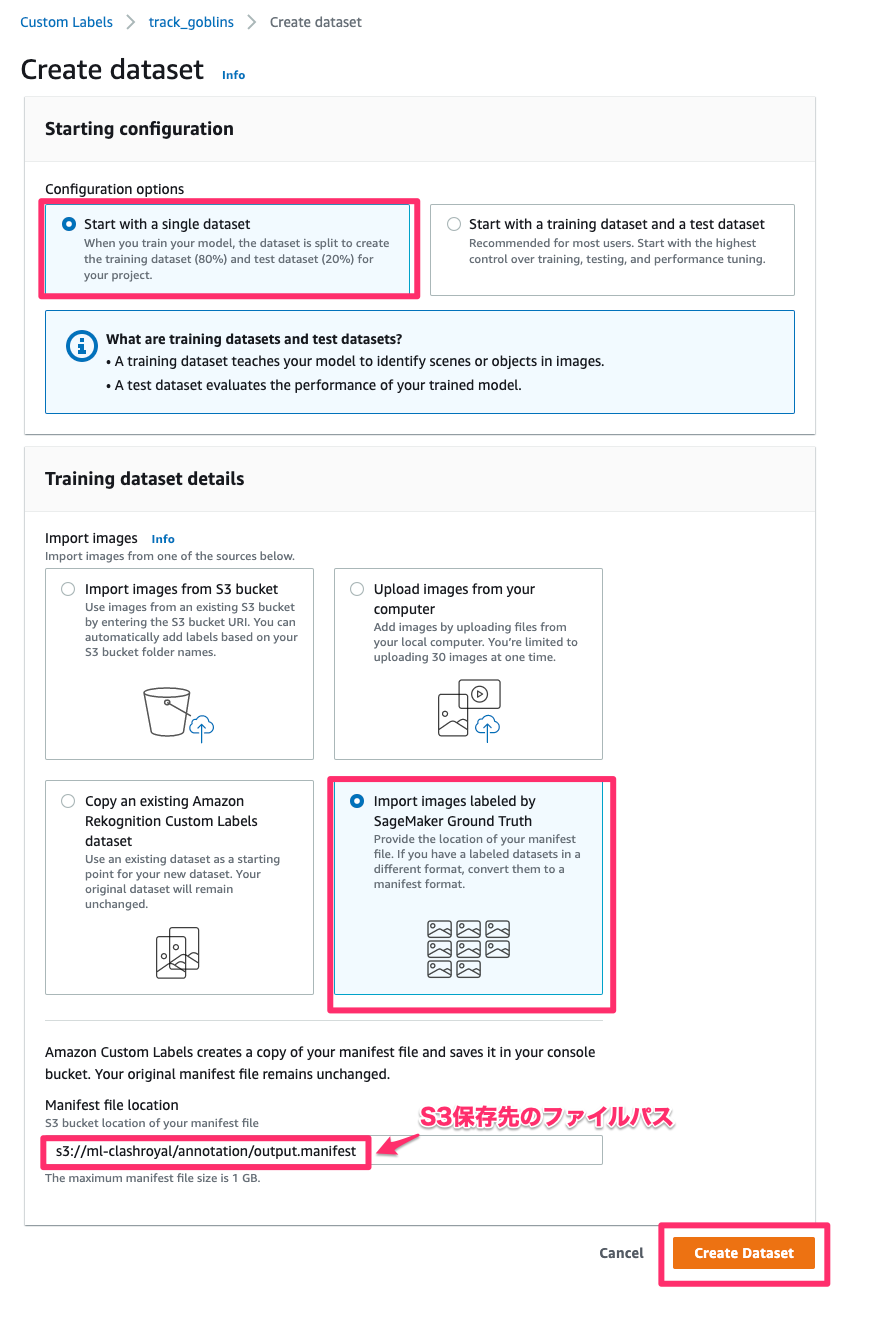
「Create dataset」をクリック。
Starting configurationは「Start with a single dataset」を選ぶ
Training dataset detailsは右下の「Import Images labeled by SageMaker Ground Truth」を選び、S3に保存してあるマニフェストファイルのS3パスを入力する。
「Create Dataset」をクリック。
LabelsでLabeledを選んでアノテーションが付いているか確認する。
問題なければ「Train model」をクリックする。
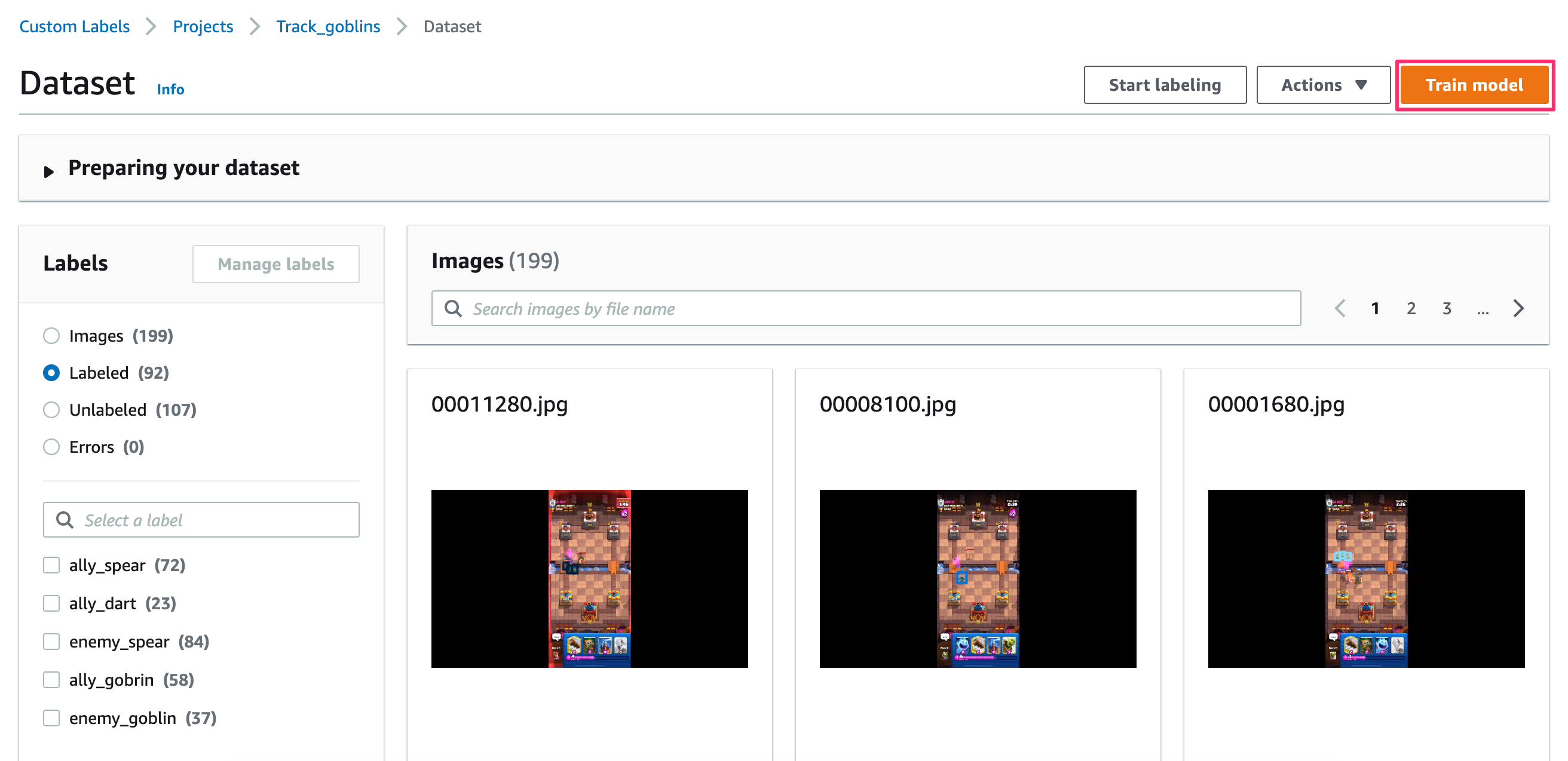
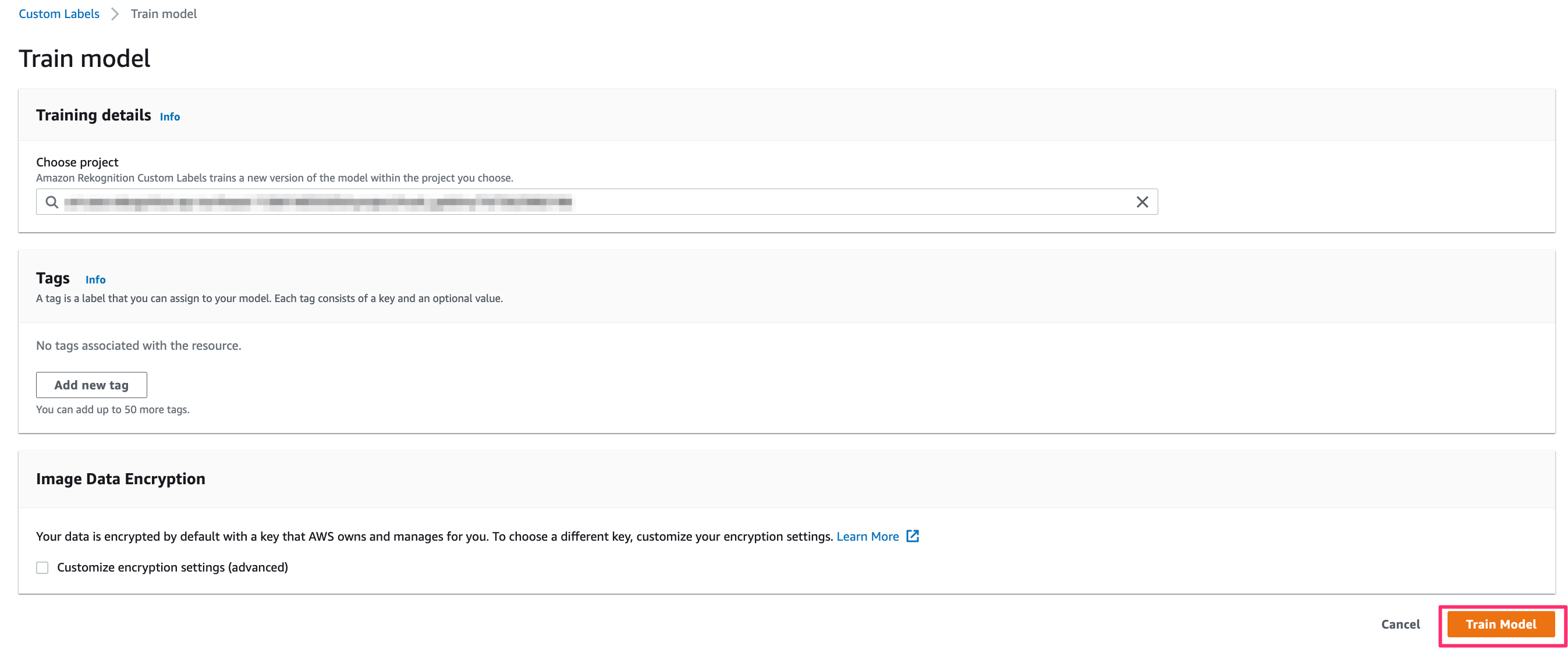
何も考えずに「Train model」をクリックする。
これで学習がスタートします。
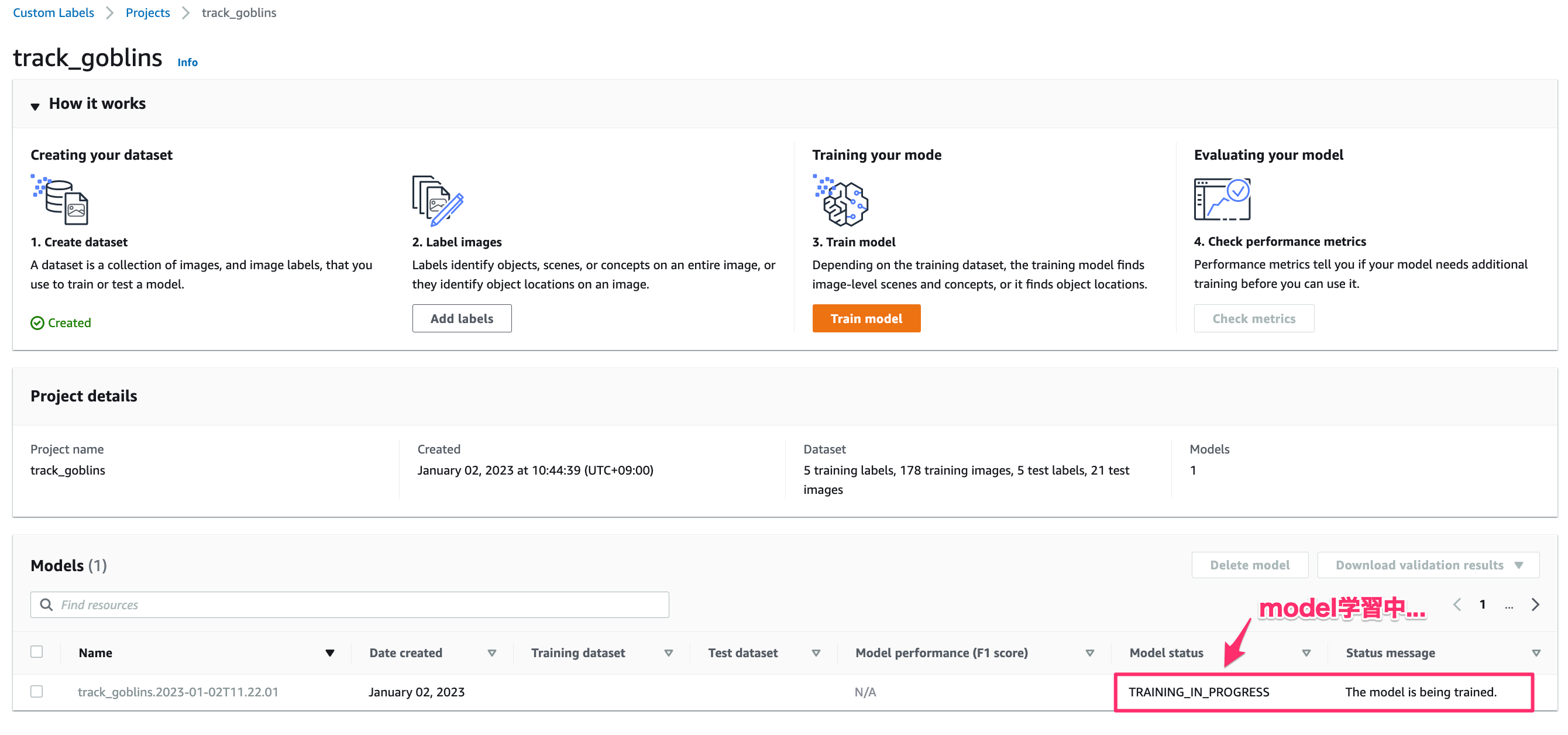
学習はすぐ終わりません。
学習中は「TRAINING_IN_PROGRESS」と表示されます
Consequence
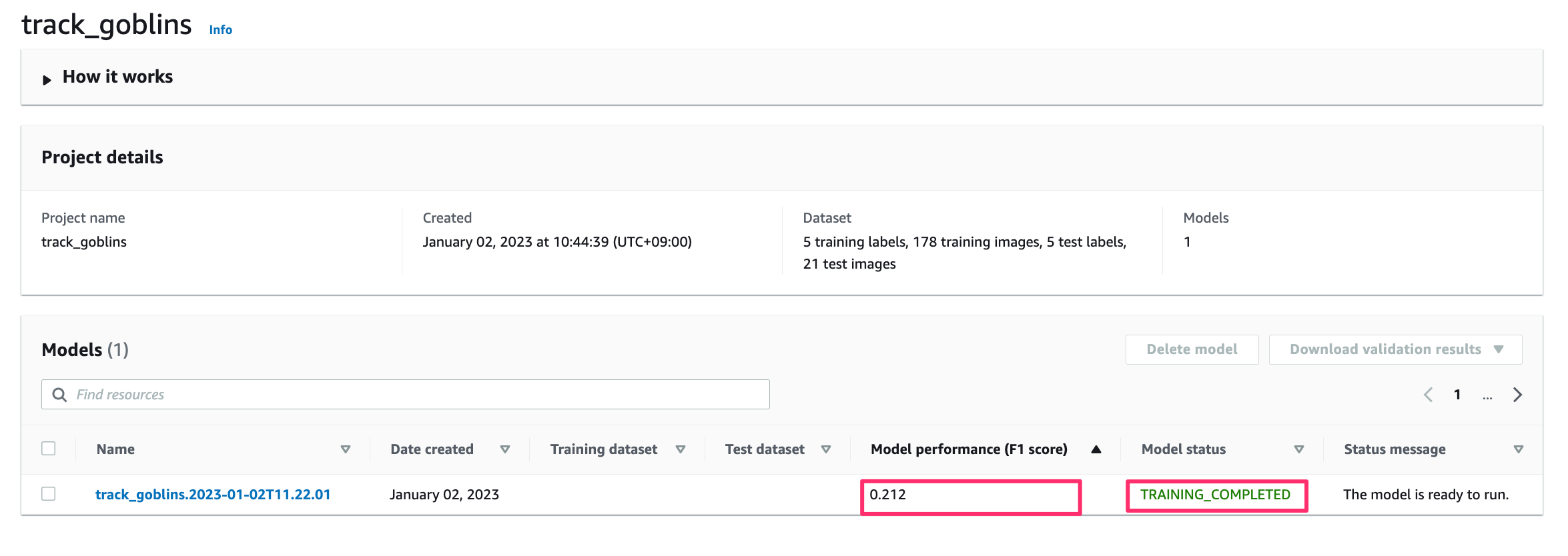
数時間後を見るとモデルが完成しました。
できたのはいいのですが、F1(適合率と再現率を考慮した値)が結構低いです![]()
なので、精度を高めるにはもう一度アノテーションを作り直すかデータ数を増やすか、、、などのことが必要です。
To Be Continued
今回出たモデルの精度が低いですが、推論の方法までを通しでやってみたい!!!があります。
次回は作成したモデルを使って推論し、物体検出をしてみます。