Motive
以前に pytorch+yolov3を使ってマリオを物体検出してみた でGPU搭載の自作PCで学習と推論をかけてみましたが、ここから約2年が経過しました。 現在ではAWSやGCP、Azureなどのクラウドサービスで機械学習が出来るみたいで、時間をかけてキャッチアップが必要と感じました。
ここではデータ取得から物体検出までの流れを書いてみようと思います。
Dataset
身の回りのものですぐに学習・推論ができそうな題材として一番多くプレイしているゲームが最適と思いました。
自分の場合はクラッシュ・ロワイヤルでゲームをすることが多いのでプレイ動画を撮ろうと思います。

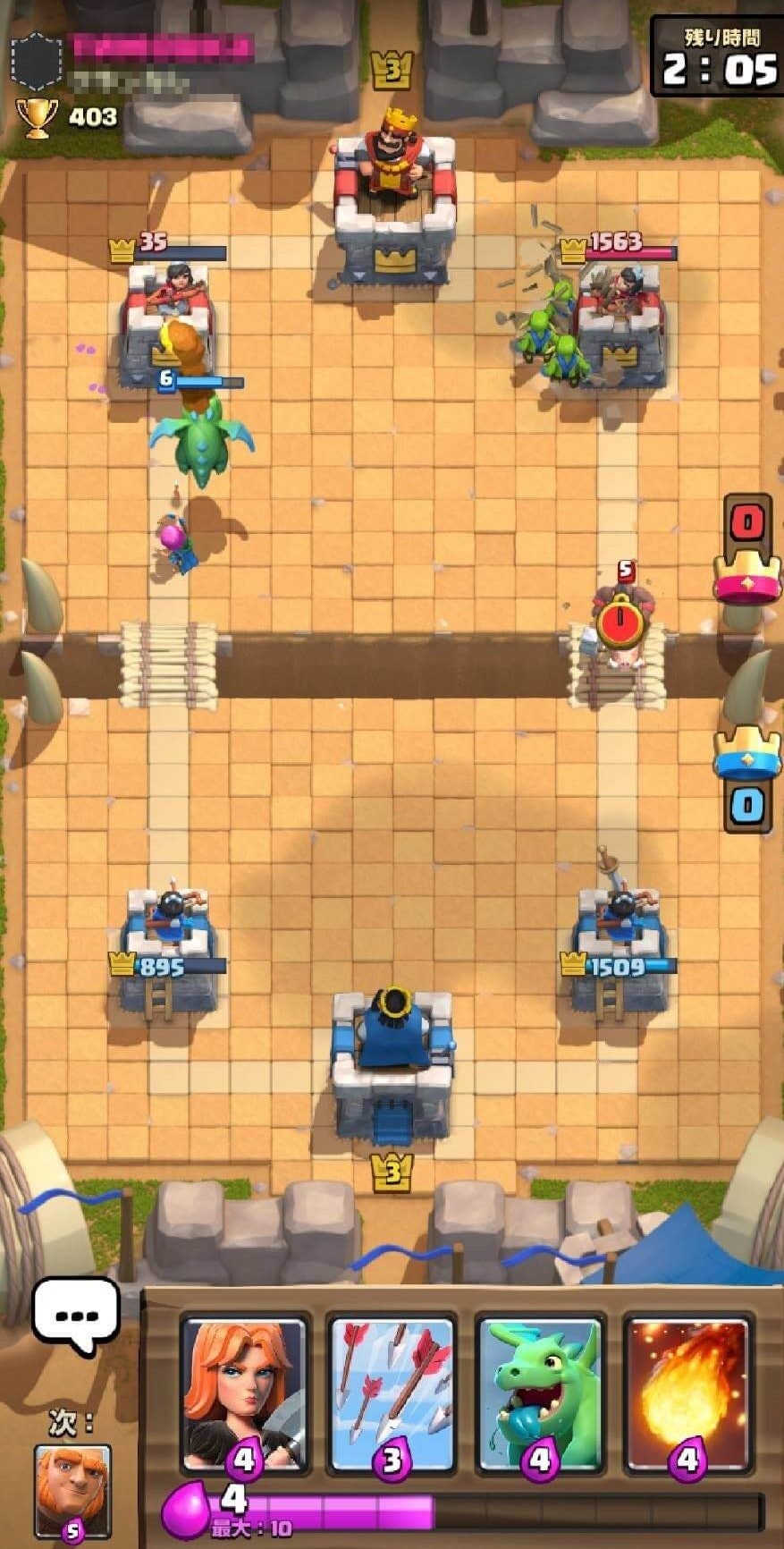
Method
プレイ動画を取得する方法はomletというゲーム配信アプリを使います。このアプリの中にプレイ動画を保存する機能があるので、こちらを使います。

次に冒頭部分などの不要な部分を削除します。
スマホアプリでできると思いますが、ここではiMovieを使って最初と最後をカットしてmp4形式の動画を生成しました。
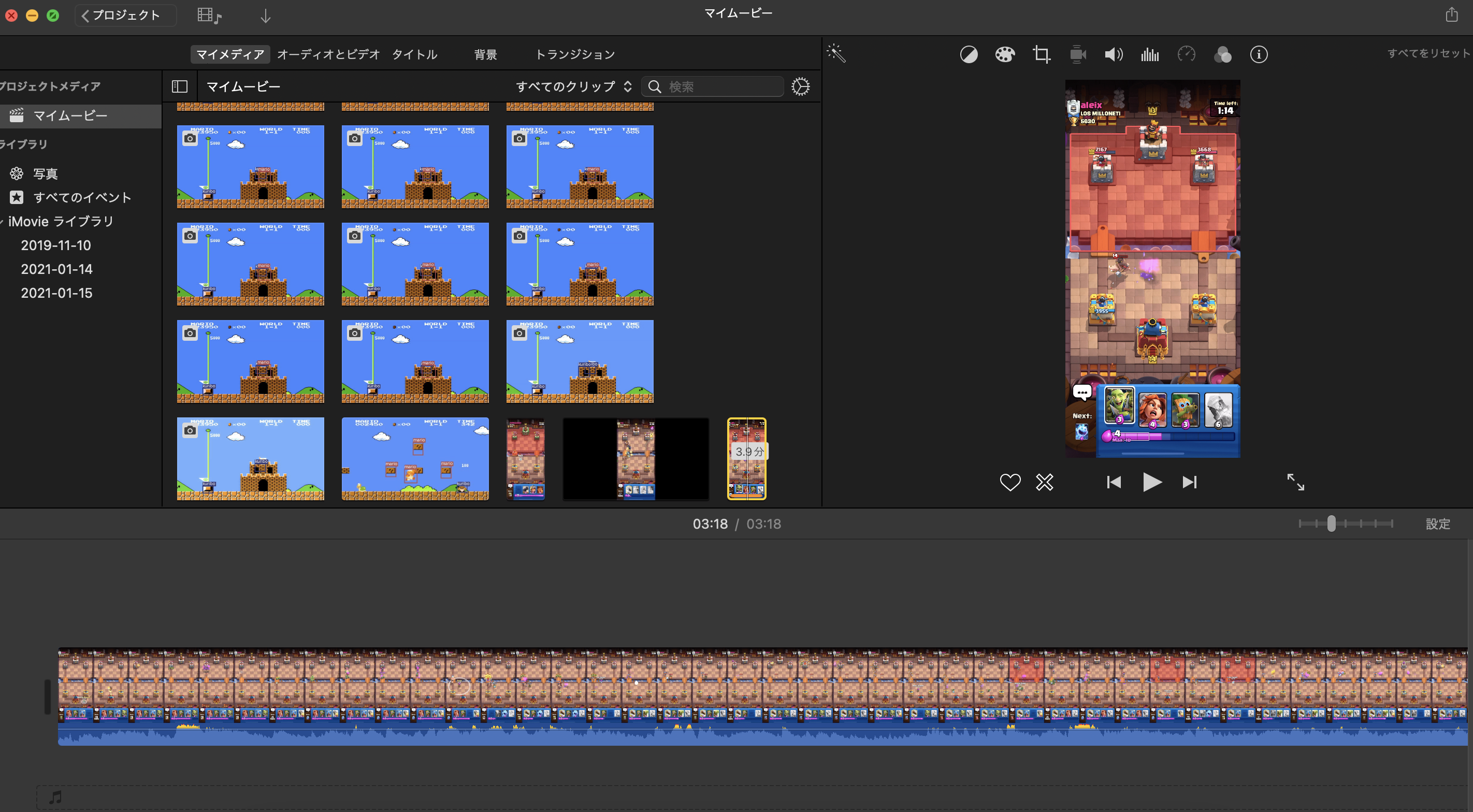
最後に動画から画像に変換します。
ここでは変換用のスクリプトファイルをダウンロードして使っています。 1秒間に60フレームの画像があって動画再生時間も約4分あるので全て画像を取得すると約1万5千枚になってしまいます。今回は単に機械学習でモデルを作りたいだけなのでラベリングする枚数は少なくて良いので1秒間に1枚で十分です。なので取得するフレームレートを-r 1にしています。
wget https://raw.githubusercontent.com/wkentaro/dotfiles/f3c5ad1f47834818d4f123c36ed59a5943709518/local/bin/video_to_images
pip install imageio imageio-ffmpeg tqdm
python video_to_images -r 1 your_video.mp4
実行後は your_video フォルダ内にフレーム画像が格納されています。
To Be Continued
次回は cvat を使ったアノテーション(ラベリング)の付け方についてです。