Motive
巨大なテーブルをBigqueryに転送する方法 ではひとつのテーブルに約2億レコードあって約100GBある巨大なデータをBigqueryに移行する方法を書いています。 現在は移行作業は完了し、次のタスクとして日次で追加されているMySQLのデータをBigqueryに移行するスクリプトを作成していました。24時間分と前回のデータよりはかなり少ないので、サーバ自体のメモリや容量などので考慮すべき部分はないのでここで紹介する方法はよく使うパターンではないかと思います。また、前回ではデータの経由地点としてS3を使っていましたが、ここではGCPのCloud Storageを使っています。同じGCP内であるためか空のテーブルの作成や転送の構成を設定する必要がないので比較的簡単に転送は出来ました。ここではGCPのサービスのみでBIgqueryに転送する方法を紹介します。
Preparetion
必要なパッケージは下記の通りです。
pip install -r requirements.txt
pyarrow
google-auth
google-api-python-client
google-auth-httplib2
google-auth-oauthlib
google-cloud-bigquery
google-cloud-storage
Method
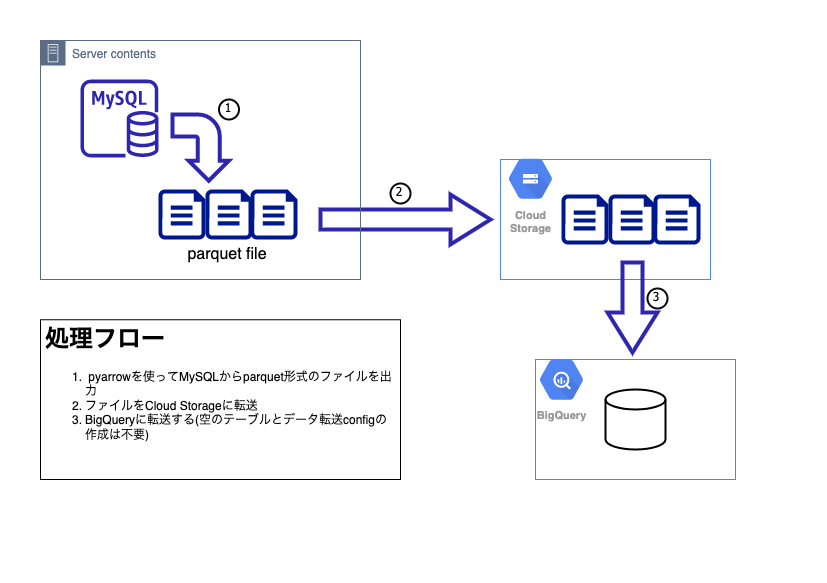
フローは3つのステップ。
- MySQLからparquet形式のファイルを出力
- Cloud Storageのbucketに転送
- Bigqueryに転送
Development
全体のコードを掲載します。 process の後半を見ると前述の3つのステップ output_parquet cs_upload fill_lake を処理していることがわかると思います。 また、 cs_upload fill_lakeではBigqueryAPI、CloudStorageAPIを有効にしたGCPの認証ファイルを読み込ませる必要があります。認証ファイル作成方法については、Google APIを利用するためのサービスアカウントの設定(認証)を参照。
認証ファイル読み込み
credentials = service_account.Credentials.from_service_account_file(
'./featurepoints_credential.json',
scopes=["https://www.googleapis.com/auth/cloud-platform"]
)
コード全体
from google.oauth2 import service_account
from google.cloud import bigquery
from google.cloud import storage
import mysql.connector
import pandas as pd
import pyarrow as pa
import pyarrow.parquet as pq
import argparse
import datetime
import os
import time
# gloval valiable
DB_USER="--user name--"
DB_PASSWORD="--password--"
DB_NAME="--database name--"
BUCKET_NAME = "-- the name of bucket in the cloud storage --"
if __name__ == '__main__':
process()
def process():
parser = argparse.ArgumentParser()
parser.add_argument('table_name', help='テーブル名')
parser.add_argument('--prod', action='store_true', help='本番環境指定')
parser.add_argument('--begin', help='where from')
parser.add_argument('--end', help='where to')
args = parser.parse_args()
target_date = datetime.datetime.now() - datetime.timedelta(days=1)
try:
begin_date = target_date.strftime('%Y-%m-%d 00:00:00')
end_date = target_date.strftime('%Y-%m-%d 23:59:59')
if args.begin is not None and args.end is not None:
begin_date = datetime.datetime.strptime(args.begin, '%Y-%m-%d')
end_date = datetime.datetime.strptime(args.end, '%Y-%m-%d')
begin_date = begin_date.strftime('%Y-%m-%d 00:00:00')
end_date = end_date.strftime('%Y-%m-%d 23:59:59')
except ValueError as e:
print(e)
print("from:{0} to:{1}".format(begin_date, end_date))
try:
#MySQL から parquet形式のファイルをexport
output_parquet(args.table_name, begin_date, end_date)
#parquetファイルをcloud strageにupload
cs_upload(args.table_name)
#cloud strageファイルをbigqueryにexport
dataset_name = "development"
if args.prod:
dataset_name = "TWITTER"
fill_lake(args.table_name, dataset_name)
except Exception as e :
print ("不明なエラーです")
print (e)
def output_parquet(table_name, begin_date, end_date):
"""
MySQL から parquet形式のファイルをexport
"""
conn = mysql.connector.connect(user=DB_USER, database=DB_NAME,
password=DB_PASSWORD,
host="localhost",
port=3306)
cursor = conn.cursor()
query = "SELECT * FROM ONE_WEEK_{0} WHERE '{1}' <= created_at AND created_at <= '{2}'".format(table_name, begin_date, end_date)
pd_frame = pd.read_sql(query, con=conn)
conn.close()
table = pa.Table.from_pandas(pd_frame)
pq.write_table(table, './src/{}_segment.parquet'.format(table_name))
def cs_upload(table_name):
"""
parquetファイルをcloud strageにupload
"""
credentials = service_account.Credentials.from_service_account_file(
'./featurepoints_credential.json',
scopes=["https://www.googleapis.com/auth/cloud-platform"]
)
storage_client = storage.Client(
credentials=credentials,
project=credentials.project_id,
)
bucket = storage_client.get_bucket(BUCKET_NAME)
source_file_name = './src/{}_segment.parquet'.format(table_name)
blob = bucket.blob(os.path.basename(source_file_name))
blob.upload_from_filename(source_file_name)
def fill_lake(table_name, dataset_name):
"""
cloud strageファイルをbigqueryにexport
"""
credentials = service_account.Credentials.from_service_account_file(
'./featurepoints_credential.json',
scopes=["https://www.googleapis.com/auth/cloud-platform"]
)
client = bigquery.Client(
credentials=credentials,
project=credentials.project_id,
)
dataset_ref = client.dataset(dataset_name)
job_config = bigquery.LoadJobConfig()
job_config.autodetect = True
job_config.source_format = bigquery.SourceFormat.PARQUET
bucket_uri = "gs://{0}/{1}_segment.parquet".format(BUCKET_NAME, table_name)
load_job = client.load_table_from_uri(
bucket_uri,
dataset_ref.table(table_name),
job_config=job_config
)
print("Starting job {}".format(load_job.job_id))
load_job.result()
print("Job finished.")
destination_table = client.get_table(dataset_ref.table(table_name))
print("Loaded {} rows.".format(destination_table.num_rows))
PostScript
日次の定期実行のスクリプトも作成し、Biqueryへの移行はひと通り終わりました。
しかし、データ移行するときにEC2のストレージを大きくしたのですが、縮小することができないみたいです。
調べると新しい手頃なサイズのストレージを一つ用意してデータを移管して、古いストレージを削除する方法だとできるみたいですが、いつやろうか![]()
サーバ止めてるだけでも結構料金がかかるみたいです。