はじめに
ここでは政見放送の下に表示される字幕から文字を抽出してみようと思います。
背景が何もないので二値化でなんとかなりそうです。
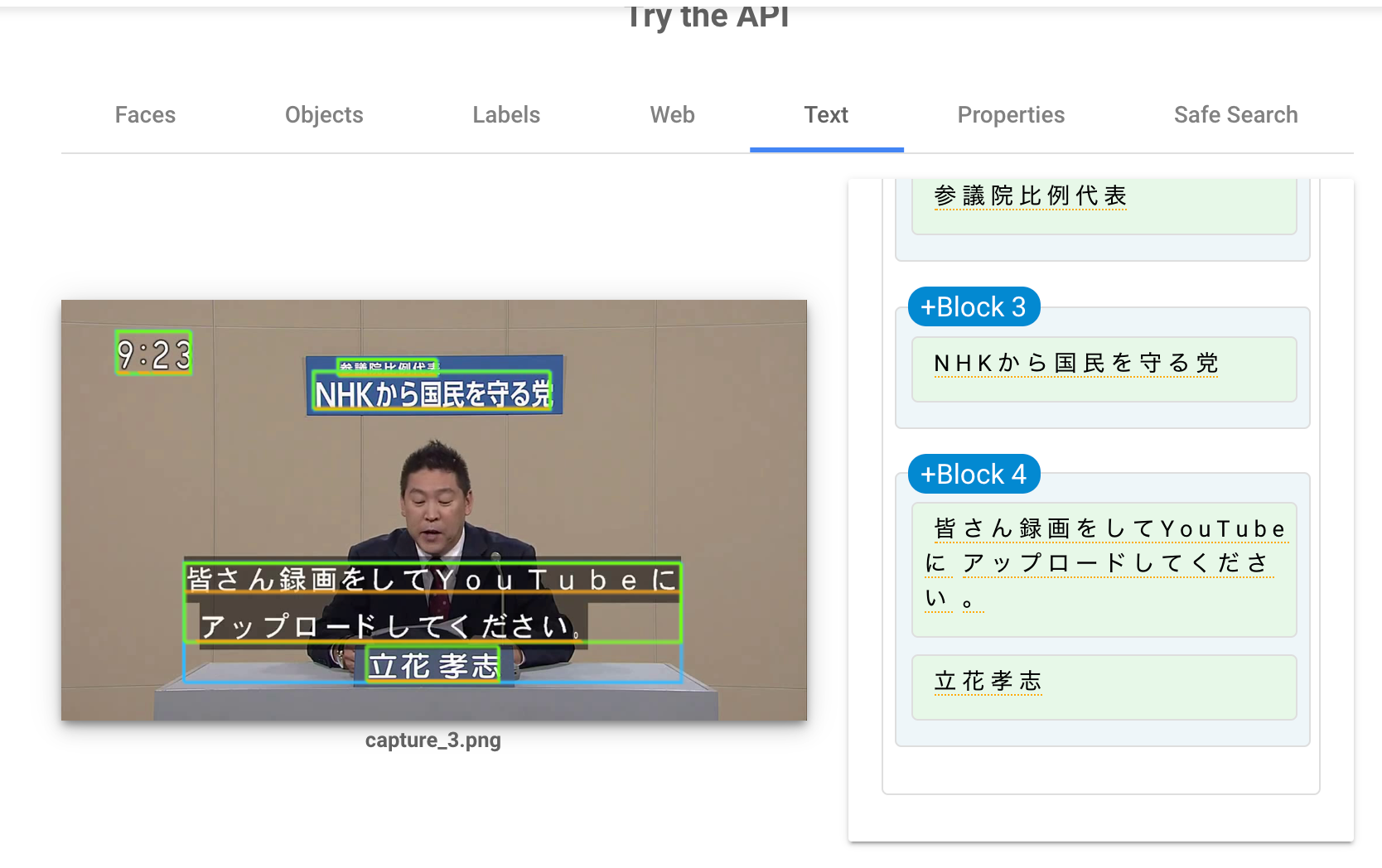
google cloud vision API で 文字抽出するとかなりの精度で文字と配置(position)を取得することはできるのですが、ここでは他の方法で文字を取得しようと思います。
tesseract-ocr / pyocr
最初に tesseract と pyocr を使って文字認識させてみます。
ソースの画像です。

下記のスクリプトで文字と位置を抽出します。
import sys
import pyocr
import pyocr.builders
import cv2
from PIL import Image
def imageToText(src):
tools = pyocr.get_available_tools()
if len(tools) == 0:
print("No OCR tool found")
sys.exit(1)
tool = tools[0]
dst = tool.image_to_string(
Image.open(src),
lang='jpn',
builder=pyocr.builders.WordBoxBuilder(tesseract_layout=6)
)
return dst
if __name__ == '__main__':
img_path = sys.argv[1]
out = imageToText(img_path)
img = cv2.imread(img_path)
sentence = []
for d in out:
sentence.append(d.content)
cv2.rectangle(img, d.position[0], d.position[1], (0, 0, 255), 2)
print("".join(sentence).replace("。","。\n"))
cv2.imshow("img", img)
cv2.imwrite("output.png", img)
cv2.waitKey(0)
cv2.destroyAllWindows()
- 文字
第二十五条すべて国民は、健康で文化的な最低限度の生活を営む権利を有する。
2国は、すべての生活部面について、社会福祉、社会保障及び公衆衛生の向上及び増進に努めなければならない。
(教育を受ける権利と受けさせる議務]第二十六条すべて国民は、法律の定めるところにより、その能力に応じて、ひとしく教育を受ける権利を有する。
2すべて国民は、法律の定めるところにより、その保護する子女に普通教育を受けさせる義務を負ふ。
義務教育は、これを無償とする。
[勤労の権利と義務、勤労条件の基準及び児童酷使の禁止〕第二十七条すべて国民は、勤労の権利を有し、義務を負ふ。
2賃金、就業時間、休息その他の勤労条件に関する基準は、法律でこれを定める。
3児童は、これを路使してはならない。
勤労者の団結権及び団体行動権〕第二十八条勤労者の団結する権利及び団体交渉その他の団体行動をする権利は、これを保障する。
財産権〕第二十九条財産権は、これを侵してはならない。
2財産権の内容は、公共の福祉に適合するやうに、法律でこれを定める。
3私有財産は、正当な補償の下に、これを公共のために用ひることができる。
- 文字位置

wordやhtmlなどから取得した文字のみの画像では、文字自体は取得できるものの正確な文字の位置は取得は厳しそうです。 ここでのほしいのは一文単位の位置ですが、tesseract_layout=6 のパラメータで調整はしても文字単位でしか取得できそうにないです。
方法


二値化やHough変換で直線抽出などをしてみたのですが、一度字幕が出そうな箇所のみをROI(画像の一部切り出し)してOCRをかけてみようと思います。
灰色の字幕のみをエリアで抽出できないか考えたのですが、人物と被るので自分のありそうな知識では厳しいです![]()
開発
import sys
import cv2
import os
import numpy as np
import pyocr
import pyocr.builders
from PIL import Image, ImageDraw, ImageFont
import time
def process(src):
kernel = np.ones((3,3),np.uint8)
gray = cv2.cvtColor(src, cv2.COLOR_BGR2GRAY)
o_ret, o_dst = cv2.threshold(gray, 0, 255, cv2.THRESH_OTSU)
dst = cv2.morphologyEx(o_dst, cv2.MORPH_OPEN, kernel)
return cv2.bitwise_not(dst)
def imageToText(tool, src):
tmp_path = "temp.png"
cv2.imwrite(tmp_path, src)
dst = tool.image_to_string(
Image.open(tmp_path),
lang='jpn',
builder=pyocr.builders.WordBoxBuilder(tesseract_layout=6)
)
sentence = []
for item in dst:
sentence.append(item.content)
return "".join(sentence)
def createTextImage(src, sentence, px, py, color=(8,8,8), fsize=28):
tmp_path = "src_temp.png"
cv2.imwrite(tmp_path, src)
img = Image.open(tmp_path)
draw = ImageDraw.Draw(img)
font = ImageFont.truetype("./IPAfont00303/ipag.ttf", fsize)
draw.text((px, py), sentence, fill=color, font=font)
img.save(tmp_path)
return cv2.imread(tmp_path)
if __name__ == '__main__':
tools = pyocr.get_available_tools()
if len(tools) == 0:
print("No OCR tool found")
sys.exit(1)
tool = tools[0]
cap = cv2.VideoCapture('one_minutes.mp4')
cap_width = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH))
cap_height = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
fps = cap.get(cv2.CAP_PROP_FPS)
telop_height = 50
fourcc = cv2.VideoWriter_fourcc('m','p','4','v')
writer = cv2.VideoWriter('extract_telop_text.mp4',fourcc, fps, (cap_width, cap_height + telop_height))
start = time.time()
count = 0
try :
while True:
if not cap.isOpened():
break
if cv2.waitKey(1) & 0xFF == ord('q'):
break
ret, frame = cap.read()
if frame is None:
break
telop = np.zeros((telop_height, cap_width, 3), np.uint8)
telop[:] = tuple((128,128,128))
gray_frame = process(frame)
roi = gray_frame[435:600, :]
txt = imageToText(tool, roi)
images = [frame, telop]
frame = np.concatenate(images, axis=0)
font = cv2.FONT_HERSHEY_SIMPLEX
seconds = round(count/fps, 4)
cv2.putText(frame, "{:.4f} [sec]".format(seconds),
(cap_width - 250, cap_height + telop_height - 10),
font,
1,
(0, 0, 255),
2,
cv2.LINE_AA)
writer.write(createTextImage(frame, txt, 20, cap_height + 10))
count += 1
print("{}[sec]".format(seconds))
except cv2.error as e:
print(e)
writer.release()
cap.release()
print("Done!!! {}[sec]".format(round(time.time() - start,4)))
補足
- 日本語文字を書き込みにはopenCVではなく、PILを使っているのですがデータを渡すときに一時的に画像ファイルを保存しています。そのせいか動画生成に10分以上かかりました

何かいい方法はないでしょうか
例)
tmp_path = "src_temp.png"
# openCVで使っていた画像データを出力
cv2.imwrite(tmp_path, src)
# PILでデータを読み込み
img = Image.open(tmp_path)
-
フォントはIPAフォントを使っています。
https://ipafont.ipa.go.jp/IPAfont/IPAfont00303.zip -
文字認識する前の処理は下記の通りのフローにしました。
- 画像を白黒化
- 大津式にて二値化処理
- オープニング処理(収縮 -> 拡大)にてノイズ除去
- 画像を反転
def process(src):
kernel = np.ones((3,3),np.uint8)
gray = cv2.cvtColor(src, cv2.COLOR_BGR2GRAY)
o_ret, o_dst = cv2.threshold(gray, 0, 255, cv2.THRESH_OTSU)
dst = cv2.morphologyEx(o_dst, cv2.MORPH_OPEN, kernel)
return cv2.bitwise_not(dst)
結果

カンペが少し文字認識を邪魔してしてますが、ある程度読み取れていると思います。
おわりに
次はGoogle Cloud Vision APIを使って文字認識させてみます。
https://cloud.google.com/vision/ からDemoを試したのですがやはり精度が高めです。