目的
Mac環境でpyOCRで画像データをテキスト化した際の備忘録です
準備
PyOCR インストール
$ sudo pip install pyocr
OCRエンジン部である Tesseract をインストール
$ brew install tesseract
$ ls /usr/local/Cellar/tesseract/4.1.0/share/tessdata/
$ wget https://github.com/tesseract-ocr/tessdata/raw/4.00/jpn.traineddata
$ mv jpn.traineddata /usr/local/Cellar/tesseract/4.1.0/share/tessdata/
日本語の縦書きを認識したい場合は、
こちらのGitHubからjpn_vert.traineddataも取得して/usr/local/Cellar/tesseract/4.1.0/share/tessdata/に格納してください。
コード
image2text.pyを参照させて頂きました。
横書きの場合
lang='jpn'とすればよい
sample.py
from PIL import Image
import sys
sys.path.append('/path/to/dir')
import pyocr
import pyocr.builders
tools = pyocr.get_available_tools()
if len(tools) == 0:
print("No OCR tool found")
sys.exit(1)
tool = tools[0]
print("Will use tool '%s'" % (tool.get_name()))
langs = tool.get_available_languages()
print("Available languages: %s" % ", ".join(langs))
txt = tool.image_to_string(
Image.open('test.png'),
lang='jpn',
builder=pyocr.builders.TextBuilder()
)
print(txt)
◾️テスト

$ python sample.py
新型iPhone発表。iPhone⑪/Pro⑦ProMaxの③モデル、上
位機はトリプルカメラ搭載
米国時間の⑨月①0日Appleはカリフォルニア州クパ
チーノのスティーブ・ジョブズ・シアターにてスペ
シャルイベントを開催。その場で、新型iPhoneを発
表しました。
(略)
上手くテキスト化できていそうです。
縦書きの場合
lang='jpn_vert'とすればよい
sample2.py
from PIL import Image
import sys
sys.path.append('/path/to/dir')
import pyocr
import pyocr.builders
tools = pyocr.get_available_tools()
if len(tools) == 0:
print("No OCR tool found")
sys.exit(1)
tool = tools[0]
print("Will use tool '%s'" % (tool.get_name()))
langs = tool.get_available_languages()
print("Available languages: %s" % ", ".join(langs))
txt = tool.image_to_string(
Image.open('test2.png'),
lang='jpn_vert',
builder=pyocr.builders.TextBuilder()
)
print(txt)
◾️テスト

$ python sample.py
※一部抜粋
(〇本の置き場所を減らせる
本好きの人なら、本の置き場所には困ることが多いものです。本1何あたりの体積や重さはそれほど
ではなくても、何十姜、何百器とまとまった数になると、かなりスペースをとります。日本の住宅事情
では、本の値段よりも、保管にかかるコストのほうが高くなってしまうことも多いでしょう
上手くテキスト化できていそうです。
Google Cloud Vision API 光学式文字認識(OCR)との性能の違いが気になるところです。
(追記)縦書き+複数の画像ファイルの場合
下記コードを使えばよい。
入力:./image/*.png に格納しているPNG形式の画像データ
出力:out.txt
sample.py
from PIL import Image
import sys
sys.path.append('/path/to/dir')
import pyocr
import pyocr.builders
import os
tools = pyocr.get_available_tools()
if len(tools) == 0:
print("No OCR tool found")
sys.exit(1)
tool = tools[0]
print("Will use tool '%s'" % (tool.get_name()))
langs = tool.get_available_languages()
print("Available languages: %s" % ", ".join(langs))
# use all files on ./image/ directory.
for root, dirs, files in os.walk("./image/."):
for filename in files:
print(filename)
input_img = Image.open('./image/' + filename)
txt = tool.image_to_string(
input_img,
lang='jpn_vert',
builder=pyocr.builders.TextBuilder()
)
with open('./out.txt', mode='a') as f:
f.write(txt)
例えば数ページに渡る文章は上記コードでテキスト化可能
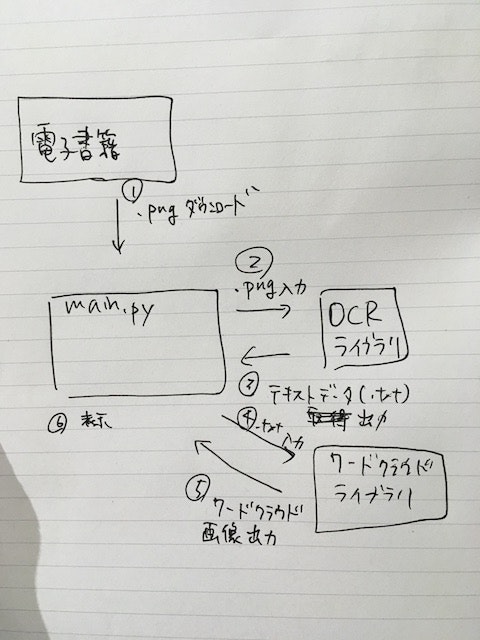
(追記)ワードクラウドと組み合わせると以下のようなデータを出力できます
画像データ(.png)から取得したテキストデータをワードクラウドへ入力

ブロック図、処理フローとしては以下のようになる。
参考
Pythonでpng画像をテキストに変換する方法【初心者向け】
PythonとTesseract OCRで文字認識
【PyOCR】画像から日本語の文字データを抽出する
【Python】画像から文字起こししてテキストに変換する方法(tesseract-OCR、pyocr)
Google Cloud Vision API 光学式文字認識(OCR)
Pythonでフォルダ内のファイルリストを取得する