ARCのretain/releaseを極力避けるためにARCから離れて別のGCを使う.今回,おもちゃレベルのGCを実装して使ってみた結果,ARCと比して意外とよいデータが出てきたので記事にしてみました.
はじめに
ARCにメモリ管理を丸投げするのはとても楽ですが,時に,その"Automatic"なところが機械的すぎて邪魔になることがあります.ARCでは(コンパイラは)参照型(クラス, クロージャ, 再帰的enum)のオブジェクトを参照するとその前後に問答無用で機械的にretain,releaseを付け足しますが,参照型だからといって常に参照カウントの上げ下げが必要になるわけではありません.例えばリンクリスト.参照カウントで保護する必要があるは先頭ノードだけで,後ろの方は参照カウントをいじる必要はないと言えます.なぜなら,先頭が生きているならば,(明示的に削除しない限り)後ろは必ず生きているというのがこの手のデータ構造だから.
retain/releaseのオーバヘッド
リンクリストのような構造をARC管理下に置くと,任意のノードアクセスに対してretain/releaseが付いてくるため,ノード数をカウントするだけでもとてつもないオーバーヘッドになります.例えば次のコード.
enum List<T> { // (注1)
case Nil
indirect case Cons(T, List3<T>)
func length() -> Int {
var (len, ys) = (0, self)
while case let .Cons(_, xs) = ys { // (注2)
(len, ys) = (len+1, xs)
}
return len
}
}
(注1): 再帰的enumは内部では参照型である.classで実装してもほとんど同じ.
(注2): Xcode7 beta6のSwiftコンパイラは再帰的enumの末尾再帰最適化をやってくれないようなのでwhileループを使う.
このlengthメソッドを派手にループで回してプロファイルしてみると,
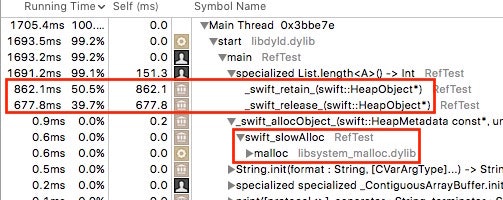
なんと実行時間の9割をretain/releaseが占めてしまっています.retain/releaseがなくなれば10倍は速くなるわけですね.また,こんな小さなオブジェクトでも領域取得にはmallocを使っています.swift_slowAllocという関数名からしてこれは遅いのでしょう.これも可能なら高速化したほうがいいですね.
(別にretain/releaseが悪だというわけではなく,重いアトミック命令を含むretain/release処理は可能な限り避けるべきだということです.どちらかという融通のきかないコンパイラが悪?)
ガベージコレクション
retain/releaseを可能な限り避けるには参照型を使わない,つまりARCの管理下から離れて自前でメモリ管理をしながら値型であるストラクトを使う必要があります.SwiftではUnsafeMutablePointerタイプを使うことで,C言語でのmalloc/freeに相当するようなメモリ管理が可能です.かといって,malloc/freeをいちいちやるのも面倒くさいですし,第一(僕のようなおっちょこちょいは)すぐにバグを入れてしまいます.となると,残る手段はガベージコレクションを実装して使うということになるでしょう(まあ,ARCもガベージコレクションの一種なのですが).
(なんちゃって)保守的GC
いきなりフルスペックのスレッドセーフなGCの実装はあまりにも大変なので,おもちゃレベルから出発します.そのスペックは:
- 保守的GCだがスキャン対象はレジスタとスタックと管理下のヒープのみ.つまり局所変数しか使えない.
- 古典的なビットマップマーキングかつ遅延スイープ方式
- とりあえずGCで扱えるオブジェクトは整数と次へのポインタを要素とするリンクリストノード(コンスセル)のみ
- シングルスレッド専用
- X86_64専用
このレベルならピュアSwiftで実装できます.載せるにはちょっと長いソースなのでつづきはリンク先で!
ARC vs. GC
シングルスレッド専用(重いアトミック命令ゼロ)のGCとマルチスレッド対応のARCを比較するのはちょっとずるい気はしますが性能比較してしまいましょう.
ちなみに,上記の再帰的enumなリストに対応するGC版リストの実装はこんな感じです.ストラクトです.
struct List {
static let NIL = List()
var cell: Cell.Pointer
var isEmpty: Bool {
return cell == nil
}
var head: Int? {
if cell == nil {
return nil
} else {
return cell.memory.value
}
}
var tail: List {
if cell == nil {
fatalError("getting tail of [].")
}
return List(cell: cell.memory.nextPtr)
}
//...
func length() -> Int {
var (len, xs) = (0, self)
while !xs.isEmpty {
(len, xs) = (len+1, xs.tail)
}
return len
}
func filter(pred: Int -> Bool) -> List {
if let v = head {
if pred(v) {
return cons(v, tail.filter(pred))
}
return tail.filter(pred)
}
return List.NIL
}
}
このほか,map, appendがあります.コードはfilterと似たようなものなのでここでは割愛(全ソース).
これと再帰的enumなリストのそれぞれで
let list = makeList(0..<10_000) // 一万要素のリスト
for _ in 0..<10_000 {
list.length()
//list.map { $0 }
//list.filter { $0 == $0 }
//list.append(IntList.NIL)
}
というループの実行時間を計測.GCのヒープサイズは1Mバイト(要素数にして2^16個分)に設定してあるので,ループ実行中に頻繁にGCが走る.
実行時間
実行環境: Xcode7 beta6, OSX 10.11 public beta6, Mac mini core i7, 2GHz.
実行時間は(たった)5回の平均で単位は秒.
コンパイラ最適化オプション:
- ARC版Listは '-O -whole-module-optimization'
- GC版は '-O'のみ (-whole-module-optimizationを付けると遅くなる)
| 関数 | ARC版List | GC版List | ARC/GC |
|---|---|---|---|
| length | 1.933 | 0.148 | 13.0 倍 |
| append | 20.84 | 2.529 | 8.2 倍 |
| filter | 21.03 | 3.752 | 5.6 倍 |
| map | 20.79 | 3.682 | 5.6 倍 |
| reverse | 19.05 | 1.437 | 13.3 倍 |
ちょっと考察
思いのほか良い値が出ていると思います.
GC版lengthはretain/releaseがない(というかARCが一切絡まない)ので速いはずとは思っていたが,'はじめに'で述べた10倍を超えて13倍まで行っている.おそらくenum版Listよりも綺麗にデータがCPUキャッシュに乗っかっているのでしょう(マイクロベンチなのでGCヒープ領域を配列のように連続アクセスする傾向が強いためCPUのデータ転送予測が当たりやすいのもあるかもしれない).
append, filter, mapともにやっていることはただのコピー作業であるが,GC版の方はappendに対してfilter,mapがちょっと遅い.この理由はクロージャの実行オーバーヘッド,及び,スタックフレームのサイズの違い(この場合,appendに対してフレームサイズはほぼ2倍)のためと思われる.クロージャも参照型のためretain/releaseの影響を受ける.ただしこの場合のクロージャはスタックにある(参照カウントなし)のでretain/releaseは呼ばれるが,やることがなくてすぐにリターンする.また,フレームサイズが大きい=GC時にスキャンするスタック領域が大きい,なのでGCのオーバヘッドも大きくなってしまう.
それでも参照型Listよりも数倍速いのは,retain/releaseが少ないのとmallocよりも速いGCのメモリ割り付けのおかげでしょう.
その現象が顕著に現れるのがreverseである.再帰ではなくループで実装したreverseはスタックを消費しないため,GC版ListではGCの負荷が極端に少なく,retain/releaseとmallocのオーバヘッドが大きい参照型Listとの差がもろに出ているのが分かる.
一方,参照型Listのappend,filter,mapの実行時間はほとんど同じでクロージャのオーバヘッドが見えない.理由はよく分からないが,オブジェクトへのアクセス時のretain/releaseの重さに隠れてしまったのかもしれない?
おわりに
遊び半分の実験であったが意外と良い結果なので,より完全なGCの実装をまじめに考えたくなりました.少なくとも局所変数だけでなく,大域変数とクラス等のプロパティで使えるぐらいには(これは半自動GCとしてなら,少しの改良で可能か?).GCをスレッドセーフにしたり任意のサイズのオブジェクトに対応したりと結構なオーバヘッドが乗っかってくるだろうから,実りが少なく終わりそうな気がしなくもないのですけど...
一番望ましいのは,別にARCで構わないのでAppleがSwiftコンパイラのARC方面の最適化(現状,無駄なことをやっているいように見えるところがある),またはもっと融通のきく処理系にしてくれることかなと思います.今のままでは,ユーザ定義型を使った場合に性能を追求するのは厳しいと思います.