遅くなってしまいましたが、re:inventで学んだ内容について少しずつまとめていこうと思います。
今回は私が興味のあったDevops agentについてです。
私の実際に触ったときの話や現地で参加した勉強会での内容なども含め記事にしていきたいと思います。
Devops Agentの概要
Devops Agentは簡単にまとめると以下の4点ができる認識です。
・検知したアラームに対しての問題を自動的に調査、解決策の提示
・過去のCloudTrailログ等を遡り、原因を特定
・予防策の提示
・既存の監視用の製品との統合(DynatraceまたはGrafana/Prometheusを接続)
Devops Agentを利用できるようになるまで
まずDevops Agentで検索すると以下のようなページが出てきます。
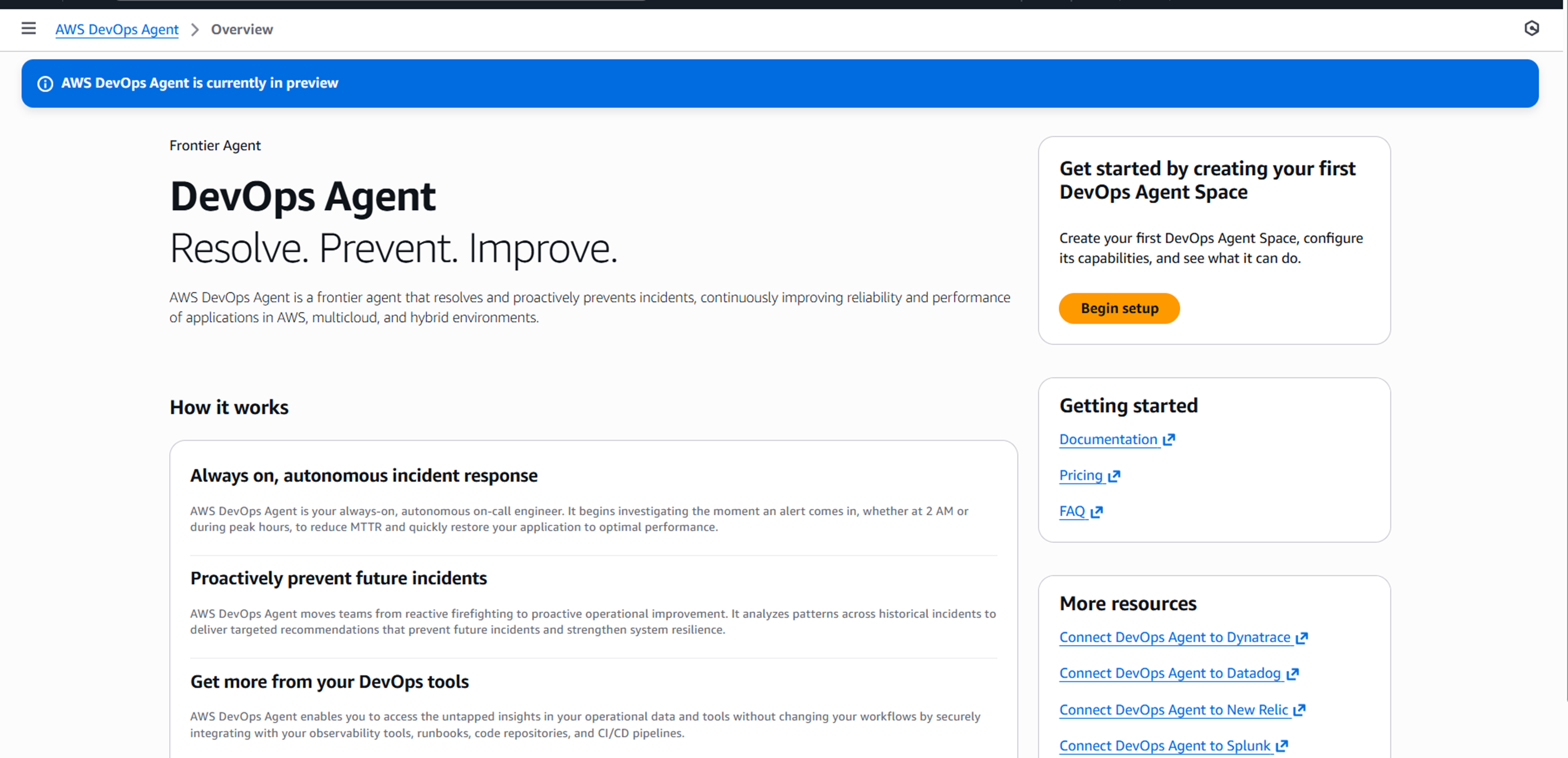
ここからエージェントスペースを作成します。
エージェントスペースではエージェントスペースがAWSリソースにアクセスするために利用するロールを設定します。
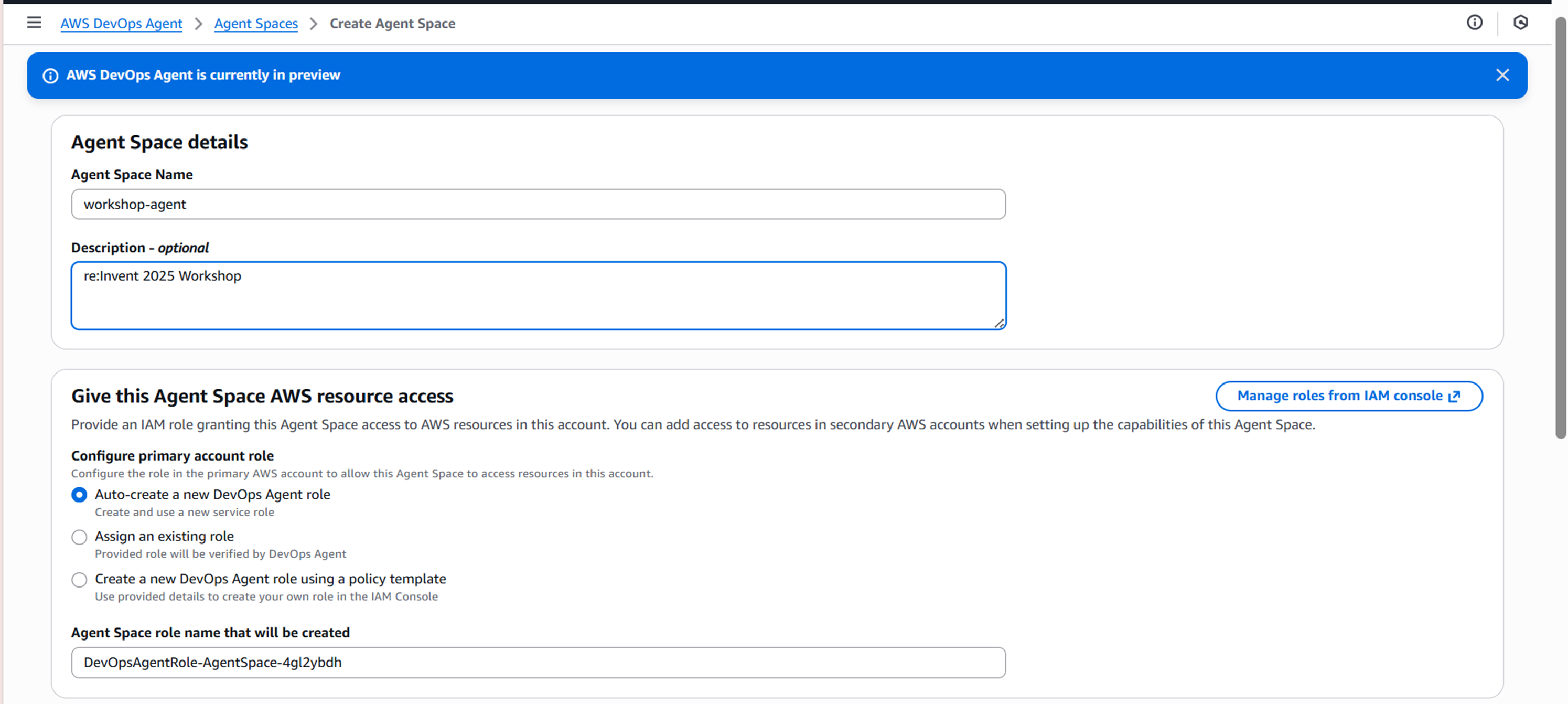
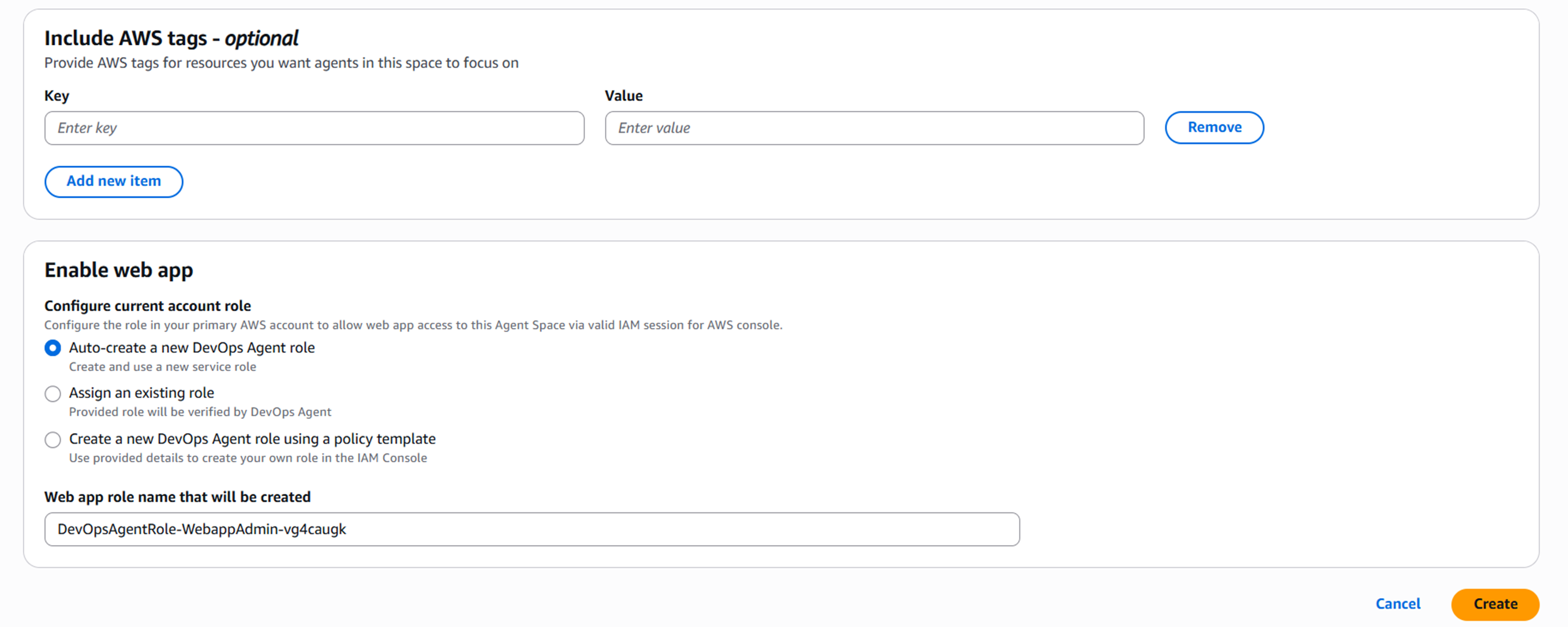
これらを設定するとエージェントスペースができ、Operator accessを開くことでDevops Agent専用のウェブアプリ(コンソール的なもの)に遷移します。
ワークショップでの実際の挙動
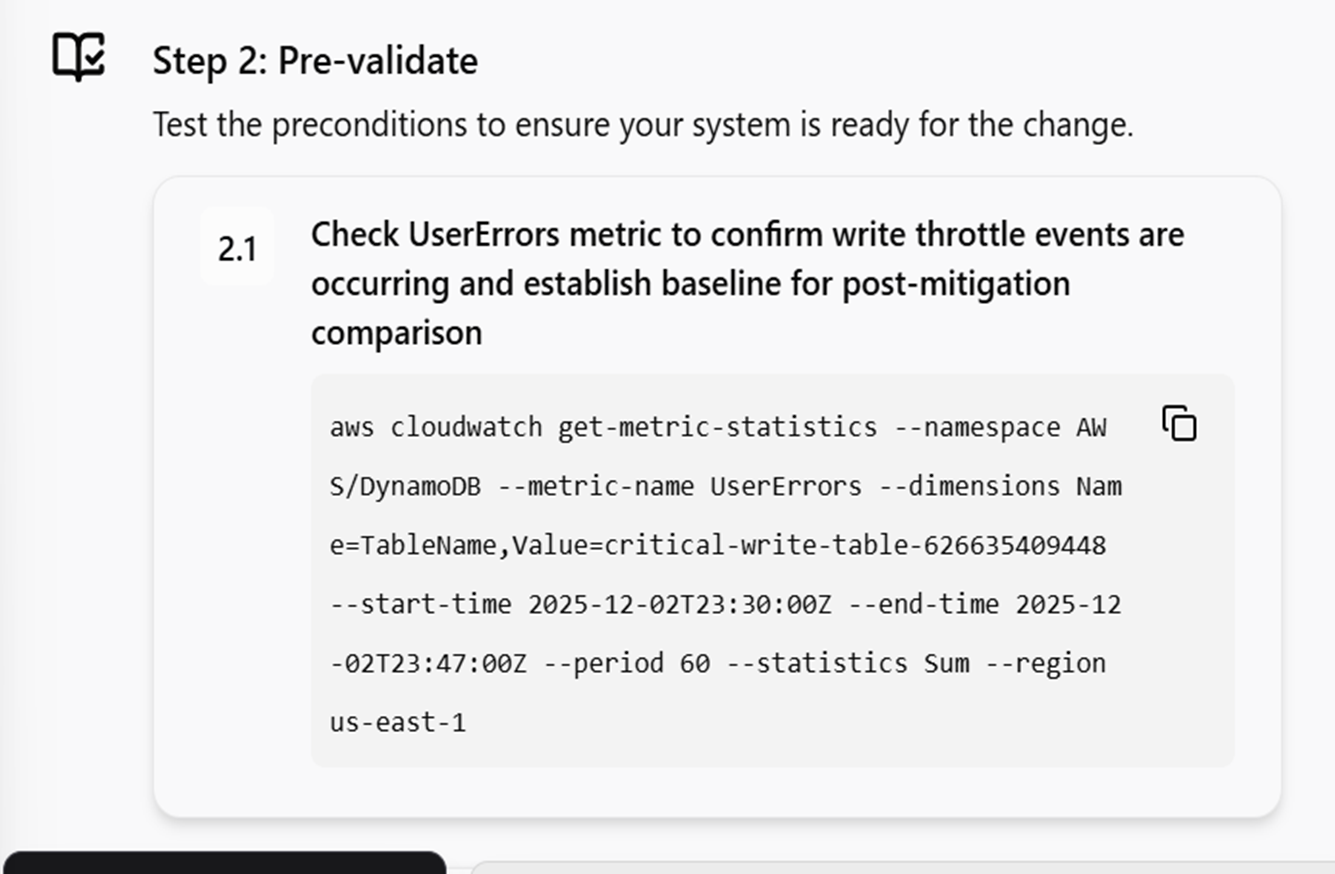
今回のワークショップでは、DynamoDBテーブルにレコードを更新するLambdaがあり、そのテーブルの最大テーブルスループットセクションの入力最大書き込みを250から2に変更してアラームを発砲させDevops Agentの挙動を見てみるというものになります。
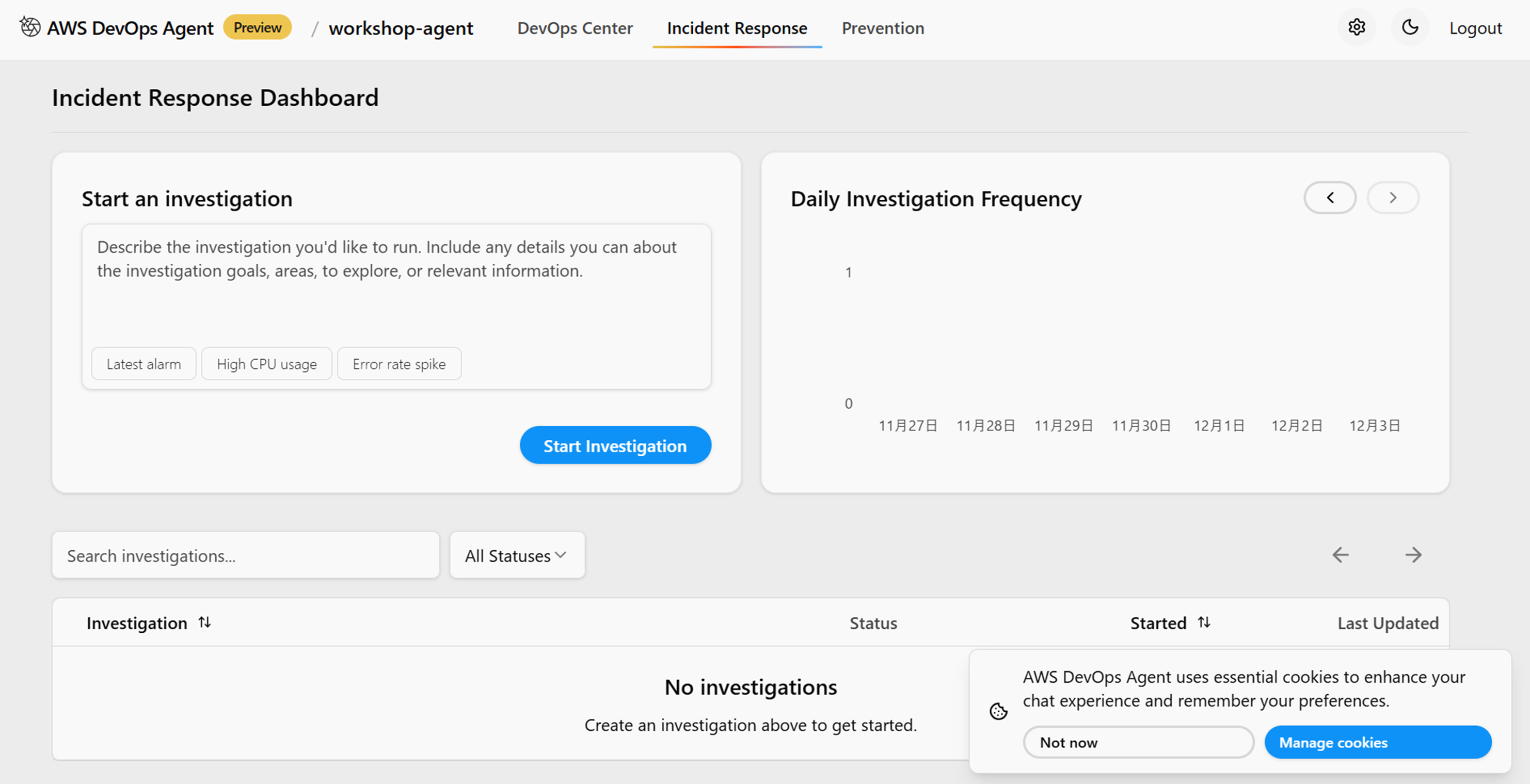
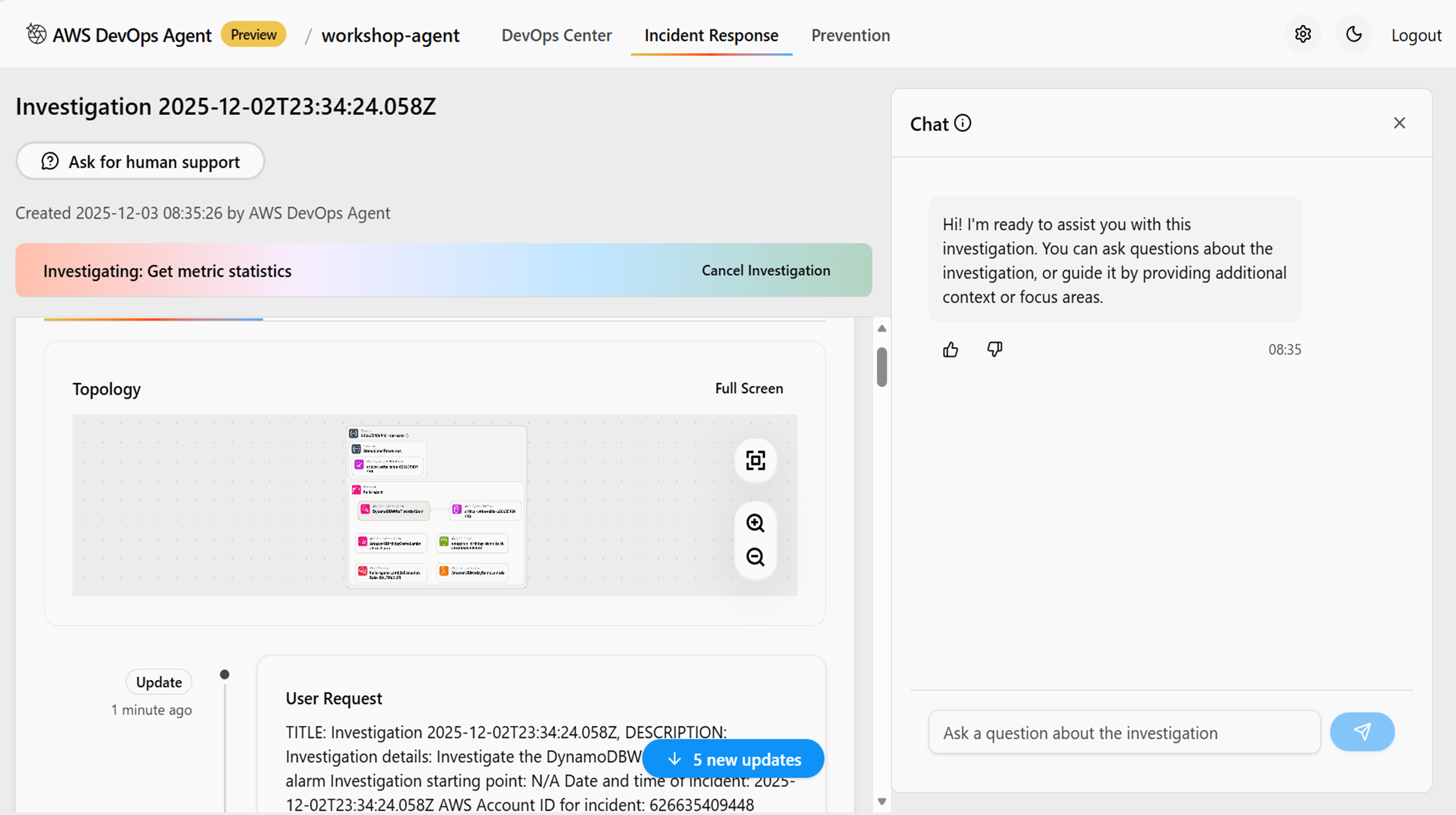
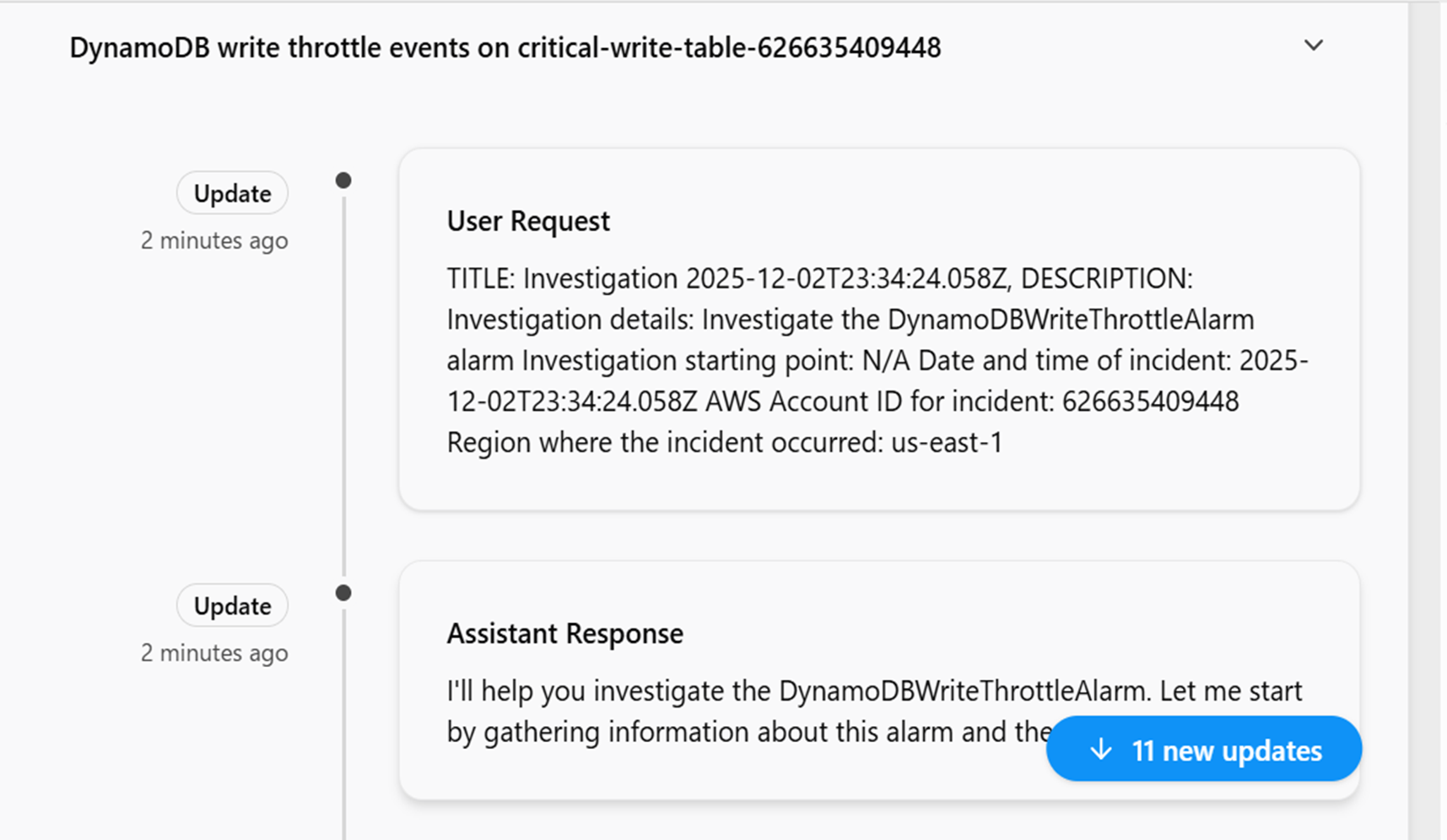
手動で調査を開始するために「Incident Response」ページに移動して「Start an investigation」に調査したいインシデント内容を記載してインシデント調査を開始します。
調査をすると、まず原因を特定してくれます。
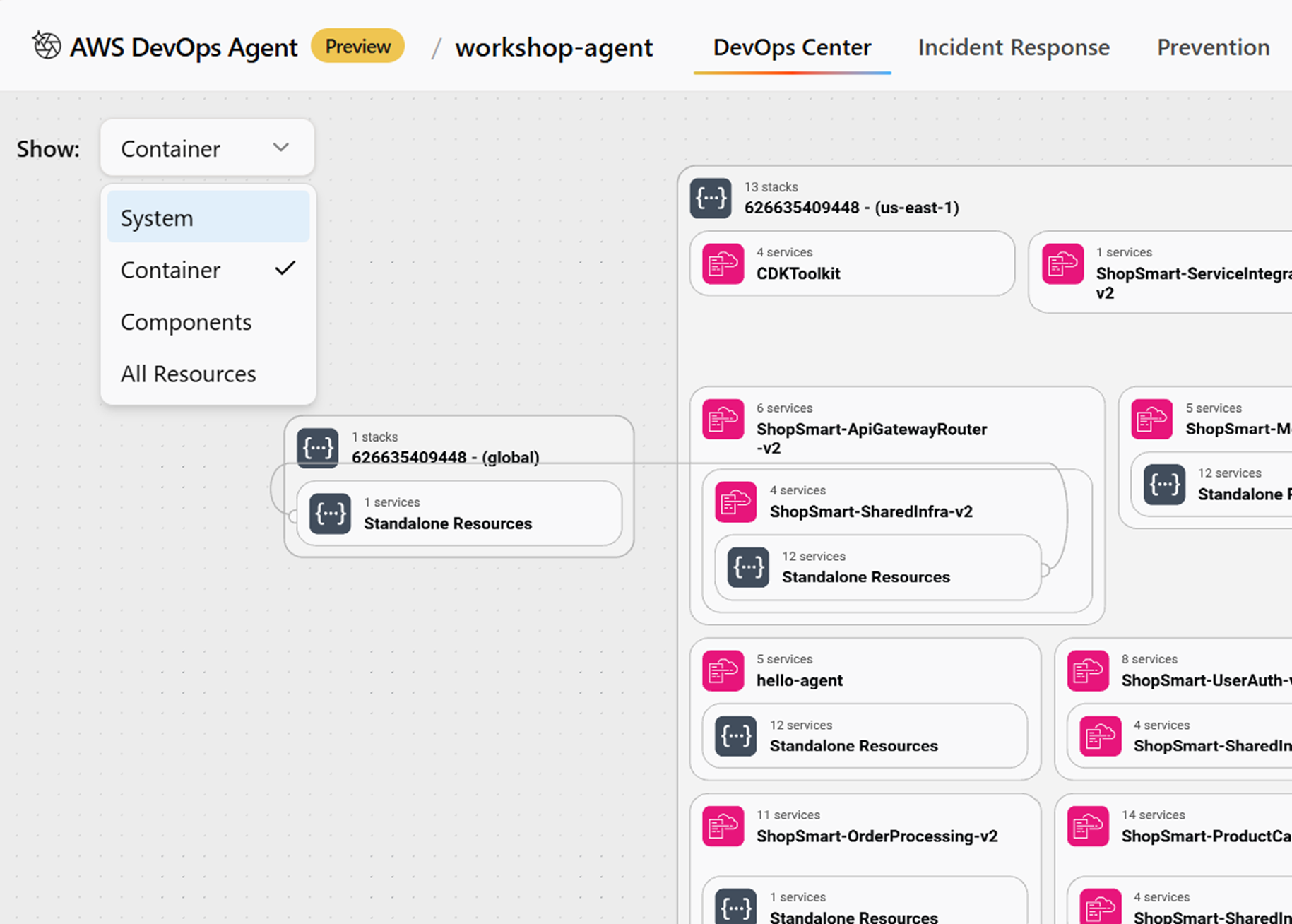
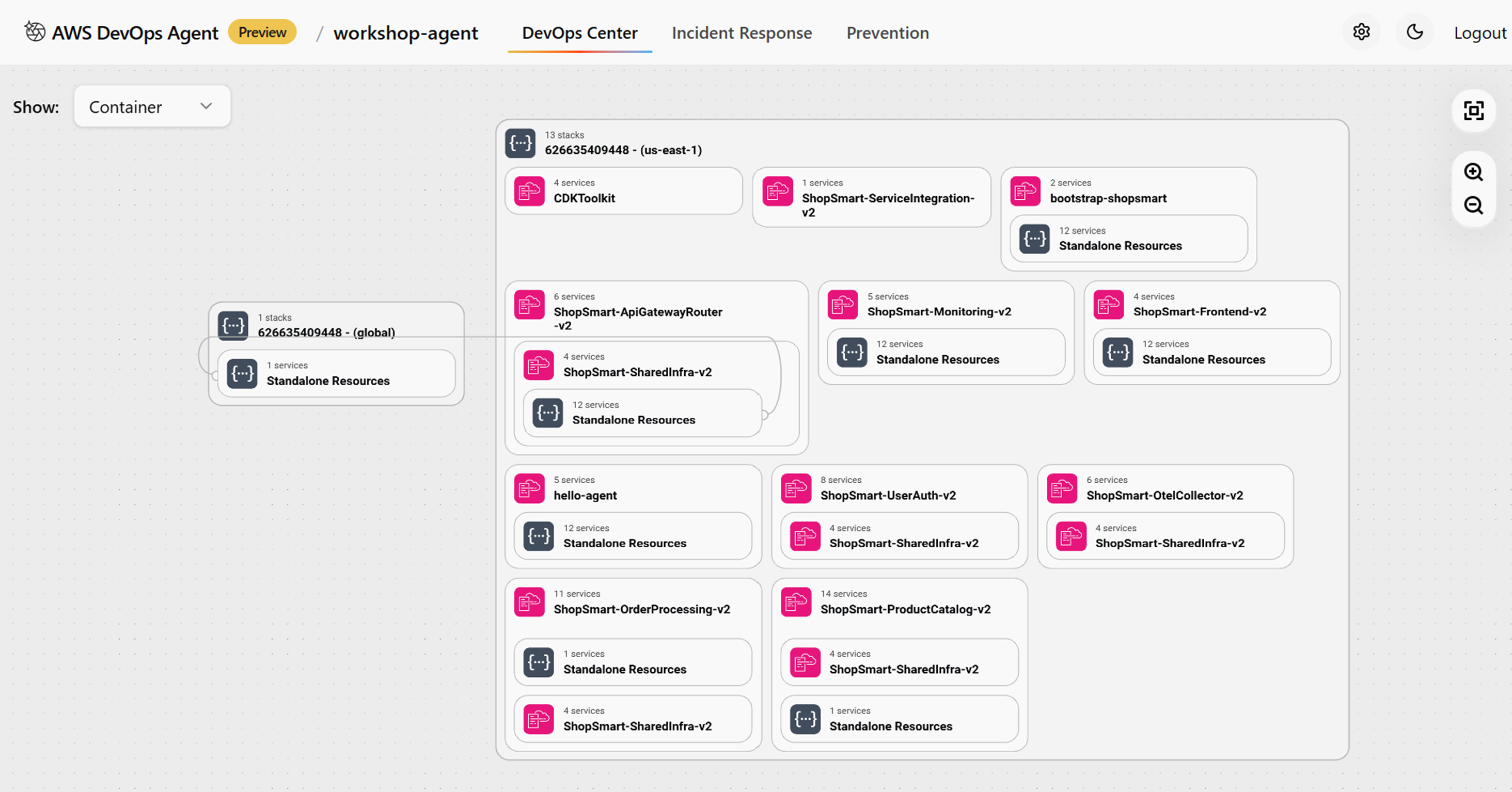
Devops AgentはAWSリソースの関係性を理解し「トポロジー」としてそれぞれのリソースの関係性を視覚的に表示しどの部分がアラームになっているか提示してくれます。
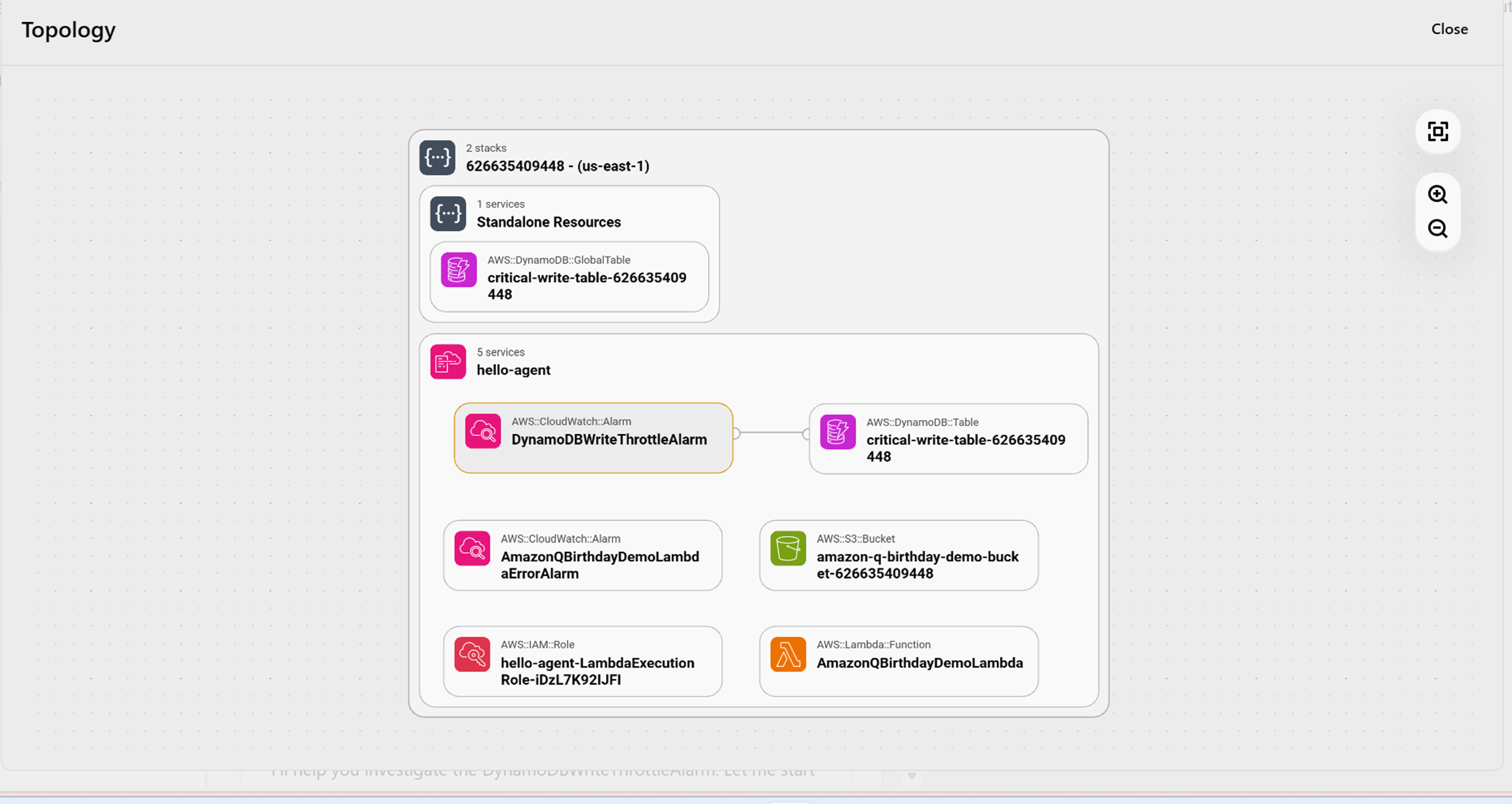
このトポロジーですが「System,Container,Components,All Resources」と4パターンの表示範囲があります。
一番広いやつはめちゃくちゃ細かくて見た瞬間うわっ!すご!と声が出ました。
ただ一つ気になるのは、、
本当に私の提供している顧客環境をこんなにきれいに関係性整理できるの?笑
個人的にこのトポロジーを見ていて気になったのがほぼすべてのリソースがCloud Formationで環境構築されていること。
顧客環境は手動でCLIコマンドやマネコンを利用して構築しているものが多いため、実際のところこんな細かく正確な関係図は作成できないのではと思っています。この点は早めに検証したいところ。
※Fin-JAWSの現地recapの中で、ここら辺を質問なさった方が発表されておりそのときはCloudFormationのスタックをみているよとぼそっと言われたとのことでした。
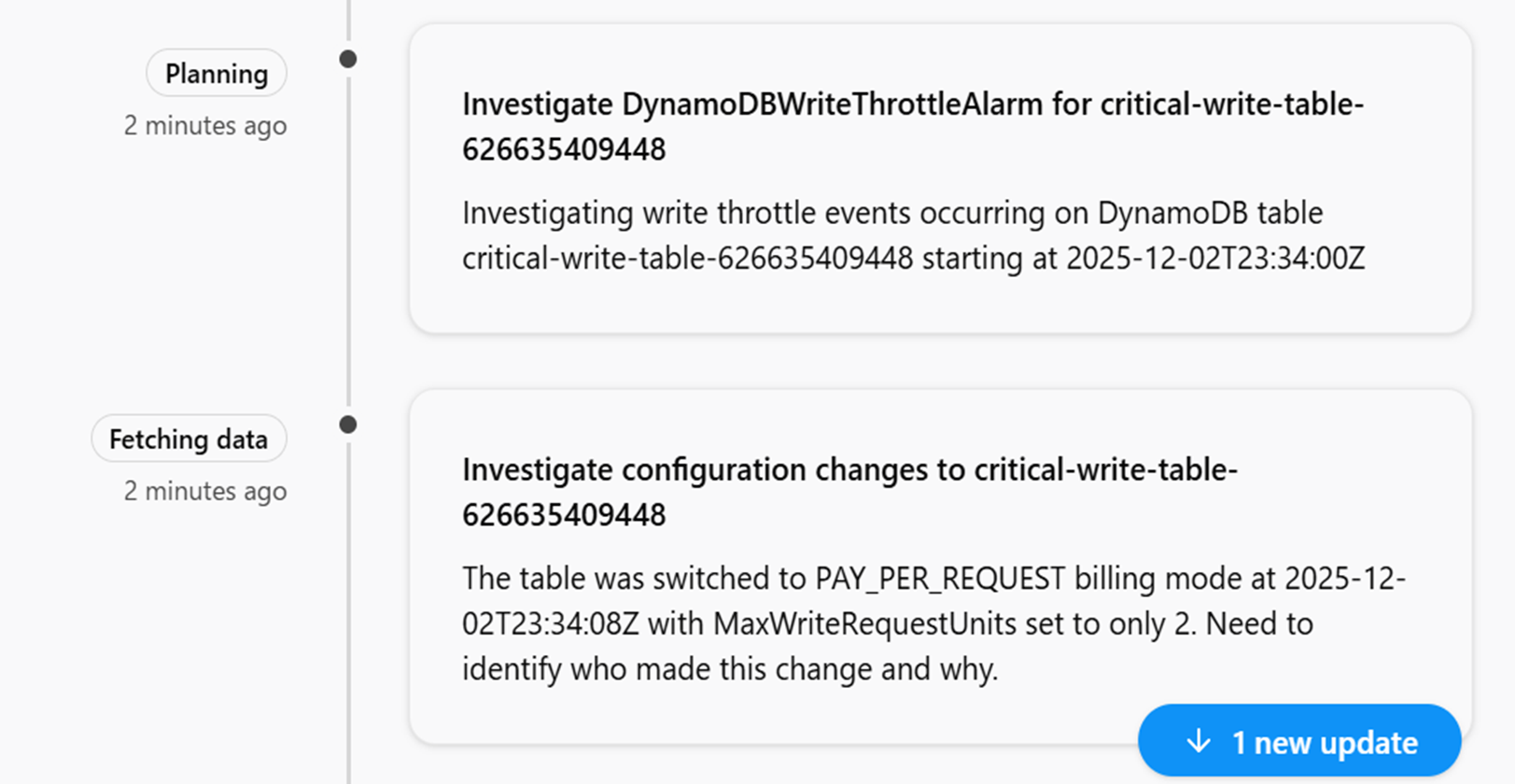
少し話がそれてしまいましたが、調査を開始するとDevops Agentにてアラームの内容の確認しどのような方針で調査するかPlannningを定め、どの作業が原因で起きたのか等を特定してくれます。
CloudTrailログなどから情報引っ張ってきてるようなので、このユーザのこの設定が原因だと思うといった示唆をはっきりと提示されて犯人捜しが簡単にできています。
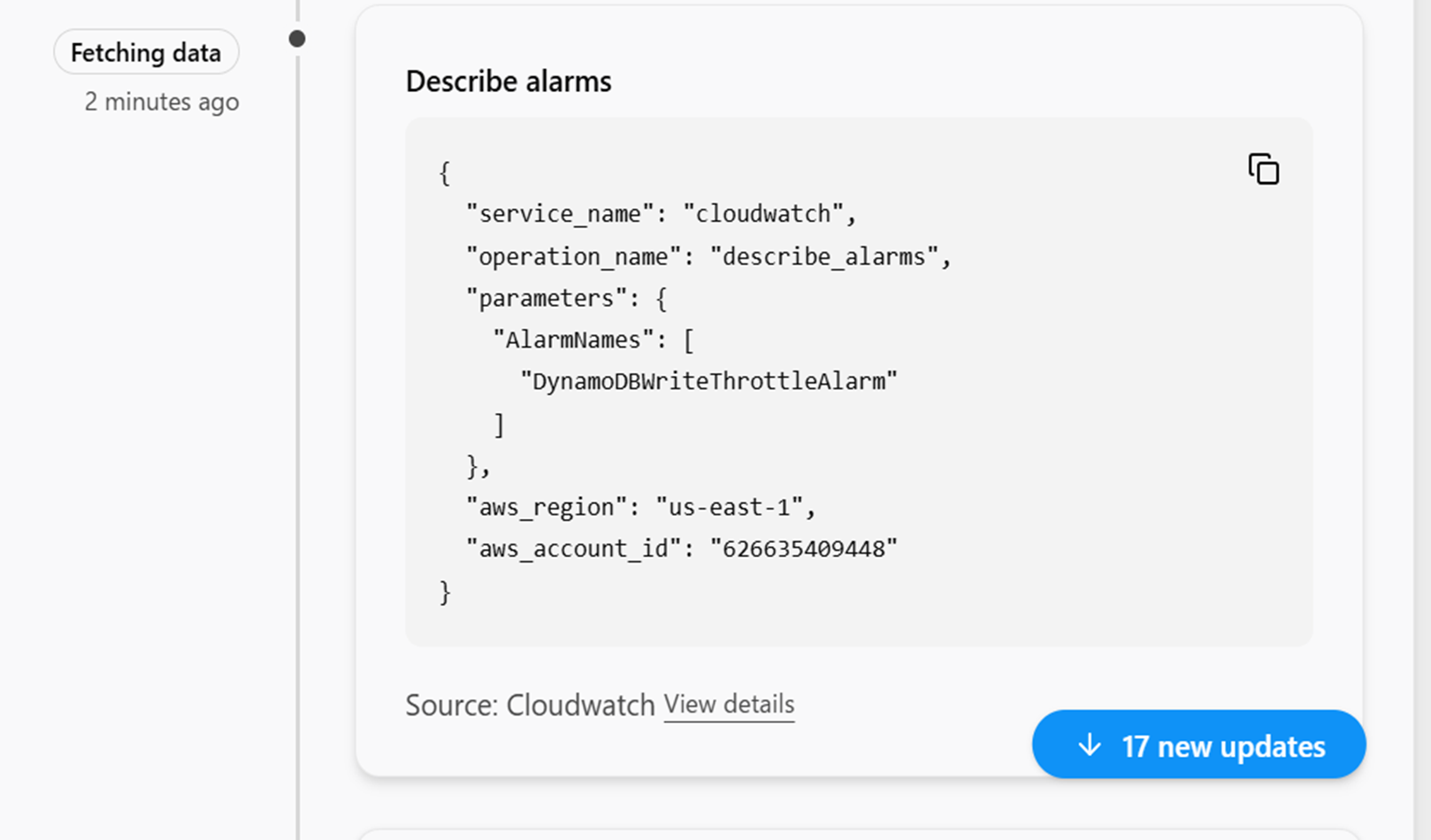

今回のワークショップでは判断できませんでしたが、EC2等でMW製品が起因で発生したインシデントについてもちゃんと原因特定して解決策を提示とかしてもらえるのかなと疑問に思ったので検証していきたいポイントですね。
※ワークショップ後に思ったので、質問することはできませんでしたが、周りの人と話したときはMW関連のログをCloudWatchlogsに吐き出しておけばちゃんと特定してくれるんじゃないかなみたいな話になりました。誰か聞いたよみたいな方いたらコメント教えていただきたいです。。。
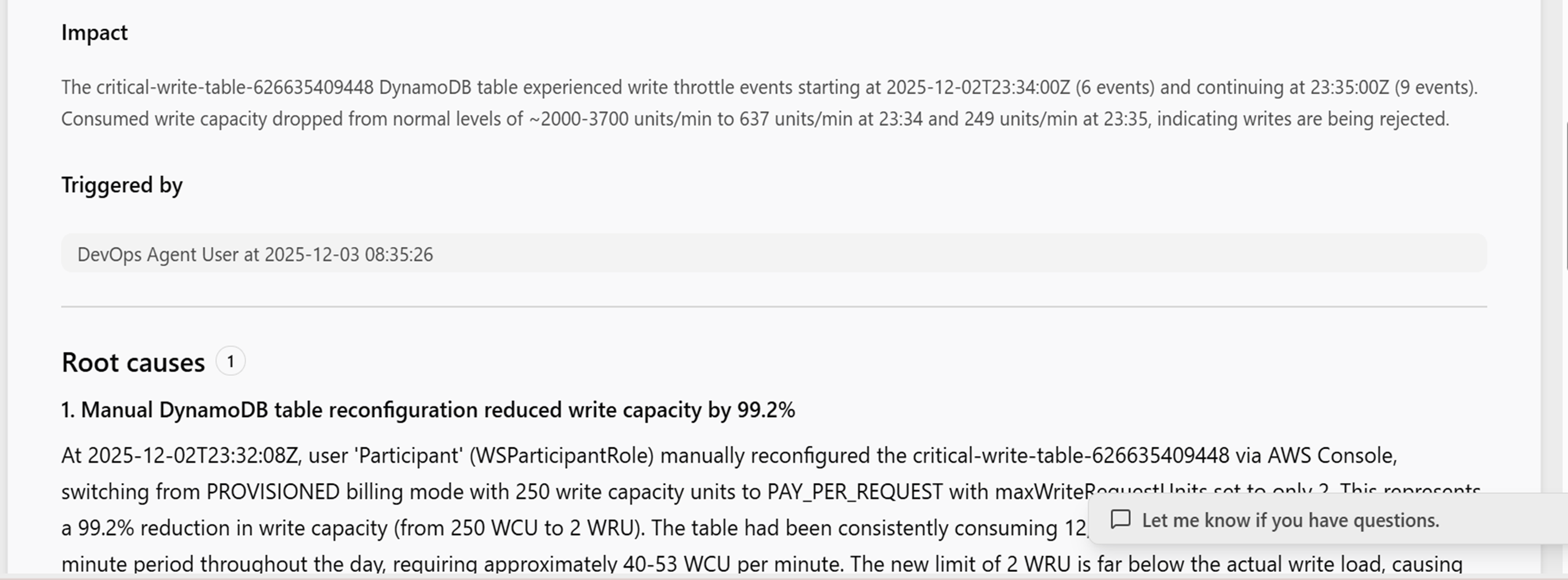
Root causeタブでは上記での調査結果をまとめてくれています。
内容としてはこのインシデントの影響、トリガーとなった作業、根本原因、Key findings(内容を読むと原因と影響の合わさったもののような感じ)を提示してくれます。
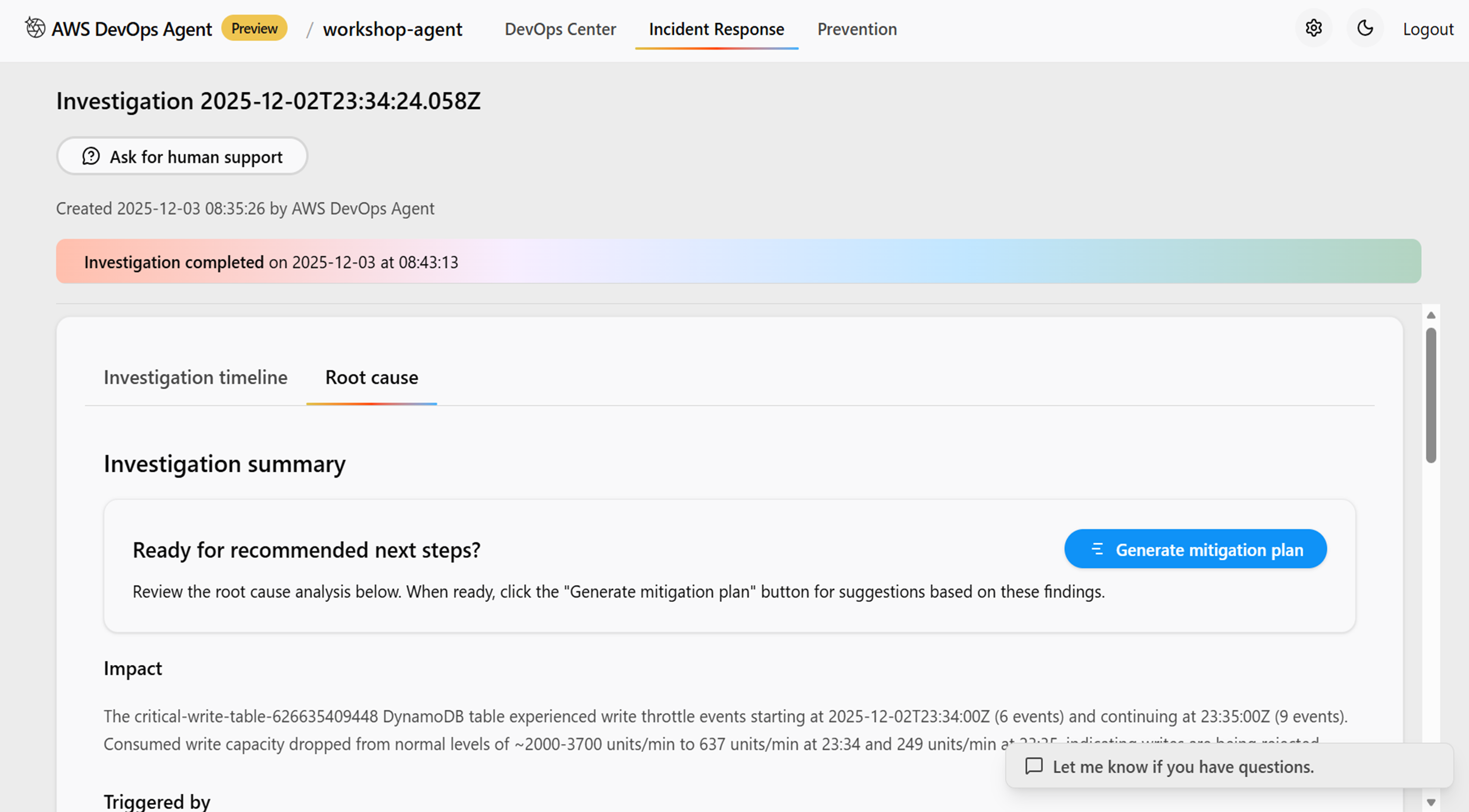



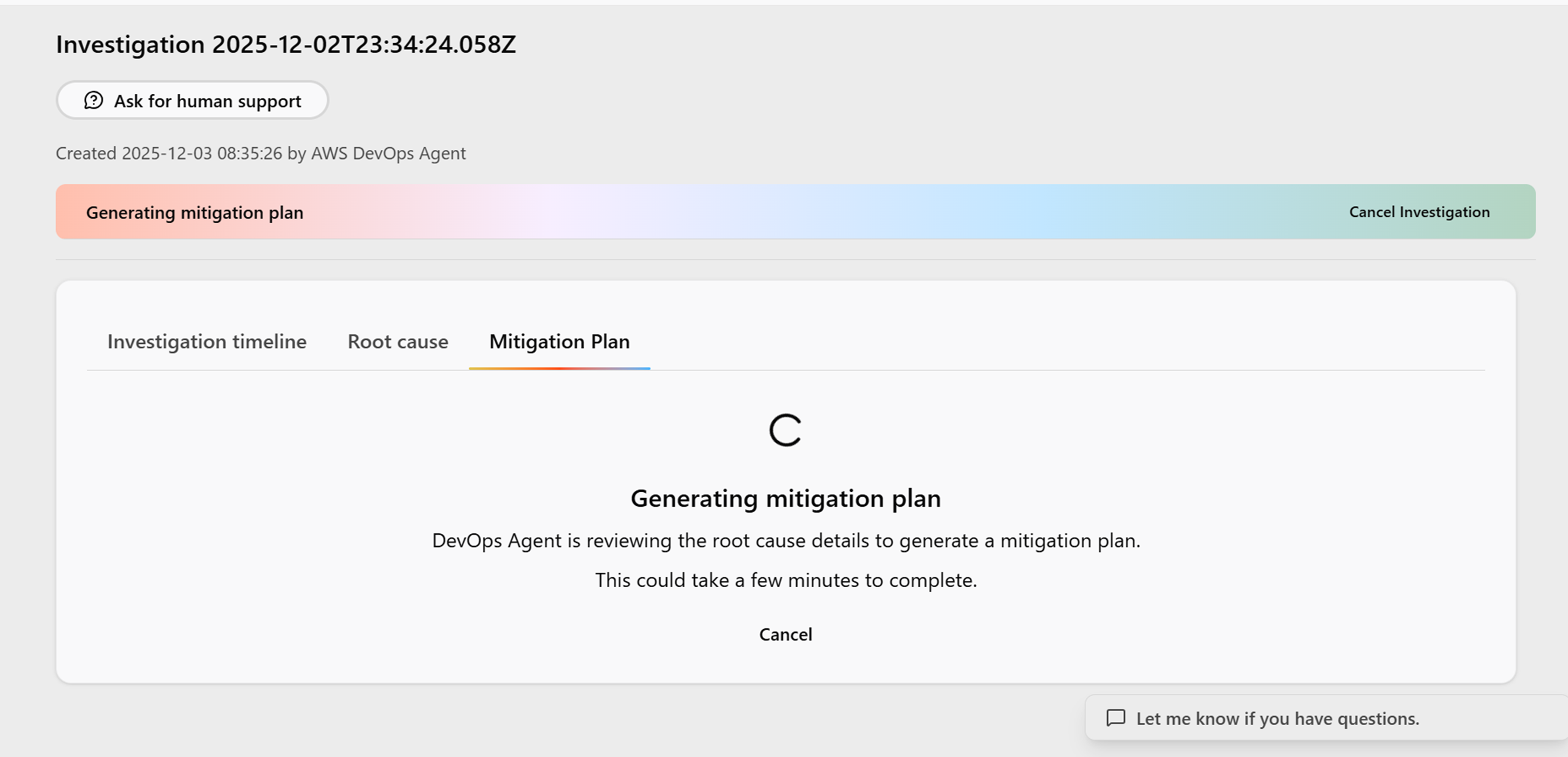
またMigration Planタブに移るとこのインシデントを解決するためのステップを提示してくれます。切り戻しプランも提示してくれるのが個人的には感動ポイントでした。
また勝手にこの解決策を実行されるわけではないため本番環境をAIに勝手に作業されてしまうという心配がないのはいいですね。
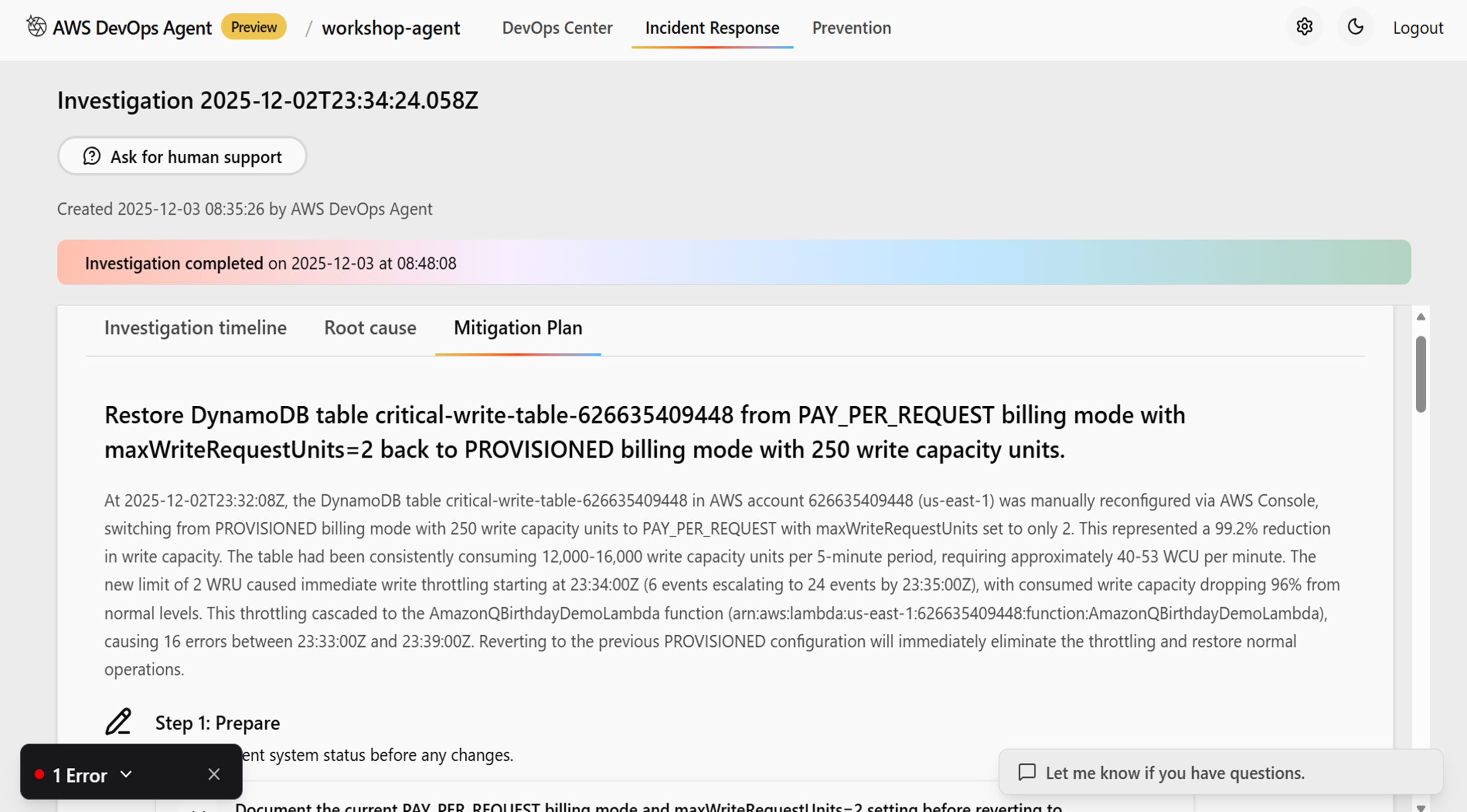
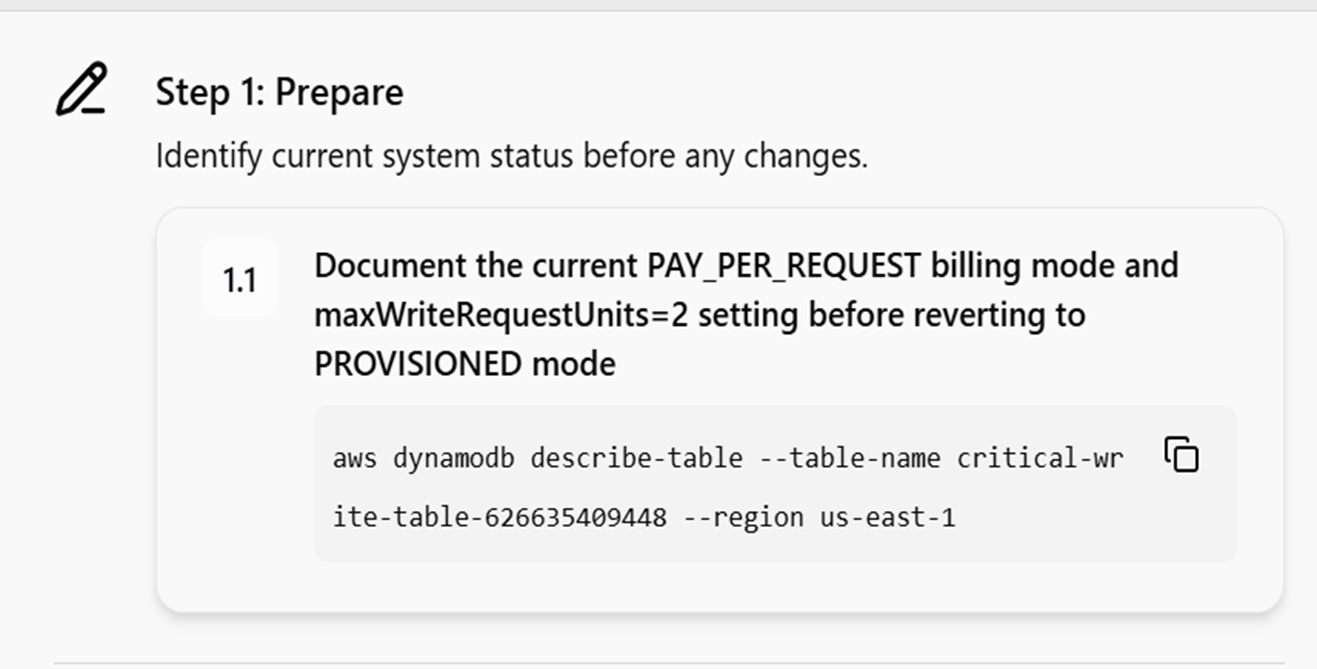
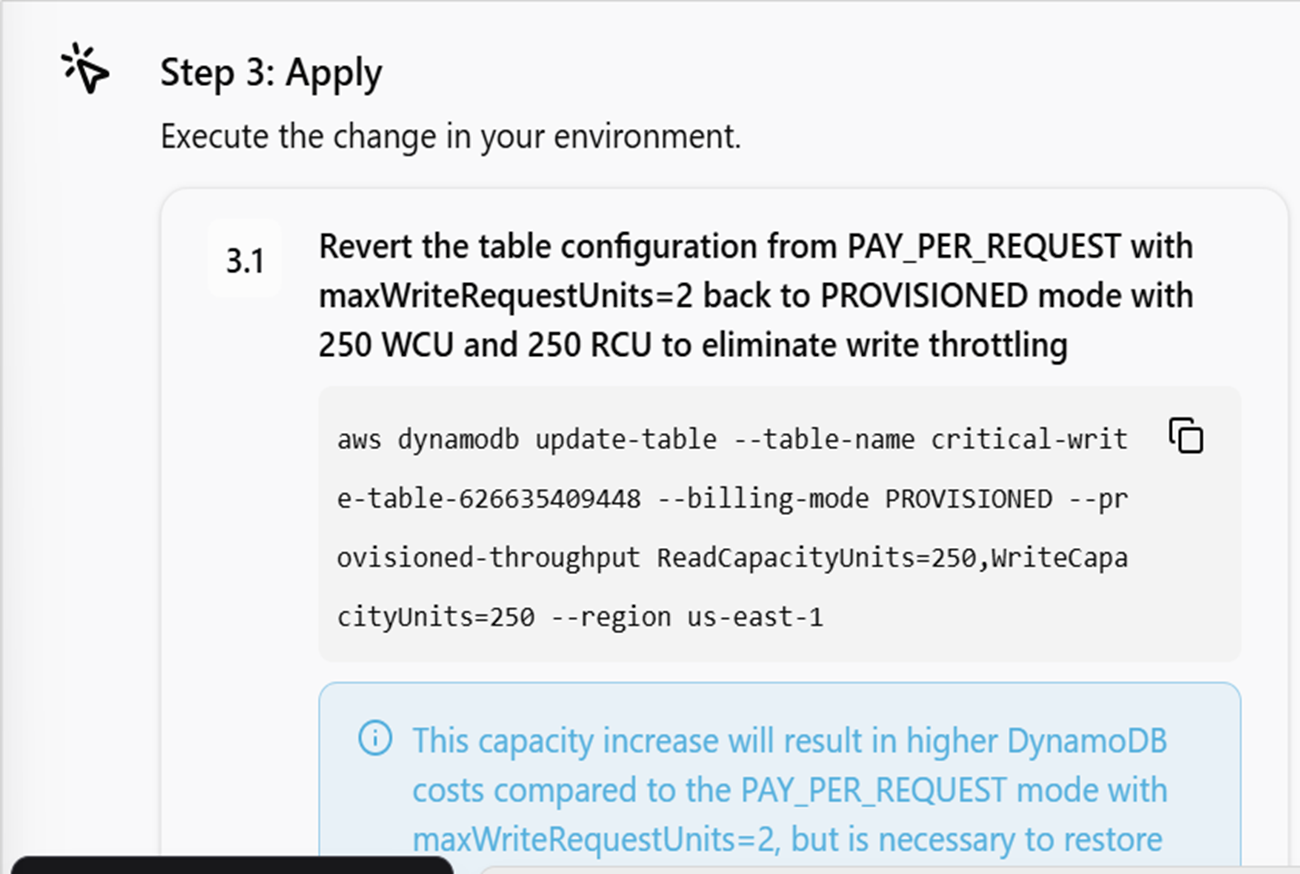

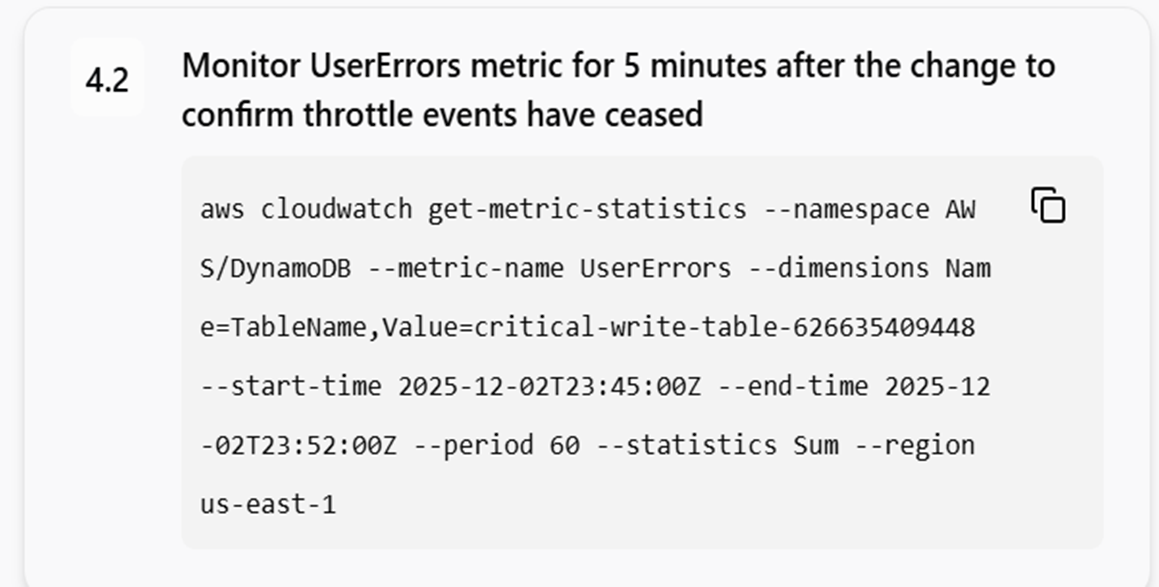
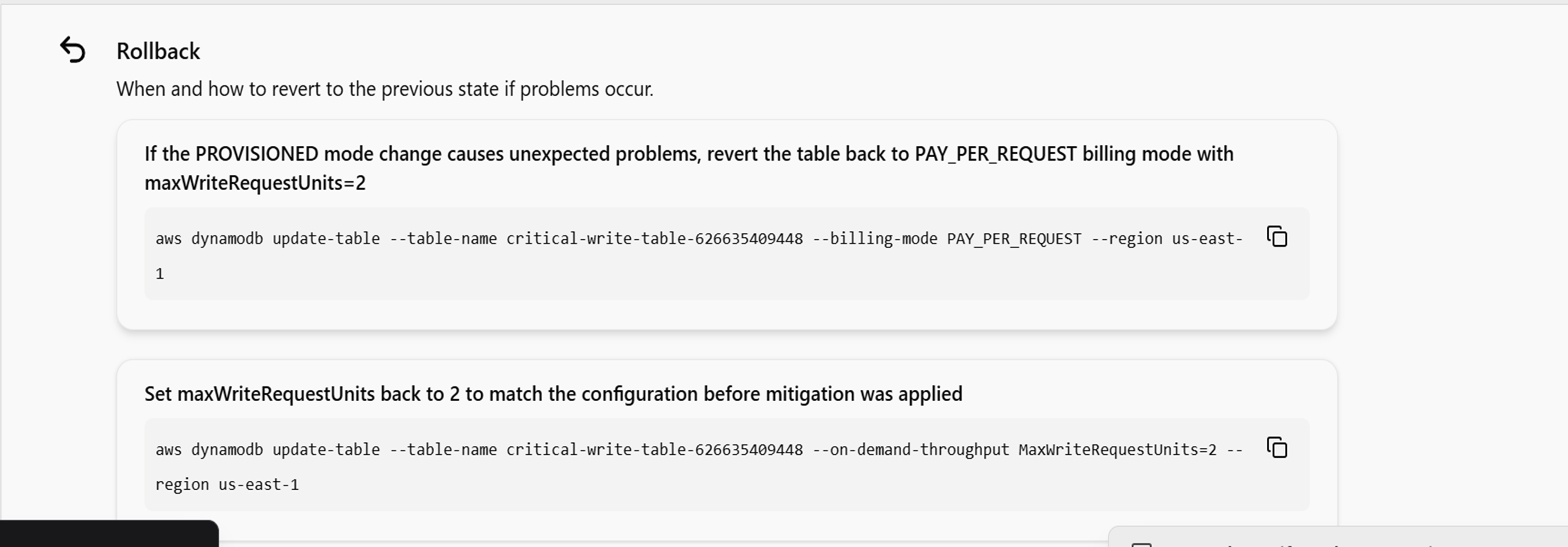
ただこの部分私については、元々の250に戻しましょうという提案がされていたので知らなかったのですが別の参加者ではここが400だったり4000だったりと過剰すぎる解決策を提示してくる場合もあったそうです。
本当に解決策が適切かは鵜呑みにしすぎてはいけないみたいですね
そして最後に予防ですね。
Preventionのタブに移るとRun nowというボタンがありそちらを実行すると予防策を考えてくれます。
ただ今回私に関しては、予防策提示してもらえませんでした。(スクショ取り忘れた泣)
ちなみに他の方も提示されていない方いたようです。
確かに人的な作業ミスって再発防止策難しいですよね。。
ただ業務ではそういうくだらないことの再発防止策を考えなければならず、そういう資料を作っている時間が一番無駄()だと思っているので、個人的には無理矢理でもいいからこの予防策提示してくれるようにならないかな…笑なんて思ってました。
この後Dynatraceとの統合のワークショップもありましたが、Dynatraceを触ったことがない私からするとめっちゃわかりづらく面倒でした笑何度Excuse me!と叫んだことか笑
(途中からスクショとるのもやめてしまったので、気になる方は別の方のブログを見ていただければと思います。)
全体通しての個人的まとめ
私的には結構いいやん!というのが感想です。
完全にインシデント電話から解放されるということはまだまだ先の話だとは思いますが、私のチームは若手ばかりで原因究明にまず何をすればいいのかわからずもたつくということもしばしばなのでDevops Agentが道筋を立ててくれて実際にそれでいいのかは人間の力で確認とかであればかなり使えるのではと思っています!
まだまだ記事の途中で記載したトポロジーやMW製品起因などのエラーにも対応できるのかという点は検証したいなと思いますが早く東京リージョンにGAされないかなとわくわくするサービスでした!