こんにちは。さとみんです。
今回は私がメイン業務として担当しているデータ分析基盤に関して、今までの振り返りもかねて構成やそれぞれのサービスについて整理していきたいと思います。
ただし一般的なものとは異なるかもしれませんが一例として考えていただけると嬉しいです。
構成図
私の案件ではTableauというSalesForceが出しているBIツールを利用することが前提となっていました。Tableauの詳細については以下を参照ください。
https://www.tableau.com/ja-jp
構成図はざっくり以下の通りです。(別アカウントの部分はかなり簡略化しています)

詳細解説
ここからは構成の工夫や各サービスの解説をしていきたいと思います。
解説していく上で、大きく以下の2つに分けようと思います。
- ETL処理
- データ分析
ETL処理
ファイルがS3に配置されてからデータ分析用に加工されるまでの構成での工夫を解説したいと思います。
本ブログでは、具体的なETLジョブの内容については触れません。
①ETL処理においての3パターンのデータ
今回の構成ではS3が3つ配置されているかと思います。
これはETL処理においては連携されたままの生データ、過去途中データ、分析用データの3種類を用意するという考え方を取り入れています。
re:InventのS3テーブルのchalk talkでもこの構成についてBronze、Silver、Goldデータとして解説されていました。(以下の図はchalk talkの内容を元に作成しました)

Bronzeは生データのようなスキーマなどが成立していないデータになります。
圧縮率も低く、データとしてはアーカイブ層まではいかないまでもアクセス頻度低めのストレージクラスでよいかと思います。(長期保管の要件も満たす必要があるためできる限り安く保管できることを意識すべきかと思います。)
Silverは加工中のデータになります。Bronze時よりはソート等を行って必要なカラムだけにしたりすることで洗練されたデータとなっていきます。生データと分析用データの中間ということで特に保管等の要件も必要ではないため、ライフサイクルポリシーは短めに設定しています。
GoldはETL処理が完了し実際にデータ分析で利用するデータになります。
実際にデータ分析で利用するためAthenaの利用料やクエリ精度の観点から、以下の3点を考慮してS3に保管しています。(Athena利用料削減のための施策についてはまた別記事にまとめたいと思うのでここでは割愛)
- gzipによる圧縮
- 年、月、週によるパーティション化
- parquet形式での保管
②Step Functionsを利用したETLフロー管理
GlueにはGlue workflowsというフロー管理のサービスがありますが、これはGlue以外のサービスをフローに組み込むことができません。
現状特にGlueのETL処理以外の要素を組み込む想定はありませんでしたが今後何かあったときの拡張性を考慮して、Step Functionsを利用してのフロー管理としました。
データ分析
次にS3に格納されている分析用データに対しての部分を解説していこうと思います。
本ブログでは、BIツールの解説はしませんのでご了承ください
①S3内のデータにクエリするための準備
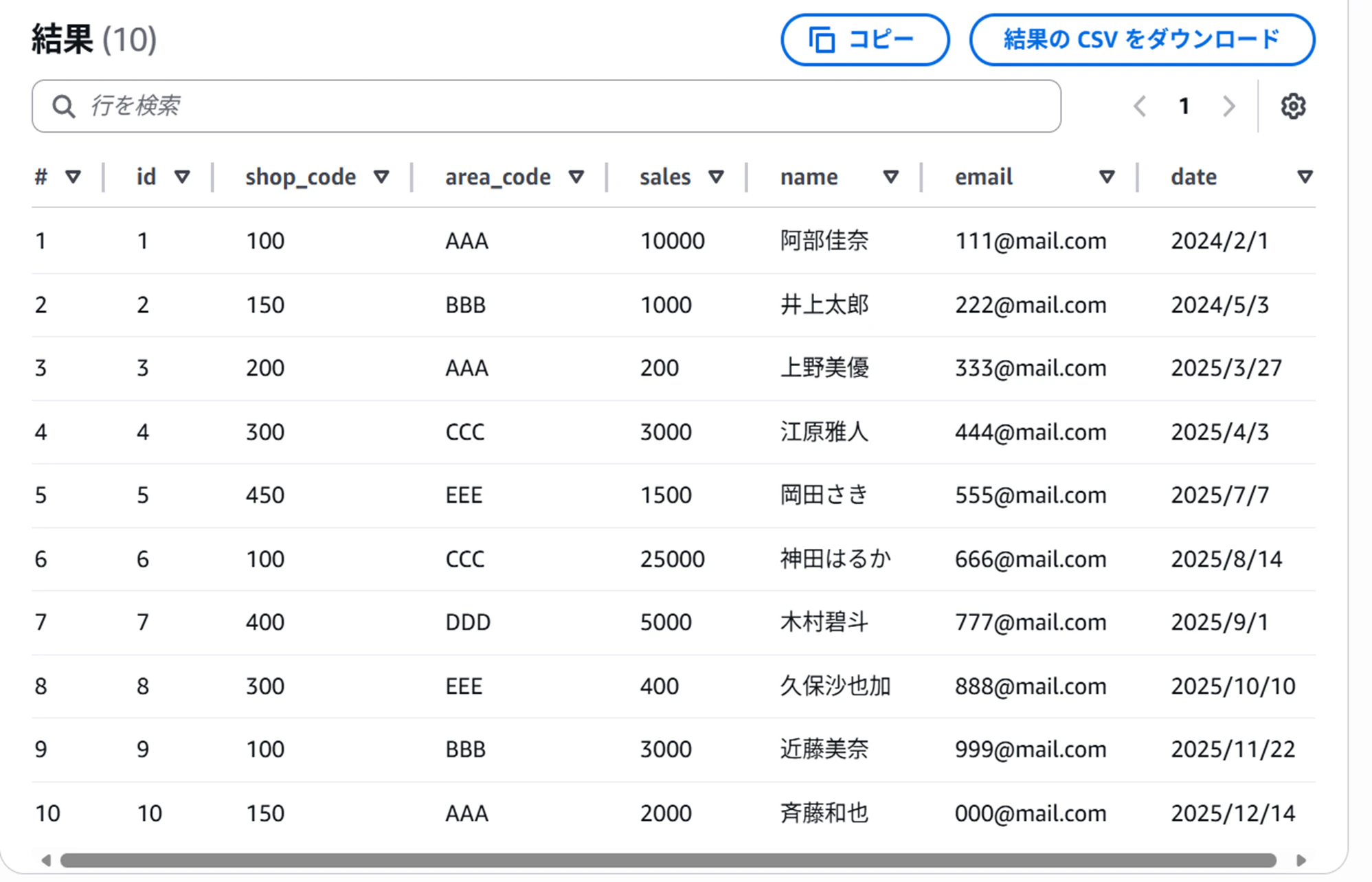
今回は実際に以下のようなcsvファイルをS3に配置し、Athenaからクエリできるようにしていきたいと思います。
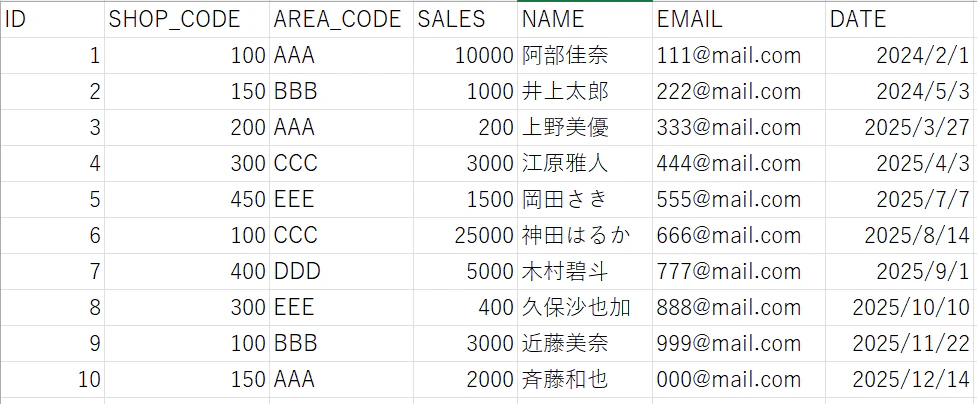
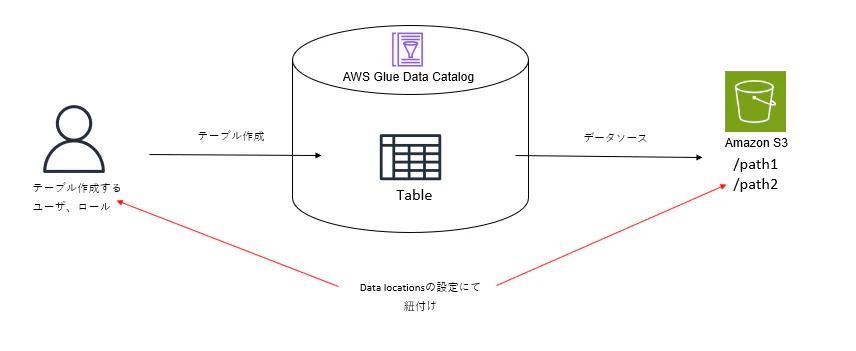
S3内のデータにクエリするためには、Glue DataCatalog内にDatabaseおよびtableを作成する必要があります。
構成としては通常のデータベースと似ておりで、Glue Databaseの中にtableを複数作成することができます。
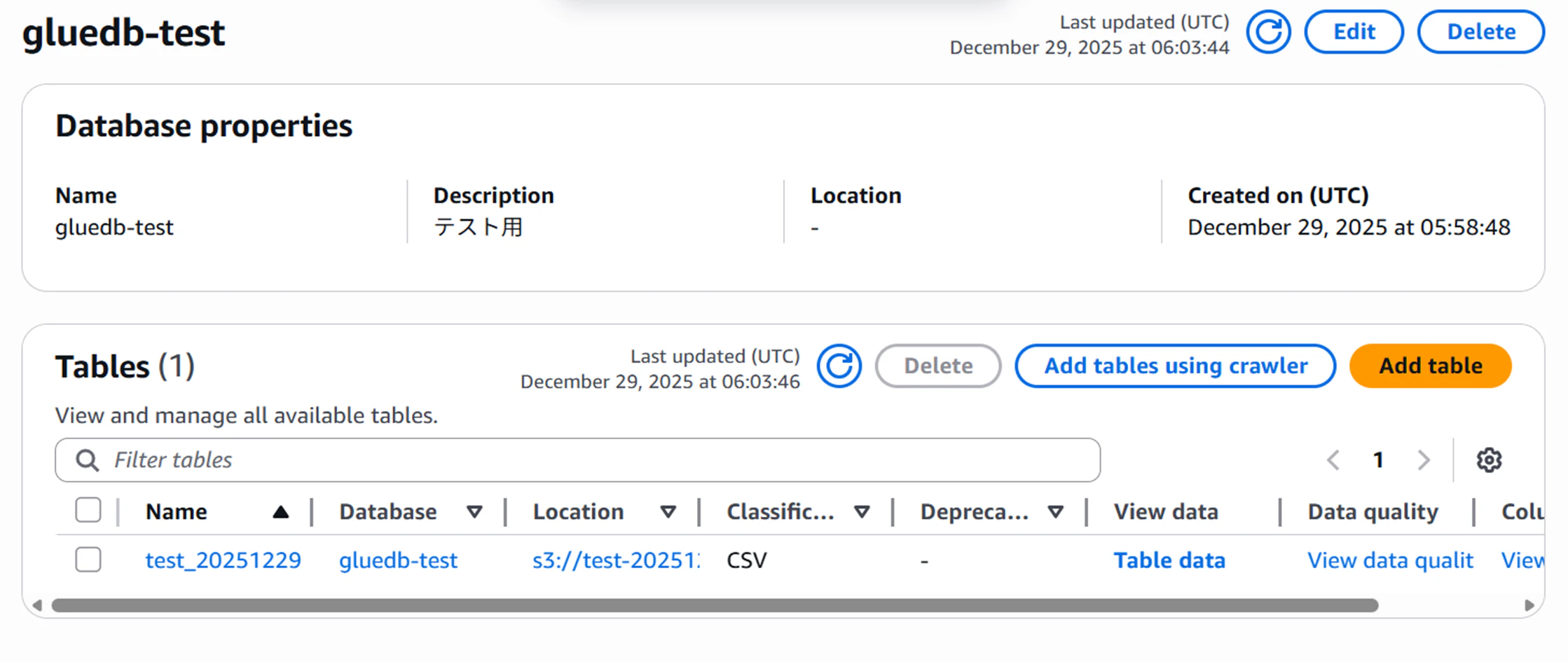
TableではS3のどのプレフィックスに保管されているデータか、またそのデータのスキーマなどが格納されています。これらのメタデータを利用して、S3内のデータに対してSQLを実行することができるということになります。
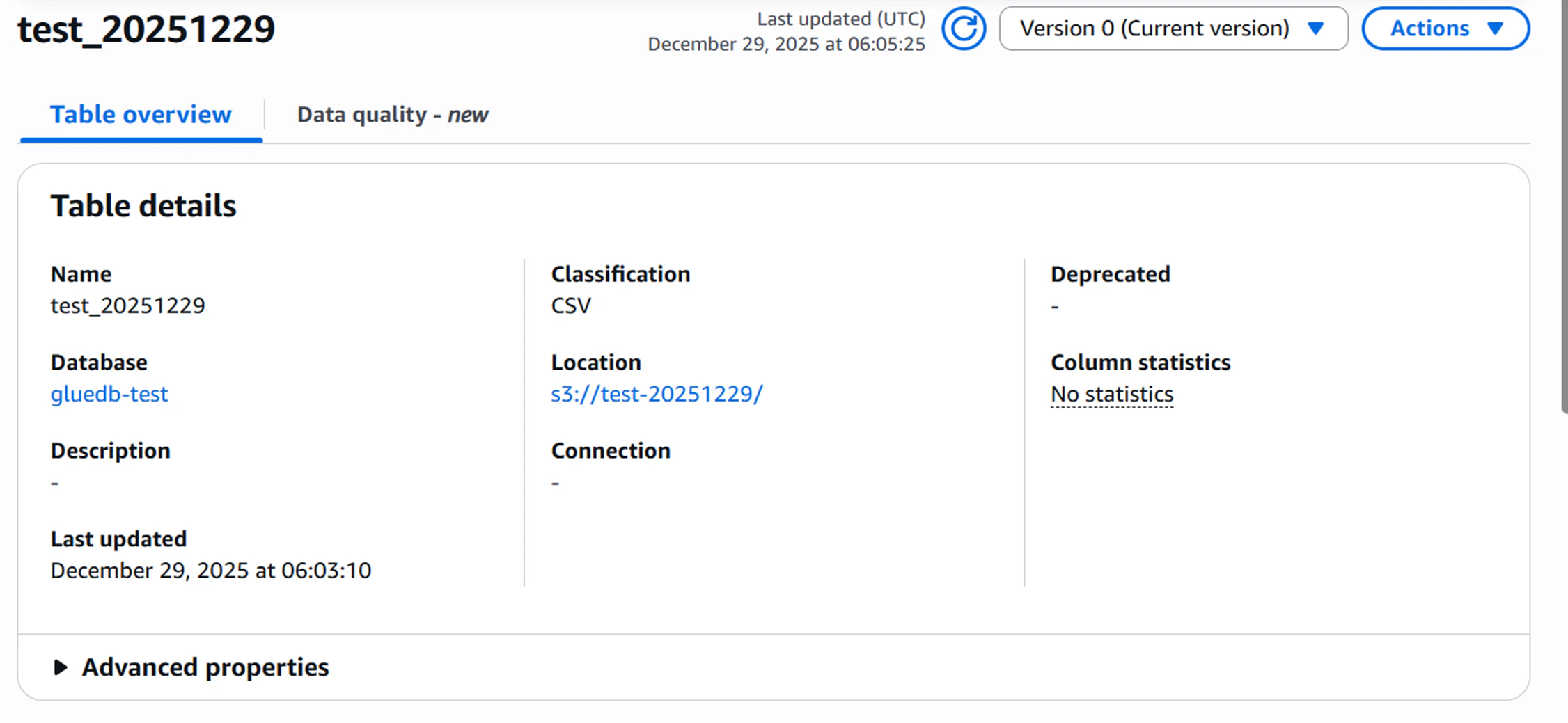
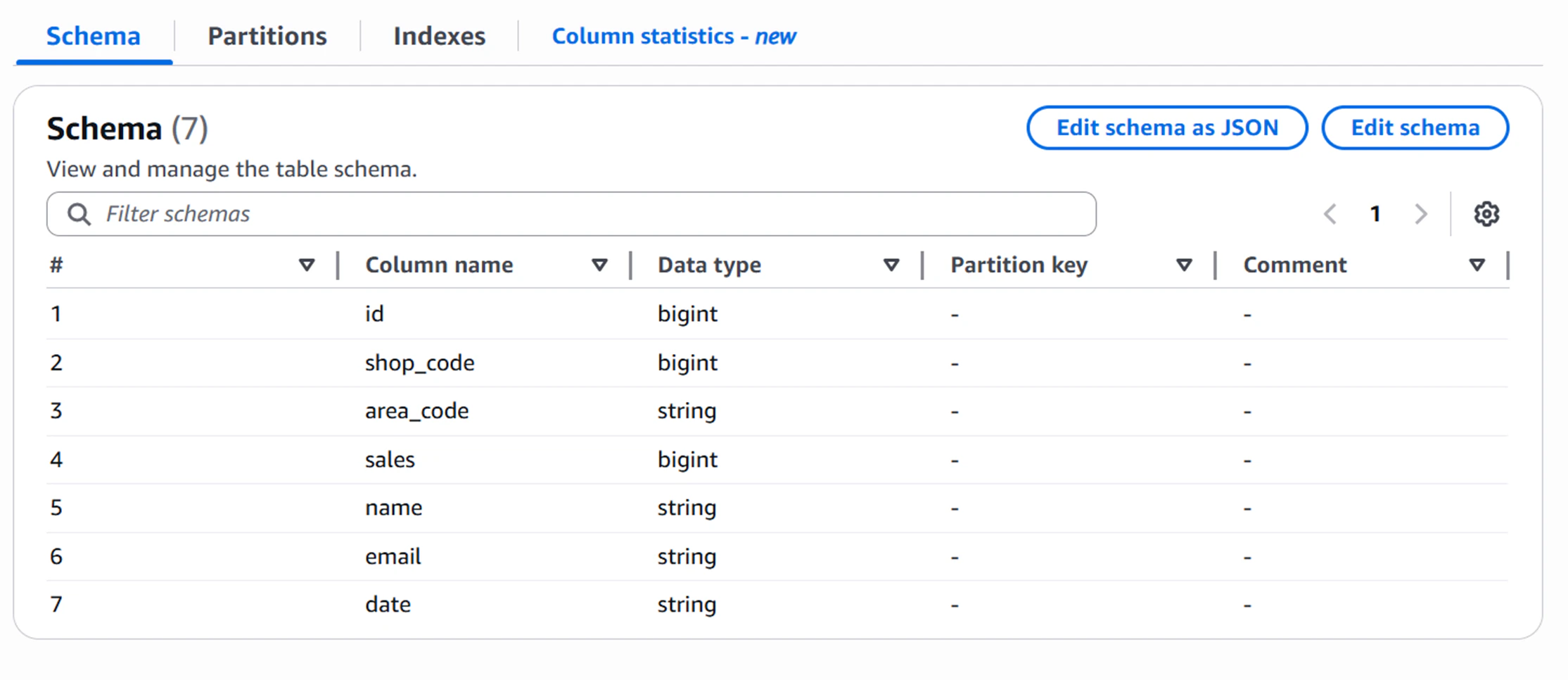
スキーマに関しては手動で入力することも可能ですが、crawlerを利用しS3内のデータをクロールすることで自動作成も可能です。(自動作成後に手動で修正することも可能です。)
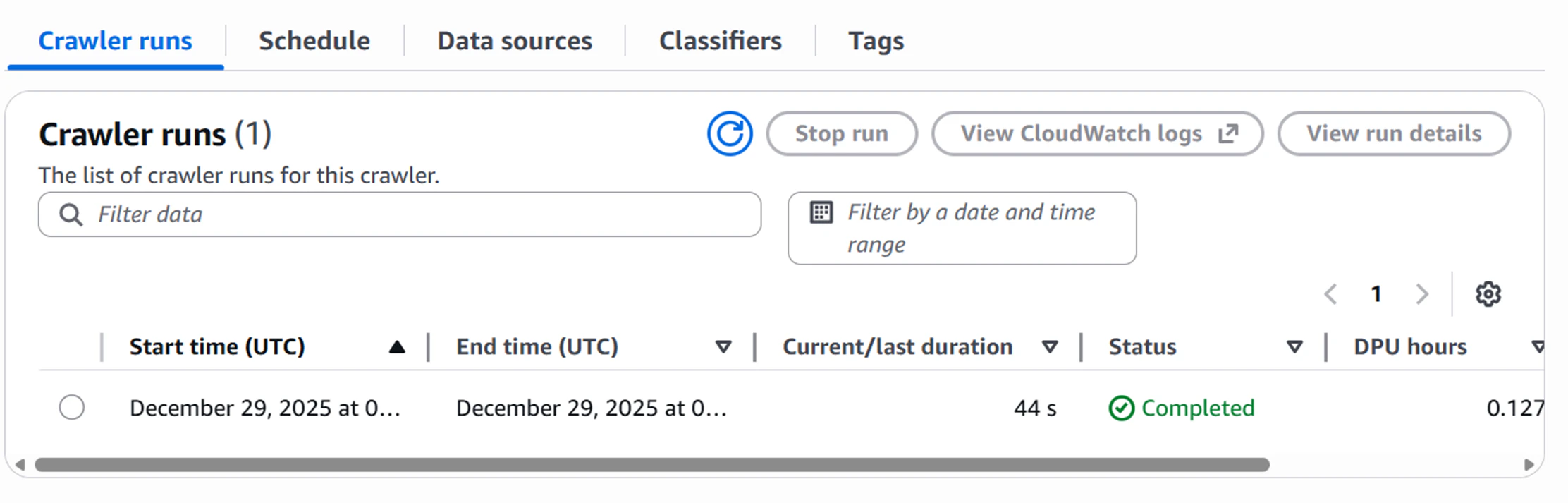
このようにGlue DataCatalog内にtableの作成が完了すればS3のデータに対してAthenaでクエリを実行することが可能になります。
(今回はBIツールからではなくAthenaからのクエリ実行画面とさせていただきます。)
②Lake Formationによる閲覧データの制御
今回のデータにおいて例えば「このユーザはshop_codeが100のデータのみ閲覧できないようにしたい」であったり「このユーザはemail以外のカラムのみ閲覧可能にしたい」といった行や列に対してデータの閲覧権限を与えたいとします。
そのような場合はIAMポリシーでの制御となると複雑化してしまいますが、Lake Formationを利用すれば簡単にデータの閲覧権限を制御することが可能となります。
Lake Formationを利用する上では以下の3点の設定が必要となります。
- Data lake locations
- Data Locations
- Data filters
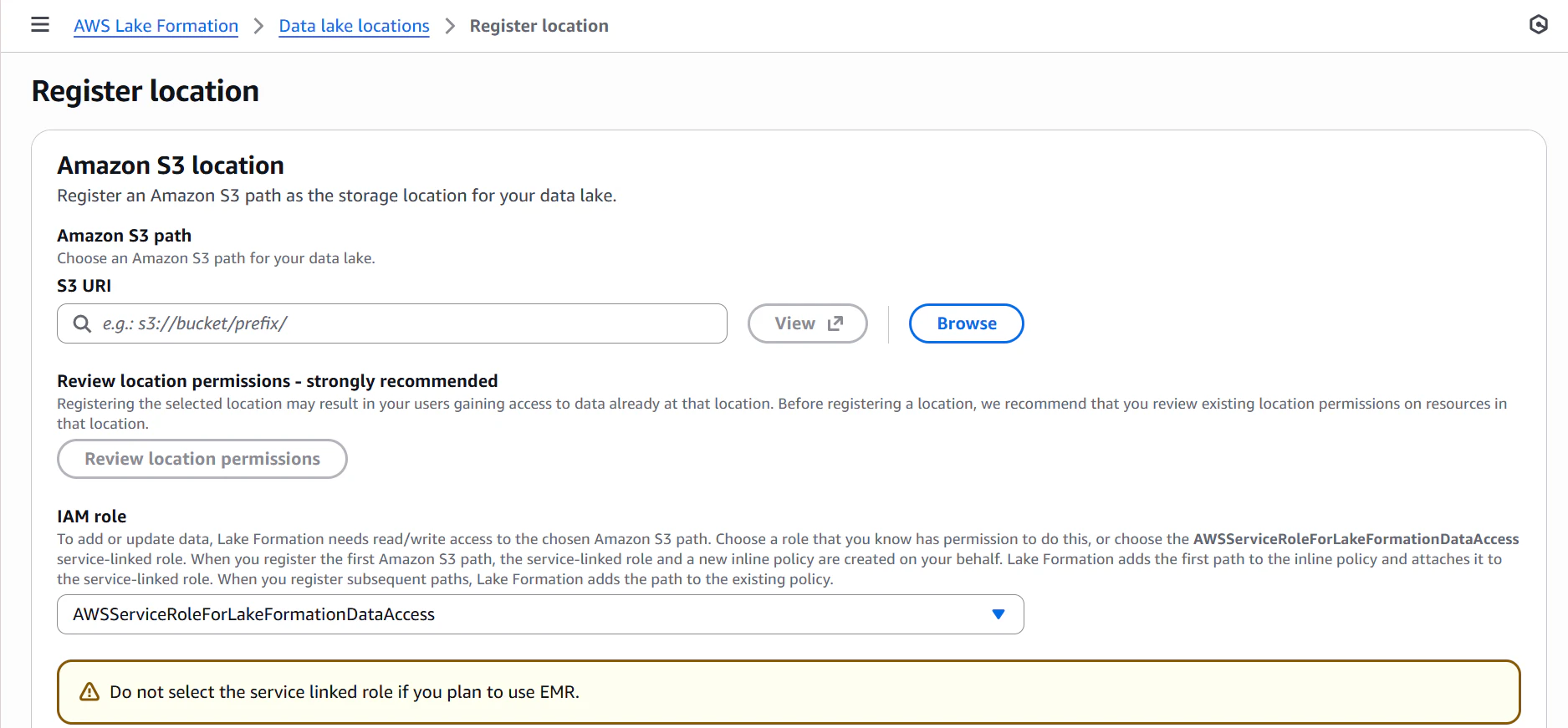
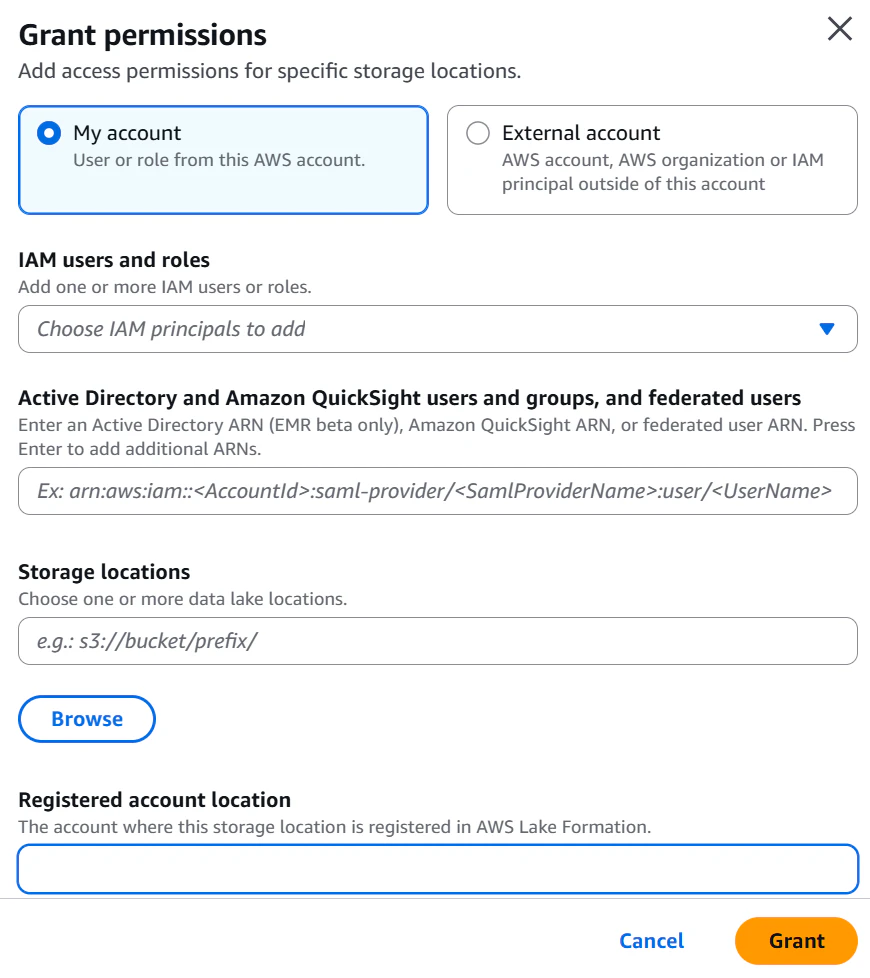
まずData lake locationsについてです。
ここではLake Formationで権限制御したい対象となるデータのS3パスの指定とLake FormationにアタッチするIAMロールを選択します。
またPermission modeというものも選択する必要があります。
| 設定値 | 説明 |
|---|---|
| Hybrid access mode | Lake Formationでの権限制御とIAMポリシーの内容を兼用 |
| Lake Formation | Lake Formationでの権限制御のみ |

次にData Locationsです。
ここではLake Formationで権限制御したい対象となるデータのS3パスに対してGlue DataCatalogのリソース(テーブル等)を作成・編集可能なIAMユーザやロールを許可します。Lake Formation管理のデータに対して、CREATE TABLEなどのテーブル作成・編集クエリを実行するユーザやロールがある場合は設定が必要となります。(特になければ設定不要)
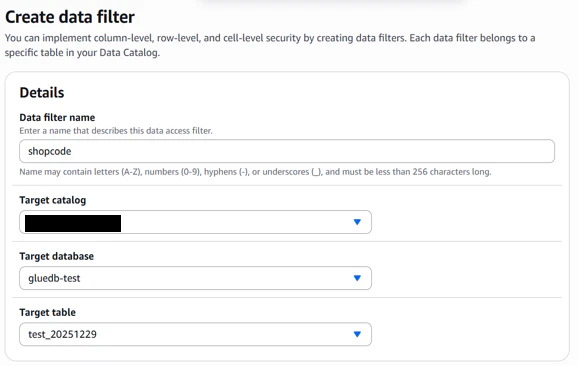
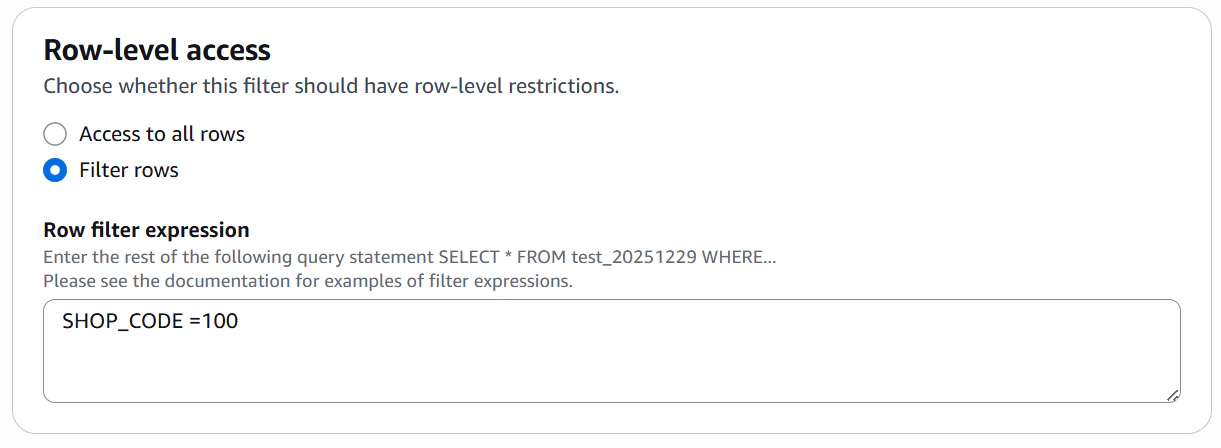
最後にData filtersですが、この設定にて列、行のアクセス制御設定を実施します。
▽列レベルの制御
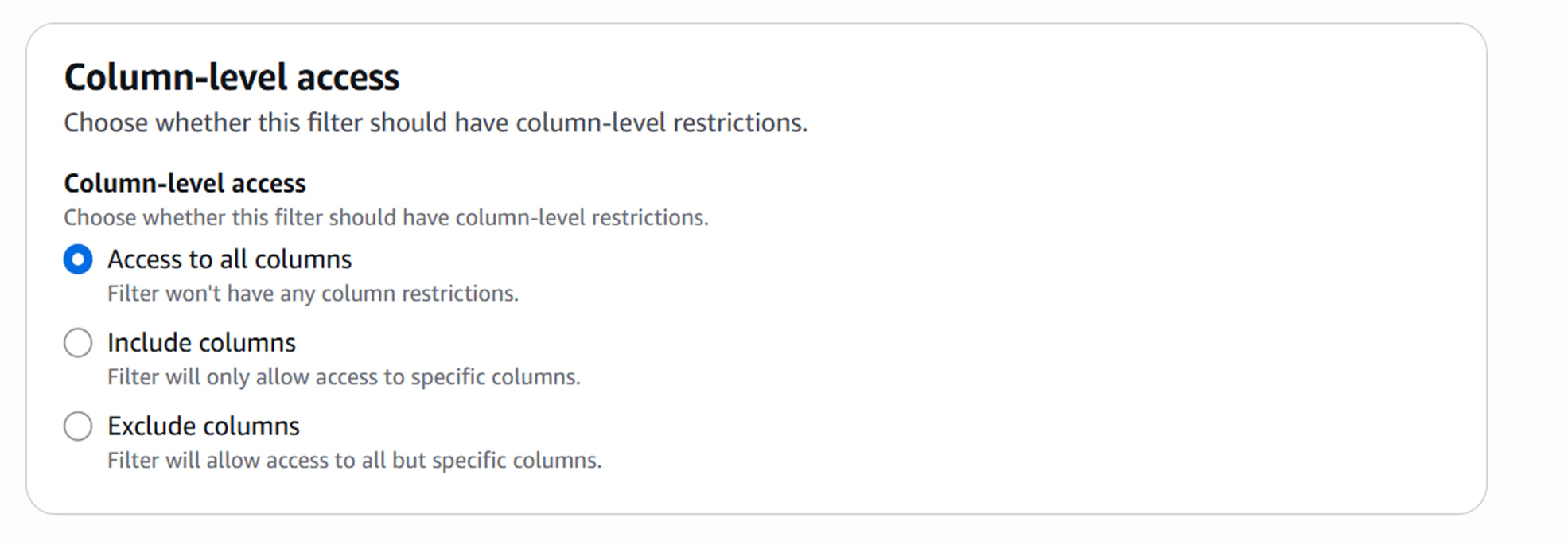
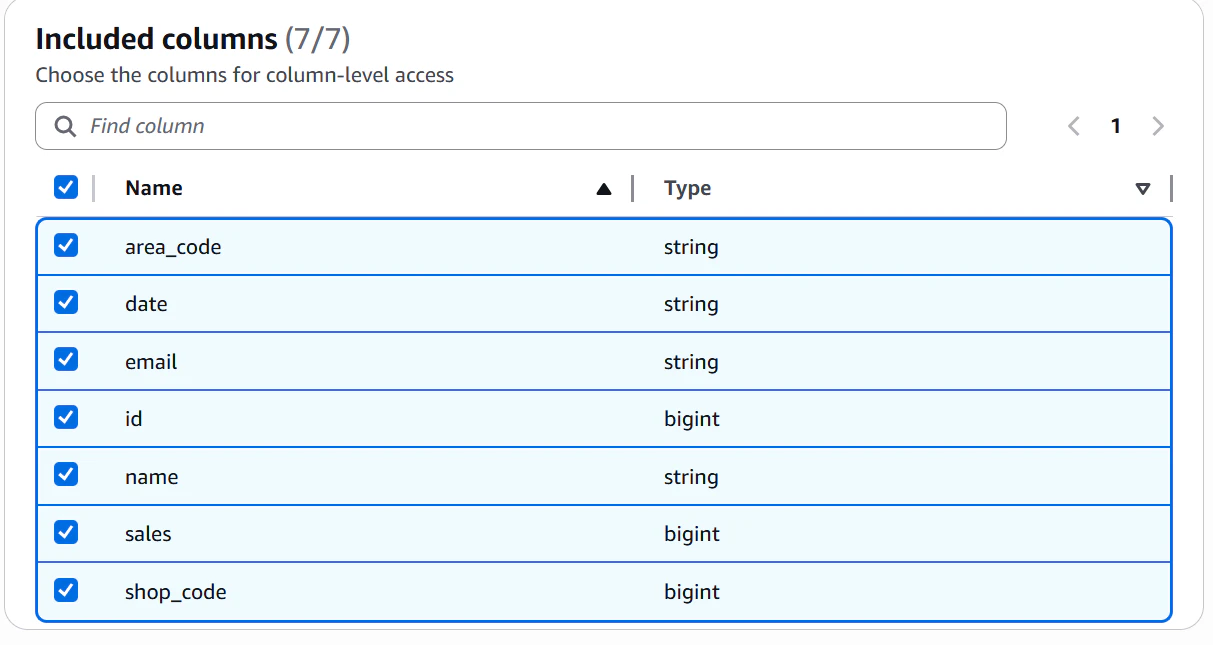
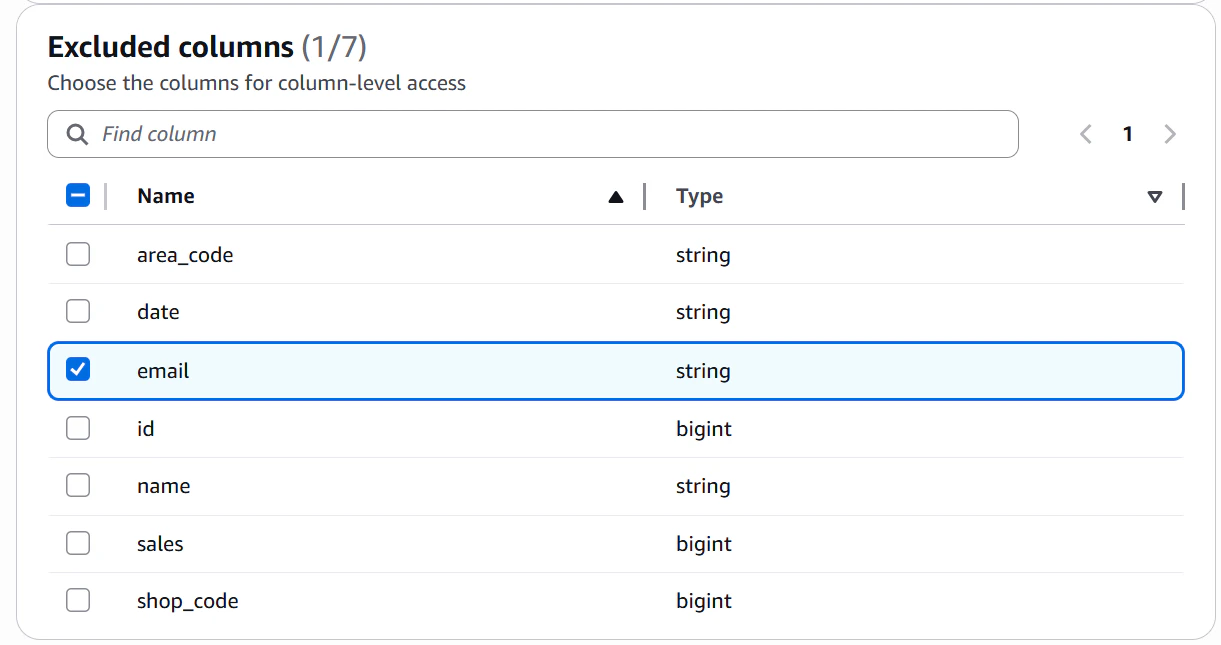
▽行レベルの制御

作成したData filterをGrant permissionsでIAMユーザにフィルターをアタッチします。

Data filterはIAMユーザ単位でのアタッチで、IAMグループ単位でのアタッチはできません。
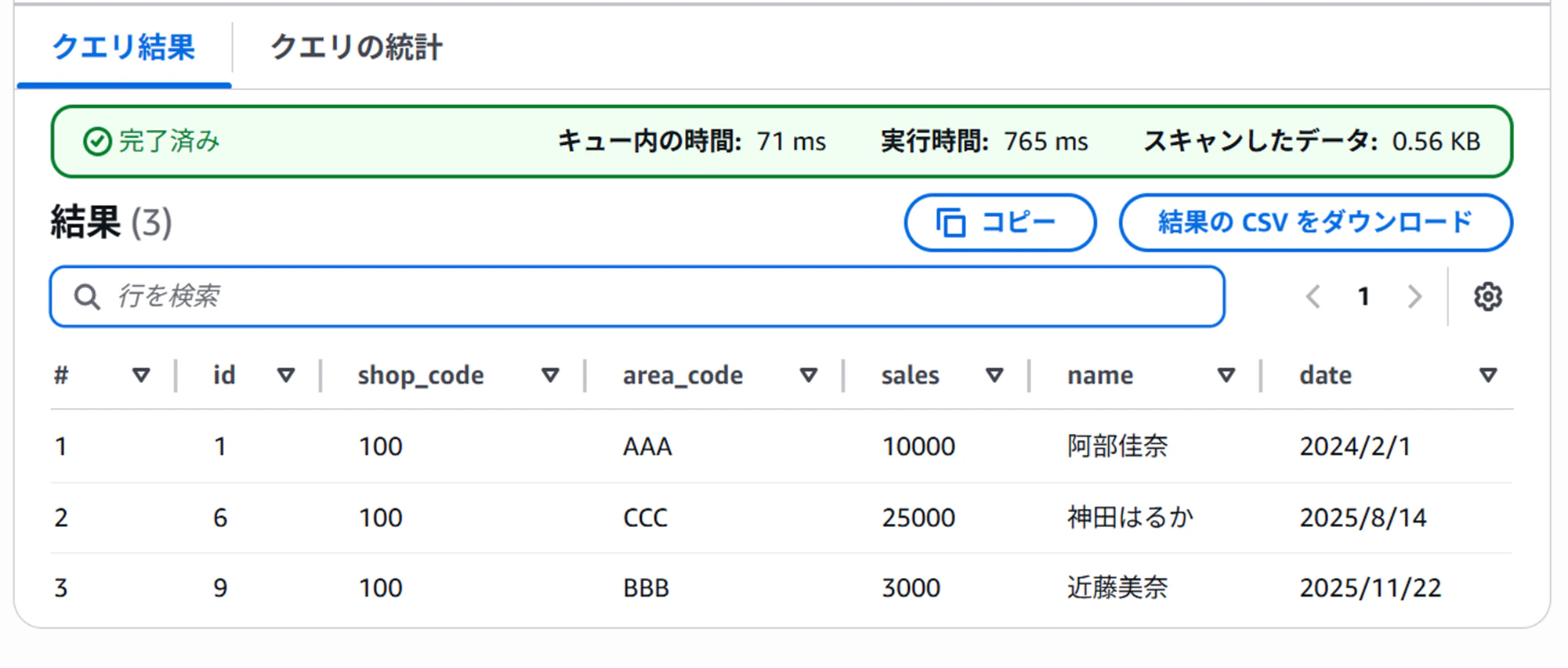
今回は以下2つのデータフィルターを作成して、「select * from テーブル名」クエリしてみた結果を確認します。
▽emailカラムは表示せず、shop_codeが100の行のみ表示するフィルター
▽shop_code,area_code,nameカラムのみ表示かつarea_codeがAAA以外の行を表示するフィルター

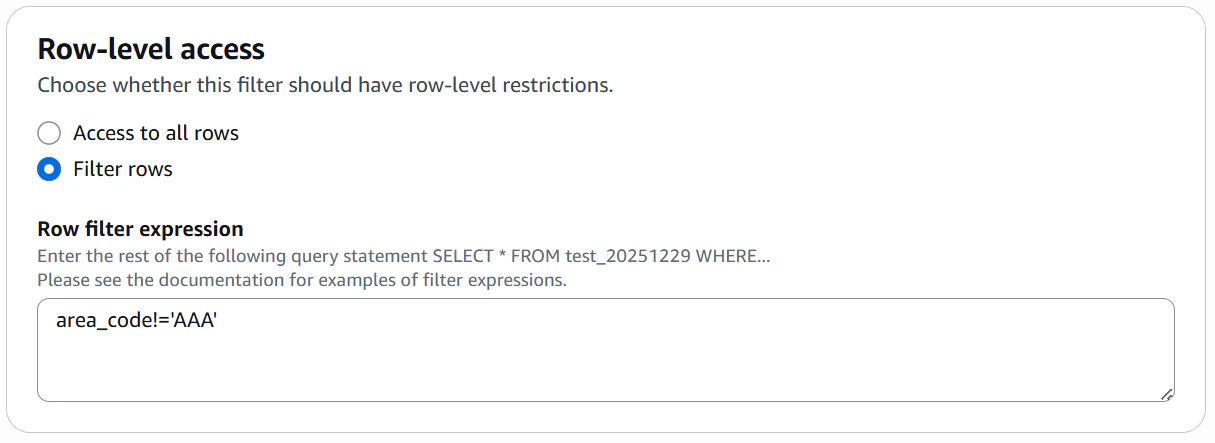
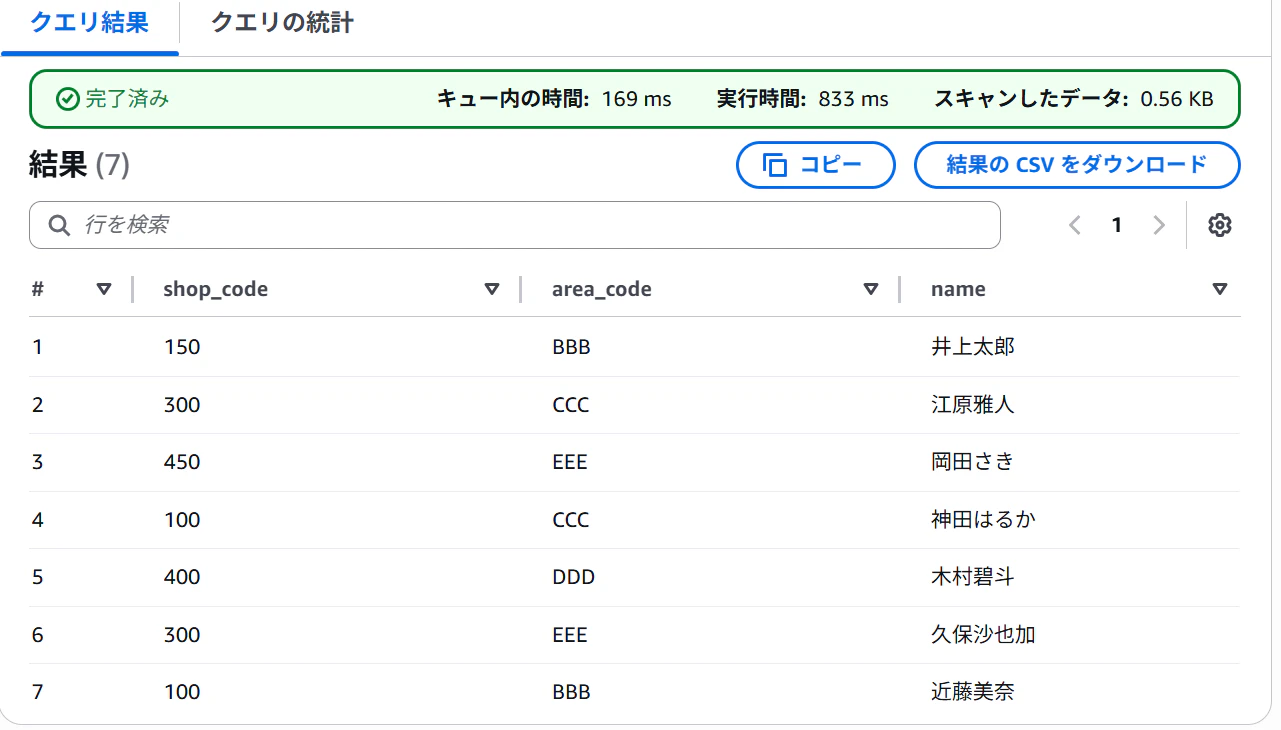
初めての設定の際はデフォルトのフィルターがついており、フィルターをアタッチしても上手く権限制御が適応されませんのでデフォルトのフィルターを削除して再度やり直してください。

クエリ結果の格納場所はAthenaのワークグループ毎に設定可能となります。
IAMポリシーでS3へのアクセス制御をしていればクエリ実行のみならずクエリ結果についても閲覧制御ができます。

まとめ
今回は自分が案件で設計していたデータ分析基盤について記事にしてみました。
設計思想やサービスの仕組みなど自分の頭の中の整理にもいい機会になりました!