2015/02/15 書き直しました!サーセン!
安すぎて今までその考えはなかったわwww
さて、BigQueryの課金について。
今まで1テーブルあたりのデータ量も数十GBレベル、レコード数も億に届くかどうかぐらいのデータなんでクソクエリ回したところで1回1円未満とかそんなだったので、あんまり気にしなかった。(まぁ、使い始めた頃は5倍ぐらいの値段だったので気にするレベルだったのですが)
あと、GoogleAnalyticsPremiumも入っているし、毎月$500が免除されるためもっと気にしてなかった。w
でも、普通に契約するとお金がかかるわけで。なので、ちょっと考えてみましたと。
そもそもどこに課金されるんだっけ?
BigQueryの課金は主に3つあります。
- 入れているデータ量(ストレージ)
- StreamingInsert使っている場合はその行数
- クエリするデータ量
詳しくはこちらに書いていますよっと。
ストレージの課金
BigQueryに放り込んでるデータ量によって課金されます。
$0.020(GB 単位/月)だそうです。でも、実際には明細をみる限り1時間単位で課金されているように見えます。
BigQuery ストレージ: ******** Gibibyte-hour(プロジェクト: *****)
入れた時点から時間割して課金ってことなんでしょう。うちだと400GBぐらいで800円/月ぐらいです。
StreamingInsertの課金
2014 年 7 月 1 日以降は $0.01(100,000 行あたり)。
だそうです。今から使っていきますが、まだ明細には載っていないのでごめんなさい。
クエリによる課金
これですね。真打登場です。$5(処理容量単位: TB)だそうです。
テーブルのデータ量による課金じゃないんですね。クエリを実行した『列』のデータ量に対して課金されるそうです。
しかし、これがよくわからない。一応勉強したんですが。不思議がいっぱいあります。
今回はここを掘り下げてみたいと思います。
色んなクエリを投げてみよう
って、ことで前編では1テーブルのクエリを中心にやっていきます。
後編ではJOINやUNIONについてやっていきます。
*このあたりから書き直しました。すいません・・・
使うデータ
こんな感じのサンプルデータを使います。
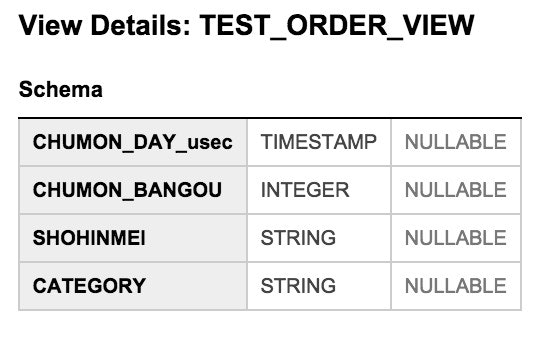
各カラムの説明、容量はSELECTでそのカラムだけを出した場合。
■テーブル全体(2.10GB 4500万レコード)
全体の容量です。SELECT *でやってみました。レコード数はCOUNT(*)で取りました。
■CHUMON_DAY(344MB)
TIMESTAMP型です。注文日が入っています。
※画像ではカラム名のあとに『_usec』と入っていますが、バグのようですが気にしない。
■CHUMON_BANGOU(344MB)
INTEGER型です。注文番号が入っています。
■SHOHINMEI(1.07GB)
STRING型です。商品名が入っているので一番重いです。
■CATEGORY(371MB)
STRING型です。カテゴリー名が日本語で入っています。
((344 + 344 + 371) / 1024) + 1.07 = 2.10GB あってますね。
じゃ、やっていきましょう。
結局は足し算になります!
前述しましたが、クエリに書かれているカラムが課金対象となります。
SELECTで使おうがWHEREで使おうが関係ありません。
と、いうことは逆に考えてみるとそのクエリに1回書かれていれば2回使われても1カラムの容量で計算されるようです。やってみましょう。
-
1つのカラムをSELECT句で指定します。
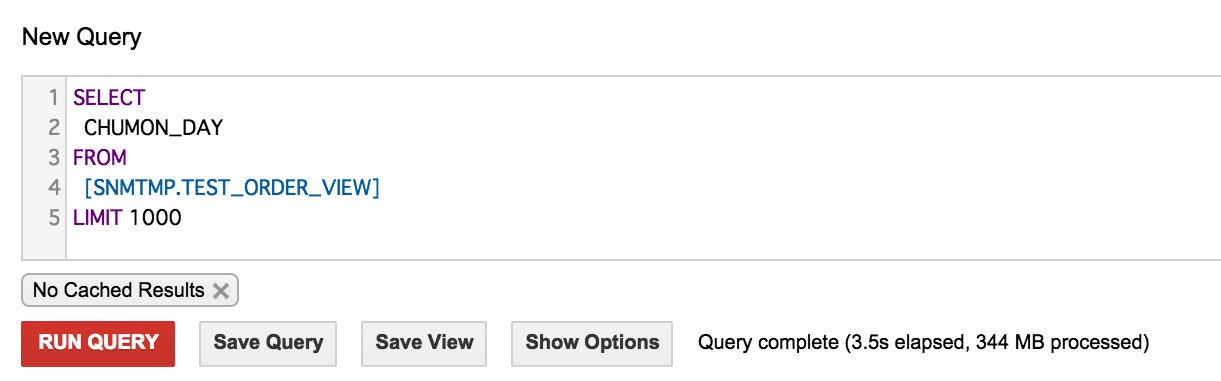
カラムの説明で書いたとおりの容量になっています。 -
2つのカラムをSELECT句で指定します。
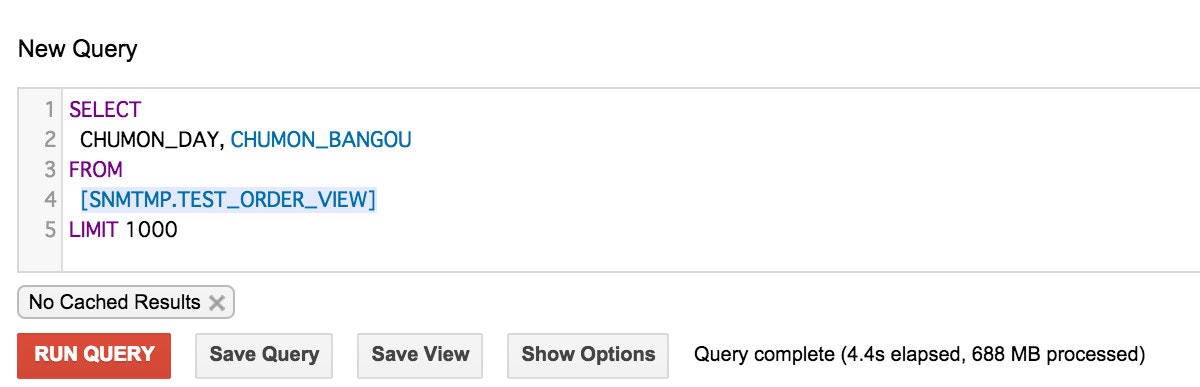
きちんと足し算されています。 -
2つカラムをSELECT句で指定して、そのうち1つのカラムをWHERE句で指定してみます。
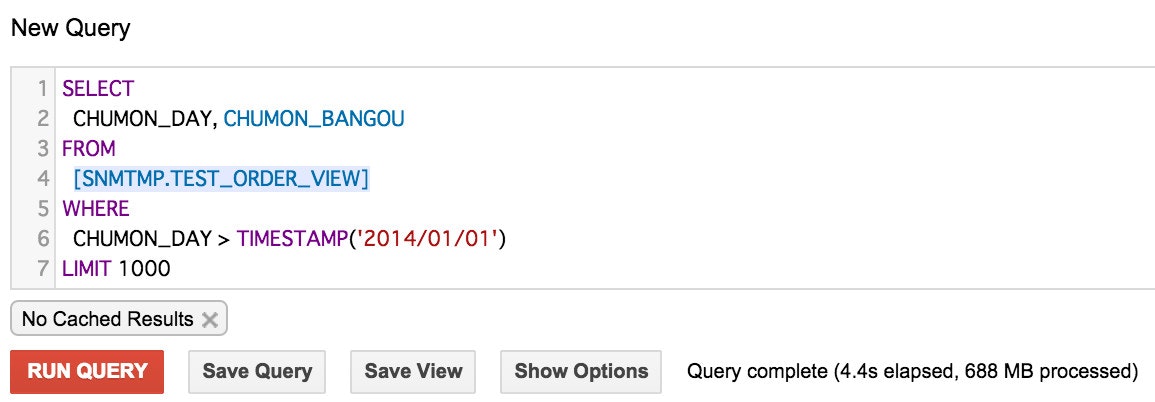
SELECT句でもWHERE句でも使われているのに変わりませんでしたね。 -
2つのカラムをSELECT句で指定して、そこに含まれないカラムをWHERE句で指定してみます。
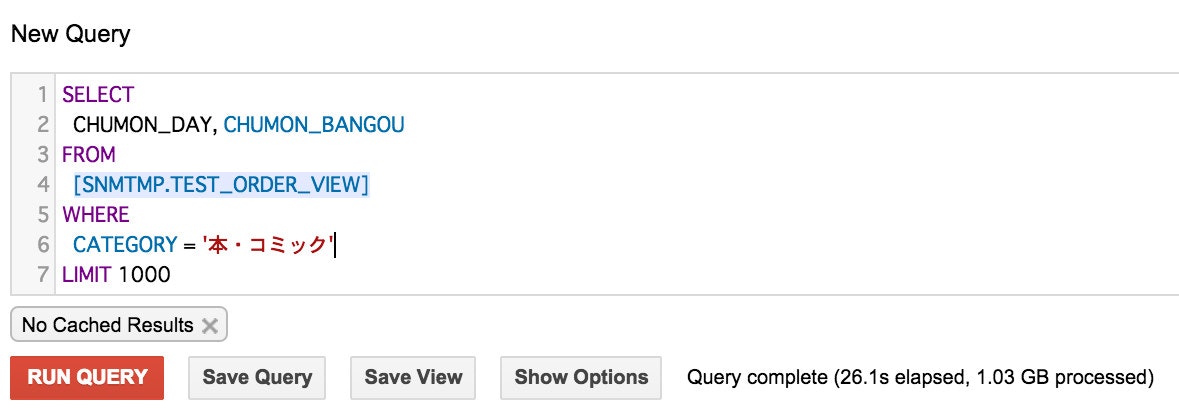
ここでも見事に足し算されています。 -
おまけ(でも重要!)
ここまでで使ったカラムだけが課金されることがわかりました。
そこのカラムしか課金されないというのはすごいメリットだなぁと。
じゃ、CPUを使うような処理はどうなるのか?
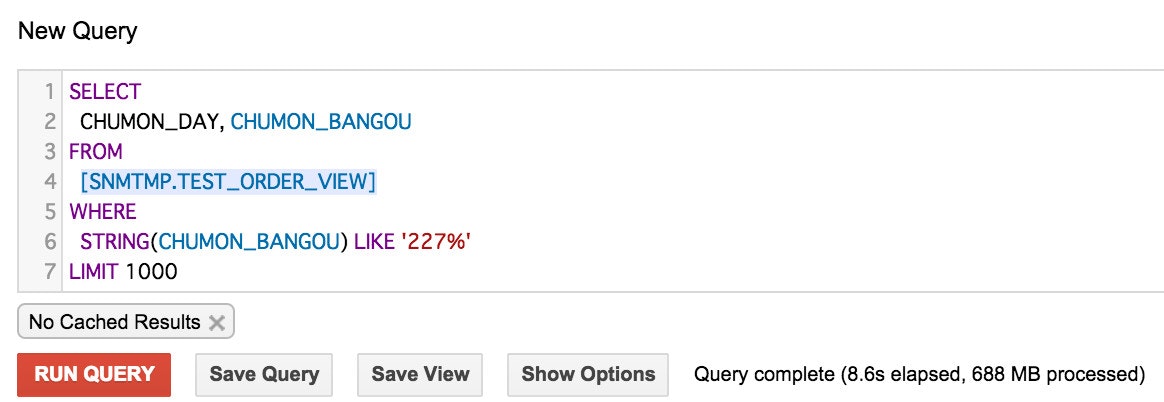
サーセン!Googleさん!無駄CPU使っちゃって!
普通のRDBとかで考えると『型変換やったらIndex効かないよぉ』となったり。
CPU使うような処理を書いても課金は同じってことでした。
どうでしょうか?課金はどこが対象なのかが理解できたでしょうか。
今まで『安いから、まぁいっか』と何も考えずにデータを入れていましたが、少しは考えた方が良いかな?と思ったり。1つのカラムにデータを入れていて、その中の一部の文字列を取ってきて、違うカラムの数値を集計するとかあると思います。そんな場合はその文字列を切り出したりした方が良いわけで。使っていくうちにチューニングしていくのも良いかもしれません。
性能というよりはお金的にという感じですけどね。
もし、わかんないことあったらコメントください。実験します!
と、いうことで次回はJOINやUNIONなどもお金的な観点でやってみます。