要約
- Kaggle / MNIST で予測精度向上を目指す (1. チュートリアル通りにCNN を作る) で作った CNN のフィルタサイズを大きくすることで,精度向上を目指す
- 予測精度は 0.99035 となり,前回の 0.98792 を上回った
はじめに
前回の記事 (Kaggle / MNIST で予測精度向上を目指す (1. チュートリアル通りにCNN を作る)) では TensorFlow のチュートリアル 通りに畳み込みニューラルネットワーク (Convolutional Neural Network, CNN) を作り,予測精度 0.98792 を得られた。
今回は,あらためて MNIST の画像を確認して,精度向上の方策を考える。
MNIST の画像を確認する
データ処理において,データを生に近い形で確認することは重要である。なので,ここで MNIST の画像を見ておくことにする。(これを表示するスクリプトは,本記事の末尾に掲載)

これを見て私が感じたのは,太い文字が多いな ということである。前回の CNN では tensorflow.keras.layers.Cond2D で (3, 3) フィルタを使っていた。しかしこれでは,太い文字の特徴を十分に抽出できていない可能性があると思った。
そこで,第 1 層目のフィルタを (3, 3) から (5, 5) に変更することにした。
CNN の作成,および最適な epochs 数の探索
データの準備
データを読み込んで,0 ~ 1 の範囲に変換する。この部分は,前回と同じ。
# This Python 3 environment comes with many helpful analytics libraries installed
# It is defined by the kaggle/python Docker image: https://github.com/kaggle/docker-python
# For example, here's several helpful packages to load
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
# Input data files are available in the read-only "../input/" directory
# For example, running this (by clicking run or pressing Shift+Enter) will list all files under the input directory
import os
for dirname, _, filenames in os.walk('/kaggle/input'):
for filename in filenames:
print(os.path.join(dirname, filename))
# You can write up to 20GB to the current directory (/kaggle/working/) that gets preserved as output when you create a version using "Save & Run All"
# You can also write temporary files to /kaggle/temp/, but they won't be saved outside of the current session
# Load data
train_data = pd.read_csv("/kaggle/input/digit-recognizer/train.csv")
test_data = pd.read_csv("/kaggle/input/digit-recognizer/test.csv")
train_data_len = len(train_data)
test_data_len = len(test_data)
print("Length of train_data ; {}".format(train_data_len))
print("Length of test_data ; {}".format(test_data_len))
# Length of train_data ; 42000
# Length of test_data ; 28000
train_data_y = train_data["label"]
train_data_x = train_data.drop(columns="label")
train_data_x = train_data_x.astype('float64').values.reshape((train_data_len, 28, 28, 1))
test_data = test_data.astype('float64').values.reshape((test_data_len, 28, 28, 1))
train_data_x /= 255.0
test_data /= 255.0
訓練データとバリデーションデータに分割
今回は epoch 毎の精度を確認したいので,訓練データとバリデーションデータに分割する。ここでは sklearn.model_selection.train_test_split を使う。
- 訓練データ ;
X,y - バリデーションデータ ;
X_cv,y_cv
です。
from sklearn.model_selection import train_test_split
X, X_cv, y, y_cv = train_test_split(train_data_x, train_data_y, test_size=0.2, random_state=0)
test_size=0.2 として,訓練データ : バリデーションデータ = 8 : 2 に分割した。具体的なデータ数は,
- 訓練データ ; 42000 * 0.8 = 33600
- バリデーションデータ ; 42000 * 0.2 = 8400
である。実は,後々の学習時のバッチサイズはデフォルトの 32 だが,32 * 1050 = 33600 となり,実は 33600 はキリのいい数字になっている。
CNN を作る
前回の CNN をベースに,第 1 層目のフィルタを (3, 3) から (5, 5) に変更する。
# Create CNN model
import tensorflow as tf
from tensorflow.keras import layers, models
model = models.Sequential()
# model.add(layers.Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 1))) # 前回
model.add(layers.Conv2D(32, (5, 5), activation='relu', input_shape=(28, 28, 1))) # 今回
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.Flatten())
model.add(layers.Dense(64, activation='relu'))
model.add(layers.Dense(10, activation='softmax'))
model.summary()
コンパイルして学習を実行する
今回は epoch 数を 20 にして,最適な epochs 数を探索する。バリデーションデータは,validation_data オプションで指定。後ほど精度を確認するために,tensorflow.keras.models.fit の結果を history という変数に保存している。
# Compile
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
# Fit
history = model.fit(X, y, validation_data=(X_cv, y_cv), epochs=20)
ログを示す。
Epoch 1/20
1050/1050 [==============================] - 3s 3ms/step - loss: 0.1967 - accuracy: 0.9399 - val_loss: 0.0809 - val_accuracy: 0.9752
Epoch 2/20
1050/1050 [==============================] - 3s 3ms/step - loss: 0.0601 - accuracy: 0.9815 - val_loss: 0.0607 - val_accuracy: 0.9810
Epoch 3/20
1050/1050 [==============================] - 3s 3ms/step - loss: 0.0429 - accuracy: 0.9867 - val_loss: 0.0503 - val_accuracy: 0.9843
Epoch 4/20
1050/1050 [==============================] - 3s 3ms/step - loss: 0.0333 - accuracy: 0.9893 - val_loss: 0.0479 - val_accuracy: 0.9852
Epoch 5/20
1050/1050 [==============================] - 3s 3ms/step - loss: 0.0265 - accuracy: 0.9913 - val_loss: 0.0396 - val_accuracy: 0.9873
Epoch 6/20
1050/1050 [==============================] - 3s 3ms/step - loss: 0.0221 - accuracy: 0.9924 - val_loss: 0.0464 - val_accuracy: 0.9875
Epoch 7/20
1050/1050 [==============================] - 3s 3ms/step - loss: 0.0181 - accuracy: 0.9941 - val_loss: 0.0514 - val_accuracy: 0.9862
Epoch 8/20
1050/1050 [==============================] - 3s 3ms/step - loss: 0.0162 - accuracy: 0.9946 - val_loss: 0.0524 - val_accuracy: 0.9850
Epoch 9/20
1050/1050 [==============================] - 3s 3ms/step - loss: 0.0134 - accuracy: 0.9958 - val_loss: 0.0379 - val_accuracy: 0.9888
Epoch 10/20
1050/1050 [==============================] - 4s 4ms/step - loss: 0.0120 - accuracy: 0.9958 - val_loss: 0.0458 - val_accuracy: 0.9890
Epoch 11/20
1050/1050 [==============================] - 3s 3ms/step - loss: 0.0100 - accuracy: 0.9968 - val_loss: 0.0378 - val_accuracy: 0.9899
Epoch 12/20
1050/1050 [==============================] - 3s 3ms/step - loss: 0.0084 - accuracy: 0.9971 - val_loss: 0.0568 - val_accuracy: 0.9873
Epoch 13/20
1050/1050 [==============================] - 3s 3ms/step - loss: 0.0102 - accuracy: 0.9968 - val_loss: 0.0495 - val_accuracy: 0.9892
Epoch 14/20
1050/1050 [==============================] - 3s 3ms/step - loss: 0.0083 - accuracy: 0.9971 - val_loss: 0.0399 - val_accuracy: 0.9913
Epoch 15/20
1050/1050 [==============================] - 3s 3ms/step - loss: 0.0072 - accuracy: 0.9977 - val_loss: 0.0404 - val_accuracy: 0.9901
Epoch 16/20
1050/1050 [==============================] - 3s 3ms/step - loss: 0.0058 - accuracy: 0.9980 - val_loss: 0.0504 - val_accuracy: 0.9906
Epoch 17/20
1050/1050 [==============================] - 3s 3ms/step - loss: 0.0088 - accuracy: 0.9972 - val_loss: 0.0658 - val_accuracy: 0.9885
Epoch 18/20
1050/1050 [==============================] - 3s 3ms/step - loss: 0.0042 - accuracy: 0.9986 - val_loss: 0.0609 - val_accuracy: 0.9883
Epoch 19/20
1050/1050 [==============================] - 3s 3ms/step - loss: 0.0082 - accuracy: 0.9976 - val_loss: 0.0636 - val_accuracy: 0.9876
Epoch 20/20
1050/1050 [==============================] - 3s 3ms/step - loss: 0.0065 - accuracy: 0.9981 - val_loss: 0.0520 - val_accuracy: 0.9895
最適な epochs を探索する
以下の 2 つの変数を確認する。epoch 数を横軸にして,グラフを描く。
- accuracy ; 訓練データの予測精度
- val_accuracy ; テストデータの予測精度
# draw graph of accuracy and val_accuracy
import matplotlib.pyplot as plt
plt.plot(history.history['accuracy'], label='accuracy')
plt.plot(history.history['val_accuracy'], label = 'val_accuracy')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.ylim([0.9, 1])
plt.legend(loc='lower right')
plt.show()
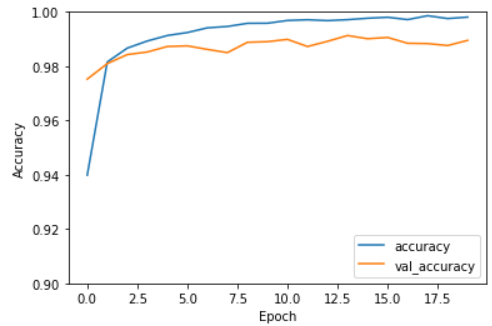
ログの epochs 数は 1 から始まっているが,グラフの x 軸は 0 から始まっていることに注意。 (うっかりしてました)
さっきのログやグラフから,val_accuracy (テストデータの精度) が 1 番良い,epochs = 14 を最適とここでは判断する。
注意
実際は loss (訓練データの損失) や val_loss (テストデータの損失) も確認して,過学習になっていないかを確認すべきだが,このときはそれに気付かなかった :-p
最適 epochs 数で予測する
コンパイルして学習する
データを読み込んで CNN を作るところまでは,先ほどと同じなので省略する。下記のように epochs=14 にして学習する。
# Compile
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
# Maximum of val_accuracy ; epochs = 14
history = model.fit(train_data_x, train_data_y, epochs=14)
予測と結果保存
前回同様に,テストデータを使って予測して,CSV 形式でファイルに保存する
# Prediction
rediction = model.predict_classes(test_data, verbose=0)
output = pd.DataFrame({"ImageId" : np.arange(1, 28000+1), "Label":prediction})
output.to_csv('digit_recognizer_CNN1e_epochs14.csv', index=False)
print("Your submission was successfully saved!")
訓練データの予測結果の保存
今後のスクリプトの改善のために,訓練データを使った予測結果を保存する。ここでは 2 種類のデータを保存している。
-
tensorflow.keras.models.predict_classes; ラベルの予測結果 -
tensorflow.keras.models.predict_proba; 各ラベルに対する確率
# Save probability for further study
pred = model.predict_classes(train_data_x, verbose=0)
pred_proba = model.predict_proba(train_data_x, verbose=0)
pred_df = pd.DataFrame(pred, index=np.arange(train_data_len), columns=["Prediction"])
pred_proba_df = pd.DataFrame(pred_proba, index=np.arange(train_data_len), columns=["p{}".format(i) for i in range(10)])
output = pd.concat([pred_df, pred_proba_df], axis=1)
output.to_csv("prediction_CNN1e_epochs14.csv", index=False)
print("Your prediction was successfully saved!")
結果
| No | 説明 | スコア |
|---|---|---|
| Ref | SVM | 0.98375 |
| 01 | チュートリアル通り | 0.98792 |
| 02 | (3,3) → (5,5) | 0.99035 |
チュートリアル通りに作った前回のスコアを越えた。「太い文字の特徴を認識できるようにするために,フィルタサイズを大きくする」という仮説が当たったからかは断言できないが,スコアを改善することができた。
今後は,保存したデータから「予測を間違えているデータ」を調べて,それに合うような改善を検討する。
また今回は「最適 epochs 数の探索」と「最適 epochs 数で予測する」を 2 つのスクリプトに分けた。このようなやり方は手間がかかるので,その部分も見直していく。
参考
web site
サンプルスクリプト
- show_digit.py ; MNIST データを表示するスクリプト
- digit-recognition_CNN1e_1.py ; 最適 epochs 数を探索するスクリプト
- digit-recognition_CNN1e_2.py ; 最適 epochs 数で予測するスクリプト