はじめに
画像も扱えるように、ロカール環境で VLM(視覚言語モデル)を構築しました。
開発環境
以下の記事の環境を使用しました。また、現在はいくつかバージョンアップ(変更)を行っています。
GeForce RTX 3050、Linux(Ubuntu 24.04.03)、CUDA Toolkit 13.0 Update 2、cuDNN 9.14.0、Python 3.12、Ollama 0.12.9
Ollama で VLM を実行
アリババ社の Qwen3-VL を使用します。他には Google 社の gemma3:12b などもあります。
ollama run qwen3-vl:8b
初回はファイルがダウンロードされ、実行に成功すると >>> (プロンプト入力)が表示されます。
>>> """
複数行のメッセージを記述する場合
"""
>>> /show
>>> /bye
(.llm) webmaster@noble03:~$ ollama ps
NAME ID SIZE PROCESSOR CONTEXT UNTIL
qwen3-vl:8b 901cae732162 11 GB 35%/65% CPU/GPU 4096 3 minutes from now
(.llm) webmaster@noble03:~$ ollama list
NAME ID SIZE MODIFIED
qwen3-vl:8b 901cae732162 6.1 GB 6 hours ago
Dify との接続
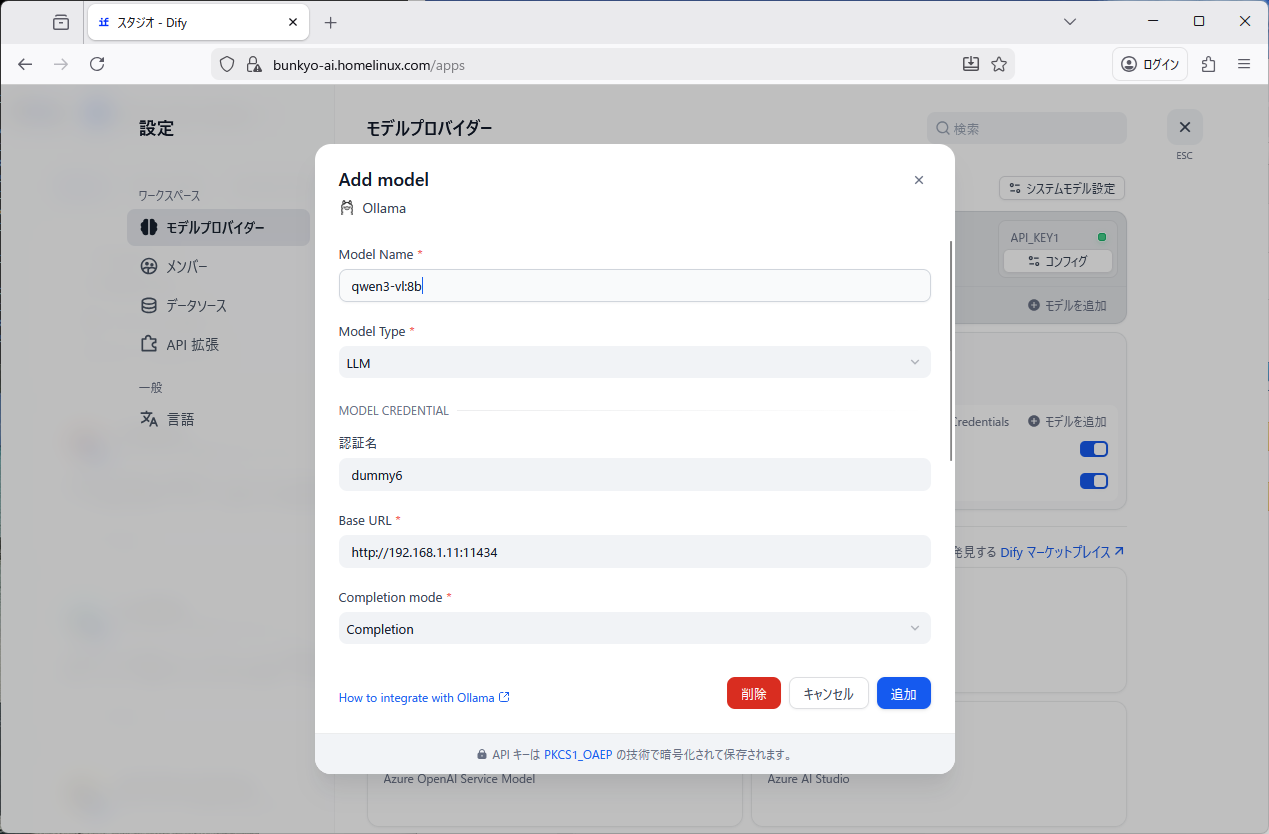
右上、ユーザーアイコン、設定、モデルプロバイダー、Ollama、モデルを追加
Model Name: qwen3-vl:8b
Model Type: LLM
Model credential (認証名): dummy6 ※重ならないように番号を振る
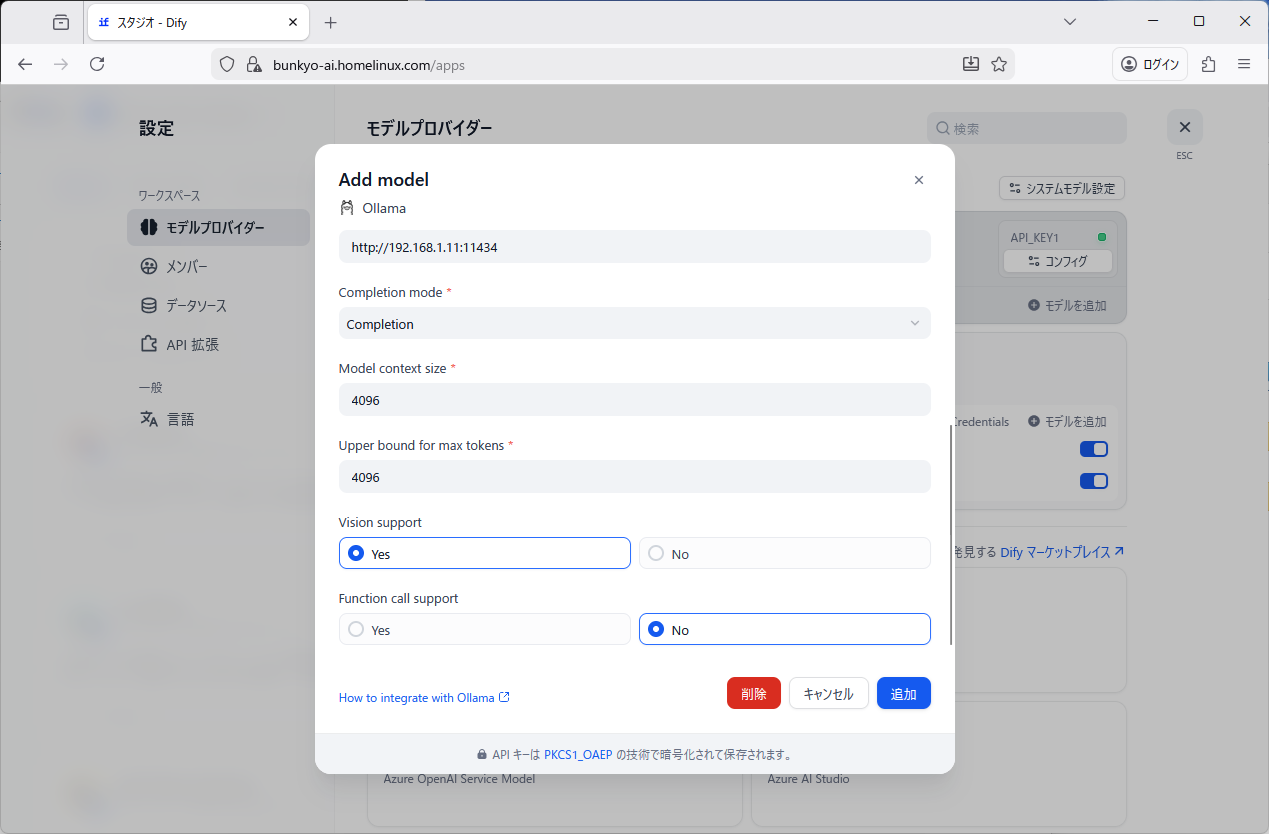
Base URL: http://192.168.11.1:11434
Completion mode: Completion
Vision support: Yes
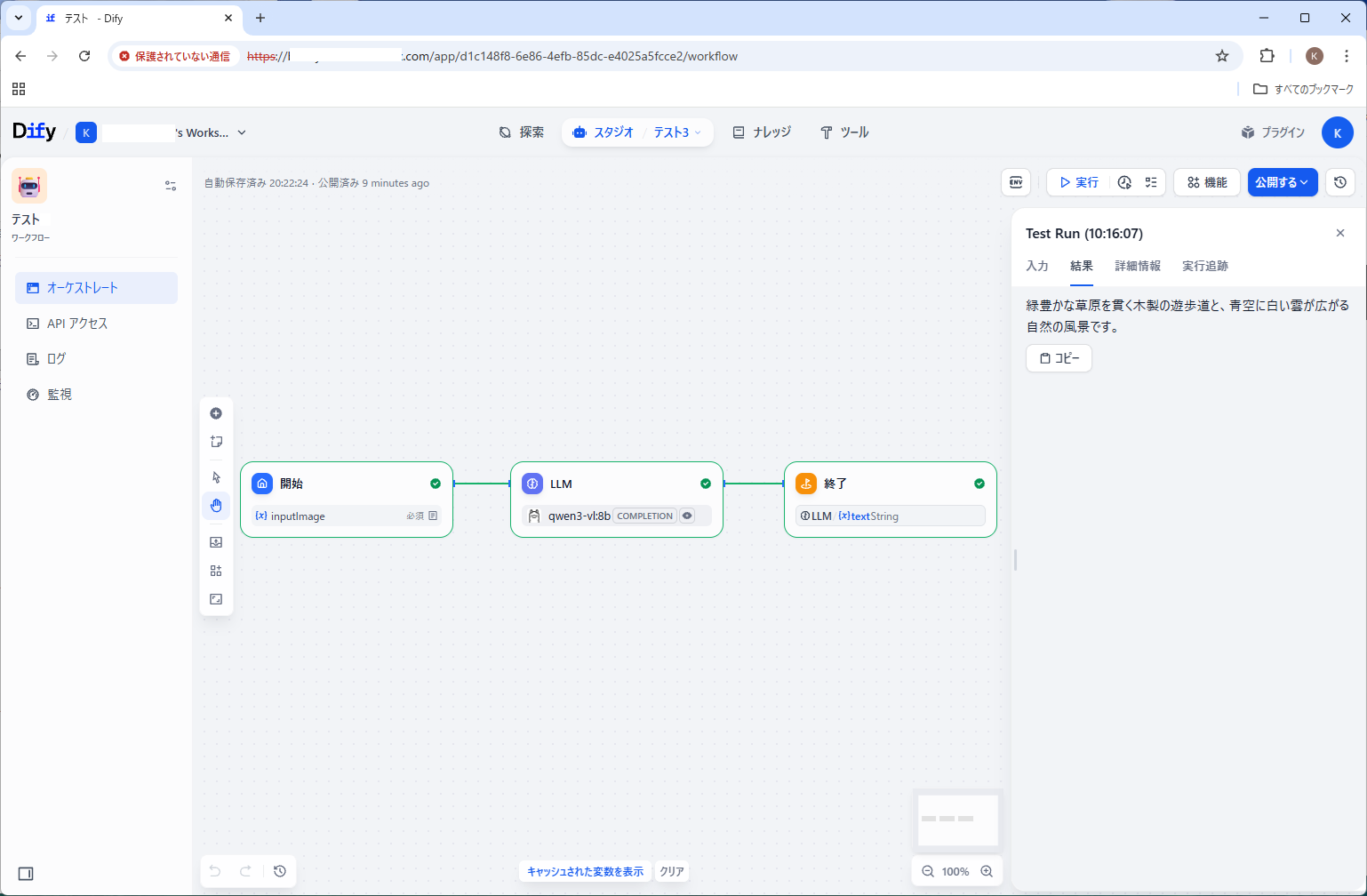
スタジオ、最初から作成、ワークフロー
[開始]
入力フィールドを追加
単一ファイル(file)
※ フィールドタイプは他に、短文(string)、段落(string)、選択(string)、数値(number)、チェックボックス(boolean)、ファイルリスト(array[file])があります
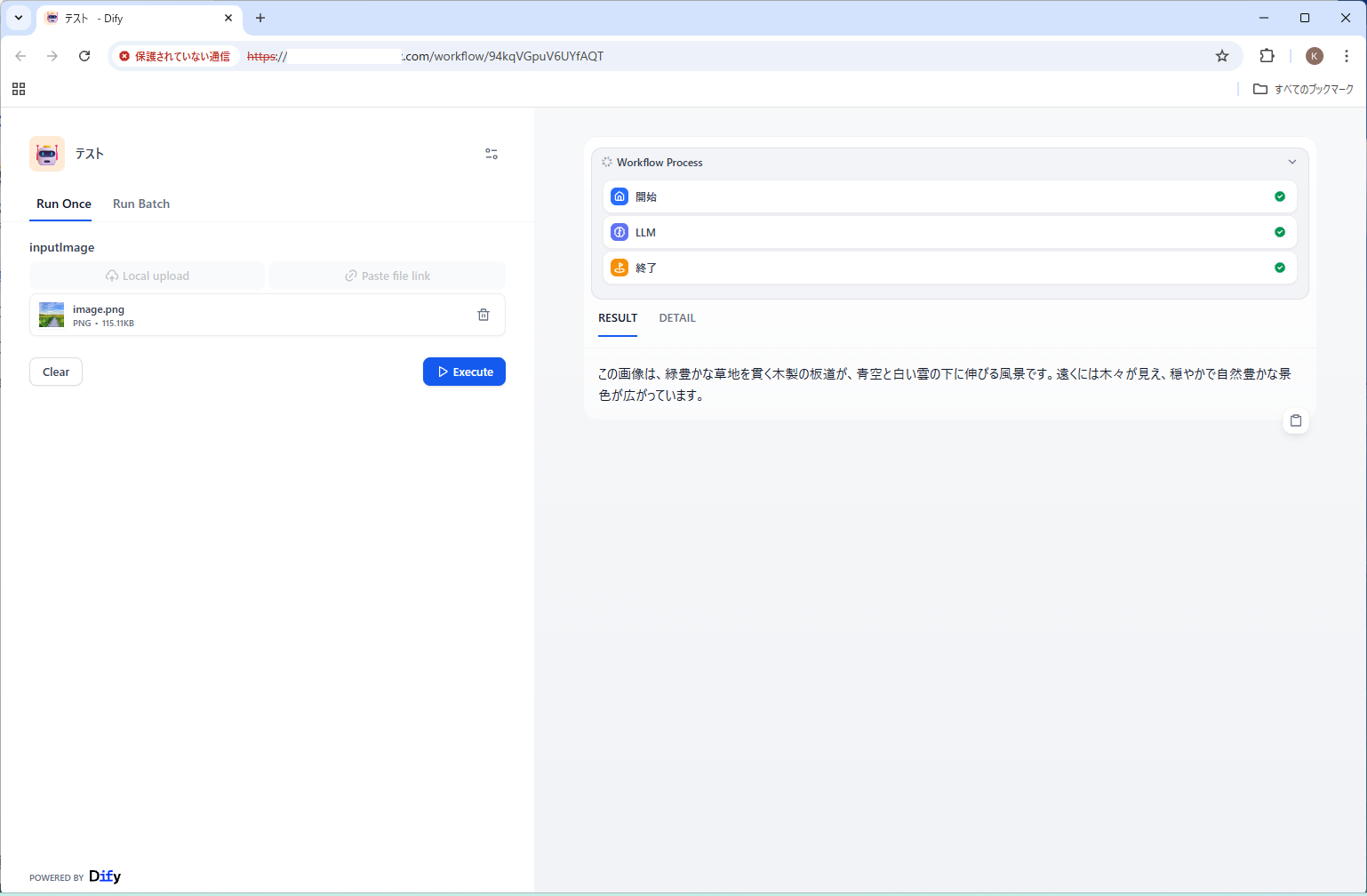
inputImage
画像
ローカルアップロードとURLの両方
必須
[LLM]
モデル: qwen3-vl:8b
ビジョン: inputImage
プロンプト:「この画像は何ですか?日本語で答えてください。」
※ コンテキストは無しで良い
[終了]
出力変数: outputText、LLM / {x} text String
結果:
緑豊かな草原を貫く木製の遊歩道と、青空に白い雲が広がる自然の風景です。

https://upload.wikimedia.org/wikipedia/commons/thumb/d/dd/Gfp-wisconsin-madison-the-nature-boardwalk.jpg/2560px-Gfp-wisconsin-madison-the-nature-boardwalk.jpg