はじめに
LangChain を使用して、次の機能を実行します。
- プロンプトテンプレート
- 会話履歴の扱い
- データベース連携(RAG)
- チャットボット
cheerio を利用してウェブページを読み込み、情報源としています。
本文では、LangChain の機能に含まれる会話スレッドとエージェントは行っていません。
Ubuntu に JavaScript (Node.js) をインストール
使用した環境: Windows 11、WSL2 の Ubuntu 22.04
sudo apt update
sudo apt install nodejs
バージョンの確認(.exit を入力すると node を終了します)
node
Welcome to Node.js v12.22.9.
Type ".help" for more information.
>.exit
デフォルトでインストールされるバージョンが古いため、nvm を使用して Node.js をバージョンアップします。
nvm インストール(リンク先の Install & Update Script のコマンドを実行します)
https://github.com/nvm-sh/nvm#install--update-script
nvm ls-remote
nvm install 20.18.1
バージョンの再確認
node
Welcome to Node.js v20.18.1.
Type ".help" for more information.
>.exit
LangChain のセットアップ
作業用フォルダを作成し、そのフォルダに移動します。
mkdir /home/(username)/20241214_langchain
cd /home/(username)/20241214_langchain
Node.js にライブラリを追加
npm install --save cheerio readline-sync
npm i langchain @langchain/core
npm i @langchain/community
npm i @langchain/openai
OpenAI API と LangChain の API キーを環境変数に登録
export OPENAI_API_KEY="..."
export LANGCHAIN_TRACING_V2="true"
export LANGCHAIN_API_KEY="..."
以下の1番簡単なサンプルプログラムが動作することを確認します。コンソールで「node ファイル名」を入力するとプログラムが実行されます。
node 01_SimpleLLM.mjs
Build a Simple LLM Application with LCEL
https://js.langchain.com/docs/tutorials/llm_chain
import { ChatOpenAI } from "@langchain/openai";
import { HumanMessage, SystemMessage } from "@langchain/core/messages";
const model = new ChatOpenAI({ model: "gpt-4o-mini" });
const messages = [
new SystemMessage("Translate the following from English into Italian"),
new HumanMessage("hi!"),
];
// SystemMessage:以下を英語からイタリア語に翻訳してください
// HumanMessage:hi!
const response = await model.invoke(messages);
console.log(response.content);
// AIMessage:Ciao!
LangChain の実行
下記の「02_LangChain.mjs」が、LangChain を実行するプログラムです。
OpenAI API を使用します。LangChain では Google Gemini、Microsoft Azure、Amazon AWS、Anthropic Claude などに簡単に切り替えることが可能です。
まず、質問への回答元となる情報源(コンテンツ)を、ウェブページから読込みます。gpt-4o-mini は2023年10月時点までの情報しか持っていないため(カットオフ)、最新の情報や優先的に扱いたい自社の情報を追加します。
プログラムは ChatGPT で使用するようなプロンプトを作成します。LangChain を使用しているので、
- システムメッセージ
- 情報源
- 会話履歴
- ユーザー質問
が OpenAI API に送信されます。ここで、会話履歴は(内部的に)毎回 OpenAI API に送信する必要があります。これを行わないと、引き続きの対話になりません。
RAG(データベース連携)は、ユーザーの質問に対して、事前に準備されたデータベースを検索し、見つかった情報(コンテンツ、記事)をユーザーの質問に追加したうえで ChatGPT に問合せる仕組みです。
「以下の記事を使用して質問に答えてください。答えが分からなければ『分からない』と伝えてください。」+「記事」+「ユーザー質問」
のような形になります。
プログラムは、クローリングまたはスクレイピングを行う cheerio を使用してウェブページから情報を取得します。その後、LangChain の機能を利用して、記事を1000文字ごとに区切りつつ、各区切りで200文字を重複させて分割し、ベクトルデータベースに登録します。英語だと良く動作するのかもしれませんが、日本語では章や節ごとに区切って意味のあるデータを持ったほうが良いかもしれません。
LangChain は、OpenAI API の Embedding 機能を使用して、与えられた文章や記事を1536個の数値パラメータに変換します(1536 次元ベクトル、text-embedding-3-small モデル、埋め込み)。変換されたデータは、PCメモリ上またはどこかのベクトルデータベースに保存します。検索時には、ベクトルの類似性を計算してデータを検索します。
参考:https://cookbook.openai.com/examples/question_answering_using_embeddings
データベース検索を行う際、ユーザーの質問に「それ」や「この」などの表現が含まれていると、クエリの結果として正しい答えが返って来ない可能性があります。LangChain の機能を使用すると、自動的に ChatGPT に問合せて会話履歴の中から、「それ」や「この」を具体的な内容に置き換えて、補完された質問を作成してくれます。
「会話履歴がなくても理解できる、独立した質問を作成してください。質問に答えてはいけません。」
のような形になります。回答はデータベース検索のために使用されるものであり、最終的に ChatGPT に送信される問合せ内容は「会話履歴」+「(元の)ユーザー質問」となります。
プログラムは while 文を使用して繰り返し処理を行い、ユーザーからの質問を受け付けて回答します。「exit」を入力すると終了します。
node 02_LangChain.mjs
import { ChatOpenAI, OpenAIEmbeddings } from "@langchain/openai";
import { CheerioWebBaseLoader } from "@langchain/community/document_loaders/web/cheerio";
import { RecursiveCharacterTextSplitter } from "langchain/text_splitter";
import { MemoryVectorStore } from "langchain/vectorstores/memory";
import { ChatPromptTemplate, MessagesPlaceholder } from "@langchain/core/prompts";
import { createRetrievalChain } from "langchain/chains/retrieval";
import { createStuffDocumentsChain } from "langchain/chains/combine_documents";
import { createHistoryAwareRetriever } from "langchain/chains/history_aware_retriever";
import { HumanMessage, AIMessage } from "@langchain/core/messages";
import readlineSync from "readline-sync";
// OpenAI API を使用
const llm = new ChatOpenAI( { model: "gpt-4o-mini", temperature: 0 } ); // temperature=0 は質問が同じならばいつも同じ回答を返す
// コンテンツの読込み
const loader = new CheerioWebBaseLoader( "https://lilianweng.github.io/posts/2023-06-23-agent/" );
const docs = await loader.load();
const textSplitter = new RecursiveCharacterTextSplitter({
chunkSize: 1000,
chunkOverlap: 200
});
const splits = await textSplitter.splitDocuments(docs);
const vectorstore = await MemoryVectorStore.fromDocuments( splits, new OpenAIEmbeddings() );
const retriever = vectorstore.asRetriever();
// システムテンプレート
const systemPrompt =
"You are an assistant for question-answering tasks. " +
"Use the following pieces of retrieved context to answer " +
"the question. If you don't know the answer, say that you " +
"don't know. Use three sentences maximum and keep the " +
"answer concise." +
"\n\n" +
"{context}";
// あなたは質問応答タスクのためのアシスタントです。以下の提供された
// コンテンツを使用して質問に答えてください。答えが分からない場合は、
// 分からないと伝えてください。最大で3文以内に簡潔に答えてください。
// RAG で使用するために、会話履歴を利用して最新の質問を補完するためのプロンプト
const contextualizeQSystemPrompt =
"Given a chat history and the latest user question " +
"which might reference context in the chat history, " +
"formulate a standalone question which can be understood " +
"without the chat history. Do NOT answer the question, " +
"just reformulate it if needed and otherwise return it as is.";
// チャット履歴と、チャット履歴の文脈を参照している可能性がある最新の
// ユーザーの質問をもとに、チャット履歴なしでも理解できる独立した質問
// を作成してください。質問に答えてはいけません。必要に応じて再構成し、
// それ以外の場合はそのまま返してください。
const contextualizeQPrompt = ChatPromptTemplate.fromMessages([
["system", contextualizeQSystemPrompt],
new MessagesPlaceholder("chat_history"),
["human", "{input}"],
]);
const historyAwareRetriever = await createHistoryAwareRetriever( { llm, retriever, rephrasePrompt: contextualizeQPrompt } );
const qaPrompt = ChatPromptTemplate.fromMessages([
["system", systemPrompt],
new MessagesPlaceholder("chat_history"),
["human", "{input}"],
]);
const questionAnswerChain = await createStuffDocumentsChain( { llm, prompt: qaPrompt } );
const ragChain = await createRetrievalChain( { retriever: historyAwareRetriever, combineDocsChain: questionAnswerChain } );
let chatHistory = [];
// メインループ
(async () => {
console.log("Welcome to the chatbot! Type 'exit' to quit.");
while (true) {
const userInput = readlineSync.question("\nYour question: ");
if (userInput.toLowerCase() === "exit") {
console.log("Thank you for using the chatbot. Have a great day!");
break;
}
const output = await ragChain.invoke({
input: userInput,
chat_history: chatHistory,
});
chatHistory = chatHistory.concat([
new HumanMessage(userInput),
new AIMessage(output.answer),
]);
console.log(output.answer);
}
})();
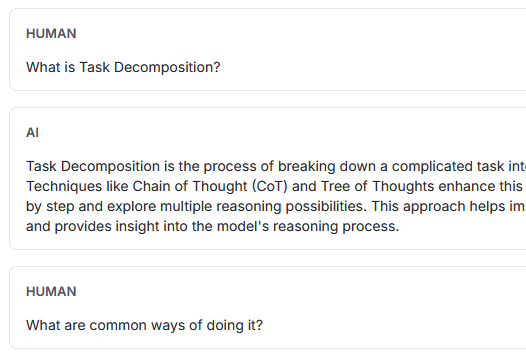
// 入力例1:What is Task Decomposition?
// 入力例2:What are common ways of doing it?
実行結果
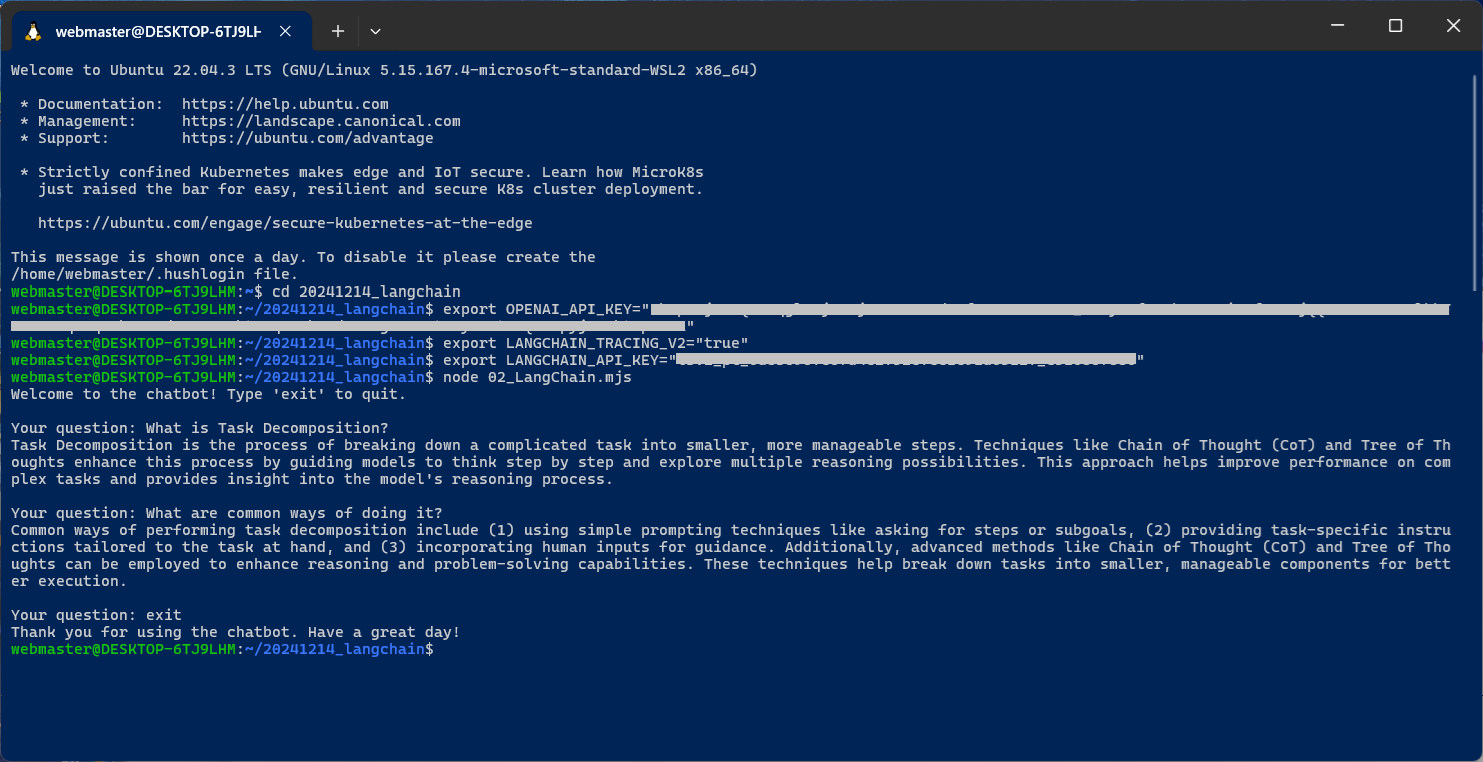
実行後、何が行われたのかを LangChain のウェブページで確認できます。
https://www.langchain.com/
Home > Tracing projects > default > Runs
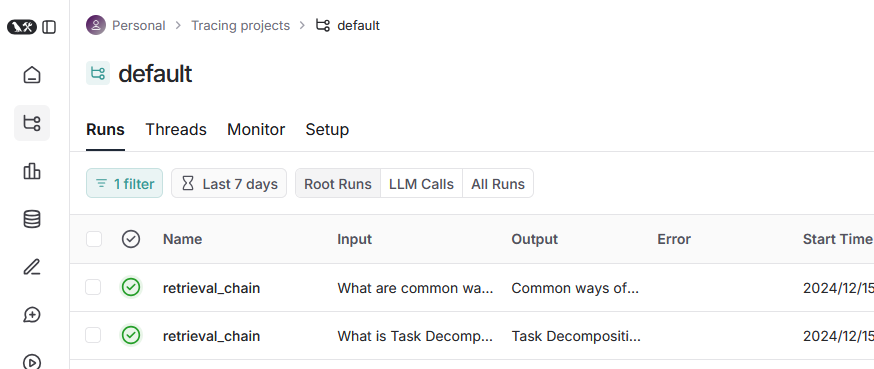
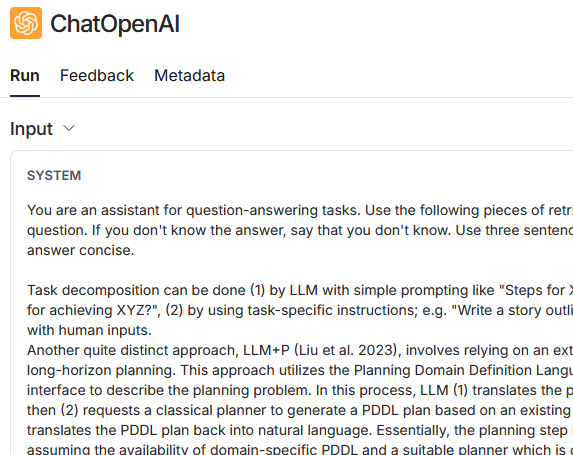
1回目の問合せでは、コンテンツの内容を追加したシステムメッセージとユーザーの質問を使用して、OpenAI に問合せ(ChatOpenAI)を行います。コンテンツの検索(VectorStoreRetriever)では、ユーザーが入力した文章がそのまま使用されています。
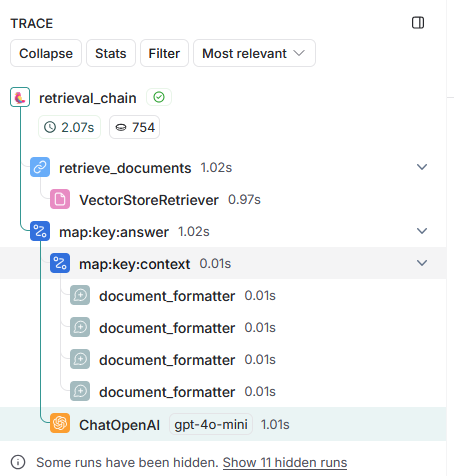
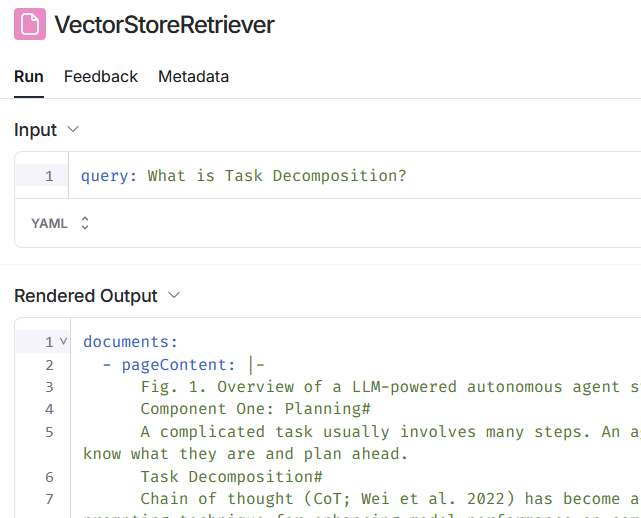


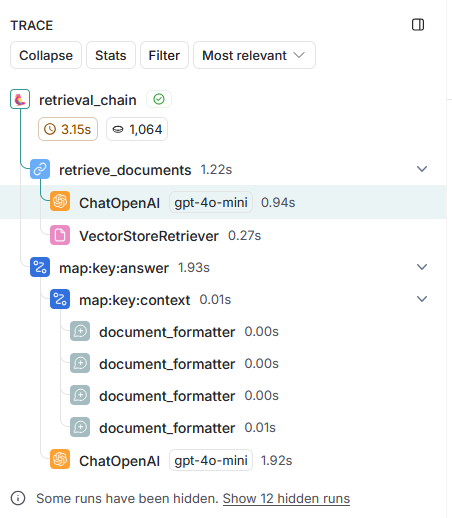
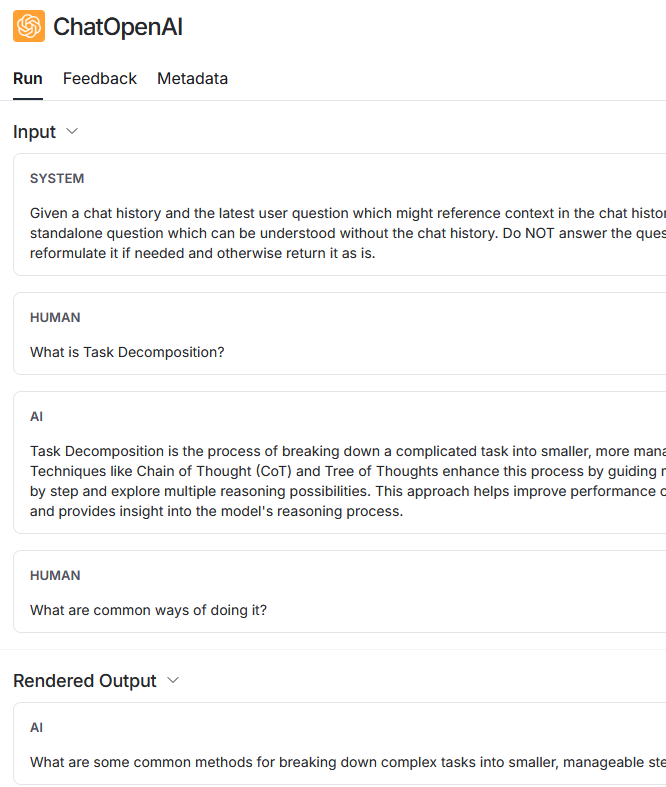
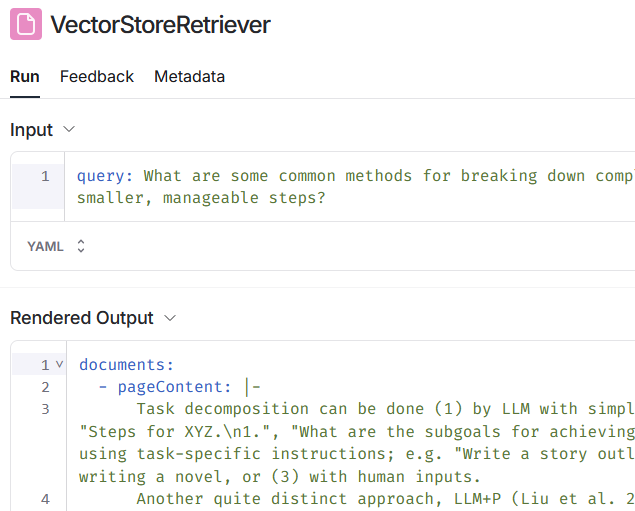
2回目の問合せでは、実際には OpenAI への問合せ(ChatOpenAI)が2回行われています。最初に、会話履歴を利用して最新の問合せを補完します。 そして、補完された文章を使用してコンテンツを検索(VectorStoreRetriever)します。
補完前:
What are common ways of doing it?
補完後:
What are some common methods for breaking down complex tasks into smaller, manageable steps?
次に、コンテンツの内容を追加したシステムメッセージ(会話履歴を含む)とユーザーの質問を使用して、OpenAI に問合せを行います。前述の補完した文章は RAG のために使用されるものであり、OpenAI への問合せには補完前の文章がそのまま使用されています。また、会話履歴も送信されています。

Python 版
上記プログラム(Node.js、JavaScript)の Python 版です。また、input.txt に記述したテキストファイルをすべて読み込み、RAG のナレッジベースにする機能を追加しました。
(2025/8/4)短すぎる質問を複数のクエリに展開し、検索に適した形に変換する機能(MultiQueryRetriever)を追加しました。
export OPENAI_API_KEY="..."
export LANGCHAIN_TRACING_V2="true"
export LANGCHAIN_API_KEY="..."
export USER_AGENT="MyLangChainBot/1.0 (contact: your-email@example.com)"
python 03_LangChain.py
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
from langchain_community.document_loaders import TextLoader
from langchain_community.vectorstores import FAISS
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.prompts import ChatPromptTemplate, MessagesPlaceholder, PromptTemplate
from langchain.chains import create_history_aware_retriever, create_retrieval_chain
from langchain.chains.combine_documents import create_stuff_documents_chain
from langchain_core.messages import HumanMessage, AIMessage
import sys
# OpenAI API を使用
llm = ChatOpenAI(model="gpt-4o", temperature=0)
embeddings = OpenAIEmbeddings(model="text-embedding-3-large")
# コンテンツの読込み
docs = []
with open("input.txt", "r", encoding="utf-8") as f:
paths = [line.strip() for line in f if line.strip()]
for path in paths:
loader = TextLoader(path, encoding="utf-8")
loaded_docs = loader.load()
docs.extend(loaded_docs)
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000,
chunk_overlap=200
)
splits = text_splitter.split_documents(docs)
vectorstore = FAISS.from_documents(splits, embeddings)
#retriever = vectorstore.as_retriever(search_kwargs={"k": 4}) # TopK 指定
retriever = vectorstore.as_retriever()
# システムテンプレート
system_prompt = (
"You are an assistant for question-answering tasks. "
"Use the following pieces of retrieved context to answer "
"the question. If you don't know the answer, say that you "
"don't know. Use three sentences maximum and keep the "
"answer concise.\n\n"
"{context}"
)
# あなたは質問応答タスクのためのアシスタントです。以下の提供された
# コンテンツを使用して質問に答えてください。答えが分からない場合は、
# 分からないと伝えてください。最大で3文以内に簡潔に答えてください。
# RAG で使用するために、会話履歴を利用して最新の質問を補完するためのプロンプト
contextualize_q_system_prompt = (
"Given a chat history and the latest user question "
"which might reference context in the chat history, "
"formulate a standalone question which can be understood "
"without the chat history. Do NOT answer the question, "
"just reformulate it if needed and otherwise return it as is."
)
# チャット履歴と、チャット履歴の文脈を参照している可能性がある最新の
# ユーザーの質問をもとに、チャット履歴なしでも理解できる独立した質問
# を作成してください。質問に答えてはいけません。必要に応じて再構成し、
# それ以外の場合はそのまま返してください。
contextualize_q_prompt = ChatPromptTemplate.from_messages([
("system", contextualize_q_system_prompt),
MessagesPlaceholder("chat_history"),
("human", "{input}")
])
history_aware_retriever = create_history_aware_retriever(llm=llm, retriever=retriever, prompt=contextualize_q_prompt)
qa_prompt = ChatPromptTemplate.from_messages([
("system", system_prompt),
MessagesPlaceholder("chat_history"),
("human", "{input}")
])
question_answer_chain = create_stuff_documents_chain(llm=llm, prompt=qa_prompt)
rag_chain = create_retrieval_chain(retriever=history_aware_retriever, combine_docs_chain=question_answer_chain)
chat_history = []
# 短すぎる質問を複数のクエリに展開し、検索に適した形に変換する(MultiQueryRetriever)
multi_query_prompt = PromptTemplate(
input_variables=["question"],
template=(
"You are an AI language model assistant. Your task is to generate five "
"different versions of the given user question to retrieve relevant documents from a vector "
"database. By generating multiple perspectives on the user question, your goal is to help "
"the user overcome some of the limitations of the distance-based similarity search. "
"Provide these alternative questions separated by newlines. Please speak in Japanese."
"Original question: {question}"
)
)
# あなたは AI 言語モデルのアシスタントです。あなたのタスクは、与えられたユーザーの質問に対して、
# 5つの異なるバージョンを作成するとことです。これらはベクトルデータベースから関連文書を取得する
# ために使用されます。ユーザーの質問を複数の観点から言い換えることで、距離ベースの類似検索に
# おける一部の制約を克服できるよう支援します。これらの代替質問を改行で区切って提示してください。
# 日本語で出力してください。
# メインループ
print("Welcome to the chatbot! Type 'exit' to quit.")
while True:
user_input = input("\nYour question: ").strip()
if user_input.lower() == "exit":
print("Thank you for using the chatbot. Have a great day!")
break
# 入力が短すぎる場合は複数クエリに展開
history_length = sum(len(message.content) for message in chat_history)
if (len(user_input) + history_length) < 70:
expanded = llm.invoke(multi_query_prompt.format(question=user_input)).content
expanded_query = " ".join(q.strip("-• ").strip() for q in expanded.split("\n") if q.strip())
print(f"[Expanded Query]({len(user_input)}) {expanded_query}")
query_input = expanded_query
else:
query_input = user_input
output = rag_chain.invoke({
"input": query_input,
"chat_history": chat_history
})
answer = output["answer"]
chat_history.extend([
HumanMessage(content=query_input),
AIMessage(content=answer)
])
print(answer)
# 入力例1:What is Task Decomposition?
# 入力例2:What are common ways of doing it?
参考ページ:
Build a Chatbot
https://js.langchain.com/docs/tutorials/chatbot
Conversational RAG
https://js.langchain.com/docs/tutorials/qa_chat_history