- Python の gensim というライブラリを使って、Twitter のツイートの分類にチャレンジしました。
- -> GitHub のリポジトリ
動機
短文の分類をしたかった
- もともと演劇の台本を構造化する事に興味があり、各行を「セリフ行」や「ト書き行」に分類する方法を模索していました。
自分でデータセットを作りたかった
- 誰かが用意したデータセットでなく、自分で収集したデータを使っても予測モデルが作れるのか、試したかったのです。
教師なし学習をしたかった
- 自分で集めたデータセットに教師ラベルをつけるのが大変だと思ったので。
課題設定
- データセットは、たくさんのツイートを収集して作る。
- 分類のためのトピックモデルを作る (教師なし学習)。
-
トピックモデルをチューニングする。
- 「分類できた」と言える状態に持っていく。
- 余力があれば、ツイートの分類結果を使ってユーザを分類する。
トピックモデルについて
- 文書に潜んでいる "トピック" を予測するモデルです。
- "トピック" とは簡単にいうと「何について言っているか」という事です。
- 1つの文書に複数のトピックが潜んでいます。
- 教師なし学習の場合は、どういうトピック種別があるかは、学習する過程で (単語の出現確率などによって) 決まってゆきます。
- (参考) 自然言語処理による文書分類の基礎の基礎、トピックモデルを学ぶ
LDA モデル
- トピックモデルの一種です。
- ベイズ推定によって、直接的な単語を持たない文書のトピックも予測できるそうです。
- 短文の分類に向いているのではないかと思いました。
- (参考) トピックモデル(LDA)で初学者に分かりづらいポイントについての解説
準備
Twitter App
- Twitter の API を使えるように、アプリケーションを登録しておきます。
- (参考) PHP + OAuthで Twitter botをつくってみよう - PHP入門 - Webkaru
Python のライブラリ
- 以下のライブラリをインストールします。
-
Tweepy
- Twitter API にアクセスするために使います。
-
PyMongo
- MongoDB にアクセスするために使います。
-
Janome
- 形態素解析に使います。
-
gensim
- トピックモデルを簡単に生成できます。
-
Tweepy
- これらは、GitHub のリポジトリをクローン/ダウンロードした方は
pipenv syncすればインストールできます。 - 使ったバージョンについては、Pipfile.lock を御覧ください。
実行環境
-
VSCode
- Python 拡張を入れることで、.py ファイルをインタラクティブに実行できます。
- Windows で作業したので、Explorer から VSCode でフォルダを開けるようにしました。
- フォルダを開いたら自動的に .venv フォルダを見に行くようにしました。
- (参考) VSCode で相対パスの仮想環境を使う
DB
-
MongoDB
- 取得したツイートを JSON 形式のまま保存したり、後で簡単にフィールドを足したりできるので使いました。
- 使ったバージョンは
4.0.9です。
やったこと
システム構成
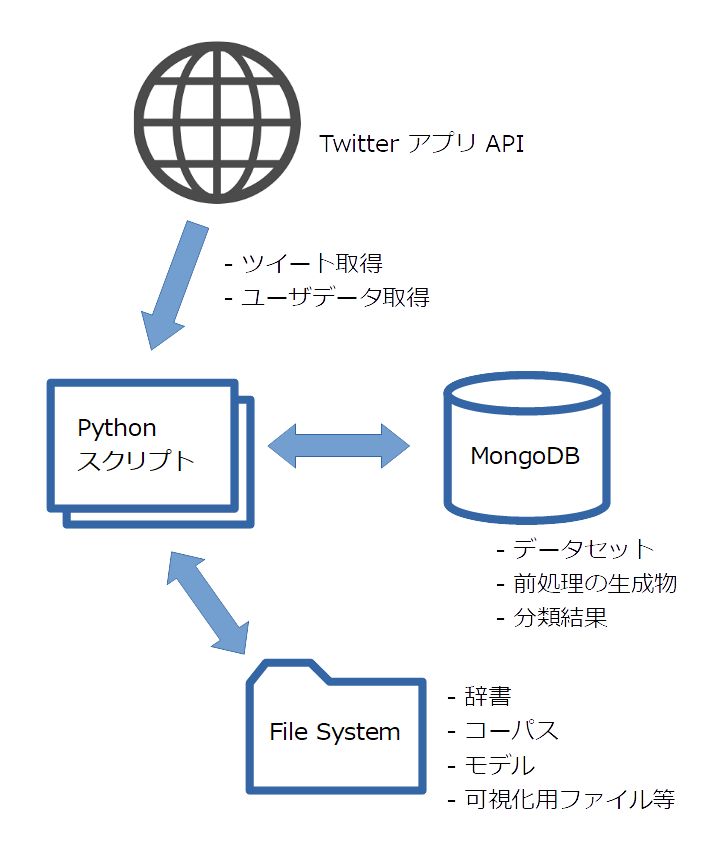
- 各スクリプトの役割や使い方については、docs/operation.md にまとめてあります。
サンプルツイートの取得
- Twitter の API からツイートを取得して、データセットとして MongoDB に保存します。
- これをしているスクリプトは、retrieve_tweets.py です。
- なるべく無作為に取得したかったのですが、何らかの検索をして取得することになるので、適当な検索ワードを入れてあります。
q = 'です OR ます OR でした OR ました OR でしょう OR ましょう'
- ツイートを取得しているのは以下の行です。
for results in twconn.search(q, since_id=since_id, pages=1000):
-
twconnは TwConn (という Tweepy のラッパークラスを作りました) のオブジェクトです。 -
TwConn.search()は、ツイートの取得を繰り返すジェネレータです。-
pagesが繰り返しの回数です。 - デフォルトでは1回につき15ツイートを取得するようです (
pages=1000ならトータルで15000ツイート)。
-
- 取得したツイートを MongoDB に保存しているのは以下の行です。
ins_result = col_twsamples.insert_many(results)
-
col_twsamplesは PyMongo の Collection (SQLDB のテーブルに相当するもの) を扱うオブジェクトです。 - retrieve_tweets.py は、繰り返し実行すれば新しいツイートを DB に追加していくようになっています。
形態素解析
- 保存したデータセットに、
wordsというフィールドを追加しつつ、形態素解析の結果を持たせます。 - これをしているスクリプトは tokenize_tweets.py ですが、具体的な処理は lib/mongo_util.py の中の
add_tokenized_words()メソッドでやっています。 - 形態素解析の前にツイートから、'RT', mention, URL をノイズとして取り除いています。
import re
(中略)
# ノイズとして取り除くパターン
rt = re.compile(r'^RT\s*')
mention = re.compile(r'\s*@\w+:\s*')
url = re.compile(r'\s*https?://[\w/:%#\$&\?\(\)~\.=\+\-]+\s*')
(中略)
# ノイズ除去
text = rt.sub('', text)
text = mention.sub(' ', text)
text = url.sub(' ', text)
- また (これを書いている時点では) 名詞のみ (代名詞以外) を保存しています。
# Model_04 ~ 代名詞でない名詞のみ抽出
words = [tk.base_form for tk in t.tokenize(text)
if tk.part_of_speech.split(',')[0] == '名詞'
and tk.part_of_speech.split(',')[1] != '代名詞']
-
tは Janome の Tokenizer です。
辞書とコーパスの作成
- モデルを鍛えるのに辞書とコーパスが必要なので、上で作った単語列から生成します。
- これは gensim のメソッドで可能です。
- 訓練データを選べる方が良いので、ランダムで選んでマークをつけるスクリプトを作りました (mark_training_data.py)。
- 選ばれた訓練データから辞書とコーパスを作るスクリプトは extract_training_data.py です。
- コード内の「モデル番号」とは、モデルごとのデータを保存するフォルダ名です。その名前のサブフォルダをあらかじめ作っておきます。
- 辞書を作るのに、gensim.corpora.dictionary.Dictionary の filter_extremes() メソッドを使っています。
from gensim import corpora
from lib.mongo_util import StreamWords
(中略)
# サンプルツイートから単語列を取得するイテラブル
stream = StreamWords(col_twsamples, 'words')
# 辞書作成
dict = corpora.Dictionary(stream.words_from_col(ids))
dict.filter_extremes(no_below=no_below, no_above=no_above)
(中略)
dict.save(dict_file_name)
| 2022-03-31 追記 |
|---|
| "dict" は組み込み型のコンストラクタなので、変数名に使うべきではありません。 |
-
StreamWords.words_from_col()は、ストップワードを除外した単語列を DB から取得するジェネレータです (lib/mongo_util.py)。 - 引数として渡している
idsは選ばれた訓練データのidのリストで、あらかじめ DB から取得しています (取得の仕方はコードを御覧ください)。 -
filter_extremes() メソッドに渡している
no_below,no_aboveは、頻繁に出現する単語や滅多に出現しない単語を無視するためのパラメタです。 - 辞書をテキスト型でセーブすれば、内容を確認することができます。
dict.save_as_text(dict_name + '.txt')
470 いかが 187
92 いっぱい 130
542 いつか 112
315 おかげ 138
63 おすすめ 141
564 お世話 196
246 お互い 154
460 お客様 123
201 お待ち 462
531 お気 106
- 辞書の ID を使って単語列を書き直したものがコーパスです。
- これは gensim.corpora.dictionary.Dictionary の doc2bow() メソッドで作れます。
# コーパス作成 & 保存
corpus_file_name = corpus_name + '.txt'
with open(corpus_file_name, 'w') as f:
for words in stream.words_from_col(ids):
print(dict.doc2bow(words), file=f)
[(0, 1), (1, 2), (2, 1), (3, 2), (4, 1), (5, 1), (6, 1)]
[(7, 1), (8, 1), (9, 1), (10, 1), (11, 1), (12, 1)]
[(13, 1), (14, 1), (15, 1)]
[(14, 1), (16, 1), (17, 2), (18, 1), (19, 1), (20, 1), (21, 1), (22, 1), (23, 1)]
[]
[(24, 1)]
[(25, 1), (26, 1)]
[(27, 1), (28, 1)]
[(29, 1), (30, 1)]
[(31, 1), (32, 1)]
LDA モデルの作成
- 辞書とコーパスを使って、LDA モデルを作成します。
- これをしているスクリプトは make_model.py です。
- LDA モデルの作成には gensim.models.ldamodel.LdaModel を使っています。
# 辞書とコーパスの読み込み
dict = corpora.Dictionary.load(dict_file_name)
corpus = StreamCorpus(corpus_file_name)
# モデルの作成と保存
model = models.LdaModel(
corpus=corpus, id2word=dict, num_topics=num_topics, alpha='auto')
model.save(model_name)
- 主なパラメタは
num_topicsとalphaです。- num_topics : トピック種別の数
- alpha : トピック種別の分布
-
LdaMulticore というマルチプロセッサで動くモジュールもありますが、それだと
alpha='auto'が指定できません。- 'auto' だとコーパスの内容によって適切な分布を決めてくれるようです。
- チューニングのために、モデル内でのトピックの定義を見るためのスクリプトを作りました (print_model_topics)。
分類
- とりあえず、LDA モデルを作成するのに使った訓練データ (5万件) を分類してみます。
- 1つの文書に複数のトピックが潜んでいますが、構成比が最大のものをその文書のトピックとします。
- これをしているスクリプトは cluster_training_data.py です。
- 処理は以下の2ステップになっています。
-
分類
- 各ツイートのトピック構成比を LDA モデルで予測し、「構成比が最大のトピックの ID」と、その構成比を DB に記録する。
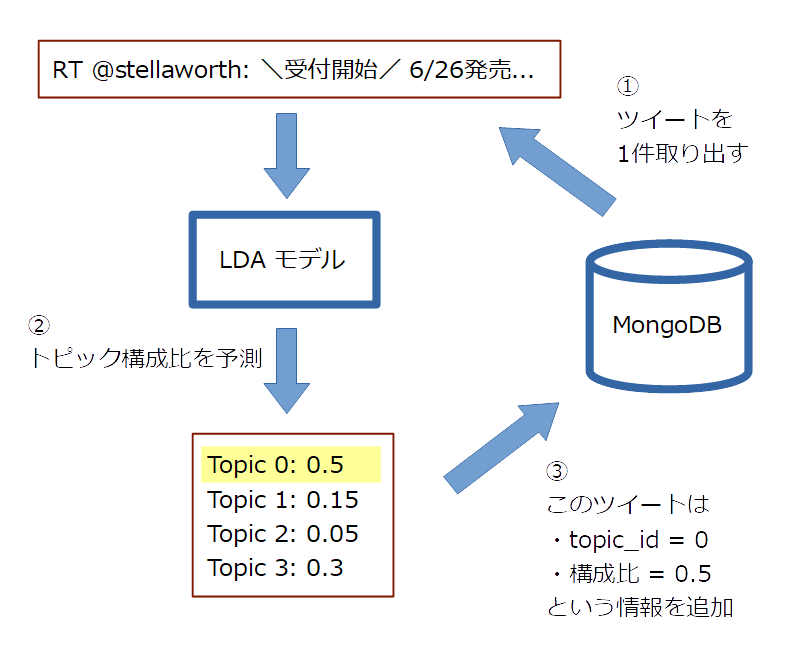
-
可視化
- DB からトピック ID ごとにツイートを取り出して、ファイルに書き出す。この時、予測された構成比が大きい順に並べる。
-
分類
- ファイルに書き出すところでメモリ不足のエラーが出るかも知れません。DB の
topic_probフィールドでソートしている事が原因なら、インデックスを追加してやりなおします。
col_twsamples.create_index([('topic_prob', DESCENDING)])
チューニング
- 以下のようなチューニングをして、モデルを改良していきました。
- ストップワードを追加した。
- モデルを作る時の
alphaをデフォルトのasymmetricからautoに変えた。 - 辞書に載せる言葉を名詞に限定した (ただし代名詞以外)。
- 重複するリツイートを取り除いてデータセットを作った。
- それをするスクリプトは gen_text_only.py です。
- 辞書を作る時の
no_belowを大きくした (20 -> 100)。 - 辞書を作る時の
no_aboveを小さくした (0.2 -> 0.1)。 - num_topics を小さくした (8 -> 4)。
評価指標
- モデルを評価する指標として、Coherence と KL-divergence を使いました。
-
Coherence
- トピックの特徴となる単語にどれくらい一貫性があるかを示します。
- モデルを評価する際には、全トピックの平均をとりました。
- (参考) - gensimのLDA評価指標coherenceの使い方
-
KL-divergence
- KL-divergence は、トピック間の距離のような概念です (非対称なので「距離」という言い方は間違いとも言われます)。
- モデルを評価する際には、2個のトピックを選ぶ全組み合わせについて KL-divergence を求め、平均をとりました。
- (参考) カルバック・ライブラー情報量
- (参考) gensim.matutils.kullback_leibler()
-
Coherence
- この2つを算出・可視化しているスクリプトは eval_model.py です。
# Coherence の平均を求める (抜粋)
tps = model.top_topics(corpus=corpus)
c_mean = mean([tp[1].astype(float) for tp in tps ])
# KL-divergence の平均を求める (抜粋)
t = model.state.get_lambda()
ds = []
for i in range(model.num_topics):
for j in range(model.num_topics):
if i != j:
kl = kullback_leibler(t[i], t[j])
ds.append(kl)
d_mean = mean([d.astype(float) for d in ds])
- この2つの指標は、上記のチューニングをした結果、以下のように変化しました。

- 結局これらはあまり参考にせず、分類結果を見て自分で「分類できた」と言えるかどうかを判断しました。
- チューニングの過程については、docs/tuning_history.md にまとめてあります。
分類結果
- 7番目に作ったモデルで「分類できた」と思えたので、その結果を抜粋して掲載します。
- すべての出力はこちら。
- 各トピックについて、予測された構成比が大きかったものから順に10件ずつ抜粋しています。
- これらは訓練データをそのまま分類したものですが、別のデータセット (5万件) についても同様の結果が得られました。
- その出力はこちら。
- 括弧内は私が名付けたトピック種別名です。
トピック 0 (告知・イベント系)
0.9481092095375061 RT @stellaworth: \受付開始/ 6/26発売予定CD「天下統一恋の乱LoveBallad ドラマCD~俺とお前の絆語り~其の二 信長×光秀」のご予約受付を開始致しました! ステラワース特典【ドラマCD「一緒にお風呂!?」の巻】付き! 出演:小野大輔/置鮎龍太郎…
0.9310030341148376 RT @CabbitOfficial: Cabbit最新作「鍵を隠したカゴのトリ」がついに来週の金曜日、5月31日からご予約解禁!予約特典とか店舗特典とか楽しみですか?楽しみですよね?素敵なイラストいっぱいです!あと少しだけお待ちくださいね! #カギトリ https://t.c…
0.9296544194221497 RT @saikoro1to3: 【バトルスピリッツ予約受付】 8月31日発売予定 バトルスピリッツ コラボブースター 「仮面ライダー 新世界への進化」 予約価格6000円(税込み) 予約締切6月4日まで 皆様のご予約お待ちしております! ※初めてご予約される方は店頭にて前…
0.9280203580856323 RT @side_connection: 『恋姫†礼舞 KOIHIME LIVE2019』 開催日:2019年11月9日(土) 会 場:山野ホール サイドコネクションが制作・運営で参加いたします! 7月26日発売予定の『真・恋姫†夢想-革命- 劉旗の大望』にイベント最速先行…
0.9267843961715698 RT @comic_cune: 「あやかしこ」コミックス最新第6巻は5月23日(木)発売!ドラマCD付き特装版も当時発売です! ☆店舗特典一覧公開しました! #あやかしこ ⇒ https://t.co/xMfOstVcli https://t.co/Fu6OqowR76
0.9241254329681396 RT @oxgakuox: 東海テレビ #スイッチ ご覧いただきありがとうございました! 沢山の手紙も感謝! 明日はいよいよ #大人の土ドラ #仮面同窓会 初回スタートです! 是非ご覧ください♪ そして、東海テレビの前には大きな ポースターが! https://t.co/…
0.9233863949775696 RT @i_luvJ: 最後の挨拶です〜 東京のみなさま どうぞいらっしゃいました(・゚∀゚*) どうぞいらっしゃいました(;・゚∀゚;)? フフッ 赤西です なんかおかしな挨拶になっちゃって、同じ挨拶2回言って、自分でも笑っちゃったじんじんでしたー。 お疲れ様でした!…
0.9226896166801453 RT @aikoh_nico: 【お知らせ】 今週のニコ生"野良犬の穴"はお休みとなります。 来週は6/4(火)の放送となります。 通常通り、21:00放送開始です。 6/7(金)はお休みとさせていただきます。 宜しくお願い致します。
0.9222129583358765 RT @animateonline: 📢Windows用🔞ゲーム 2019年6月28日(金)発売 『Fate/stay night+hollow ataraxia 復刻版』 本日よりご予約受付開始いたしました❗️ご予約お待ちしております。 ↓ご予約↓ https://t.c…
0.9192668795585632 RT @pre_dia: 【明日!】 6/1(土)「GIG TAKAHASHI tour 2019」@新横浜NEW SIDE BEACH!!出演です🔥 prediaの出演は15:10~🎤 ※終演後特典会実施。 そしてイベント公式パンフレットの販売もございます! 特製アクリル…
トピック 1 (その他系)
0.9489241242408752 RT @irukanigohan: 最近、デマな鯨食論があり、「鯨肉がごく一部の地域のニーズ」と誤報されます. 否、「東京」や「大阪」は、歴史的な鯨食地です. お店があり、食人口が「東京で1割」と案外いて、その為にも、鯨肉が確保されています. ごく一部の地域だけの話なら、…
0.9466836452484131 RT @yuya_1243: 彼女にベタ惚れな彼氏 彼氏にベタ惚れな彼女 彼女の笑顔の為 頑張る彼氏 彼氏の事 影で支える彼女 彼女の為 立派な男になろうって彼氏 彼氏の為 日々努力する彼女 彼女の事 周りに自慢する彼氏 彼氏の事 誇りに思ってついてく彼女 こんな 想い…
0.9466820359230042 RT @onnnanolove: 彼女にベタ惚れな彼氏 彼氏にベタ惚れな彼女 彼女の笑顔の為 頑張る彼氏 彼氏の事 影で支える彼女 彼女の為 立派な男になろうって彼氏 彼氏の為 日々努力する彼女 彼女の事 周りに自慢する彼氏 彼氏の事 誇りに思ってついてく彼女 こんな…
0.9436168670654297 @homurashouken おっしゃる通りです! レアアース然り米国債(貿易赤字)問題然り、現に米国は中国にかなりの部分で頼っています。逆も然りですが。 ですので問題は覇権争い。衝突が経済国1位対10位ぐらいだったら折れる方は目に見えてますが、1位と2位ですので、選挙も見据えるとお互い譲れず長期化になりますね。
0.9395936727523804 RT @1415920: 新しい環境で働き初めて二週間くらい経ったんだけど、歳が近くて結構漫画やゲームの話をする女性社員さんと仲良くなったのでお互いの趣味の話をした。 ひぃ子「私はお人形が好きで~~~ブライスとかご存じですか?」 女性社員「ごめんわかんないや~~~」 →
0.9386203289031982 RT @kawagoemizusaki: 猫カフェ×ネカフェ「猫家 川越店」が天国すぎる!Wi-Fi利用もOK https://t.co/rqC5aPSqTC 「猫家 川越店」(@nekoyacafe)の取材記事です。猫アレルギーさえなければ私が行きたかった…(切実)!本やソフ…
0.9370874762535095 RT @amasehimika147: 合成洗剤を使わないことは、もちろん聖三活動の柱の一つ「地球清浄化活動」の最大の実践ですね。食器の汚れがひどい場合、洗う前に紙で拭くのも一つの手ですが、無添加(香料、アロマ精油等不使用)の天然石けんを使うのが一番環境に優しく最善です。地球環…
0.9344350099563599 RT @tyan_sae: 「若い人が昔の作品を好んで語りたがるのが無理してるのか承認欲求が強いのかしらないけど、不自然でイラつく。」という個人的意見のTLが流れてきたけど、 昔の作品が好きな事は悪い事なのですか?自分がリアルタイムで見ていたものが好きじゃなきゃダメですか? な…
0.9341456294059753 @new238528591 @KentoSymi 私は眞島さんと同年ですがかなり若くても全然無理です💦😅実母は美人なんですが全く似てなくて顔がまず大きくて肌も若い頃から苺鼻で💦 娘は肌も綺麗で小顔でスタイル良いのでワンちゃん考えた事あります🤣そしたら、本人が売れてもネットとかで叩かれるのが耐えられないから無理だって😆
0.9324640035629272 マルバスちゃん可愛い。※メギド72の話 元々ぶりっ子な子はあまり好きではないのだけど、今回のイベントやっていい所や弱い所とか色々見れた気がして、とても好きだったよ…!そしてお迎えしたリジェネレイトマルバスは点欠上げて戦えるって事でとても強くなりそうで嬉しいです(´ω`*)
トピック 2 (♡出会い系)
0.9630098342895508 □山梨県の落居駅周辺にいるエッチな裏垢男子情報 *5月19日 11:46頃に投稿されたエッチな詳細情報はプロフURLから見れます♥ ■淫乱な人妻はセフレ相手募集中 近頃はえろ垢の人たちによるセックスグループ(LINE)が人気なようです。
0.9630072712898254 ・福井県の勝山駅周辺にいる裏垢女子と団地妻情報 ◆6月1日 6:46頃に紹介されたHな詳細情報はプロフ欄のURLから♥ ♪ド変態な人妻はエッチの相手募集中 ここ最近はエロアカの人たちによるセックスグループ(ライン)が流行っているようです。
0.9622365832328796 □沖縄県の儀保駅周辺にいる裏垢の男性と熟女情報 *5月19日 9:06頃に追加されたえろい詳細情報はプロフのURLからアクセス❣ *ド変態な痴女はセックスの対象検索中 ここ最近は裏垢の人たちによるHなグループ(ライン)が人気なようです。
0.9619156122207642 ★群馬セフレ募集速報! 内容:☓☓が感じるM男性で、☓☓☓の開発に興味がある人を募集します。女性崇拝願望がる男性が私の好みです。 名前:♀美佳 年齢:20歳 地域:桐生市 彼女の連絡先⇒当アカウントのプロフ欄URLから詳細確認 6月1日(土)6時47分の情報です♪
0.9615198969841003 ☆高知県の香南市周辺にいる裏垢女子と人妻情報 ※6月1日 1:06頃に設定されたエロ詳細情報はプロフのURLから確認♥ ♪淫乱な人妻はセフレ対象募集中 ここ最近はえろ垢の人たちによるHなグループ(ライン)が流行りのようです。
0.9615072011947632 ♡栃木県の寺内駅周辺にいる裏垢男子と人妻情報 ♪6月1日 6:46頃に追加されたエロい詳細情報はプロフのURLから確認❣ ●ド変態な熟女は浮気対象物色中 ここ最近はエロ垢の人たちによるHなグループ(ライン)が流行りのようです。
0.9604401588439941 □北海道の大町駅周辺にいる裏垢の男性と団地妻情報 ♪6月1日 6:46頃に紹介されたエロ詳細情報はプロフ欄のリンクから見れます❤ ●ド変態な痴女はセックスの相手検索中 最近ではエロ垢の人たちによるセフレグループ(ライン)が人気なようです。
0.959851861000061 ★高知県の新改駅周辺にいる裏垢の男性と人妻情報 *6月1日 6:46頃に紹介されたエロイ詳細情報はプロフ欄URLから確認♥ ◆淫乱な若妻はセックスの対象探し中 ここ最近は裏あかの人たちによるHなグループ(LINE)が流行っているようです。
0.95981764793396 ◇裏垢男子♂(山形県新庄市周辺)情報 ♪6月1日 1:06頃に紹介されたエロイ詳細情報はプロフURLから確認❣ @ド変態な痴女も利用中 最近では裏垢の人たちによるセックスグループ(ライン)が流行しているようです。
0.9598084688186646 ◆新潟県新潟市西蒲区のエッチな裏垢男子掲示板 ※5月19日 11:46頃に書込されたエロい詳細情報はプロフのURLから確認❣ ★ド変態な人妻も利用中 近頃はエロ垢の人たちによるセックスグループ(ライン)が流行しているようです。
トピック 3 (交換・譲渡系)
0.9628610610961914 RT @327mikuuu: 【交換】うたプリ マジLOVEキングダム 缶バッジ リングライト 譲→リングライト:翔 レン 蘭丸 カミュ2 缶バッジ:翔 セシル 蘭丸 カミュ 求→同種 真斗 郵送でのお取引希望です。 検索からでもお気軽にお声がけ下さい! h…
0.9628500938415527 【交換】うたプリ マジLOVEキングダム 缶バッジ リングライト 譲→リングライト:翔 レン 蘭丸 カミュ2 缶バッジ:翔 セシル 蘭丸 カミュ 求→同種 真斗 郵送でのお取引希望です。 検索からでもお気軽にお声がけ下さい! https://t.co/QOfbDSCdZq
0.9628340005874634 RT @chamchoco1641: 【譲渡】FGO 霊基召喚缶バッジ 旅装 譲:画像 求:1.2枚目 1個300円 3枚目 1個200円 1枚目は1個につき、3枚目より3個お迎えください。2.3枚目は単品譲渡可能です。纏めて優先。宜しくお願い致します。 ht…
0.9620353579521179 RT @19rabbit01: 【交換・譲渡】ラブライブ サンシャイン 缶バッジ、ブロマイド、コースター 譲:画像のもの 求:朝香果林グッズ又は譲渡 5thの前日物販を含めて3日間での手渡しのみ 1枚目譲渡は要相談、2枚目定価、3枚目セットのみ定価 2枚目3枚目(バラ売り…
0.9614040851593018 RT @tomA3my: 【交換/譲渡】A3! キャラバッジ 譲)真澄、シトロン、天馬、椋、三角、東 求)画像2枚目幸2>画像3枚目紬幸、定価 ※上段は下段含むお取引優先 都内手渡しまたは郵送での交換が可能です。※譲渡は都内手渡しのみ 気軽にお声掛け下さい。 https…
0.9605931639671326 【譲渡/代含】刀剣乱舞 すわらせ隊8 袋予約予定 譲:今剣13、物吉22、☆山姥切長義1 求:定価+送料 連絡先の交換や予約後に先払いが可能な方のみ。 1点につき☆は今剣と物吉を各1点ずつ引き取り可能な方のみお譲り可能です。 無印は単体でお譲り可能。 リプにてご連絡下さい。 https://t.co/kDBBiAMi1q
0.9594737887382507 RT @gayakoki1105: 交換 ツキウタ。 グリコ メモリアルカード 1弾 2弾 譲)画像1枚目第一弾、2枚目第二弾 求)画像3・4枚目。 赤いのが優先。SDはSD同士で。 手渡し、横浜・都内。郵送可。 よろしくお願い致します。 検索からお気軽にどうぞ。 https:…
0.9592937231063843 RT @Ai_showtai: 【交換】うたプリ 劇場版 マジLOVEキングダム リングライト SHINING ver 譲→レン、翔、カミュ 求→同種藍 16日の舞台挨拶昼の部前手渡し優先。郵送でのお取り引きも可能です。お気軽にお声を掛けください。 https://t.c…
0.9581330418586731 【譲渡】Disney 声の王子様 Voice Stars Dream Live ディズニー 譲:6/9(日) 昼 夜の部 各2枚連番 未発券の為、座席不問の方 求: 定価のみ(8,980×2枚) お振込確認後発券番号をご連絡いたします。発券後の郵送、都内手渡しも可能です。 DM解放しておりますので、お気軽にお声がけ下さい。 https://t.co/IJsHo5xbxd
0.957792341709137 交換 譲渡 テニミュ 全国立海 【譲】 8/2 夜 2連 1枚 8/4 昼 1枚 8/9 夜 1枚 【求】 9/21 夜 2連 7/14 昼 2連 8/4 夜 1枚 定価(+送料) 発券後のお取引になります。 譲渡はキャンセル防止のため先にお振込をお願いいたします。
考察
- トピックモデルを教師なし学習する時は、トピック数をうまく決めてやることが重要みたいです。
- 分類結果を見て特徴的だと思える単語が、意外とトピックの特徴としては上の方に出ていなかったりします。
- トピックの特徴は以下のように定義されていました。
- ちなみに「交換」が出ていないのは、ストップワードにしていたからです。
(0, '0.029*"箱" + 0.024*"peing" + 0.018*"゚" + 0.018*"楽しみ" + 0.018*"回" + 0.017*"写真" + 0.015*"動画" + 0.014*"予定" + 0.014*"ライブ" + 0.013*"前" + 0.012*"是非" + 0.011*"会" + 0.011*"配信" + 0.010*"イベント" + 0.010*"一緒" + 0.010*"曲" + 0.010*"発売" + 0.010*"世界" + 0.010*"応援" + 0.009*"素敵" + 0.008*"二" + 0.008*"目" + 0.008*"予約" + 0.008*"後" + 0.008*"出演" + 0.008*"言葉" + 0.008*"先生" + 0.008*"期待" + 0.007*"元気" + 0.007*"開始" + 0.007*"大事" + 0.007*"戦" + 0.007*"達" + 0.007*"撮影" + 0.007*"お知らせ" + 0.007*"放送" + 0.007*"金" + 0.007*"水" + 0.007*"uratasama" + 0.006*"活" + 0.006*"土曜日" + 0.006*"お話" + 0.006*"愛" + 0.006*"開催" + 0.006*"めちゃくちゃ" + 0.006*"公開" + 0.006*"最近" + 0.006*"土" + 0.006*"頭" + 0.006*"感謝" + 0.006*"試合" + 0.006*"選手" + 0.006*"スタート" + 0.005*"最高" + 0.005*"ブログ" + 0.005*"意味" + 0.005*"友達" + 0.005*"恋" + 0.005*"体" + 0.005*"電話" + 0.005*"夏" + 0.005*"間" + 0.005*"子供" + 0.005*"嫌" + 0.005*"行動" + 0.005*"販売" + 0.005*"反応" + 0.005*"版" + 0.004*"アップ" + 0.004*"赤" + 0.004*"味" + 0.004*"終了" + 0.004*"バンド" + 0.004*"気持ち" + 0.004*"ご覧" + 0.004*"次回" + 0.004*"今回" + 0.004*"タイプ" + 0.004*"決定" + 0.004*"受付" + 0.004*"足" + 0.004*"タグ" + 0.004*"令和" + 0.004*"三" + 0.004*"YouTube" + 0.004*"遊び" + 0.004*"練習" + 0.004*"ママ" + 0.004*"最終" + 0.004*"限り" + 0.004*"幸せ" + 0.004*"プレイ" + 0.004*"お待ち" + 0.004*"皆さま" + 0.004*"更新" + 0.004*"マン" + 0.004*"公式" + 0.004*"派" + 0.004*"号" + 0.003*"生"')
(1, '0.039*"好き" + 0.024*"的" + 0.022*"大丈夫" + 0.022*"朝" + 0.021*"気" + 0.018*"みたい" + 0.015*"仕事" + 0.014*"感じ" + 0.012*"店" + 0.012*"話" + 0.011*"度" + 0.011*"ところ" + 0.011*"前" + 0.010*"日本" + 0.009*"子" + 0.009*"無理" + 0.008*"今回" + 0.008*"本" + 0.008*"家" + 0.008*"次" + 0.008*"位" + 0.007*"者" + 0.007*"一番" + 0.007*"絵" + 0.007*"感" + 0.007*"上" + 0.007*"残念" + 0.007*"毎日" + 0.007*"力" + 0.007*"最後" + 0.007*"数" + 0.007*"顔" + 0.006*"音" + 0.006*"綺麗" + 0.006*"映画" + 0.006*"久しぶり" + 0.006*"所" + 0.006*"手" + 0.006*"6月" + 0.006*"問題" + 0.006*"個人" + 0.006*"部" + 0.006*"猫" + 0.006*"目" + 0.006*"男" + 0.006*"ゲーム" + 0.005*"大変" + 0.005*"夜" + 0.005*"場所" + 0.005*"機会" + 0.005*"関係" + 0.005*"色" + 0.005*"神" + 0.005*"化" + 0.005*"他" + 0.005*"結果" + 0.005*"最初" + 0.005*"女性" + 0.005*"学校" + 0.005*"チャレンジ" + 0.005*"屋" + 0.005*"キャラ" + 0.004*"アニメ" + 0.004*"雨" + 0.004*"確か" + 0.004*"相手" + 0.004*"番" + 0.004*"最近" + 0.004*"普通" + 0.004*"家族" + 0.004*"心配" + 0.004*"後" + 0.004*"一緒" + 0.004*"ヶ月" + 0.004*"通り" + 0.004*"生活" + 0.004*"全部" + 0.004*"音楽" + 0.004*"犬" + 0.004*"限定" + 0.004*"漫画" + 0.004*"返信" + 0.004*"東京" + 0.003*"気持ち" + 0.003*"週間" + 0.003*"ファン" + 0.003*"報告" + 0.003*"オススメ" + 0.003*"Twitter" + 0.003*"バス" + 0.003*"時代" + 0.003*"イベント" + 0.003*"キャンペーン" + 0.003*"勉強" + 0.003*"準備" + 0.003*"会" + 0.003*"ダメ" + 0.003*"内" + 0.003*"普段" + 0.003*"大阪"')
(2, '0.029*"募集" + 0.023*"情報" + 0.022*"垢" + 0.017*"参加" + 0.014*"大好き" + 0.014*"ツイート" + 0.014*"者" + 0.013*"万" + 0.013*"円" + 0.012*"企画" + 0.012*"裏" + 0.012*"soraruru" + 0.012*"名" + 0.011*"アカウント" + 0.011*"駅" + 0.011*"詳細" + 0.010*"頃" + 0.010*"プレゼント" + 0.010*"心" + 0.009*"紹介" + 0.009*"県" + 0.009*"たくさん" + 0.009*"誕生" + 0.009*"利用" + 0.009*"歳" + 0.009*"リプ" + 0.009*"以上" + 0.009*"全員" + 0.009*"確認" + 0.009*"プロフ" + 0.008*"希望" + 0.008*"最高" + 0.008*"セフレ" + 0.008*"定期" + 0.008*"LINE" + 0.008*"フォロワー" + 0.008*"方法" + 0.008*"市" + 0.008*"女子" + 0.008*"応募" + 0.008*"素敵" + 0.007*"URL" + 0.007*"相互" + 0.007*"花" + 0.007*"エロ" + 0.006*"先" + 0.006*"連絡" + 0.006*"名前" + 0.006*"メンバー" + 0.006*"拡散" + 0.006*"枠" + 0.006*"リツイート" + 0.006*"amp" + 0.006*"ノ" + 0.006*"必要" + 0.006*"グループ" + 0.006*"内容" + 0.006*"抽選" + 0.006*"書" + 0.006*"系" + 0.006*"女" + 0.005*"コード" + 0.005*"マジ" + 0.005*"記念" + 0.005*"お金" + 0.005*"仕事" + 0.005*"条件" + 0.005*"配布" + 0.005*"会社" + 0.005*"無料" + 0.005*"お世話" + 0.004*"レベル" + 0.004*"最近" + 0.004*"ライン" + 0.004*"年齢" + 0.004*"絶対" + 0.004*"幸せ" + 0.004*"サイト" + 0.004*"女の子" + 0.004*"フォロバ" + 0.004*"変態" + 0.004*"追加" + 0.004*"応援" + 0.004*"欄" + 0.004*"当選" + 0.004*"ネタ" + 0.004*"闇" + 0.004*"セックス" + 0.004*"歓迎" + 0.004*"固定" + 0.004*"無事" + 0.004*"エッチ" + 0.004*"出会い" + 0.004*"笑顔" + 0.004*"登録" + 0.003*"アカ" + 0.003*"商品" + 0.003*"投稿" + 0.003*"支援" + 0.003*"線"')
(3, '0.039*"可能" + 0.032*"求" + 0.030*"譲" + 0.025*"失礼" + 0.022*"枚" + 0.021*"声" + 0.020*"検索" + 0.020*"希望" + 0.016*"手渡し" + 0.015*"検討" + 0.015*"円" + 0.015*"目" + 0.015*"缶" + 0.015*"郵送" + 0.014*"譲渡" + 0.013*"画像" + 0.012*"バッジ" + 0.011*"譲り" + 0.011*"公演" + 0.011*"定価" + 0.011*"申し訳" + 0.010*"点" + 0.010*"取引" + 0.010*"幸い" + 0.010*"気軽" + 0.010*"チケット" + 0.010*"優先" + 0.010*"連絡" + 0.009*"会場" + 0.009*"初め" + 0.009*"送料" + 0.009*"返事" + 0.008*"グッズ" + 0.007*"当方" + 0.007*"参加" + 0.007*"全て" + 0.007*"リプ" + 0.007*"カード" + 0.007*"夢" + 0.007*"場合" + 0.006*"祭" + 0.006*"予定" + 0.006*"所持" + 0.006*"大阪" + 0.006*"性" + 0.006*"都内" + 0.006*"当日" + 0.006*"了解" + 0.005*"対応" + 0.005*"名古屋" + 0.005*"舞台" + 0.005*"予約" + 0.005*"席" + 0.005*"券" + 0.005*"為" + 0.005*"個" + 0.005*"連" + 0.005*"販売" + 0.005*"買取" + 0.005*"リプライ" + 0.004*"本当" + 0.004*"夜" + 0.004*"クリア" + 0.004*"周年" + 0.004*"作品" + 0.004*"車" + 0.004*"春" + 0.004*"池袋" + 0.004*"同種" + 0.004*"今後" + 0.004*"状態" + 0.004*"劇場" + 0.004*"組" + 0.004*"風" + 0.004*"夏" + 0.004*"ステージ" + 0.004*"イメージ" + 0.004*"東" + 0.004*"特典" + 0.004*"是非" + 0.004*"ラーメン" + 0.004*"初日" + 0.003*"先" + 0.003*"縁" + 0.003*"プリ" + 0.003*"東京" + 0.003*"大変" + 0.003*"お待ち" + 0.003*"購入" + 0.003*"セット" + 0.003*"外" + 0.003*"二" + 0.003*"ライト" + 0.003*"自由" + 0.003*"十" + 0.003*"馬" + 0.003*"都合" + 0.003*"際" + 0.003*"現在" + 0.003*"丸"')
- 「その他系」と名付けたトピック以外はスパム感があるので、無作為に選んだツイートをトピックモデルに入れるだけでも、スパムフィルタのようなものが出来ると思いました。
ユーザの分類 (おまけ)
- ツイートを分類するモデルが出来たので、ユーザごとに「どのトピックをどれくらい投稿しているか」を調べることができます。
- この情報を使って、ツイッターユーザの分類をしてみたいと思います。
ユーザ情報の取得
- 上で取得したサンプルツイートからユーザ情報を重複なく取り出し、users という新しい Collection を作ります。
- これをしているスクリプトは、update_users.py です。
- 具体的な処理は、lib/mongo_util.py の中の
update_users()というメソッドでやっています。- このコードには無駄があり、
PyMongo.MongoClientのreplace_one()というメソッドを使うと、もっとすっきりします (実行時間も短くなると思います)。
- このコードには無駄があり、
ユーザツイートの取得
- 上で作ったユーザ情報を使って、彼らのツイートを取得し、MongoDB に保存します。
- これをしているスクリプトは、retrieve_usr_tweets.py です。
- この「ユーザツイートの取得」から、次の「ユーザツイートの分類」までは、スクリプトの実行に時間がかかります。私の場合、1000人分のデータを取って分類するのに、PC を1ヶ月くらい止めずに動かし続けました (ツイート数は150万件くらいになりました)。
- サンプルツイートを取得する時はキーワード検索でしたが、ここではユーザのタイムラインを取得するという API (を使う関数) を使います。
- 具体的な処理は
TwConnクラスのuser_timeline()です。
api = tweepy.API(self.auth)
(中略)
# 実際には以下の関数を繰り返し呼んでいます。コードをご参照ください。
statuses = api.user_timeline(
user_id=user_id, max_id=max_id, since_id=since_id, count=count
)
-
retrieve_usr_tweets.py では、
sample_user_countで何人分のツイートを取得するか指定できます。 - スクリプトが途中で落ちて再度実行すると、
sample_user_countより多く取得してしまうので、users の方に取得したしるし (used_as_sample) を付けておいて、あとで数えられるようにしています。- 余計に取得する分には、分類する時にユーザ数を指定して調整できます。
# ユーザ ID を指定してタイムラインを取得し保存する (抜粋)
for results in twconn.user_timeline(user_id=id):
ins_result = col_usrtweets.insert_many(results)
ret_cnt = len(results)
ins_cnt = len(ins_result.inserted_ids)
print('{} tweets retrieved and {} added to DB.'.format(ret_cnt, ins_cnt))
# 何件取得したかを users collection の方でも覚えておく
col_users.find_one_and_update({'user.id': id},
{'$set': {'used_as_sample': True}, '$inc': {'tweet_count': ins_cnt}})
ユーザツイートの分類
- ツイートの分類のプロセスは、上でサンプルツイートを分類した時と同じです。
- 形態素解析は必要ですが、モデルはすでにあるので、それで分類します。
- スクリプトは、念のためサンプルツイートの時とは別に作りました。
ユーザごとのトピックの集計
- ユーザごとに、各トピック種別へと分類された文書数を数えて、Collection に記録します。
ユーザの分類
- ユーザの分類には k-means を使いました。ユーザごとに4つのトピック別文書数があるので、4次元での距離を使った分類となります。
- (参考) k平均法 - Wikipedia
- これをしているスクリプトは cluster_users.py です。
クラスタ数の見当を付ける
- VSCode で開いて、まず「エルボー法でクラスタ数の見当を付ける」までを実行します。

- クラスタを増やしながら分類を繰り返し、誤差平方和の縮まり方を見るのですが、クラスタを増やせば距離が縮まるのは当然なので、変化の度合いを見ることになります。
- 誤差平方和とは、クラスタの中心を $\left(\bar{x}, \bar{y}, \bar{z}, \bar{w}\right)$、サンプルの値を $\left(x, y, z, w\right)$ とした場合の、$\left(x-\bar{x}\right)^2+\left(y-\bar{y}\right)^2+\left(z-\bar{z}\right)^2+\left(w-\bar{w}\right)^2$ のことです (パラメタが4つの場合)。
- この場合、角度の変化が大きい "4" を採用することにします。
分類と可視化
- スクリプトの
clst_cntにクラスタ数をセットして、続きを実行します。
# 決めたクラスタ数
clst_cnt = 4
- 可視化にあたっては、横軸にトピック ID を取って、折れ線グラフで表現してみました。
- グラフタイトルの下にある4つの数字が、そのクラスタにおける各トピックの出現率です。

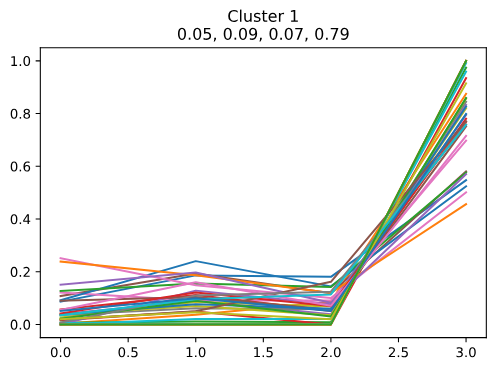


考察
- グラフを見ると、特にトピック 2 (♡出会い系) とトピック 3 (交換・譲渡系) をたくさん投稿している人は、他のトピックについてはあまり投稿していないようです。
- トピック 0 (告知・イベント系) やトピック 1 (その他系) を多く投稿している人は、それ以外のトピックについてもまぁまぁ投稿していますが、トピック 3 (交換・譲渡系) だけは少ないようです。
- おそらく「♡出会い系」や「交換・譲渡系」ばかりを投稿するアカウントがあって、中でも「交換・譲渡系」を投稿するアカウントには、それ専用のものが多いのではないかと思いました。
参考にしたページ
Twitter 分析
- スタバのTwitterデータをpythonで大量に取得し、データ分析を試みる
-
[PDF]単語の特徴に着目したTwitterユーザのリスト分類 - 言語処理学会
(ツイート内容から特徴を抽出するのにトピック分類を使っている) - API レート制限
- Rate limits
- Get Tweet timelines
- Twitter検索オプションと高度な検索
Tweepy
- Tweepy “page parameter is invalid” error
- (Tweepy のソースを見ると、API.search に page というパラメタは無い)
- API Reference - tweepy 3.7.0 documentation
- API.search
- Tweepy ドキュメント
トピックモデル
- 自然言語処理による文書分類の基礎の基礎、トピックモデルを学ぶ
- トピックモデル(LDA)で初学者に分かりづらいポイントについての解説
- tfidf、LSI、LDAの違いについて調べてみた
- 【入門】トピックモデルとは?トピック分析の3つの手法を解説
- SNOW D11:話題分類単語辞書
- SNOW D18:日本語感情表現辞書
MongoDB
PyMongo
- PyMongo 3.8.0 documentation
- PythonからMongoDB(DocumentStore)を使ってみる
- pythonでMongoDB入門しよう
- MongoDBにpythonのdatetimeオブジェクトを保存した時の挙動
gensim
- gensim: Topic modelling for humans
- Pythonで単語分散表現のクラスタリング
- scikit-learnとgensimでニュース記事を分類する
- Python用のトピックモデルのライブラリgensim の使い方
- Corpus Streaming – One Document at a Time
- gensim勉強:1.Corpora and Vector Spaces
- Gensim Tutorial – A Complete Beginners Guide
- LDAとそれでニュース記事レコメンドを作った。
評価指標
- gensimのLDAで最適トピック数を決定する方法
- トピックモデルの評価指標 Coherence 研究まとめ (スライド)
- gensimのLDA評価指標coherenceの使い方
-
トピックモデルを用いた併売の分析 - gensim の LdaModel 使用
(alpha の値による影響を考察している)
k-means