自然言語においても、最近は生ビールを頼む感覚で「とりあえずディープラーニング」となることが多いです。実際ディープラーニングは高精度を記録できることが多いですが、実はその精度は基礎的なモデルでも記録できたり、あげく負けるようなこともあったりします。
研究機関として名高いDeepMindの発表した論文でも、こうした事態がありました。

また、最近はベースラインとして良く利用されているモデルでも最高精度を達成できるといった論文もありました。このように、ベースラインとして足蹴にされているモデルでも存外隅には置けないのです。
今回は自然言語処理における基本的な手法の一種であるトピックモデルを取り上げてみます。これは文書分類などに使用されるモデルですが、文書分類の際に著者の存在を仮定するなど(オーサートピックモデル)、様々な仮定を盛り込める非常に応用力の高いモデルでもあります。
今回は、その仕組みを紹介するとともに、実装方法について解説していきたいと思います。
※本記事は、昔書いたブログの転載になります(サイト閉鎖に伴い移行しました)。
トピックモデルとは
トピックモデルは、確率モデルの一種になります。つまり、何かが「出現する確率」を推定しているわけです。トピックモデルにおいてはこれは文章中の「単語が出現する確率」になります。これをうまく推定することができれば、似たような単語が出てくる文章が把握できるというわけです。
つまり、トピックモデルとは「文書における単語の出現確率」を推定するモデルといえます。
なお、そう聞くと(単語の出現確率を学習した)トピックモデルから文章が生成できるのでは・・・という気もしますが、上述の通りトピックモデルが推定するのは「単語が出現する確率」であり、文法規則は気にしません。つまり、トピックモデルとはあくまで文章における単語とその出現頻度にフォーカスしたモデルということです。
さて、では「単語が出現する確率」をどのように推定すればよいのでしょうか。
端的には、実際文書内に出現する単語を数え上げて、それを元に推定を行います。トピックモデルでは、この出現する単語の種類と数がトピック(=カテゴリ)によって異なると仮定します。イメージ的には、政治と芸能というトピックでは出現する単語が異なるので、これは自然な仮定です。
この「トピック」が、どの単位で存在すると考えるかによって、モデルが変わってきます。 以下の図は、四角の箱が文書、その中身の色がトピックを表しています。
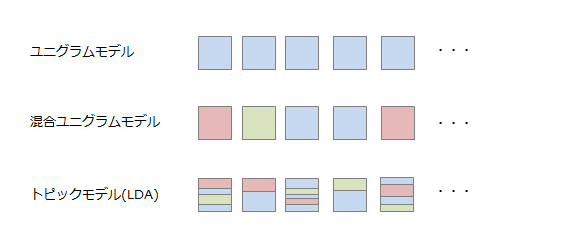
- ユニグラムモデルは、すべてのボックスが同じ青色です。つまり、全ての文書の単語は、一つのトピックから生成されたものと仮定するモデルです。
- 混合ユニグラムモデルは、各ボックスの色が異なっています。つまり、各文書に一つのトピックがあり、そのトピックから文書の単語が生成されると仮定するモデルです。
- トピックモデル(LDA)では、ボックスの中で色が異なっています。つまり、各文書は複数のトピックで構成されていて、各トピックの単語分布を合算した形で単語が生成されていると仮定します。
つまり、今回紹介するトピックモデルは、最も細やかな仮定を置いたモデルになります。
文書が複数のトピックで構成されるという仮定を置くことで、「この記事は70%はスポーツ、20%は芸能・・・」といった文書の構成を導くことができ、これにより文章の特徴を把握し、文書間の差異などが定量的に把握できるようになります(この文書はあの文書よりも10%くらい政治寄りだ、など)。
トピックモデルを実装する方法
では、実際トピックモデルを実装するための方法についてご紹介します。なお、以下ではPythonでの実装を前提としています。
最も手軽に実装できるのは、gensimになります。「topic modeling for humans」とあるとおり、ほんの数行で実装が可能です。
他には、PyMC3や、PyStanでも実装は可能です。PyMC/PyStanは、何れもMCMCサンプラーという統計モデルのパラメーターを推定してくれるためのライブラリになります。そのため、当然ですが統計モデル自体は自ら構築する必要があります。
なお、PyStanはStanというライブラリのPython用インタフェースであり、Stan自体はC++やRなどからも使うことができます。
手軽さ重視であればgensim、自分でモデルを組んで構築するなど、カスタマイズを行いたい場合はPyMC/PyStanということになると思います(ちなみに、インストールもこの順に手間です)。 今回は、手軽さ重視でgensimを使っていきたいと思います。
ここからは、実際のコードをベースに解説をしていきます。以下のリポジトリに解説用のコードを置いていますので、必要に応じて参照してください。
icoxfog417/gensim_notebook
(Starを頂ければ励みになります m(_ _)m)
Pythonで機械学習を利用した開発を行う際の環境設定については、こちらをご参考ください。Minicondaというパッケージを利用する方法を紹介しています。
上記の記事通り環境を構築すれば、gensimはconda install gensimで一発で入ります(PyMCも同様。PyStanはこんなに簡単には入りません・・・)。
上記のリポジトリの中で、iPython notebookという、Pythonのコードを含んだドキュメントを作成できるツールで解説文書を作成しています。こちらをベースに、以下の解説を行っていきます。
gensim_notebook/topic_model_evaluation.ipynb
データの取得
まずは、対象となるデータの取得を行います。
今回トピックモデルを構築するためのデータは、リクルートから提供されているホットペッパーBeautyのAPIから取得しました。
動機としては、全く自分にとってなじみのないデータなので、どんなふうになるのか興味があったためです。
上記のサイトから新規登録を行い、APIキーを取得します。
その後、リポジトリ中のscripts/download_data.pyを実行することでヘアサロンのデータをダウンロードすることができます。
データの前処理
続いて、データの前処理を行います。具体的には、文章を単語/出現回数のセットに変換します。このセットをコーパスと呼び、コーパスの中では単語はIDで表現します。このIDと実際の単語をひも付けたものを、ここでは辞書と呼びます。
このコーパス/辞書を作成する処理としては、以下のステップになります。
- 文章を単語に分解し(形態素解析)、数え上げを行う
- 不要な語の除去(ストップワードの除去など)
- 語の統一(ステミング)
文章を単語に分解する処理は、英語であれば空白で区切れますが、日本語の場合はそう簡単には行きません。
そのため、形態素解析を行えるライブラリを利用するのが一般的です。このライブラリとしてはMeCabが有名で、mecab-ipadic-neologdという、新しく出てきた単語を登録した辞書も提供されています。
ただ、特にWindowsではインストールが手間なので、Pythonだけで構築されておりインストールが簡単なjanomeを使うのもよいと思います。
今回のサンプルでは、手軽に実行してもらうため上記のようなライブラリを使った形態素解析は行っていません。データ中にある「こだわり条件」がちょうどスラッシュで区切られた情報だったので、こちらを区切って使用しています。

不要な語の除去は、分類に不要と思われる語を抜いていくことです。具体的には以下のような語になります。
- 「ある」「いる」など、分類に寄与しないような一般的な語(ストップワード)
- ほとんどの文章で出現し、分類には役に立たないような語(例えば「大人気!」など、どこでも使うような語)
- 逆に、ほとんど出現しないような語
- 上記以外の、分類に寄与しないと思われる単語
そして、語の統一とは、「美味しい」「美味しかった」など、活用形だけが異なるようなものを統一していくことです。これをステミングといいます。
自然言語処理のおいては、これらの前処理をどれだけ行えるかで精度がほぼ決まると言っても過言ではありません。
コーパスを作るためのスクリプトscripts/make_corpus.pyでは、様々なオプションにより上記の操作を行えるようになっているので、色々な設定を試してみてください。
トピックモデルの構築
コーパスと辞書ができたら、これを元にモデルを構築します。
といっても、gensimを使えばモデルの構築は一行で済みます。
m = models.LdaModel(corpus=corpus, id2word=dictionary, num_topics=3)
「何個のトピックかがあると仮定するか(num_topics)」は、設定をする必要があります。つまり、文書全体で何個のトピックがありそうかは、自ら推定する必要があるということです(実は、どれぐらいのトピック数がよいかを推定するディリクレ過程という方法もあります)。
何個に設定したら良いのか、それを検討するには、モデルの評価を行う必要があります。
トピックモデルの評価
まず、評価を行うために、通常の機械学習の作法と同様学習用と評価用にコーパスを分割します。学習用で分類を学習し、その結果評価用(=未知の文章)をきちんと分類できるか調べるわけです。
この評価には、パープレキシティという指標を用います。パープレキシティの逆数が文書中の単語の出現を予測できる度合いを示しており、よって最高は1で、モデルの精度が悪くなるほど大きな値になります(2桁ならよし、3桁前半でまあまあ、それ以後は悪い、という感じで、1桁の場合は逆にモデルやパープレキシティの算出方法に誤りがないか見直した方がよいです)。
解説文書中のMake Topic Modelの箇所で、トピック数を変えながらパープレキシティを算出しているので、確認してみてください。

そして、トピックを可視化することでモデルの評価も行いやすくなります。以下で、その手法について解説していきます。
トピック間の距離
トピックは文章の分類ですから、漏れ/重複なく、つまりはっきりと分かれていた方がうまく分類できていることになります。
つまり、トピック、分類間の距離がきちんと離れている方がよいモデルということになります。
各分類(=各トピックの単語分布)間の距離を測る指標としてKL-divergenceがあります。これを利用し、トピック間の距離を図示したものが以下になります(トピック数3で作成、軸の値はトピックの番号です)。
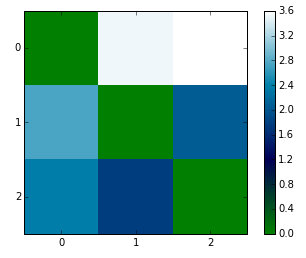
上図は、よくない例です。トピック間の距離が離れているほど薄い色になるので、図全体が濃いということは似たようなトピック(=カテゴリ)が出てきてしまっているということになるためです。
この場合は、トピック数を減らすことを検討します。
文章のトピック構成
実際に文章の分類を行う場合は、はっきりとこの文章のトピックはxx、とできた方が良いことになります。
つまり、各文章についてはっきりとメインであるトピックが分かった方がよい、ということです。
そこで、各文章を構成するトピックを図示したものが以下になります(上記の検証を受け、トピック数は2に減らしました)。ランダムに200件の文書をピックアップし、各文書におけるトピックの構成比率を表示しています。

トピックの参照
最後に、各トピックでどんな単語が出やすいのかを見てみます。
トピック間で単語が重複しておらず、また単語の集まりからどんなトピックなのかあたりが付けられそうなほど良いということになります。

これを見てみると、少なくともTopic #1は「小型サロン」「一人のスタイリストから~」というキーワードから、小規模のサロンではないかと推測できます(「完全予約制」というキーワードを考慮すると、高級店的な所なのかもしれません)。Topic #0はスタッフが多く年中無休、という感じで比較的大きなヘアサロン、といった印象です。
実際にヘアサロンのホームページを見てみると、Topic #0の方がメジャー感があり、Topic #1の方が専門店感がある気がしないでもありません。
なお、トピックモデルのように人が教えることなく、データの特徴をシステム自身に発見させ、分類させるような手法を教師なし学習と呼びます(逆に、データとその分類をセットにして学習させる手法を教師有り学習と呼びます)。
こうした教師なし学習はデータがあればすぐに始められるというメリットがある反面、上記のように**「どう分類されるか」はモデル任せになるため、結果の解釈が難しくなるという難点もあります**。
アプリケーションへの適用
このように、gensimを利用することで簡単にトピックモデルを構築し、文章の特徴を把握し分類などをを行うことができます。
これをアプリケーションへ適用することで、以下のような機能を実装できると思います。
- SNSで、似ている投稿をしているユーザー(=興味が似ているユーザー)を推薦する
- ソースコードからトピックモデルを構築し、似ている機能単位などにまとめることで、コードの静的解析に役立てる
- コールセンターなどで、過去の問い合わせと似た内容をオペレーターに表示する
また、トピックモデルは最初に述べたとおり、非常に応用力の高いモデルのためその発展系も多く存在します。
具体的には、レビューなどテキスト情報以外に評価指数といった付属情報がある際それを考慮できるようにした対応トピックモデル(Correspondence topic model)や、テキストを書いた著者を考慮する著者トピックモデル(Author topic model)などです。また、画像の特徴量を単語のように扱うことで画像分類に適応するといった試みも行われています(これによりテキストと画像双方を同時に扱えるようになるため、画像にキャプションを自動的につけるimage annotationの研究などに応用されています)。
今回の解説が、アイデアを形にするための一助となれば幸いです。
参考文献
さらに詳しく知りたい、という方のために参考となる書籍/記事を紹介しておきます。
-
トピックモデル (機械学習プロフェッショナルシリーズ)
非常にわかりやすくトピックモデルについて解説されています。他の良書としてトピックモデルによる統計的潜在意味解析 (自然言語処理シリーズ)がありますが、そちらを読む前に読んでおくとよいと思います。 -
トピックモデルシリーズ 1 概要
こちらも非常にわかりやすい解説になっています。PyStanベースでの解説なので、PyStanで実装したい方はそちらも参考になると思います
確率などの初歩的な考え方については、以下記事が丁寧に解説しています。
PyMCで実装する場合は、こちらのチュートリアルが参考になります。