最近、Transformerベースのdiffusion modelが高いパフォーマンス(ImageNetのFID基準)を出している。ということで、特に性能の高い最新モデルを2つ紹介する。加えて、これらを調査していたら、それらの性能をさらに底上げする手法とCNNベースでさらに高い性能を出してSOTAを達成したぞという論文にもさらに行き着いたので、それら2本も併せて追加で紹介する。
(追記)2024/2/23に発表されたStable Diffusion 3や2/15に発表されたOpenAIのSoraでは、今回紹介するDiTがDiffusion Transformer(拡散トランスフォーマー)のベース技術に採用されている。
※以降の図は論文からそのまま引用、もしくはそれに多少の加工を加えたものとなる。
※以降のpaperswithcodeの順位は2024/1時点
目次
- DiT (ICCV'23): Diffusion Model + Transformer
- DiffiT: Diffusion Model + Transformer (+ U-Net)
- CADS (ICLR'24): 多様性を向上させるsampling
- EDM2: CNNベースの高性能 Diffusion Model
- 感想
DiT (ICCV'23): Diffusion Model + Transformer
ImageNet 256 - 10位 (paperswithcode)
概要
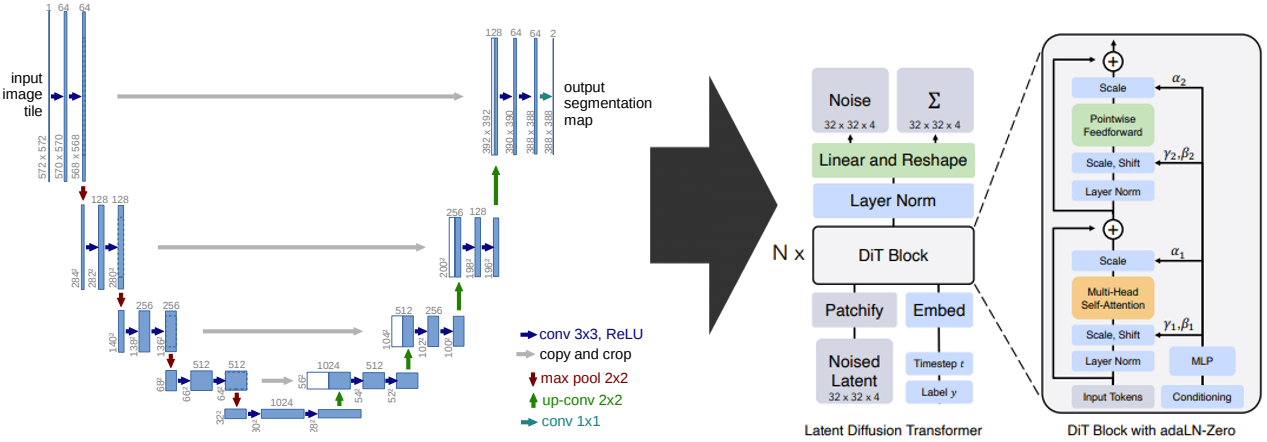
Diffusion modelの基幹であるCNNベースのU-Netを、Transformerベースのアーキテクチャに置き換えることで性能向上を実現している。
モデル解説
従来からのDiffusionモデルが持つU-Net構造を捨て、新たにViT構造を採用したアーキテクチャであるDiTが提案されている。DiTは、ViTから以下に説明する入出力とself-attention blockの2点を変更した生成モデルである。
※全体アーキテクチャのベースはLDM (Stable Diffusion)
※ロスは通常のDDPM
(ViTからの変更点1) 入出力

ViTとはタスクが異なるため、ViT(上図の左)の入出力を生成モデル用(上図の右)の入出力に変更する。
- ViT
- [入力] 画像
- [出力] クラス分類結果
- DiT
- [入力] 画像+時刻t+クラスラベルy
- 正確には、「画像」でなく「ノイズ画像」である
- LDMと同様、画像はVAEのencoderによりコンパクト化された状態で扱うため、
Latentと表記される - ちなみに、入力としてtext embeddingを追加すればtextも扱える
- [出力] 画像(+標準偏差Σ)
- 正確には、「画像」でなく「入力のノイズ画像に載っているノイズ成分」である
- 画像を出力させるために、最終段でunpatchify処理(patchifyの逆)を行っている
- 標準偏差Σはオプション(Diffusion modelの学習方式次第)
- [入力] 画像+時刻t+クラスラベルy
(ViTからの変更点2) DiT Block
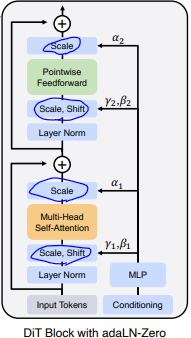
ViTには存在しない入力である条件情報(=Conditioning=時刻t+クラスラベルy)を扱えるように変更する。具体的には、ViTのself-attention blockに対して、上図のようにAdaLN機構(γ/βによるScale/Shift)を追加する。このAdaLN機構により、Scale γ, Shift βを通じた条件情報の注入が達成される。
このように、基本的には元のself-attentionにAdaLNを追加するだけのシンプルな変更であるが、性能向上のために追加で以下の2つの工夫を加えている。
- AdaLNのγ・βに加え、Scale αを新規に追加: 条件情報を参照するパラメータを増やすことで、条件情報をより強く画像に反映させることができる
- Scale αの実装: 上図にあるように残差結合の直前にα倍のスケーリング処理を追加する
- AdaLNのγ・βを算出するMLPの重み・バイアスを0初期化: 学習初期は条件情報を全く注入しないことになり、学習が安定化する
- まともな画像を出力できていない段階で、条件情報でその画像をさらに大きく変化させてしまうと、学習が安定しないため
※Tensorの並び順等の都合で実装上はAdaLNであるが、動作イメージとしてはAdaINである。
※論文上ではDiT blockの候補として他に3案を挙げているが、ここでは最終的に採用された方式のみを説明した。
Experiment
classifier-free guidance付きの高GFlops(patch size=2、XLargeサイズ)なDiTモデルを用意して、SOTA級のモデルら(GANで現状最強のStyleGAN-XL や classifier-free guidance付きLDM)と比較した。結果、以下の通りFID=2.27でDiTが首位を獲得した。
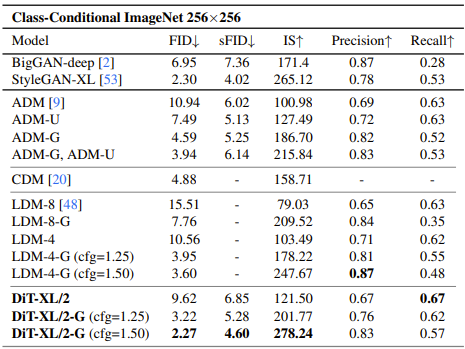
※Precisionは画像の品質、Recallは画像のcover率(≒多様性)
DiffiT: Diffusion Model + Transformer (+ U-Net)
ImageNet 256 - 2位 (paperswithcode)
ImageNet 512 - 7位 (paperswithcode)
- [論文]DiffiT: Diffusion Vision Transformers for Image Generation (arXiv)
- [実装]github(2024/1/31 まだコード上がってない)
概要
上述のDiTと同じで、Diffusion modelの基幹であるCNNベースのU-Netを、Transformerベースのアーキテクチャに置き換えることで性能向上を実現している。この際、U-Net構造を継承する効率的なバージョンも用意しており、U-Netの高い効率性を得ることができる。

モデル解説
DiTと同様にViTベースの構成をしており、主な特徴(≒DiTとの差分)は独自のDiffiT blockとオプションのU-Net構造にある。(上図はU-Net構造なし版)
入出力
ViTに対して、DiTと同様の変更が行われている。
つまり、入力は画像(noised)に加えて時刻・クラス情報が追加され、出力は画像(noised)に変更されている。
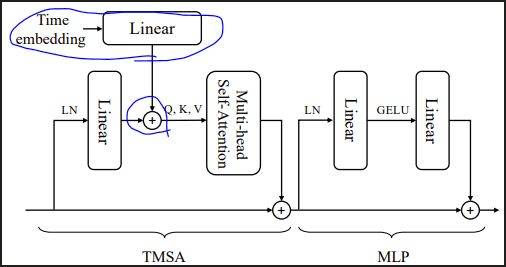
DiffiT Block
DiTと同様に、ViTからself-attention blockが変更されている。DiTではself-attention処理にAdaLNを適用することで条件情報の注入を実現したが、DiffiTでは下図のようにself-attentionの入力であるQ, K, Vに条件情報トークンを加算することで注入する。また図には載っていないが、Relative positional encodingを採用することで、時刻情報を追加で与えている。
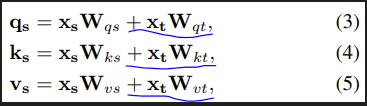
(オプション) U-Net構造
規模の小さい(解像度が低い、複雑性が低い)データセットでは、下図のようなU-Net構造による軽量化・効率化が提案されている。本構造では、DownsamplingやWindow attentionの導入によりself-attentionの計算量を削減することで、大幅な軽量化を実現している。
※ImageNetの規模だと大量のパラメータが必要なためか、U-Net構造は採用されていない

Experiments
以下の通り、DiT越えのFID=1.73を達成した。(ImageNet-256)

以下の表の上2つはFFHQ-64データセット、下2つはImageNet-256データセット(Latent空間)の結果である。DiffiTは、FFHQでは高効率なU-Net有りモデルを採用し、ImageNetでは高性能なU-Net無しモデルを採用している。それぞれ同規模の従来モデルと比較しているが、DiffiTの方が高い性能(FID)を出せている。

CADS (ICLR'24): 多様性を向上させるsampling
ImageNet 256 - 1位 (paperswithcode) ‥ DiTベース
- [論文]CADS: Unleashing the Diversity of Diffusion Models through Condition-Annealed Sampling (arXiv)
- [実装]公式実装なし(SD-WebUIでの実装例)
概要
Diffusion modelのアーキテクチャ変更はなしで、samplingの工夫のみで多様性の向上を実現している。下図の左が通常sampling、右がCADS samplingの例であるが、CADSの方が高い多様性を表現できているのが見て取れる。
CADSはsamplingの工夫であるため、任意のDiffusion modelへ容易に適用可能である。本論文では、CADSを先に紹介したDiTへ適用することでImageNet 256のSOTAを叩き出している。


CADS Sampling手法
やり方は極めてシンプルで、条件情報yを徐々に弱まるノイズnで補正するだけである。(ここでの条件はクラスやテキストを指す)
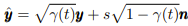
sはノイズスケール、γ(t)∈[0,1] はノイズ割合調整用係数(時刻と共に徐々に小さくなる)である。
ノイズ付与によりyの平均・標準偏差が変質してしまうのを防ぐために、以下のrescale手法が追加で提案されている。ただし、これを適用すると品質は上がるものの多様性向上効果が下がるので、resclaeをどの程度行うかはハイパーパラメータψで調整可能にしている。
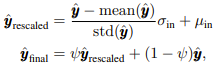
ちなみに、このようなノイズ付与機構なんかを追加するんでなく、単にCFG重み値(=条件の強さ)を徐々に増やせば同等のことをできるのではないか(=Dynamic CFG)、と考える人もいるかもしれない。だが、著者らもそれを考えて実際に比較実験をした結果、下表のようにCADSが性能・多様性の両面で圧倒した。画像デノイズ(=Reverse process)の初期段階で、ノイズで条件をかき乱して画像の方向性を固定化させないことが多様性に繋がるっぽい。
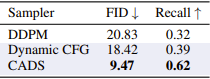
※Recallは画像のcover率(≒多様性)
Experiment
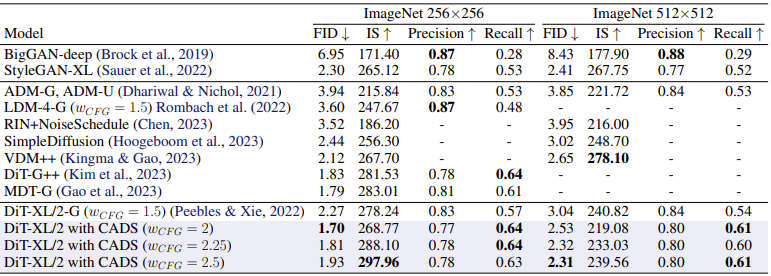
結果は下表の通りで、DiTにCADSを適用することで、DiffiT(FID=1.73)を上回るFID=1.70を達成した。(ImageNet-256)
EDM2: CNNベースの高性能 Diffusion Model
ImageNet 512 - 1位 (paperswithcode)
概要
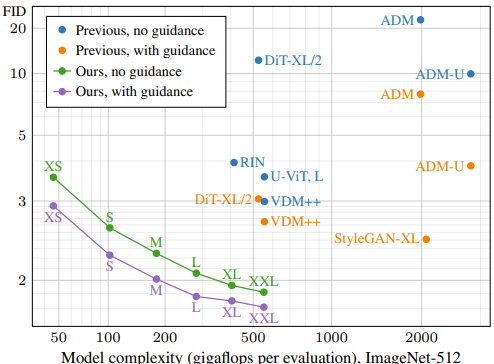
CNNベースのDiffusion modelを、最新の知見を生かしてチューニングしていくことで高性能・高効率なモデルを実現している。ImageNet 512では、DiT・DiffiT(下図に載ってないが)を上回る性能・効率を達成した。
モデル解説(チューニング)
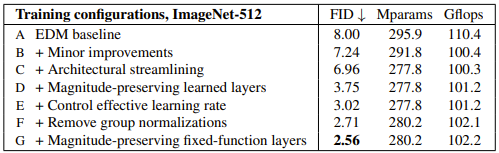
下表のA→...→Gのように、モデルや学習方式を少しずつ改良していくことで高性能・高効率なモデルを作り上げた。
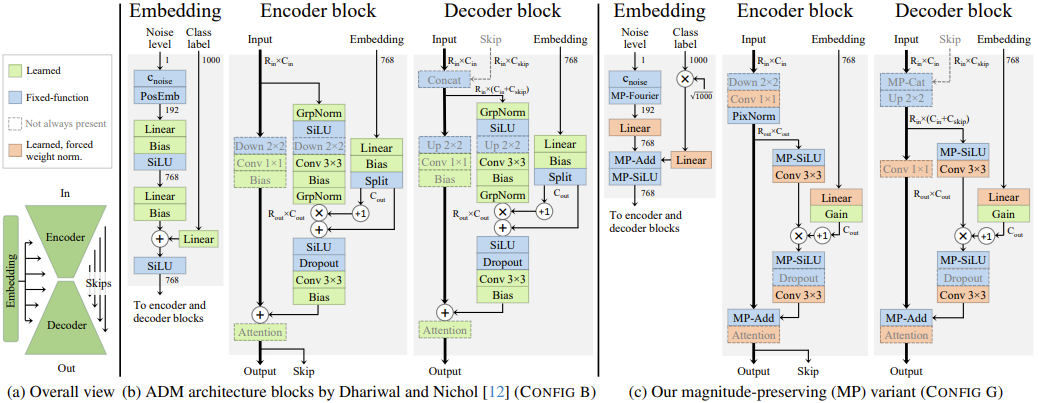
特に、全体の値のスケールを上手く調整するような構造(Magnitude Preserving)を取ることで、微妙に邪魔だった正規化層を大きく排することに成功しており、これによりかなり簡素なレイヤー構造になっているのが特徴的である。
ちなみにこの論文では、少数パターンのEMAパラメータのモデルから、任意のEMAパラメータのモデルを高精度に近似する手法も提案しており、この分析手法により最適なEMAパラメータを効率的に求めている。
Experiment
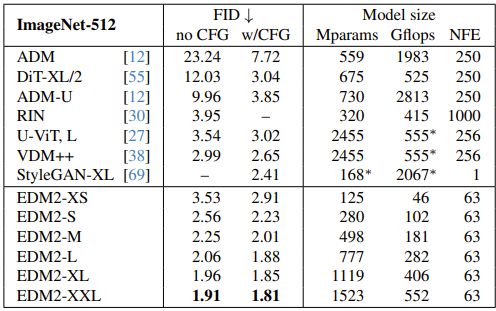
以下の表の通り、ImageNet-512でDiffiT(FID=2.63)やCADS(FID=2.31)を上回るFID=1.91を達成した。(ImageNet-256の評価は無い)
感想
Diffusion modelでもCNNからTransformerにしてくのが良いのかと思ったら、EDM2でCNNベースが猛追してきて、現状どっちが優れてるのかまだまだ判断できないという感じだった。
(ViTに対するConvNeXtと同じような構図)