はじめに
kerasを使って画像分類プログラムを作成。初めてディープラーニングを実装しました。
喜怒哀楽の感情認識を行いたかったのですが、「喜」と「楽」の区別が画像からでは難しいと判断し、「笑顔」「怒っている顔」「悲しそうな顔」の三種類の分類を行いました。
画像の収集
今回は感情がより明確にわかる画像を収集したかったため、スクレイピングなどは行わず、手作業で一枚一枚、3種類の画像に対して約100枚づつ集めました。一枚の画像から複数の感情が感じられるものが多くあり、収集作業は難航しました。
プログラム
インポート
import keras
from keras.models import Sequential
from keras.layers import Dense, Dropout, Flatten
from keras.layers import Conv2D, MaxPooling2D
from keras import backend as K
from keras.preprocessing.image import array_to_img, img_to_array, load_img
import numpy as np
import matplotlib.pyplot as plt
from PIL import Image
import os
import random,math
学習データの前処理
batch_size = 128
epochs = 16
category_num = 3
img_rows = 256
img_cols = 256
loaded_array = np.load("face.npz")
x = loaded_array['x']
y = loaded_array['y']
x = x.astype(np.float32)
import random
num =[]
for i in range(217):
num.append(i)
random.seed(1234)
random.shuffle(num)
random_x = []
random_y = []
for i in num:
random_x.append(x[i])
random_y.append(y[i])
random_x = np.array(random_x)
random_y = np.array(random_y)
random_x /= 127.5
random_x -= 1
学習データとテストデータに分ける
p = 0.8
split_index = int(len(x)*p)
x_train = random_x[0:split_index]
y_train = random_y[0:split_index]
x_test = random_x[split_index:len(x)]
y_test = random_y[split_index:len(x)]
x_train = random_x[0:200]
y_train = random_y[0:200]
x_test = random_x[200:250]
y_test = random_y[200:250]
AIのモデルを定義
model = Sequential()
model.add(Conv2D(32, kernel_size=(3, 3), activation='relu', input_shape=(256, 256, 3)))
model.add(Conv2D(64, (3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(64, (3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(32, (3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(32, (3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(128, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(5, activation='softmax'))
model.compile(loss=keras.losses.sparse_categorical_crossentropy,
optimizer=keras.optimizers.Adadelta(),
metrics=['accuracy'])
モデルの構造
Total params: 887,621
Trainable params: 887,621
Non-trainable params: 0
モデルの学習
history = model.fit(x_train, y_train,
batch_size=batch_size,
epochs=epochs,
verbose=1,
validation_data=(x_test, y_test))
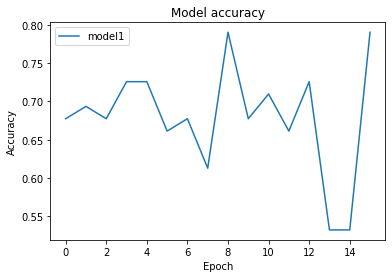
実行結果
Train on 247 samples, validate on 62 samples
Epoch 1/16
247/247 [==============================] - 3s 11ms/step - loss: 0.8169 - acc: 0.6721 - val_loss: 0.9165 - val_acc: 0.6774
Epoch 2/16
247/247 [==============================] - 3s 10ms/step - loss: 0.8579 - acc: 0.6356 - val_loss: 0.8189 - val_acc: 0.6935
Epoch 3/16
247/247 [==============================] - 3s 10ms/step - loss: 0.8301 - acc: 0.6235 - val_loss: 0.7927 - val_acc: 0.6774
Epoch 4/16
247/247 [==============================] - 3s 10ms/step - loss: 0.7580 - acc: 0.6802 - val_loss: 0.7936 - val_acc: 0.7258
Epoch 5/16
247/247 [==============================] - 3s 10ms/step - loss: 0.7494 - acc: 0.6883 - val_loss: 0.7825 - val_acc: 0.7258
Epoch 6/16
247/247 [==============================] - 3s 11ms/step - loss: 0.6734 - acc: 0.7126 - val_loss: 0.8027 - val_acc: 0.6613
Epoch 7/16
247/247 [==============================] - 3s 10ms/step - loss: 0.6361 - acc: 0.7571 - val_loss: 0.7703 - val_acc: 0.6774
Epoch 8/16
247/247 [==============================] - 3s 10ms/step - loss: 0.8512 - acc: 0.6275 - val_loss: 0.8758 - val_acc: 0.6129
Epoch 9/16
247/247 [==============================] - 3s 10ms/step - loss: 0.7143 - acc: 0.7287 - val_loss: 0.6430 - val_acc: 0.7903
Epoch 10/16
247/247 [==============================] - 3s 10ms/step - loss: 0.5427 - acc: 0.7814 - val_loss: 0.8462 - val_acc: 0.6774
Epoch 11/16
247/247 [==============================] - 3s 11ms/step - loss: 0.7831 - acc: 0.6761 - val_loss: 0.6719 - val_acc: 0.7097
Epoch 12/16
247/247 [==============================] - 3s 11ms/step - loss: 0.5954 - acc: 0.7449 - val_loss: 0.6917 - val_acc: 0.6613
Epoch 13/16
247/247 [==============================] - 3s 11ms/step - loss: 0.6762 - acc: 0.7490 - val_loss: 0.6542 - val_acc: 0.7258
Epoch 14/16
247/247 [==============================] - 3s 11ms/step - loss: 0.5252 - acc: 0.7692 - val_loss: 0.9343 - val_acc: 0.5323
Epoch 15/16
247/247 [==============================] - 3s 11ms/step - loss: 0.7746 - acc: 0.6478 - val_loss: 0.8525 - val_acc: 0.5323
Epoch 16/16
247/247 [==============================] - 3s 11ms/step - loss: 0.6295 - acc: 0.7287 - val_loss: 0.6170 - val_acc: 0.7903
CPU times: user 17.6 s, sys: 10.5 s, total: 28.2 s
Wall time: 41.6 s
学習済みモデルをテストする
def predict_one_image(image):
fig, (axL, axR1) = plt.subplots(ncols=2, figsize=(10,4))
img = np.copy(image)
img += 1
img *= 127
img = img.astype(np.uint8)
img = np.reshape(img, (img_rows, img_cols, 3))
axL.imshow(img)
img = np.copy(image)
img = np.reshape(img, (1, img_rows, img_cols, 3))
res = model.predict(img, batch_size=None, verbose=0, steps=None)
axR1.bar(range(category_num), np.reshape(res, (-1,)))
axR1.set_xticks(range(category_num))
fig.show()
for i in range(len(x_test)):
predict_one_image(x_test[i])
0=笑顔、1=怒り、2=悲しみ として分類したのですが、下のように口角が上がっていると怒りの画像でも笑顔として認識されてしまいました。

まとめ
- 笑顔の画像は高い確率で正しく認識される。
- 悲しみと怒りは誤って認識される確率が高い。
- 悲しみや怒りの画像でも、少し口角が上がっていると笑顔と認識されてしまう。
- 手動で画像を収集したので、怒りの画像は男性の割合が高くなってしまった。それにより感情の認識に性別が影響してしまった可能性がある。