最近TensorFlowのv1.0がリリースされたようなのですが、まだ確認しておらず少し古いバージョンでの実行となっています。なるべく早めにv1.0に更新できればという状態です。
今回はDCGANのモデルをTensorFlowで実装し、ロゴ画像を生成してみました。
元論文はUnsupervised Representation Learning with Deep Convolutional Generative Adversarial Networksのようです。
DCGANについては既にやっている人も多く、学習のロジックや詳細については
Chainerで顔イラストの自動生成
Chainerを使ってコンピュータにイラストを描かせる
TensorFlowによるDCGANでアイドルの顔画像生成
あたりがわかりやすく説明されており参考になります。
学習環境
TensorFlow 0.11.0rc2
Ubuntu 16.04
GTX1080
画像データ
webサービスや企業などのロゴ画像を643枚収集

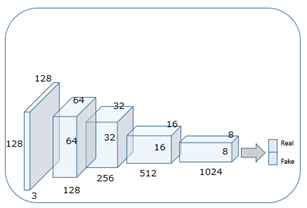
実装・学習
基本的にコードはhttps://github.com/carpedm20/DCGAN-tensorflowをベースにしてます。
今回のコード(github)
GeneratorとDiscriminatorのスケールなどパラメータを少しいじってあります。
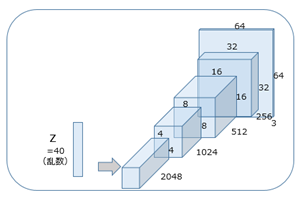
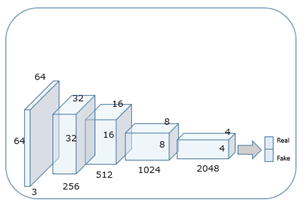
tf.nn.batch_normalizationをGeneratorとDiscriminatorに入れてあります。
...
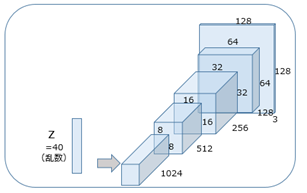
def generator(self, z, y=None):
if not self.y_dim:
# project `z` and reshape
self.z_, self.h0_w, self.h0_b = linear(z, self.gf_dim*8*4*4, 'g_h0_lin', with_w=True) #linear => ops.pyメソッド
# z_= in*random + b , h0w = random , h0b = bias(random)
self.h0 = tf.reshape(self.z_, [-1, 4, 4, self.gf_dim * 8])
mean0, var0 = tf.nn.moments(self.h0, [0,1,2]) #[-1,4,4,64*8]
h0 = tf.nn.relu(tf.nn.batch_normalization(self.h0, mean0, var0, None , None,1e-5,name='bn0')) # relu(batch_norm(h0) name='g_bn0')
self.h1, self.h1_w, self.h1_b = deconv2d(h0, #deconv2d => ops.pyメソッド #
[self.batch_size, 8, 8, self.gf_dim*4], name='g_h1', with_w=True) # h1 = deconv[64,8,8,64*8] ,h1w = w(rand) , hb1 = b(rand)
mean1, var1 = tf.nn.moments(self.h1, [0,1,2])
h1 = tf.nn.relu(tf.nn.batch_normalization(self.h1, mean1, var1, None , None,1e-5,name='bn1')) # relu(batch_norm(h1) name='g_bn1')
h2, self.h2_w, self.h2_b = deconv2d(h1, # 以下deconvルーチン
[self.batch_size, 16, 16, self.gf_dim*2], name='g_h2', with_w=True) #
mean2, var2 = tf.nn.moments(h2, [0,1,2])
h2 = tf.nn.relu(tf.nn.batch_normalization(h2, mean2, var2, None , None,1e-5,name='bn2'))
h3, self.h3_w, self.h3_b = deconv2d(h2,
[self.batch_size, 32, 32, self.gf_dim*1], name='g_h3', with_w=True)
mean3, var3 = tf.nn.moments(h3, [0,1,2])
h3 = tf.nn.relu(tf.nn.batch_normalization(h3, mean3, var3, None , None,1e-5,name='bn3'))
h4, self.h4_w, self.h4_b = deconv2d(h3,
[self.batch_size, 64, 64, 3], name='g_h4', with_w=True) # out_shape = [64,64,64,3]
return tf.nn.tanh(h4)
... # tanh(h4)
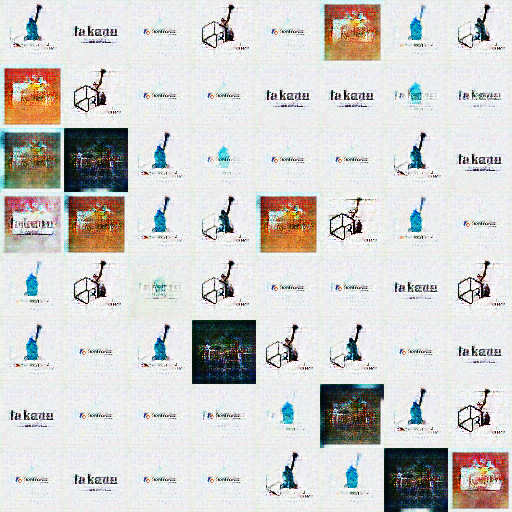
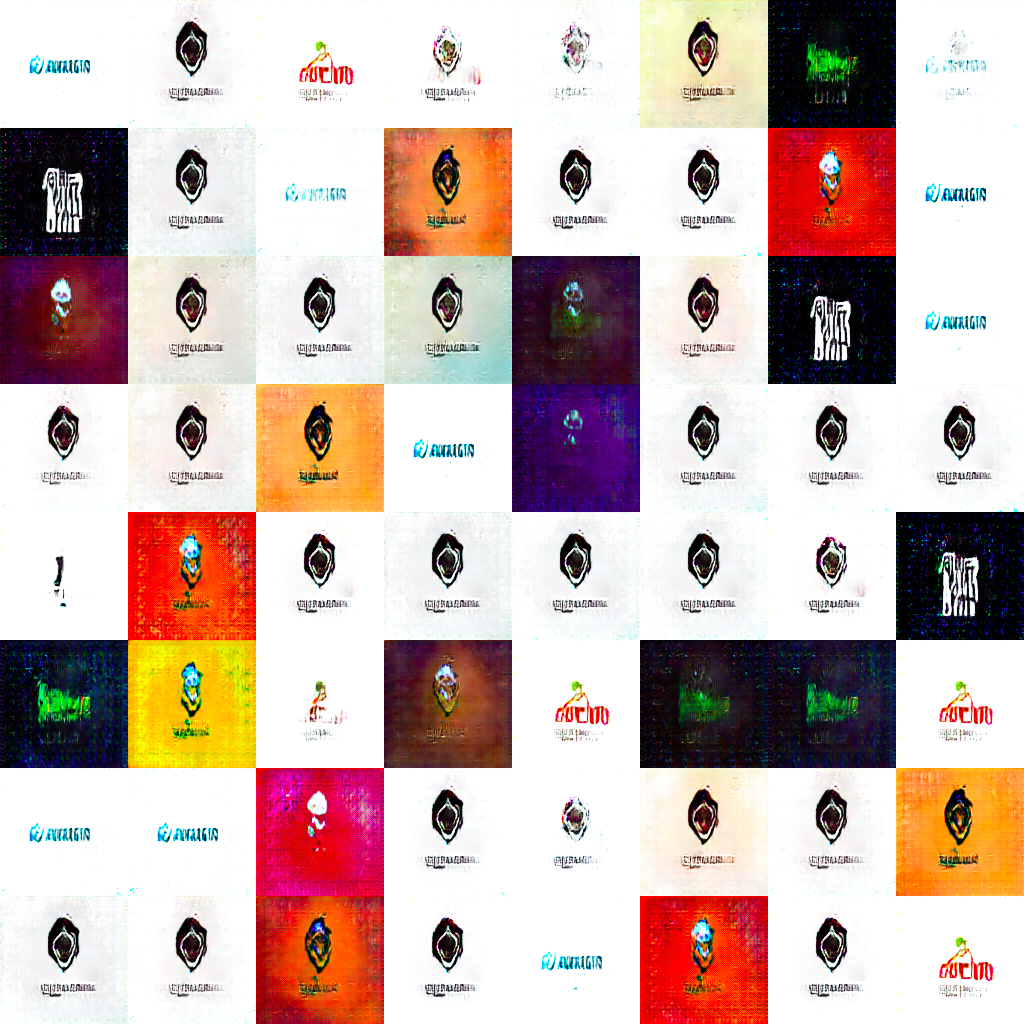
結果
生成された画像の一部(gifはサイズオーバーでした)
ロゴっぽい感じではありますかね

改良を試みる--Feature matching
GANの学習テクニックなどが書かれているImproved Techniques for Training GANsを参考に改良したい。英語なので理解はアバウトですが。。。
既に先行研究TensorFlowによるDCGANでアイドルの顔画像生成 その後の実験などでFeature matchingをされていたので参考にさせていただき、やってみました。コード(github)
#生成された画像の平均値と学習データ画像の平均値
self.feature_matching = 0.1
self.mean_from_g = tf.reduce_mean(self.G )#, reduction_indices=(0)) #生成画像平均値
self.mean_from_i = tf.reduce_mean(self.images)# , reduction_indices=(0)) #学習画像平均値
#平均値の差分に適度な値をかける
self.g_mean_loss = tf.mul(tf.nn.l2_loss(self.mean_from_g - self.mean_from_i), self.feature_matching)
#判別器の特徴(生成画像/学習画像)の平均値
self.feature_form_i = tf.reduce_mean( self.D_feature )#, reduction_indices=(0))
self.feature_from_g = tf.reduce_mean( self.D_feature_ )#, reduction_indices=(0))
#平均値の差分に適度な値をかける
self.g_feature_loss = tf.mul(tf.nn.l2_loss(self.feature_from_g - self.feature_form_i), self.feature_matching)
#self.losses = self.mean_loss + self.feature_loss
#tf.add_to_collection('ge_loss',self.losses)
self.d_loss_real = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(self.D_logits, tf.ones_like(self.D)))
self.d_loss_fake = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(self.D_logits_, tf.zeros_like(self.D_)))
self.g_loss_ = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(self.D_logits_, tf.ones_like(self.D_)))
#tf.add_to_collection('ge_loss',self.ge_loss)
self.d_loss = self.d_loss_real + self.d_loss_fake #disc _loss合計
self.g_loss = self.g_loss_ + self.g_mean_loss + self.g_feature_loss # generator_lossの計算
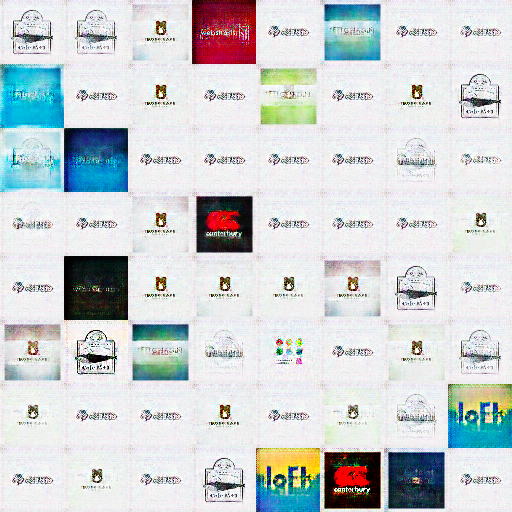
結果2
Feature matchingして生成された一部の画像
んー、大きな変化は見られないようですねー

さらに改良を試み--データ変更・増量
とりあえずデータを変えて、ロゴ画像4350枚に増やし(前の643枚を含まない)
もう少し大きい画像で生成できるようにネットワークのスケールを変更して、
とりあえず生成してみる(Feature matchingなし)
コードgithub

結果3
大きい画像で見やすくなったかと。
同じロゴ画像でもデータが変わると、生成される画像も随分変わりますね

まだ改良を--Semi supervised Learning
論文Improved Techniques for Training GANsでの、"Semi-supervised Learning"についてです。
今までは集めたロゴ画像に対しDiscriminatorが(生成されたもの/学習データ)の2値で分類をしていました。
これをもっと高度なラベルをつけて、つまり他クラス分類のようにKクラスの分類に生成された画像を加えてK+1クラスでの学習する。さらにGeneratorで生成された画像をデータセットに加えることで半教師あり学習となる?らしい。。。
そして誤差関数は

と定義するようです。これは赤い部分が通常のKクラス分類の誤差的なもので、青い部分が生成も含めた誤差を計算する関数で、今まで通りGANの誤差(下の青いとこ)で計算して、赤と青を足して誤差Eにするみたいな感じですかね。
。。。
んー難しいし、ロゴ画像を他クラスにはできない。ので、スマホアプリのアイコン画像を3000枚ほど収集し、
ロゴ ・ アプリ ・ 生成 の3クラスにすることにしてみました。
 収集したアプリ画像
収集したアプリ画像
ロゴの画像も適当に3000枚に絞り、学習させてみる。コードgithub
結果4
生成された画像の一部。
うーん。微妙です。改善は確認できない。
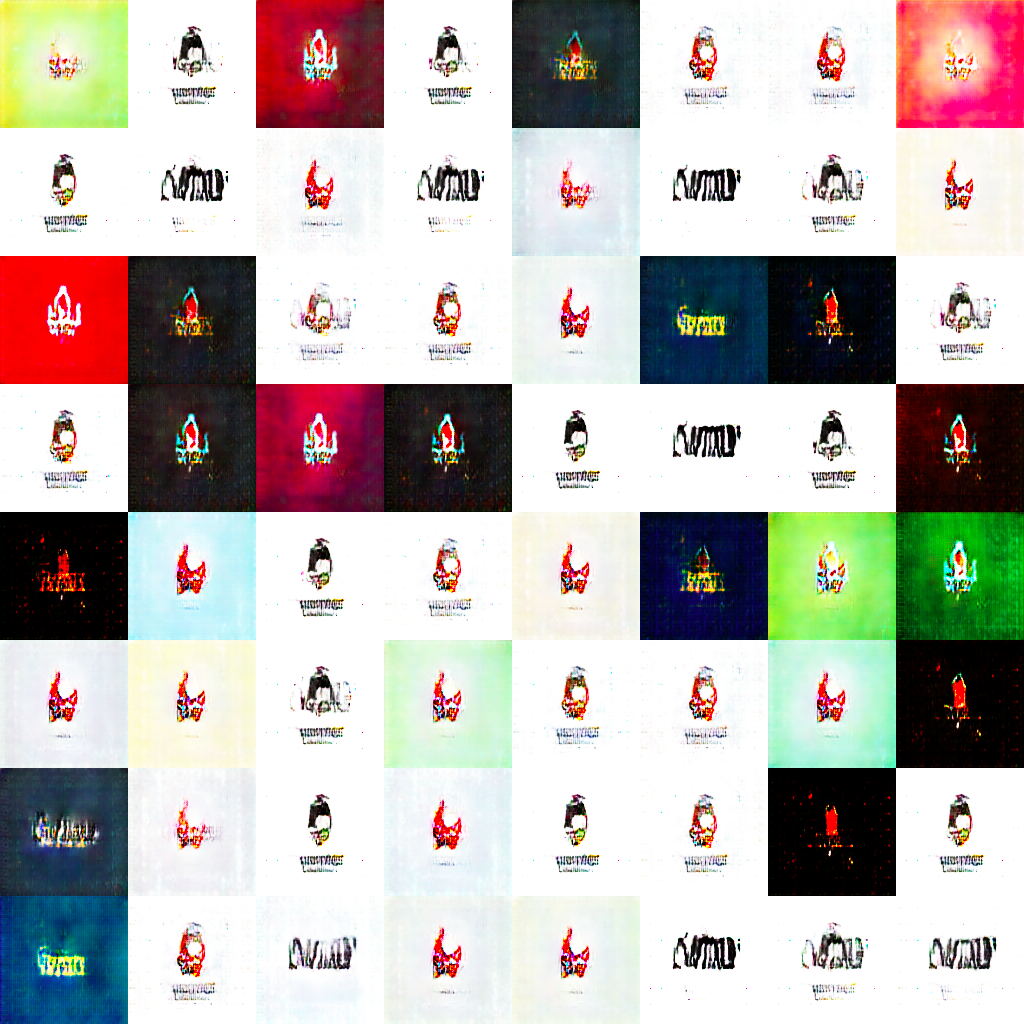

まだまだ改良を--Minibatch discrimination
またまた論文Improved Techniques for Training GANsよりMinibatch discriminationというものをやってみる。
生成された画像には似たようなものがいくつも出ており、これは勾配が集中してしまうことが原因であり、Discriminatorの特徴量に以下ようなの計算した結果をサイド情報として結合し、次の層に渡すことで同じものが出ることを防ぎたいということらしいです。
Discriminatorの特徴量f(Xi)にテンソルT(Tの中身については論文では分かりませんでした)を
かけて、その結果マトリクスMとする。n個のMの行についてL1-distanceをi,j全て求め、Cbとしてe^CbのΣをB個並べたベクトルと元の特徴量f(Xi)と結合して次の層に渡す。
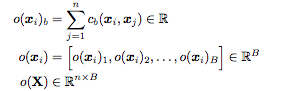
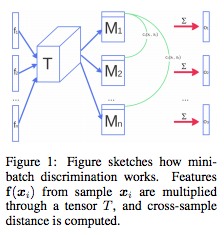
今回はこれをDiscriminatorの3層目に入れ、4層目の入力に適用しました。
https://github.com/jakekim1009/temporalprediction/blob/master/tensorflow_code/anthony_lstm/static_ops.pyを参考にしました。
*コードは後ほど更新します。
結果
Minibatch discriminationは計算に多くメモリを消費するため、生成の画像は小さくなってます。
多いパターンが生成されているような、そうでもないような感じです。あまり効果があったとは言えないですかね。。。


まとめ
TensorFlowを使ってDCGANでロゴ画像を生成しました。その後の改良も試みてみたものの微妙な感じでした(やり方が間違いなどあるかも)。もうちょっと色々試してみたいと思います。
また更新します。