目次
1.はじめに
2.今回の実施内容
3.開発環境の確認と事前準備
4.実装
5.最後に
1 はじめに
本記事では、大規模言語モデル(Large Language Model、以下、LLM)を活用した複雑なワークフローシステムを開発するためのライブラリであるLangGraphについて基本的な使い方を紹介します。
LangGraphとは
LangGraphは、ワークフローをグラフ構造としてモデル化し、複雑なタスクの自動化、システムの状態管理を支援します。LangGraphはLangChainの一部として提供されています。LangChainのChainsは一方向の処理フローを定義しますが、LangGraphは循環的な処理フローを定義します。LangGraphを活用することでより複雑なシステムに対する処理フローを実現することが可能です。その他のLangGraphの特徴は以下の通りです。
- 複数のエージェントが協力して問題を解決していくマルチエージェント開発に適している
- LangChainを基に開発されているため、LangChainの機能が活用できる
- グラフ構造を用いることで、「繰り返し処理」や「分岐処理」を実現できる
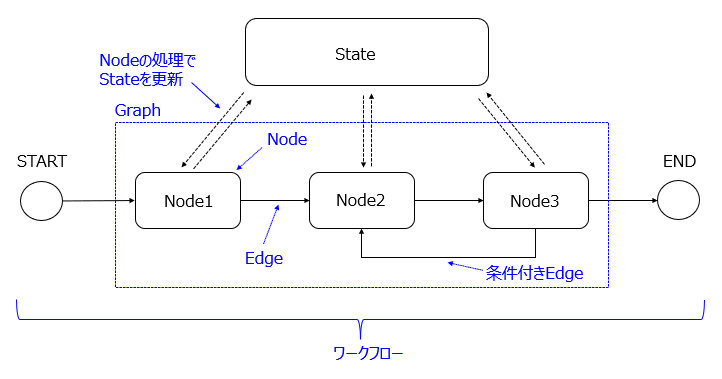
LangGraphの主要な構成要素は、State、Node、Edge、Graphの4つがあります。
| 構成要素 | 説明 |
|---|---|
| State | グラフに共通する状態を管理する要素。ワークフローで実行される各Nodeによって更新された値を保存する。 |
| Node | 処理を行う要素。Stateから必要な情報を取り出し、処理結果をもとにStateを更新する。 |
| Edge | Node間を接続する要素。次に実行するノードを指定する。無条件に遷移するEdgeや条件に基づいて遷移先のNodeを決定する条件付きEdgeが設定できる。 |
| Graph | NodeとEdgeで構成されるシステム全体を表す要素。 |
グラフ構造のイメージは以下の通りです。
2 今回の実施内容
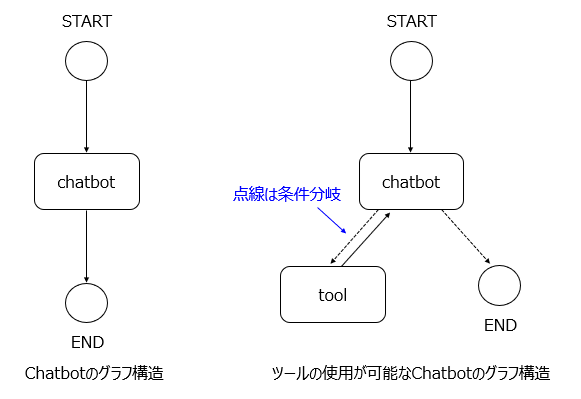
LangGraphの基本的な使い方を紹介するために、今回は以下2つのシステムを構築します。
- チャットボットの構築
- ツールの使用が可能なチャットボットの構築
チャットボットの構築では、LangGraphの基本的な実装方法を学びます。
ツールの使用が可能なチャットボットの構築では、LangGraphを使用してツールの呼び出しを学びます。LangGraphでツールを使用することで、より複雑なシステムを構築することが可能になります。
それぞれのグラフ構造のイメージは以下の通りです。
3 開発環境の確認と事前準備
開発環境の確認
今回は以下のバージョンで動作確認を行いました。
- Windows 11
- Python 3.13.2
- 主なLangChainのライブラリ
- langchain==0.3.20
- langchain-openai==0.3.7
- langgraph==0.3.3
事前準備
Pythonのインストール
以下の公式サイトよりPythonをダウンロードしてインストールを行います。
OpenAI API keyの取得
本記事の動作確認では、OpenAIの「gpt-4o-mini」を利用します。OpenAIのモデルを利用するためには、OpenAI API keyを取得する必要があります。事前に以下のサイトにアクセスしOpenAI API keyを取得します。初回はアカウントの登録が必要です。
※OpenAI API keyは従量課金制であるため、使用した分の料金が発生することをご留意ください。
仮想環境の構築
以下の手順で仮想環境を構築します。
作業フォルダ作成
今回は「training」フォルダを作成します。コマンドプロンプトを開いて以下のコマンドを実行します。カレントディレクトリはC:\Users\Usernameとします。
※Usernameは各端末によって異なりますのでご留意ください。
mkdir training
cd training
仮想環境の作成
仮想環境を作成するため、以下のコマンドを実行します。
python -m venv .venv
仮想環境の有効化
仮想環境を有効化するため、以下のコマンドを実行します。
.venv\Scripts\activate.bat
仮想環境の無効化
仮想環境を無効化する場合、以下のコマンドを実行します。
deactivate
必要なパッケージのインストール
今回の動作確認に必要なパッケージをインストールします。
pip install langchain langchain-openai langgraph dotenv grandalf
OpenAI API keyの設定
OpenAI API keyを使用するため、以下の設定を行います。
- trainingフォルダ内に.envファイルを作成します
- .envファイルを開き、以下の内容を入力後保存します
OPENAI_API_KEY="取得したOpenAI API key"
4 実装
LangGraphを使用してシステムを構築します。本項を実施するためには、前項の事前準備が完了していることが必要です。
チャットボットの構築
実装コード
trainingフォルダ内に新規ファイルchatbot.pyを作成して、以下のコードを入力後保存します。
from dotenv import load_dotenv
from typing import TypedDict
from typing import Annotated
from langchain_openai import ChatOpenAI
from langgraph.graph import StateGraph, START, END
from langgraph.graph.message import add_messages
# .envファイルから環境変数を読み込む
load_dotenv()
# モデル設定
llm = ChatOpenAI(model="gpt-4o-mini")
# Stateの定義
class State(TypedDict):
messages: Annotated[list, add_messages]
# Nodeの定義
def chatbot(state: State):
# LLMが生成した回答でStateを更新
return {"messages": [llm.invoke(state["messages"])]}
# Graphの初期化
graph_builder = StateGraph(State)
# Nodeの追加
graph_builder.add_node("chatbot", chatbot)
# Node間を接続するEdgeの追加
graph_builder.add_edge(START, "chatbot")
graph_builder.add_edge("chatbot", END)
# Graphのコンパイル
graph = graph_builder.compile()
# Graphの実行
result = graph.invoke({"messages": ["こんにちは"]})
# 結果表示
print(result)
コード実行
コマンドプロンプトから実装したコードを実行します。
※本手順を実行するためには事前に仮想環境の有効化の手順が必要です。
(.venv) C:\Users\Username\training>python chatbot.py
コード説明
モデルの設定
from langchain_openai import ChatOpenAI
# モデル設定
llm = ChatOpenAI(model="gpt-4o-mini")
ChatOpenAIクラスで使用する言語モデルgpt-4o-miniを設定しインスタンス化します。
Stateの定義
from typing import TypedDict
from typing import Annotated
from langgraph.graph.message import add_messages
class State(TypedDict):
messages: Annotated[list, add_messages]
TypeDictクラスを継承したStateクラスを定義します。TypeDictクラスは辞書型の型ヒントを定義するクラスです。messagesフィールドに、型ヒントをつける関数Annotatedとメッセージの追加を行う関数add_messagesを定義しています。messagesフィールドの第1引数にリスト、第2引数にadd_messagesを設定しているため、State更新時はリストの要素が追加されます。本例では、チャットボットとの会話履歴がリストの要素として追加されます。
Nodeの定義
def chatbot(state: State):
# LLMが生成した回答でStateを更新
return {"messages": [llm.invoke(state["messages"])]}
LangGraphではNodeの処理を関数として定義します。Nodeの処理を関数として定義する場合、Stateオブジェクトを引数に指定し戻り値をStateクラスの形式に合わせて辞書型で返します。chatbot関数の場合、stateオブジェクトを引数に受け取り、LLMのinvoke関数にstate["messages"]を渡して呼び出します。戻り値はStateクラスの辞書型に合わせるため、keyとしてmessages、valueとしてinvoke関数の出力結果をリスト型で返しています。
※Nodeの処理は、Runnableオブジェクトでも定義可能ですが、本記事では説明を割愛します。
Graphの初期化
# Graphの初期化
graph_builder = StateGraph(State)
StateGraphクラスにStateを渡して、Graphのインスタンスを生成します。今回はGraphのインスタンスとしてgraph_builderを生成しました。以降の手順でgraph_builderに対して、NodeやEdgeの設定を追加していきます。
Nodeの追加
graph_builder.add_node("chatbot", chatbot)
Nodeの追加はadd_node関数を使用します。add_node関数の第1引数にはNode名、第2引数には関数名を設定します。第1引数に設定されたNode名はEdgeの設定の際に使用します。
Edgeの追加
graph_builder.add_edge(START, "chatbot")
graph_builder.add_edge("chatbot", END)
Edgeの追加はadd_edge関数を使用します。add_edge関数の第1引数には遷移元のNode名を設定し、第2引数には遷移先のNode名を設定します。STARTは始点NodeをENDは終点Nodeを表す特殊なNodeです。
Graphのコンパイル
graph = graph_builder.compile()
Graphのコンパイルはcompile関数を使用します。compile関数はStateGraphをコンパイルしてCompiledStateGraphのインスタンスを生成します。CompiledStateGraphのインスタンスはRunnableとして使えるため、invoke関数、ainvoke関数、stream関数等の関数を実行することができます。
Graphの実行
# Graphの実行
result = graph.invoke({"messages": ["こんにちは"]})
# 結果表示
print(result)
本例ではinvoke関数を使用してGraphを実行しています。invoke関数に初期状態を渡して実行すると、Graph内のすべての処理が実行された後の最終結果が返されます。
出力例は以下の通りです。※出力例は整形表示しています。
{
'messages':[
HumanMessage(content='こんにちは',
additional_kwargs={
},
response_metadata={
},
id='36dda751-466f-4cde-83bd-19cf644e824a'),
AIMessage(content='こんにちは!どうかされましたか?何かお手伝いできることがあれば教えてください。',
additional_kwargs={
'refusal':None
},
response_metadata={
'token_usage':{
'completion_tokens':25,
'prompt_tokens':8,
'total_tokens':33,
'completion_tokens_details':{
'accepted_prediction_tokens':0,
'audio_tokens':0,
'reasoning_tokens':0,
'rejected_prediction_tokens':0
},
'prompt_tokens_details':{
'audio_tokens':0,
'cached_tokens':0
}
},
'model_name':'gpt-4o-mini-2024-07-18',
'system_fingerprint':'fp_06737a9306',
'finish_reason':'stop',
'logprobs':None
},
id='run-4b603376-6809-4fb9-8865-4bcd172ff02f-0',
usage_metadata={
'input_tokens':8,
'output_tokens':25,
'total_tokens':33,
'input_token_details':{
'audio':0,
'cache_read':0
},
'output_token_details':{
'audio':0,
'reasoning':0
}
}
)
]
}
チャットボットの回答のみ出力したい場合、print文を以下の通り修正します。
print(result["messages"][-1].content)
出力例は以下の通りです。
こんにちは!どうかされましたか?何かお手伝いできることがあれば教えてください。
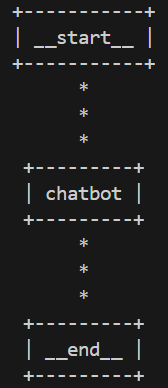
グラフ構造の可視化
LangGraphにはグラフ構造を可視化する機能が備わっています。この機能を活用することで、構築したチャットボットのグラフ構造を表示できます。グラフ構造の可視化のコードを実行する前に、以下2点を完了する必要があります。
-
grandalfのインストール - Graphのコンパイル
print(graph.get_graph().print_ascii())
出力例は以下の通りです。
ツールの使用が可能なチャットボットの構築
実装コード
trainingフォルダ内に新規ファイルchatbot_tools.pyを作成して、以下のコードを入力後保存します。
from dotenv import load_dotenv
from typing import TypedDict
from typing import Annotated
from langchain_openai import ChatOpenAI
from langchain_core.messages import ToolMessage
from langchain_core.tools import tool
from langgraph.graph import StateGraph, START, END
from langgraph.graph.message import add_messages
# .envファイルから環境変数を読み込む
load_dotenv()
# toolの定義
@tool
def multiply_function(x: int, y: int) -> int:
"""
2つのint型の値を引数で受け取り、掛け算の結果をint型で返す
Args:
x (int): 1つ目のint型の引数
y (int): 2つ目のint型の引数
Returns:
int: x * y
"""
return x * y
# toolの定義
@tool
def add_function(x: int, y: int) -> int:
"""
2つのint型の値を引数で受け取り、足し算の結果をint型で返す
Args:
x (int): 1つ目のint型の引数
y (int): 2つ目のint型の引数
Returns:
int: x + y
"""
return x + y
# ツールの辞書作成
tools_dict = {
"multiply_function": multiply_function,
"add_function": add_function
}
# モデル設定
llm = ChatOpenAI(model="gpt-4o-mini")
# toolsの作成
tools = [multiply_function, add_function]
# toolsの紐づけ
llm_with_tools = llm.bind_tools(tools)
# Stateの定義
class State(TypedDict):
messages: Annotated[list, add_messages]
# chatbotのNodeを定義
def chatbot(state: State):
# LLMが有効なtoolを選択して生成した回答でStateを更新
result = llm_with_tools.invoke(state["messages"])
return {"messages": [result]}
# toolのNodeを定義
def tool(state: State):
# 最後のメッセージを取得
last_message = state["messages"][-1]
# 実行結果を保存するためのリスト
messages = []
for tool_call in last_message.tool_calls:
# toolの実行
tool_output = tools_dict[tool_call["name"]].invoke(tool_call["args"])
# toolの結果を使用してToolMessageの作成
tool_messages = ToolMessage(
content=tool_output,
name=tool_call["name"],
tool_call_id=tool_call["id"],
)
# ToolMessageをmessagesリストに追加
messages.append(tool_messages)
# Stateを更新可能な辞書型を返す
return {"messages": messages}
# 条件分岐を判断する関数を定義
def router(state: State):
# 最後のメッセージを取得
last_message = state["messages"][-1]
# 最後のメッセージにtool_callsが存在するか判定
if last_message.tool_calls:
# tool_callsが存在する場合、"tool"を返す
return "tool"
else:
# それ以外の場合、"end"を返す
return "end"
# Graphの初期化
graph_builder = StateGraph(State)
# chatbot Nodeの追加
graph_builder.add_node("chatbot", chatbot)
# tool Nodeの追加
graph_builder.add_node("tool", tool)
# 条件付きEdgeの追加
graph_builder.add_conditional_edges(
# 遷移元のNode名を設定
"chatbot",
# 条件分岐を判断する関数を設定
router,
# routerの戻り値によって遷移先のNodeを決める
{
# "tool"の場合、tool Nodeに遷移
"tool": "tool",
#"end"の場合、END Nodeに遷移
"end": END
}
)
# tool Nodeからchatbot NodeへのEdgeを追加
graph_builder.add_edge("tool", "chatbot")
# STARTからchatbot NodeへのEdgeを追加
graph_builder.add_edge(START, "chatbot")
# Graphのコンパイル
graph = graph_builder.compile()
# Graphの実行
result = graph.invoke({"messages": ["100掛ける200の計算と1足す2の計算をそれぞれしてください"]})
# 結果表示
print(result)
コード実行
コマンドプロンプトから実装したコードを実行します。
※本手順を実行するためには事前に仮想環境の有効化の手順が必要です。
(.venv) C:\Users\Username\training>python chatbot_tools.py
コード説明
toolの定義
# toolの定義
@tool
def multiply_function(x: int, y: int) -> int:
"""
2つのint型の値を引数で受け取り、掛け算の結果をint型で返す
Args:
x (int): 1つ目のint型の引数
y (int): 2つ目のint型の引数
Returns:
int: x * y
"""
return x * y
# toolの定義
@tool
def add_function(x: int, y: int) -> int:
"""
2つのint型の値を引数で受け取り、足し算の結果をint型で返す
Args:
x (int): 1つ目のint型の引数
y (int): 2つ目のint型の引数
Returns:
int: x + y
"""
return x + y
# ツールの辞書作成
tools_dict = {
"multiply_function": multiply_function,
"add_function": add_function
}
LLMから呼び出される関数を定義します。@toolデコレータを使用して関数を定義することでLLMから呼び出される関数を作成することができます。ここでは、2つの引数を取って掛け算の結果を返すmultiply_functionと足し算の結果を返すadd_functionを作成します。関数のdocstringは、LLMがプロンプトの内容から適切な関数(tool)を判断して呼び出す際に利用されます。そのため、docstringに適切な説明を記載することは重要です。tools_dictはLLMがツールを呼び出す際に使用するツールの辞書です。
モデルの設定
from langchain_openai import ChatOpenAI
# モデル設定
llm = ChatOpenAI(model="gpt-4o-mini")
# toolsの作成
tools = [multiply_function, add_function]
# toolsの紐づけ
llm_with_tools = llm.bind_tools(tools)
LLMが作成したツールを呼び出すための設定を行います。設定手順は、モデルを設定した後、定義した各ツールを要素に持つリストをbind_tools関数に渡してモデルに紐づけを行います。本例では、multiply_functionとadd_functionを要素に持つリストtoolsを作成後、bind_tools関数にtoolsを渡してLLMに紐づけを行っています。
Stateの定義
from typing import TypedDict
from typing import Annotated
from langgraph.graph.message import add_messages
class State(TypedDict):
messages: Annotated[list, add_messages]
「チャットボットの構築」のStateの定義と同じ内容のため説明を割愛します。
各Nodeの定義
chatbot Nodeの定義
# chatbotのNodeを定義
def chatbot(state: State):
# LLMが有効なtoolを選択して生成した回答でStateを更新
result = llm_with_tools.invoke(state["messages"])
return {"messages": [result]}
chatbot関数は、stateオブジェクトを受け取り、llm_with_tools(ツールが紐づけられたLLM)のinvoke関数にstate["messages"]を渡して呼び出します。戻り値はStateクラスの辞書型に合わせるため、keyとしてmessages、valueとしてinvoke関数の出力結果をリスト型で返しています。
tool Nodeの定義
# toolのNodeを定義
def tool(state: State):
# 最後のメッセージを取得
last_message = state["messages"][-1]
# 実行結果を保存するためのリスト
messages = []
for tool_call in last_message.tool_calls:
# toolの実行
tool_output = tools_dict[tool_call["name"]].invoke(tool_call["args"])
# toolの結果を使用してToolMessageの作成
tool_messages = ToolMessage(
content=tool_output,
name=tool_call["name"],
tool_call_id=tool_call["id"],
)
# ToolMessageをmessagesリストに追加
messages.append(tool_messages)
# Stateを更新可能な辞書型を返す
return {"messages": messages}
tool関数は、stateオブジェクトを受け取り、state["messages"][-1]によってstateオブジェクトに保存されている最後のメッセージを取得します。for文では最後のメッセージに含まれるtoo_callsからツール情報を取得し、too_callsのnameをもとにtoolの定義で定義したツールの辞書(tools_dict)から実際のツールを呼び出します。また、ツールの変数としてtoo_callsのargsを渡してツールを実行します。ツールの実行結果を使用してToolMessageオブジェクトを作成します。ToolMessageのパラメータとして、content(ツールの実行結果)、name(ツールの名前)、tool_call_id(ツールのID)を設定します。作成したToolMessageオブジェクトは、messagesに追加します。戻り値はStateクラスの辞書型に合わせるため、keyとしてmessages、valueとしてmessagesリストを設定して返しています。
条件分岐を判断する関数の定義
# 条件分岐を判断する関数を定義
def router(state: State):
# 最後のメッセージを取得
last_message = state["messages"][-1]
# 最新メッセージにtool_callsが存在するか判定
if last_message.tool_calls:
# tool_callsが存在する場合、"tool"を返す
return "tool"
else:
# それ以外の場合、"end"を返す
return "end"
条件分岐を判断するためrouter関数を定義します。router関数は、stateオブジェクトを受け取り、state["messages"][-1]によってstateオブジェクトに保存されている最後のメッセージを取得します。if文では最後のメッセージにツールの呼び出しに対応するtool_callが存在するかを判定します。具体的には、last_message.tool_callsを判定し、tool_callが存在する場合は"tool"を返し、それ以外の場合は"end"を返します。
Graphの初期化
「チャットボットの構築」のGraphの初期化と同じ内容のため説明を割愛します。
各Nodeの追加
# chatbot Nodeの追加
graph_builder.add_node("chatbot", chatbot)
# tool Nodeの追加
graph_builder.add_node("tool", tool)
add_node関数を使用して、chatbot Nodeとtool Nodeを追加します。
各Edgeの追加
条件付きEdgeの追加
# 条件付きEdgeの追加
graph_builder.add_conditional_edges(
# 遷移元のNode名を設定
"chatbot",
# 条件分岐を判断する関数を設定
router,
# routerの戻り値によって遷移先のNodeを決める
{
# "tool"の場合、tool Nodeに遷移
"tool": "tool",
#"end"の場合、END Nodeに遷移
"end": END
}
)
条件付きEdgeは、条件に基づいて遷移先のNodeを決定するEdgeです。add_conditional_edges関数を使用します。第1引数に遷移元のNode名を設定します。第2引数には条件分岐を判断する関数を設定します。本例では、条件分岐を判断する関数の定義で定義したrouter関数を設定します。第3引数には第2引数の関数で返される値とその値に対応する遷移先のNodeを辞書型で設定します。router関数の戻り値が"tool"の場合はtool Nodeへ遷移し、"end"の場合はENDへ遷移します。
Edgeの追加
# tool Nodeからchatbot NodeへのEdgeを追加
graph_builder.add_edge("tool", "chatbot")
# STARTからchatbot NodeへのEdgeを追加
graph_builder.add_edge(START, "chatbot")
add_edge関数で遷移元のNodeと遷移先のNodeを定義します。graph_builder.add_edge("tool", "chatbot")は、tool Nodeからchatbot Nodeへの遷移を設定します。graph_builder.add_edge(START, "chatbot")は、STARTからchatbot Nodeへの遷移を設定します。
Graphのコンパイル
# Graphのコンパイル
graph = graph_builder.compile()
「チャットボットの構築」のGraphのコンパイルと同じ内容のため説明を割愛します。
Graphの実行
本例では、以下4パターンのGraph実行結果を確認します。
- チャットボットが
multiply_function、add_functionを呼び出すパターン - チャットボットが
multiply_functionのみ呼び出すパターン - チャットボットが
add_functionのみ呼び出すパターン - チャットボットがツールを呼び出さないパターン
- 簡単な掛け算や足し算は、ツールを使用せずにgpt-4o-miniを使用して直接計算可能ですが、本例ではチャットボットがツールを呼び出す処理を確認するためツールを準備しています
- ツールを2つ準備した理由は、チャットボットが複数のツールの中から有効と判断したツールを選択して呼び出せることを確認するためです
# Graphの実行
result = graph.invoke({"messages": ["100掛ける200の計算と1足す2の計算をそれぞれしてください"]})
# 結果表示
print(result)
出力例は以下の通りです。※出力例は整形表示しています。
{
'messages':[
HumanMessage(content='100掛ける200の計算と1足す2の計算をそれぞれしてください',
additional_kwargs={
},
response_metadata={
},
id='610ba8cd-e2c2-4765-a7e7-9380cb06cf3b'),
AIMessage(content='',
additional_kwargs={
'tool_calls':[
{
'id':'call_lT9Qfzb9LsKlcJ0nFgXHU4so',
'function':{
'arguments':'{"x": 100, "y": 200}',
'name':'multiply_function'
},
'type':'function'
},
{
'id':'call_uhocLNTmBaEamMt1G7NNQAo5',
'function':{
'arguments':'{"x": 1, "y": 2}',
'name':'add_function'
},
'type':'function'
}
],
'refusal':None
},
response_metadata={
'token_usage':{
'completion_tokens':53,
'prompt_tokens':222,
'total_tokens':275,
'completion_tokens_details':{
'accepted_prediction_tokens':0,
'audio_tokens':0,
'reasoning_tokens':0,
'rejected_prediction_tokens':0
},
'prompt_tokens_details':{
'audio_tokens':0,
'cached_tokens':0
}
},
'model_name':'gpt-4o-mini-2024-07-18',
'system_fingerprint':'fp_b8bc95a0ac',
'finish_reason':'tool_calls',
'logprobs':None
},
id='run-0c31e74c-a663-41e4-bc1c-3a769b8018a1-0',
tool_calls=[
{
'name':'multiply_function',
'args':{
'x':100,
'y':200
},
'id':'call_lT9Qfzb9LsKlcJ0nFgXHU4so',
'type':'tool_call'
},
{
'name':'add_function',
'args':{
'x':1,
'y':2
},
'id':'call_uhocLNTmBaEamMt1G7NNQAo5',
'type':'tool_call'
}
],
usage_metadata={
'input_tokens':222,
'output_tokens':53,
'total_tokens':275,
'input_token_details':{
'audio':0,
'cache_read':0
},
'output_token_details':{
'audio':0,
'reasoning':0
}
}
),
ToolMessage(content='20000',
name='multiply_function',
id='6802bb59-097c-4e78-a30a-98db8f29a0a8',
tool_call_id='call_lT9Qfzb9LsKlcJ0nFgXHU4so'),
ToolMessage(content='3',
name='add_function',
id='88d0c420-2cd1-40c7-8afa-04d7cb955bdc',
tool_call_id='call_uhocLNTmBaEamMt1G7NNQAo5'),
AIMessage(content='100掛ける200の結果は20000で、1足す2の結果は3です。',
additional_kwargs={
'refusal':None
},
response_metadata={
'token_usage':{
'completion_tokens':24,
'prompt_tokens':291,
'total_tokens':315,
'completion_tokens_details':{
'accepted_prediction_tokens':0,
'audio_tokens':0,
'reasoning_tokens':0,
'rejected_prediction_tokens':0
},
'prompt_tokens_details':{
'audio_tokens':0,
'cached_tokens':0
}
},
'model_name':'gpt-4o-mini-2024-07-18',
'system_fingerprint':'fp_b8bc95a0ac',
'finish_reason':'stop',
'logprobs':None
},
id='run-cd2c8b19-340c-4d6e-8328-997f245d3b6e-0',
usage_metadata={
'input_tokens':291,
'output_tokens':24,
'total_tokens':315,
'input_token_details':{
'audio':0,
'cache_read':0
},
'output_token_details':{
'audio':0,
'reasoning':0
}
}
)
]
}
AIMessageのtool_callsにmultiply_functionとadd_functionのツール情報が保存されています。
# Graphの実行
result = graph.invoke({"messages": ["100掛ける200の計算をしてください"]})
# 結果表示
print(result)
出力例は以下の通りです。※出力例は整形表示しています。
{
'messages':[
HumanMessage(content='100掛ける200の計算をしてください',
additional_kwargs={
},
response_metadata={
},
id='5d547b8e-ea1c-485d-8868-d098b3cbd7a6'),
AIMessage(content='',
additional_kwargs={
'tool_calls':[
{
'id':'call_6nNQUiItocW0i67BZStdMZlF',
'function':{
'arguments':'{"x":100,"y":200}',
'name':'multiply_function'
},
'type':'function'
}
],
'refusal':None
},
response_metadata={
'token_usage':{
'completion_tokens':19,
'prompt_tokens':211,
'total_tokens':230,
'completion_tokens_details':{
'accepted_prediction_tokens':0,
'audio_tokens':0,
'reasoning_tokens':0,
'rejected_prediction_tokens':0
},
'prompt_tokens_details':{
'audio_tokens':0,
'cached_tokens':0
}
},
'model_name':'gpt-4o-mini-2024-07-18',
'system_fingerprint':'fp_b8bc95a0ac',
'finish_reason':'tool_calls',
'logprobs':None
},
id='run-6ff2ffb0-3a42-4387-8361-666c76f3f3c1-0',
tool_calls=[
{
'name':'multiply_function',
'args':{
'x':100,
'y':200
},
'id':'call_6nNQUiItocW0i67BZStdMZlF',
'type':'tool_call'
}
],
usage_metadata={
'input_tokens':211,
'output_tokens':19,
'total_tokens':230,
'input_token_details':{
'audio':0,
'cache_read':0
},
'output_token_details':{
'audio':0,
'reasoning':0
}
}
),
ToolMessage(content='20000',
name='multiply_function',
id='52a90328-d42c-4391-9454-9ab33b0e4c2a',
tool_call_id='call_6nNQUiItocW0i67BZStdMZlF'),
AIMessage(content='100掛ける200の計算結果は20000です。',
additional_kwargs={
'refusal':None
},
response_metadata={
'token_usage':{
'completion_tokens':16,
'prompt_tokens':239,
'total_tokens':255,
'completion_tokens_details':{
'accepted_prediction_tokens':0,
'audio_tokens':0,
'reasoning_tokens':0,
'rejected_prediction_tokens':0
},
'prompt_tokens_details':{
'audio_tokens':0,
'cached_tokens':0
}
},
'model_name':'gpt-4o-mini-2024-07-18',
'system_fingerprint':'fp_b8bc95a0ac',
'finish_reason':'stop',
'logprobs':None
},
id='run-6586f0b6-e2f2-40aa-9330-d7905b888bab-0',
usage_metadata={
'input_tokens':239,
'output_tokens':16,
'total_tokens':255,
'input_token_details':{
'audio':0,
'cache_read':0
},
'output_token_details':{
'audio':0,
'reasoning':0
}
}
)
]
}
AIMessageのtool_callsにmultiply_functionのツール情報のみが保存されています。
# Graphの実行
result = graph.invoke({"messages": ["1足す2の計算をしてください"]})
# 結果表示
print(result)
出力例は以下の通りです。※出力例は整形表示しています。
{
'messages':[
HumanMessage(content='1足す2の計算をしてください',
additional_kwargs={
},
response_metadata={
},
id='766e74d9-4444-415d-9517-d9f99912a453'),
AIMessage(content='',
additional_kwargs={
'tool_calls':[
{
'id':'call_DPt0KPDmLPWOgXonPzAGl5FE',
'function':{
'arguments':'{"x":1,"y":2}',
'name':'add_function'
},
'type':'function'
}
],
'refusal':None
},
response_metadata={
'token_usage':{
'completion_tokens':19,
'prompt_tokens':210,
'total_tokens':229,
'completion_tokens_details':{
'accepted_prediction_tokens':0,
'audio_tokens':0,
'reasoning_tokens':0,
'rejected_prediction_tokens':0
},
'prompt_tokens_details':{
'audio_tokens':0,
'cached_tokens':0
}
},
'model_name':'gpt-4o-mini-2024-07-18',
'system_fingerprint':'fp_b8bc95a0ac',
'finish_reason':'tool_calls',
'logprobs':None
},
id='run-4c149635-f960-4f29-a72b-8947ecdb8b99-0',
tool_calls=[
{
'name':'add_function',
'args':{
'x':1,
'y':2
},
'id':'call_DPt0KPDmLPWOgXonPzAGl5FE',
'type':'tool_call'
}
],
usage_metadata={
'input_tokens':210,
'output_tokens':19,
'total_tokens':229,
'input_token_details':{
'audio':0,
'cache_read':0
},
'output_token_details':{
'audio':0,
'reasoning':0
}
}
),
ToolMessage(content='3',
name='add_function',
id='c37c23a9-fd9b-4dc2-812a-036f6c6069b8',
tool_call_id='call_DPt0KPDmLPWOgXonPzAGl5FE'),
AIMessage(content='1足す2は3です。',
additional_kwargs={
'refusal':None
},
response_metadata={
'token_usage':{
'completion_tokens':10,
'prompt_tokens':237,
'total_tokens':247,
'completion_tokens_details':{
'accepted_prediction_tokens':0,
'audio_tokens':0,
'reasoning_tokens':0,
'rejected_prediction_tokens':0
},
'prompt_tokens_details':{
'audio_tokens':0,
'cached_tokens':0
}
},
'model_name':'gpt-4o-mini-2024-07-18',
'system_fingerprint':'fp_b8bc95a0ac',
'finish_reason':'stop',
'logprobs':None
},
id='run-ec71e5bc-438f-48e0-9a33-ea25e3300065-0',
usage_metadata={
'input_tokens':237,
'output_tokens':10,
'total_tokens':247,
'input_token_details':{
'audio':0,
'cache_read':0
},
'output_token_details':{
'audio':0,
'reasoning':0
}
}
)
]
}
AIMessageのtool_callsにadd_functionのツール情報のみが保存されています。
# Graphの実行
result = graph.invoke({"messages": ["こんにちは"]})
# 結果表示
print(result)
出力例は以下の通りです。※出力例は整形表示しています。
{
'messages':[
HumanMessage(content='こんにちは',
additional_kwargs={
},
response_metadata={
},
id='d7108f0b-9ba5-487b-ad7a-14346062b8bb'),
AIMessage(content='こんにちは!何かお手伝いできることがありますか?',
additional_kwargs={
'refusal':None
},
response_metadata={
'token_usage':{
'completion_tokens':16,
'prompt_tokens':202,
'total_tokens':218,
'completion_tokens_details':{
'accepted_prediction_tokens':0,
'audio_tokens':0,
'reasoning_tokens':0,
'rejected_prediction_tokens':0
},
'prompt_tokens_details':{
'audio_tokens':0,
'cached_tokens':0
}
},
'model_name':'gpt-4o-mini-2024-07-18',
'system_fingerprint':'fp_b8bc95a0ac',
'finish_reason':'stop',
'logprobs':None
},
id='run-3261cace-04df-4633-94df-66859f1bbcbc-0',
usage_metadata={
'input_tokens':202,
'output_tokens':16,
'total_tokens':218,
'input_token_details':{
'audio':0,
'cache_read':0
},
'output_token_details':{
'audio':0,
'reasoning':0
}
}
)
]
}
AIMessageにtool_callsが存在しないことを確認できます。
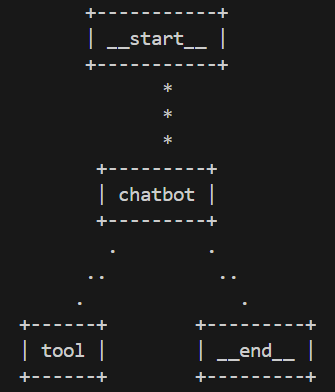
グラフ構造の可視化
今回構築したグラフ構造を可視化します。詳細については「チャットボットの構築」のグラフ構造の可視化と同じ内容のため説明を割愛します。
print(graph.get_graph().print_ascii())
出力例は以下の通りです。
5 最後に
今回は基礎的なシステム構築を通して、LangGraphの基本的な使い方を紹介しました。次回はLangGraphを使用したマルチエージェントシステムについて触れたいと思います。