全体像
ゴール
- Reasoning and Actという推論手法を使った何かを作っていきます。
- ユースケースとして、「社内資料を検索して情報をまとめる」というタスクを取り扱ってみます。
- このユースケースを基に、人間の作業を図に書き出してみました。
- 人間の負担って割と大きくないですか?

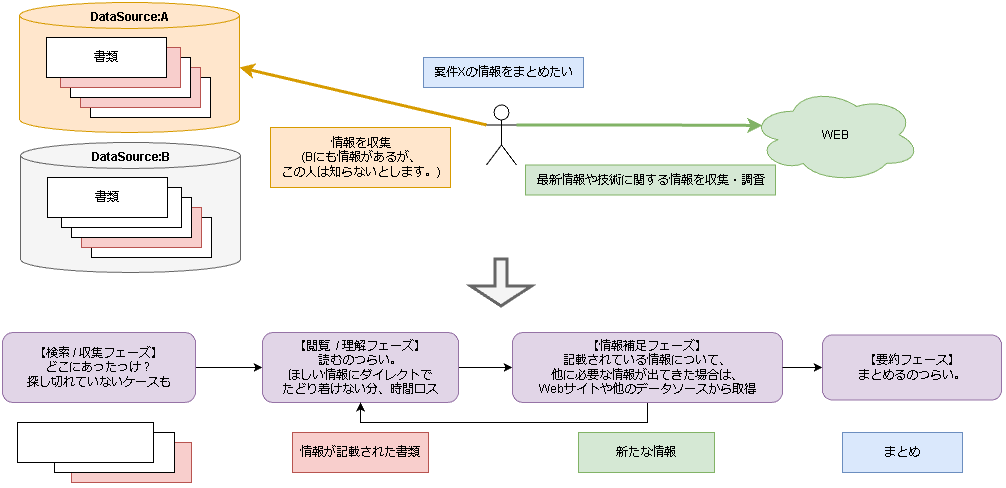
- 今回やりたいことをざっくり説明すると、「上記図の紫で示した人間のタスクをAIにやらせよう」といった具合です。
- 人間がやるべきことは「うまいこと指示を与える」だけで済みますね
- 図では
AI=エージェントと記載しています。
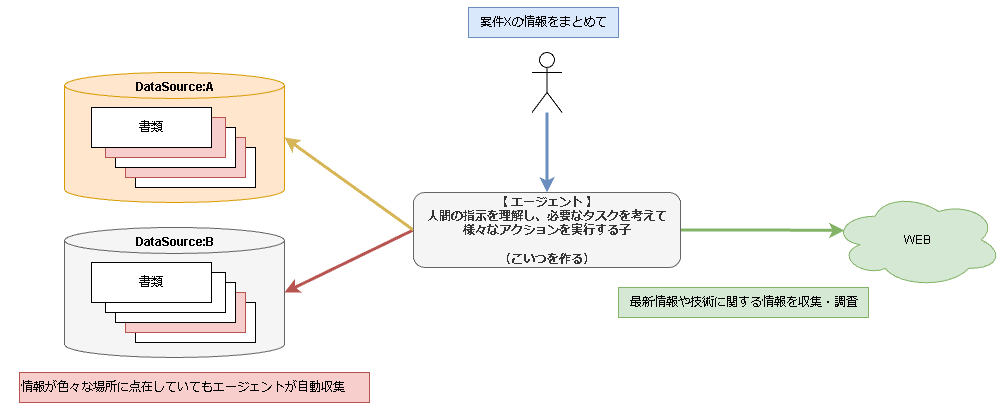
上記図のエージェントを作るために必要なものを調査・実装し、複数回に分けてまとめていきたいと思います。
関連記事
背景・モチベーション
1. ReActを実装してみたい
- Reasoning and Actの略らしいです。
- 夢が広がるアーキテクチャ(?)です。
2. オープンな言語モデルをLangChainに組み込んでみたかった
- オープンなAIの開発が凄まじいので役に立ちそう
3. 無料で色々開発できる環境が欲しかった
- OpenAI APIの無料分18$使い切ってしまった、、Embedding試してたら一瞬でした、、
- オープンなモデルを使えば無料なのでは?というのがコトの発端
- 電気代はかかりそう。
オープンな言語モデルについて
- Metaが手掛けるGPTの対抗馬LLaMAのパラメータファイルが公開されたことにより、オープンなモデルの開発が加速したみたいです。
- ここでは、その派生である
みんなのためのGPT=GPT4ALLを使います。- ややこしい名前、、
- だれでも自由に使えるので、オープン言語モデルを使っていきたいと思います。
参考:
(こちらに流れがまとまっているので覗いてみてください)
Reasoning and Act (ReAct)について
この論文で示されたLLMの活用方法の一種?推論頑張ろうアーキテクチャといえるのかな。
ReActと呼ばれるらしいです。ややこしい。
ChatGPTとかと違うのは、タスク達成のためになにをすべきかを考えて自動で色々としてくれるところですかね。
ReActのイメージ
以下はあくまでイメージです。
原論文のAppendixに実際の例が載っているので気になる方はぜひ原論文見てみてくださいい。
人間:
ア行で始まる都道府県の面積と人口を表にまとめて。
エージェント:
[思考] = 達成に必要なサブタスクは「日本の都道府県の一覧を調べる → ア行でフィルタ→各都道府県の面積と人口を調べる → 表にする」だな。
[行動] = 日本の都道府県の一覧を調べる (Web検索なども可能)
[観察] = 都道府県の一覧を取得できた (ここで、サブタスクを達成できていないとまた「思考」が入り、何が必要か考える)
[行動] = ア行でフィルタする
・
・
・
例の補足
タスクの達成のために、何が必要か考えて必要なアクションを実行してくれます。
GPT単体でQA・テキスト抽出するとかの次元ではなくなり、様々なソース連携できることが強みだと思います。
API連携、Webからの情報収集、社内情報の検索などなど。
(人間がいらなくなるのもそう遠くなさそうですよね、、IBMの採用から分かるように既に仕事を奪われつつありますもんね、、)
まとめると、以下のような感じです。
- 人間
- エージェントに指示を出す
- エージェント
- できることは3つ「思考→行動→観察」
- 指示を与えられると、指示を達成するために何が必要か考えてサブタスクに分解する
- サブタスクを達成するためのアクションを実行
-
実行結果を確認し、サブタスクが満たされているか判断。
- 満たされていたら次へ
- 満たされていないなら何が必要か再度考える
LangChain×オープン言語モデルの実装
いきなりReAct実装するのではなく、ReAct実装に使えそうなLangChainを使ってみようというのが今回のメインです。
LangChainにはいくつかの機能があります。扱うものだけ詳細を記述しています。他の機能は以下の記事が分かりやすかったです。
また、OpenAI APIの無料枠を使い切ってしまったため、LangChainとオープン言語モデルを組み合わせています。
-
Models
- LangChainで使うモデルを指定する
- モデルは大別すると3種類
- LLMs: 色々な言語モデルを使える
- Chat: ChatGPTのようなチャットを行える
- TextEmbedding:文章をベクトルに変換できる
-
Prompts
- モデルに対する指示を与える。Few-Shotも可能。
- ChatGPTがイメージしやすい
- (学習ではなく、推論側で頑張るの面白いですよね。)
- モデルに対する指示を与える。Few-Shotも可能。
- Indexes
- Memory
-
Chains
- 複数の機能を簡単に組み合わせて実行可能
- ユーザ側で組み込んだ言語モデルで推論する際にも使う
-
Agents
- 次回以降扱います
- 指示に従い、色々なタスクを自動で行ってくれる
- Callbacks
手順1.必要なパッケージのインストール
- Pythonパッケージ
langchainとpygpt4allをインストールする
# python仮想環境を作る (いらない人は無視してください)
py -m venv pyenv-langchain
pyenv-langchain/Scripts/Activate # Windows環境です
# パッケージインストール
pip install langchain
pip install pygpt4all
手順2.モデルのダウンロード
ダウンロード
以下からモデルをダウンロードします。
現状ベストと記載されているモデルggml-gpt4all-j-v1.3-groovy.binをダウンロードしました。4GBくらいでした。(※追記:gpt4all-lora-quantized-ggml.binに変更)
※追記
最終的にgpt4all-lora-quantized-ggml.binというモデルをダウンロードして使っています。
色々エラーにはまりました。
ハッシュ確認
ダウンロードしたモデルと上記サイトに記載されているモデルの整合性確認をしておきます。
(Windows環境なのでPowerShellスクリプトです、、ChatGPTにコピペして「~~に変換して」と投げると変換してくれると思います。)
Param(
[Parameter(mandatory=$true)][String]$file_path
)
$hash_dict = @{'ggml-gpt4all-j-v1.3-groovy.bin'='81a09a0ddf89690372fc296ff7f625af'}
echo $hash_dict
Get-FileHash -Algorithm MD5 $file_path | Select-Object -Property Hash, Path
手順3.モデルの読み込み確認
pygpt4allのモジュールを使い、ダウンロードしたモデルを読み込めるか確認します。
from pygpt4all import GPT4All_J
model_path = "D:LLaMa/gpt4all/models/ggml-gpt4all-j-v1.3-groovy.bin"
model = GPT4All_J(model_path=model_path)
- 以下のようにモデルの詳細が表示されたらOKです。
python tests/pygtp4all_test.py
gptj_model_load: n_vocab = 50400
gptj_model_load: n_ctx = 2048
gptj_model_load: n_embd = 4096
gptj_model_load: n_head = 16
gptj_model_load: n_layer = 28
gptj_model_load: n_rot = 64
gptj_model_load: f16 = 2
gptj_model_load: ggml ctx size = 4505.45 MB
gptj_model_load: memory_size = 896.00 MB, n_mem = 57344
gptj_model_load: ................................... done
gptj_model_load: model size = 3609.38 MB / num tensors = 285
※追記
ここで問題なく実行できても、以降のLangChain側でエラーが発生する可能性があります。
そのため、以下から互換性のあるモデルとしてgpt4all-lora-quantized-ggml.binをダウンロードしました。
ダウンロードリンクはこちらです
手順4.モデルの変換 (?)
ここについて詳しい方いれば教えてください、、
langchainはGPT4ALL, GPT4ALL_Jの両方に対応しているっぽいです。
llm = GPT4All(model=local_path, callbacks=callbacks, verbose=True)
# If you want to use GPT4ALL_J model add the backend parameter
llm = GPT4All(model=local_path, backend='gptj', callbacks=callbacks, verbose=True)
ただ、これに倣いbackendを指定するも、エラーが発生。
色々調べているとモデルをconvertする必要がありそうだったので、
ggml-gpt4all-j-v1.3-groovy.binを変換しようと試みるも諦めました、、
この辺りどういう仕組みなんでしょうか。
以下から互換性のあるモデルとして、gpt4all-lora-quantized-ggml.binをダウンロード。
gpt4all-lora-quantized-ggml.binを変換するといけました。
以下、手順です。
git clone https://github.com/ggerganov/llama.cpp.git
pip install -r ./llama.cpp/requirements.txt
# 変換したいモデルのパスを指定して実行
python ./llama.cpp/convert.py /path/to/gpt4all-lora-quantized-ggml.bin
.
.
.
Wrote /path/to/ggml-model-q4_0.bin # ここに変換後のモデルが書き出される
手順5. LangChainの動作確認
やっとLangChainにたどり着きました。
変換後のモデルを利用して、LangChainの動作確認をします。
from langchain import PromptTemplate, LLMChain
from langchain.llms import GPT4All
from langchain.callbacks.streaming_stdout import StreamingStdOutCallbackHandler
# Prompts: プロンプトを作成
template = """Question: {question}
Answer: Let's think step by step."""
prompt = PromptTemplate(template=template, input_variables=["question"])
# Models(LLMs): 変換後のモデルを読み込み
local_path = "/Downloads/gpt4all/models/ggml-model-q4_0.bin"
callbacks = [StreamingStdOutCallbackHandler()]
llm = GPT4All(model=local_path, callbacks=callbacks, verbose=True)
# Chains: 作成したモデルを利用可能な状態にする
llm_chain = LLMChain(prompt=prompt, llm=llm)
# 質問を投げる
question = "How can I get the end of the list in Python?"
llm_chain.run(question)
めちゃくちゃ遅いですが、しばらくしたら回答がきました。
(GPU使ってモデルロードってどうやってやるんだ?)
まとめ
精度はGPT3.5, GPT4に劣りますが、無料で色々と試せる環境を入手できました。
次は、
- HuggingfacePipeLineを使ってローカルGPUを使う方法
- Chat機能とAgent機能の実装
を扱いたいと思います。
開発が捗りそうです: )
トラブルシューティング
①too old, regenerate your model files or convert them with convert-unversioned-ggml-to-ggml.py!
最新版のモデルをダウンロードしてもこのエラーが発生しました。
Versionのことではなく、使おうとしているモデルを変換する必要があるそうです。
上記issueに解決策がありました。
llama.cppのmainブランチにある、convert.pyを実行すればよさそうです。
※追記
ここで、以下のValueError: read length must be non-negative or -1のようなエラーや、
②,③のエラーが出る場合、変換前のモデルに原因がありそうです。
git clone https://github.com/ggerganov/llama.cpp.git
# helpを確認 → モデルへのパスを引数にする必要あり
python ./llama.cpp/convert.py -h
# 変換したいモデルのパスを指定して実行
python ./llama.cpp/convert.py /path/to/local_model
# 上記issueの他の方と同じようにエラーが発生、、
ValueError: read length must be non-negative or -1
3.モデルの読み込み確認に示したように変換元のモデルを変える必要がありそうです。
②AttributeError: 'GPT4All' object has no attribute '_ctx'
①と同じ要領でいけそうです。
③invalid model file (bad magic [got 0x67676d66 want 0x67676a74])
①と同じ要領でいけそうです。
④TypeError: Model.generate() got an unexpected keyword argument 'new_text_callback'
llm_chain.run(questin)でエラーが発生しました。
issueを見ると、pygpt4allのバージョンを==1.0.1にダウングレードするといけると書いてあります。
pip install --updrage pygpt4all==1.0.1