生成AIの進化が目覚ましい今、動画生成AIも飛躍的に発達し、驚くほど高品質な映像を作ることができるようになりました。
前回の記事では、生成AIを使ってコンテンツ制作を行う際の心掛けやコツについて紹介しました。
今回は プログラミング言語を擬人化したアニメ風オープニング映像 を作ってみました。
制作過程で多くの課題と限界に直面しました。その経験をもとに、「後悔したこと(今後活かしたいこと)」 と 「できなかったこと(今後検証していくこと)」 の2つの観点から振り返ってみました。
できなかったことについては、私の知識不足により解決策が存在する可能性もありますが、今後さらに検証を重ねていく予定です。
自分への戒めの意味も込めて、実際の経験を共有し、同じ過ちを繰り返さないよう記録として残したいと思います。
これからコンテンツ制作に取り組む方の参考にもなれば幸いです。
余談
制作時の余談ですが、Java、Rust、Ruby、PHPなど有名な言語のキャラクターも用意していましたが、尺の都合でカットすることになりました😔

使用したAIサービス
画像と動画の生成には主に Midjourney を使用しましたが、本記事の内容はどのAIサービスでも同様に適用できると考えています。

前提
まず前提として、動画生成AIの特性について気づいたことがあります。リアル風映像 と アニメ風映像では生成精度に大きな差があるということです。
- 3次元のリアル風映像:高精度で自然な動きが生成される
- 2次元アニメ風映像:精度が低下し、不自然な動きが多発する
静止画の場合は、どちらのスタイルでも高品質なものを作ることができます。しかし、動画では2次元アニメ風の方が動きの破綻が目立つケースが多々見られました。
注意点
今回は2次元イラストでの検証結果をまとめています。リアル風の人間キャラクターを使った場合は異なる結果になる可能性があります。この点については今後の課題として検証していく予定です。
後悔したこと(今後活かすこと)
後悔したこと① - 曖昧なプロンプトで無駄な時間を浪費
これが最も痛感した失敗です。他の後悔も結局はここに集約されると言っても過言ではありません。
普段からプロンプトの重要性を理解していたはずなのに、なぜか動画生成ではこの基本を軽視してしまいました。その結果:
- 思い通りの結果が得られないことが頻繁に発生
- 特に2次元イラストでは奇妙な動きが多発
- リアル映像と比べて品質の安定性に大きな差
30本作ってもほとんど使えなかったシーン
以下は、アニメOPでよく見る「光に向かって視点が移動する」シーンの制作例です:
元画像:

使用したプロンプト:
カメラが少年の周りを激しく旋回する。少年は少し驚いている。カメラが一人称視点になりながら空の光へズームしていく。少年は映らなくなる。
結果: このシーンだけで30本以上の動画を作成しましたが、どれも使い物になりませんでした。

なんだか暴れていますね😅 他の動画も同様で、首がねじれたり奇妙な動きをしたりと、とても使えるレベルではありませんでした。
その中で、一つだけうまくいったのが以下です。

詳細プロンプトで一発成功した例
ところが、プロンプトを詳細にするだけで劇的に改善することが、動画完成後に判明しました。
ChatGPTに詳細なプロンプトを作成してもらった結果:
the camera begins to rapidly circle around a teenage boy from a low angle, creating a swirling motion that intensifies with each rotation. as the camera spins faster, it gradually rises and tilts upward, transitioning seamlessly into the boy’s first-person perspective. from his viewpoint, the camera suddenly zooms upward toward a blinding light in the sky--pure white and radiant--drawing the viewer into its center. the boy’s figure disappears entirely from view, leaving only the overwhelming brightness above. the background fades into darkness around the light, emphasizing a feeling of ascension, disappearance, or transcendence. the motion is dramatic and fluid, with a cinematic sense of speed and emotion.
このような詳細なプロンプトにすると、1回で満足のいく動画を作ることができました。

どのAIを使う場合でもプロンプトを詳細に書くことで理想の生成結果が得られ、無駄な時間を省けます。
なぜこんな基本的なことを忘れていたのでしょうか…
後悔したこと② - 元画像を軽視していた
動画生成は基本的に「画像から動画を作る」プロセスなので、元画像の品質が最終結果を大きく左右します。
静的な画像 vs ダイナミックな画像の差
元画像に躍動感がなければ、どれほど優れたプロンプトを使っても動的な動画は作ることができません。
以下の比較をご覧ください。同じプロンプトで生成した2枚の画像ですが、躍動感に大きな差があります:
- 1枚目:空中を旋回しておらず、躍動感に欠ける単調なポーズ
- 2枚目:空中を旋回しながら雷を発生させる、今にも攻撃しそうなダイナミックなポーズ
1枚目:

2枚目:

動画生成結果の明確な違い
動画化した1枚目(静的):

動画化した2枚目(動的):

結果は一目瞭然です。躍動感のある元画像から生成した動画の方が、明らかに迫力と自然さが増しています。
💡 学んだ教訓
静的な画像をいくらプロンプトで工夫して動かそうとしても限界があります。元画像の段階で躍動感を作り込むことが成功の鍵でした。
後悔したこと③ - キャラ一貫性を諦めてしまった
シーンごとに違う服装の原因
完成した動画を見ると、キャラクターの服装がシーンごとに異なっていることがわかります。これは制作中の大きな悩みの種でした。
キャラクターの参照機能を使用していましたが、服装の複雑さによって再現精度が大きく変わることがわかりました。
キャラクター一貫性の再現精度:
- シンプルな服装(学生服など):比較的高精度で再現される
- 複雑なデザインの服装:精度が大幅に低下し、全く別の服装になることも
以下は複雑な服装のキャラクター例です:

AIの限界だと諦めていたこと
問題のあるアプローチ:
「少年が歩いている」という曖昧なプロンプトを使用
結果:

当初はAIの技術的限界だと諦めていました。しかし制作後に「もしかして詳細な指定で解決できるのでは?」と思い直しました。
改善されたアプローチ:
キャラクターの特徴を非常に詳細に指定してテスト
An anime-style cheerful teenage boy walking forward. He has messy black hair with blonde highlights, golden eyes, and a bright, friendly smile. He is wearing a lime green graphic T-shirt under a navy blue open jacket, with black pants rolled up at the ankles. He wears red high-top sneakers and is captured mid-step, with one foot slightly ahead as he walks naturally. A brown messenger bag hangs from his shoulder, and a pair of large black headphones rest around his neck. He also wears a whistle-like pendant. In his left hand, he casually holds a small blue globe with grid lines. The background can be plain white or a simple modern street scene. His expression is relaxed and curious, giving off a modern, tech-savvy, and optimistic vibe.

制作後に発見した解決策
重要な教訓: 生成プロンプトには毎回キャラクターの詳細情報を含める
残念ながら、この発見は動画制作後のことでした。もし最初から知っていれば...
実際の修正例:
サビの部分では、最初は曖昧なプロンプトを使っていたため全く違うキャラクターになってしまいました。この発見後、該当シーンだけは作り直しましたが、他の部分は時間と気力の問題でそのままにしています😅
修正前のサビ部分:

修正後のサビ部分:

この経験は次回の制作で活かしていきたいと思います。
不一致な部分は自分への戒めとして、あえてそのままにしています😅
後悔したこと④ - 日本語プロンプトへのこだわり
同じ内容でも英語の方が高精度
多くの生成AIは英語での学習データが豊富なため、英語プロンプトの方が高精度という傾向が見られます。
実際に同じキャラクターで日本語と英語のプロンプトを比較検証してみました 🌏
参照キャラクター:

日本語プロンプト:
アニメ風の元気な少年キャラクターが歩いているシーン。くしゃっとした黒髪に金色のハイライトが入り、目は金色で明るい笑顔を浮かべている。ライムグリーンのグラフィックTシャツの上にネイビーのジャケットを羽織り、黒いパンツの裾を足首でロールアップしている。赤いハイカットスニーカーを履いて、歩く動作の途中で片足を前に出している。肩には茶色のショルダーバッグ、首には黒いヘッドホンと笛のようなペンダントを下げている。左手には青い地球儀(グリッド線付き)を軽く持っている。背景はシンプルな白または街の通学路でも可。ポーズは自然でリラックスしており、歩きながら前を見て笑っている。現代的でテックに強く、好奇心旺盛な雰囲気を表現。
日本語での生成結果:

英語プロンプト(内容は同じ):
An anime-style cheerful teenage boy walking forward. He has messy black hair with blonde highlights, golden eyes, and a bright, friendly smile. He is wearing a lime green graphic T-shirt under a navy blue open jacket, with black pants rolled up at the ankles. He wears red high-top sneakers and is captured mid-step, with one foot slightly ahead as he walks naturally. A brown messenger bag hangs from his shoulder, and a pair of large black headphones rest around his neck. He also wears a whistle-like pendant. In his left hand, he casually holds a small blue globe with grid lines. The background can be plain white or a simple modern street scene. His expression is relaxed and curious, giving off a modern, tech-savvy, and optimistic vibe.
英語での生成結果:

結果を比較すると、英語プロンプトの方がより参照キャラクターに近い特徴を再現できていることがわかります。
これは画像生成AIに限らず、他のAIでも英語の方が高精度な結果が得られることが多いという周知の事実と一致します。
できなかったこと
「後悔したこと」が人的ミスや知識不足によるものだったのに対し、ここでは技術的な限界や現状のサービスでは実現できなかったことをまとめていきます。
私の知識不足や調査不足により解決策が存在する可能性もありますが、現時点では以下のような課題があると感じました。
できなかったこと① - アニメOPの王道パターンの実現
これが最も困難だった課題です。複数のキャラクターを同じ画面で一貫性を保ちながら動かすことは、現在の技術では非常に困難でした。
複数キャラ演出の技術的障壁
-
複数キャラ表示の技術的限界
- 複数キャラクターの登場自体は可能
- しかし動画化時に複雑な指示を与えると動きが破綻する
-
キャラクター一貫性の問題
- 仮に動きが成功しても服装・髪型・顔つきが変化してしまう
- これは2次元イラストで特に顕著に現れる
目指した「キャラが一人ずつ登場」シーン
目指していたのは「僕のヒーローアカデミア」のOPのような、アニメOPの王道パターン「キャラクターが一人ずつ格好よく登場」するシーンでした。

断念して採用した代替手段
結果的に、一つの動画内で複数キャラクターを理想的に動かすことは断念せざるを得ませんでした。
代替案: 複数キャラクターシーンの代わりに、個別キャラクターにフォーカスした動画をつなげる方式に変更しました。

🔍 今後の検証計画
このような複数キャラクターシーンを実現できるサービスが存在する可能性もありますが、私の調査範囲では見つけることはできませんでした。
次のステップとして話題のVeo3を使った検証を計画しています。より高性能なAIであれば、この課題を克服できるかもしれません。
できなかったこと② - 映像のディレクション能力
AIと人間の得意領域の違い
今回の制作で最も痛感したのは、創作における人間とAIの役割分担の重要性です。
例えば、以下の様にシーンをカットし、繋ぎ方を工夫することで、より魅力的な動画に仕上げるためには人間のクリエイティブな判断が不可欠でした。

AIが得意な領域:
- 🎵 歌詞の生成(ある程度魅力的な内容を作成)
- 🎬 個別シーンのアニメーション(指示通りの動きを生成)
- 🎨 キャラクターデザイン(詳細指定で高品質な画像)
人間が担うべき領域:
- 🎭 全体の構成・ストーリー展開の設計
- 🎞️ シーン間の繋がりや流れの演出
- 💡 視聴者の感情を動かすクリエイティブな発想
シーン構成で直面した3つの壁
1. アイデア枯渇の問題
後半の制作において、シーンのアイデアが枯渇し、作業が雑になってしまいました😅
2. 構成スキルの不足
1分程度の短い動画でも:
- シーンの考案や繋ぎ方にセンスが必要
- カット割りの効果的な配置が困難
- 視聴者を飽きさせない構成の難しさ
3. AIによる提案の限界
AIにシーン構成を相談しても:
- 単調で予測可能な構成になりがち
- 物足りない内容の提案が多い
- 感情的な盛り上がりを作れない
技術進歩と人間の役割の将来
重要な気づき: 動画制作において、技術的な生成能力と創作的な構成力は全く別のスキルだということです。
AIが画像や動画の生成技術で飛躍的な進歩を遂げても、「どんなシーンをどの順番で見せるか」「どうやって視聴者の心を掴むか」といったディレクション能力は、まだまだ人間の領域だと実感しました。
将来的にAIがさらに進化すれば、この領域でも魅力的な提案をしてくれる日が来るかもしれませんが、現時点では人間のクリエイティブな判断が不可欠だと感じました。
できなかったこと③ - 迫力あるアクションシーン
日常動作 vs 非日常アクションの大きな壁
アニメOPの花形である迫力のあるバトルシーンを実現したかったのですが、私は現在のAI技術を使って実現することができませんでした。
現在のAIが得意な動き vs 苦手な動き:
✅ 日常的な動作:歩く、走る、踊るなど
❌ 非日常的アクション:戦闘、スポーツなど
ロボット戦闘シーンでぶつかった壁
チャレンジ①:ロボットへの雷攻撃
「雷でロボットを攻撃し、ロボットが爆発する」シーンを目指しましたが…
元画像にロボットがいない場合:

⚠️ 問題点: 動画化時に新たなオブジェクト(ロボット)を登場させるのが難しい
元画像にロボットが包含されている場合:

✅ 成功例: 爆発エフェクトが自然に生成された
チャレンジ②:スタート/エンドフレーム指定
より精密な制御を目指して、Kling AIを使用して、スタートとエンドフレームを指定し、以下のプロンプトでテスト:
少年が黄色いコートと黒いパンツ姿で空中に浮かび、手から稲妻を放ってロボットを攻撃する。未来都市のデジタルスクリーンが光る背景で、ロボットの頭部が青白いエネルギーコアを爆発させ、金属破片が火花と共に飛散する。カメラは固定され、緊張感ある戦闘の瞬間を捉える。
結果:
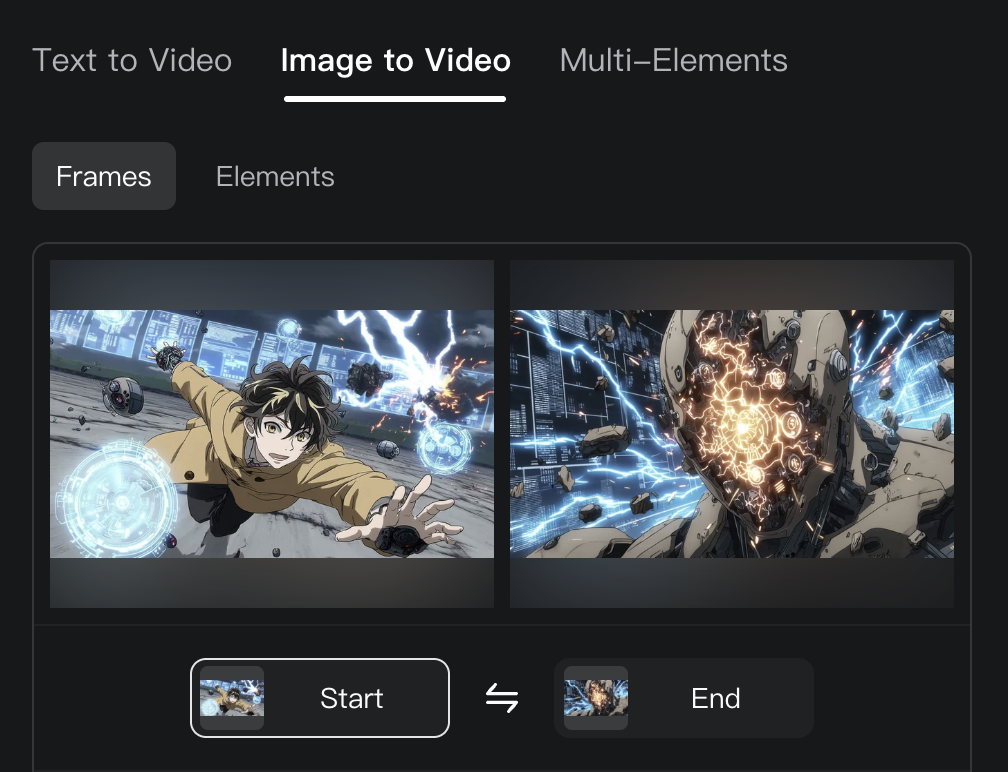

期待した結果とは程遠い仕上がりになってしまいました。
動画プロンプトより元画像が重要だった
重要な気づき:
最も難しいのは、ロボットが映っていて、かつ躍動感に満ちた元画像を作ることでした。
この経験から学んだ教訓:
💡 動画化のプロンプトを練る < 元画像の品質を高める
サッカーシーンでも同様の困難
戦闘以外の複雑な動きとして、サッカーシーンでもテストしてみました。
チャレンジ:シュートシーン
失敗例:

やや成功例:

ドリブルシュートシーン(失敗例):

リアル風では比較的マシだった
リアル風での結果比較:
リアル風では「スラム街でリフティングする少年」というプロンプトで、以下のような動画が生成できました。

ただ、ドリブルシュートシーンを生成しようとすると、あまり自然な動きとは言えない以下のような結果になってしまいました。

複雑アクション生成の現在地
現在の技術的限界:
✅ 可能なこと:
- 日常的な動作の自然な再現
- リアル風映像でのシンプルなスポーツ動作
- 元画像に含まれる要素の動き
❌ 困難なこと:
- 2次元アニメ風での複雑なアクション
- 新たなオブジェクトの途中登場
- 精密なタイミングや物理演算が必要な動き
この分野は、AI技術の今後の進化に大いに期待したい領域です!
おわりに
人的ミス vs 技術的限界の明確な分類
アニメ風OP制作を通じて、人的ミスによる後悔とAI技術で実現できなかったことを多く学ぶことができました。
後悔したこと(人的ミス):
- プロンプトの詳細化不足
- 元画像の躍動感への無関心
- キャラクター一貫性への無理解
- 日本語プロンプトへのこだわり
できなかったこと(技術的限界):
- 複数キャラクターの同時出演
- シーン構成の創作的ディレクション
- 2次元での複雑なアクションシーン
現在のAI動画制作でできること・できないこと
現在達成可能なレベル:
工夫と知識があれば、「それなりに見られる作品」は十分作成可能
まだ難しいレベル:
「真にプロフェッショナルな高品質作品」の制作には、まだ人間のクリエイティブな判断が不可欠
数年後には「プロンプト1つでOP完成」の時代が来る?
しかし、AIの進化スピードは凄まじいものがあります。
数年後には「プロンプト1つでアニメ風OPが完成!」という時代が来るかもしれません。
そんな未来を楽しみに、これからもAI技術の発展を見守っていきたいと思います!