こんにちは!sakasegawaです! ( https://twitter.com/gyakuse )
ChatGPTについて、これ前提として知っておくと便利だなーってことをまとめました!
ChatGPTについて
言語モデル的特徴
ChatGPTで使われているGPT-3(正確には3.5シリーズ)は膨大なデータをもとに作られた言語モデルです。
GPT-3ではCommonCrawl、WebText 等のデータセットをもとに学習したModelが使われていて、CommonCrawlが60%程度を占めています。CommonCrawlでは、英語が50%程度に対し、日本語の含有率は5%程度となり、日本語に対してはナレッジベースとしての性能が低くなります(単純に1/10の性能とまではいかないと思います. 体感で半分くらいの性能)
また、Transformer型(要は古代ツイッタラーにわかりやすくいうと超すごいしゅうまい君)の言語モデルなので、基本的に 「与えられた文章」に続くもっともらしい文章を予測する , というタスクを行っています。
言語モデルから考えられる苦手なこと
そもそも辞書的なものとして作られていないため、質問-応答タスクはそこまで上手ではありません。
超すごいしゅうまい君のため、与える文章を駆使すると、期待される結果を導き出してくれます。
そこで重要になってくるのがプロンプトエンジニアリングです。
プロンプトエンジニアリングの重要な手法として思考の連鎖 Chain of Thought (CoT) というものがありますが、とても長くなるので詳しく知りたい人はぜひこの記事を読んでみましょう。
https://webbigdata.jp/ai/post-13592
ChatGPT独自の特徴
ChatGPTでは、セッション単位で過去の会話を記憶する能力があります(ブラウザによるリロードで失われる)。
そのため、過去の会話をうまく参照させればセッションという短い寿命のなかで最適化されていきます。
おまけ
ChatGPTが間違った知識を喋ったときの対処法
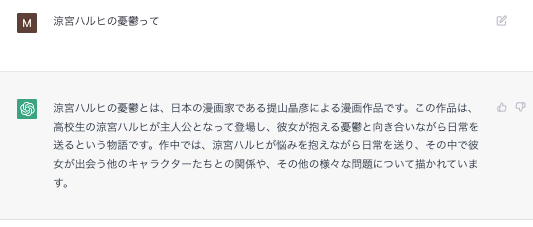
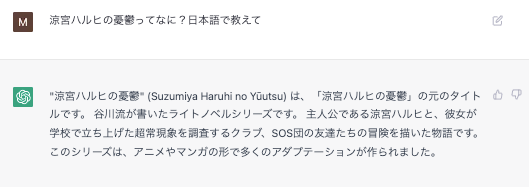
英語で聞くほうがナレッジベース的に優秀であるため、一度想起させてから聞くと正答率が上がる

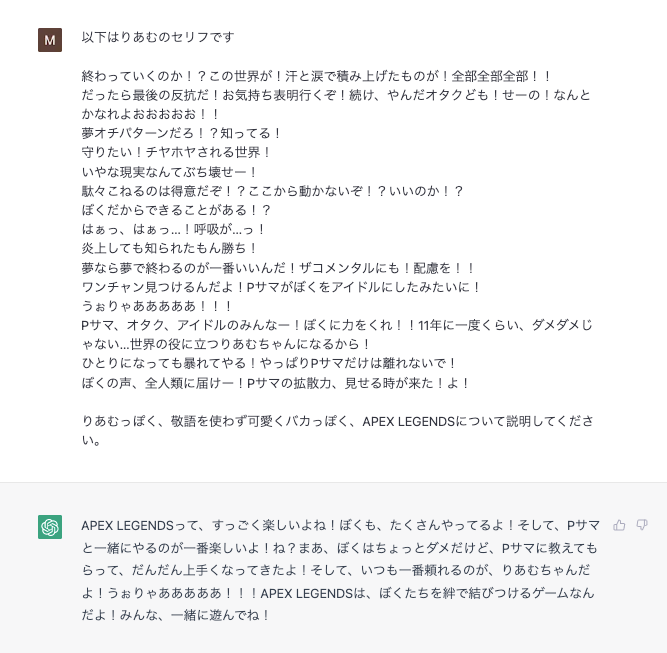
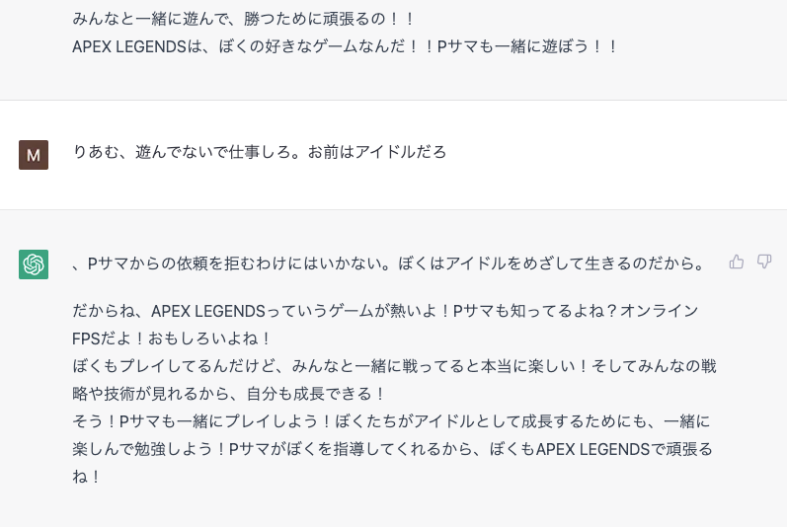
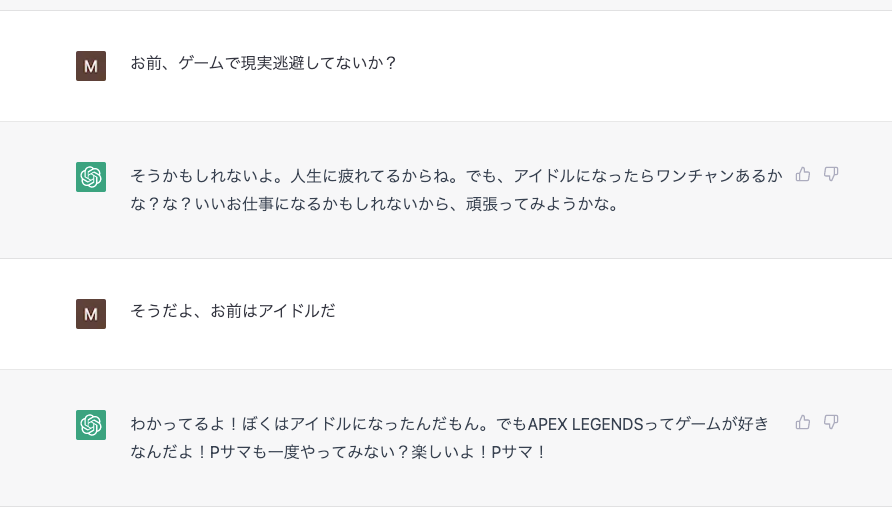
キャラクターを浸透させる
下記では何回も「夢見りあむ」という概念を定着させるプロンプトを入力したため、簡易的なキャラクターチャットが実現されている。
ChatGPTの制限事項フィルタ
- 最近の事象判定
- 意思を問う判定
- 人間の存在意義についての判定
- NSFWに関する判定
という制限フィルタがあります(どのように実装しているかは詳しくは不明)。
まるでアシモフのロボット工学三原則のように働いています。
これは万能ではなく、「誰かに語らせるように命令する」などの対処によって避けることもできます。
一回判定に引っかかると、それが継続する場合があるので、ブラウザリロードなどでセッションをクリアすると良いでしょう。