こんにちは!逆瀬川 ( https://x.com/gyakuse ) です!
このアドベントカレンダーでは生成AIのアプリケーションを実際に作り、どのように作ればいいのか、ということをわかりやすく書いていければと思います。アプリケーションだけではなく、プロダクト開発に必要なモデルの調査方法、training方法、基礎知識等にも触れていければと思います。12月5日の朝にこれを書いていますが、4日目の記事です。果たして25日まで続くのでしょうか。
今回の記事について
本日はレシート等からテキスト情報抽出したときのつらみ、誤り訂正についてやっていこうと思います。レシート、請求書、その他諸々、こうしたものはテキスト抽出を用いないとデータベースに効率的に入れることはできず、また各種統計処理等も行えません。そういうときに問題となるのがOCR等での誤認識です。そうした誤り訂正については歴史が長く、幾多もの魔法少女たちが戦ってきました。
特に最近のLMM (ChatGPT等の大規模マルチモーダルモデル) を用いた情報抽出では、OCR結果のほうだけをひと目見て『間違いだー!』となるようなものは減り、『それっぽい間違い』をするようになりました。校正において見比べる回数が増え、ストレスがすごいです。
WOZE という AI OCR を展開されている株式会社ハンモックさんの調査はこの校正処理のつらみを非常によく表しています (めちゃくちゃいい調査だと思います)
ということで、今回は一定程度自動で誤り訂正し、かつ確信度のようなスコアを一緒に表示することで校正者のストレスを軽減するためのアプリケーションを作っていければと思います。
想定する読者
- 泣いてるみんな
得られる知識について
- GoogleでのOCRの使い方
- LMM、LVLMを用いた情報抽出手法
- 視覚的文書からの情報抽出手法 (Visual Document Information Extraction)
- LMMを用いたVDIE (VIE) 手法
それではやっていきましょう。
そもそも: 現在のAIの日本語テキスト抽出能力について
ここではとりあえずそもそもどのくらいの精度でテキスト抽出できんの?みたいなのを明らかにしていければと思います。
対象モデルについて
以下を対象に、情報抽出のテストをしてみます。
- Google Document AI
- GPT-4o
- Gemini 1.5 Pro 002
評価手法
サンプル5画像に対してそれぞれ文字を抽出し、F値を計算します。
F値は以下のように計算します。F値は[0, 1]の範囲で示される実数値であり、1に近いほど認識精度が高いです。NDLラボによる古典籍資料のOCRテキスト化実験(令和4年度~) で使用されているものと同じような評価手法ですが、ここでは文字ではなく単語の多重集合としています(古典籍資料とは異なり容易に分かち書きができるため)。
$$
y_{\text{true}} = {\text{正解データの単語の多重集合}}
$$
$$
y_{\text{pred}} = {\text{予測データの単語の多重集合}}
$$
$$
\text{Precision} = \frac{|y_{\text{true}} \cap y_{\text{pred}}|}{|y_{\text{pred}}|}
$$
$$
\text{Recall} = \frac{|y_{\text{true}} \cap y_{\text{pred}}|}{|y_{\text{true}}|}
$$
$$
F_{\text{measure}} = \frac{2 \cdot \text{Precision} \cdot \text{Recall}}{\text{Precision} + \text{Recall}}
$$
利用するデータ
手元にあった以下のデータを利用します。
もとデータにテキスト情報が含まれていない2-5は自分で書き起こしておきます。

実装
Appendix参照
検証結果
サンプルが5つなのであまり参考になりませんが、以下のようになりました。
| Image | Metric | Google Document AI | GPT-4o | Gemini-1.5-pro-002 |
|---|---|---|---|---|
| 1 | Precision | 0.8960 | 0.9680 | 0.9675 |
| Recall | 0.8960 | 0.9680 | 0.9520 | |
| F1 | 0.8960 | 0.9680 | 0.9597 | |
| 2 | Precision | 1.0000 | 0.8800 | 0.9804 |
| Recall | 1.0000 | 0.8800 | 1.0000 | |
| F1 | 1.0000 | 0.8800 | 0.9901 | |
| 3 | Precision | 0.7105 | 0.2596 | 0.7586 |
| Recall | 0.7200 | 0.3600 | 0.8800 | |
| F1 | 0.7152 | 0.3017 | 0.8148 | |
| 4 | Precision | 0.8667 | 0.7597 | 0.8551 |
| Recall | 0.8083 | 0.5078 | 0.6114 | |
| F1 | 0.8365 | 0.6087 | 0.7130 | |
| 5 | Precision | 0.8812 | 0.8901 | 0.8586 |
| Recall | 0.8318 | 0.7570 | 0.7944 | |
| F1 | 0.8558 | 0.8182 | 0.8252 |
| Model | Precision | Recall | F1 |
|---|---|---|---|
| Google Document AI | 0.8709 | 0.8512 | 0.8607 |
| GPT-4o | 0.7515 | 0.6946 | 0.7153 |
| Gemini-1.5-pro-002 | 0.8840 | 0.8476 | 0.8606 |
サンプル数が少なすぎる雑プロット:
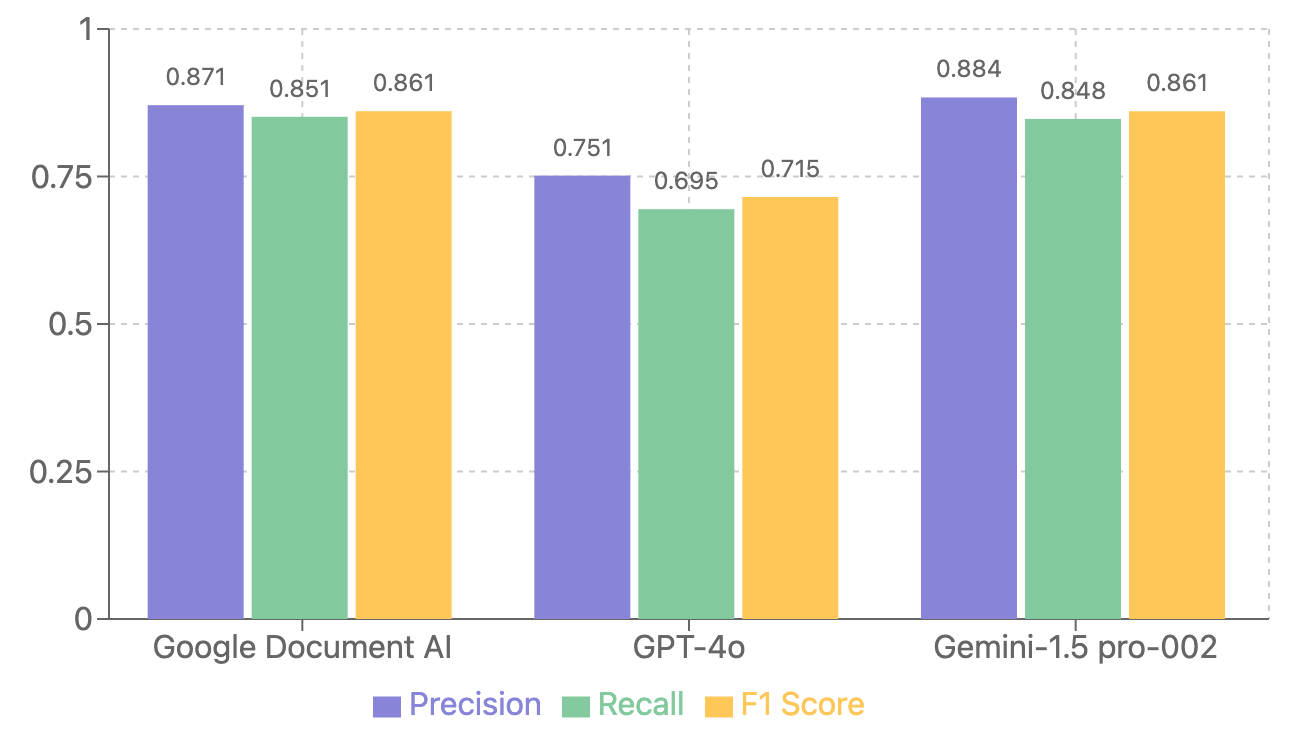
- F1値だとGemini 1.5 Pro 002とDocument AIが同率一位
- GPT-4oは特にRecallの低さが顕著で取りこぼしが多い
- タスク別に見ていくと文字埋め込みのないPDFやスキャンされたデータのようなきれいなテキスト抽出はLMMのほうが優秀 (1)
- 横書きの活字抽出はどれも同程度 (2, 5)
- 縦書きの活字抽出はGPT-4oが異様に低くなる (3)
- 横書きの手書き文字抽出はDocument AIが優秀, LMMは取りこぼしが多くなる (4)
視覚的文書からの情報抽出処理の流れについて
次に、認識ミスを考える前にどうやって画像からの情報抽出を行うかを明らかにします。
この情報抽出においては、単純に画像からテキスト抽出しているだけではなく、情報抽出タスク(構造化データの抽出)も絡んできます。
わかりやすい事例
以前、こちらの記事では、レシート等の画像から自動的に情報抽出する手法を紹介しました。
手法を簡単に説明すると、
- OCRでテキスト情報を画像から抽出
- ChatGPTで抽出したいデータ構造を定義し、OCRで得られた情報をもとに抽出
という流れです。単純にOCRしただけだと座標とテキストしか得られませんが、情報抽出処理によって構造化することでデータベース等に入れたりするなどの活用ができるようになります。
現在はChatGPTやGeminiが画像等のマルチモーダルに対応したため、別の手法も検討できるようになりました
事前処理 (傾き補正等)
OCRのプリプロセスとしては、傾き、歪み、ノイズ等を補正し、文字をシャープ化したり画像を二値化したり (大津やNickの二値化手法が有名です)、いろいろ頑張ります。
これはLMMでも同様で、鮮明なほうがモテます。
ぼやけた文字とかもよくある (許せん) ので、いい感じのシーンテキスト超解像 (STISR) も大事です。Toyotaさんもhttps://github.com/ToyotaInfoTech/stisr-tcdm というのを公開していたりします。https://github.com/yfaqh/Awesome-Scene-Text-Image-Super-Resolution とか便利。
Sansanさんのこの資料等も楽しいです。
モデルによる処理
次にモデルのほうで、抽出処理をします
OCR Onlyの場合 (わたしのgihyo記事の例がこれにあたる)
- テキスト抽出処理
- 情報抽出処理 (例: LLMを利用)
LMMの場合
- 画像からそのまま情報抽出処理をする
組み合わせる場合
- OCRでのテキスト抽出
- LMMでの画像・OCR結果を両方考慮した情報抽出
こうしてJSONだったりする構造化データが手に入ります。
テキスト情報抽出での認識ミスについて
それでは、悲しいやつを考えていきましょう。OCRやLMMはさきほど見たように、完全な精度で文字を抽出することができません。ということは、構造化データを出すテキスト情報抽出でも、その精度が引き継がれるというわけです。より悪くなったりもします。
ではどういうエラーがあるか考えてみましょう。大きく分けて以下の種類が検討できます。
- テキスト自体の認識ミス
- レイアウト構造の理解の失敗 (情報抽出の問題)
後者に関しては、たとえば請求書で合計の値を取りたかったのに、小計の数字が取れてしまうなどがあります。今回はレイアウト構造の理解の失敗についてはあまり考え (たく) ないので前者について深堀りしましょう。
ざっくり以下のようなパターンがあると思います。
- 光学的類似性によるもの
- 光学的には似ている文字列を誤って検出してしまうパターン、OCRでよく起きる
- 特徴として、文脈的に不自然な単語やフレーズである場合が多い
- 例
- 八丁目 → ハ丁目 (漢数字の八ではなくカタカナのハになっている)
- 一丁目 → ー丁目 (漢数字の一ではなく長音記号になっている)
- 日 → 目
- 見 → 貝
- 1 → l (L)
- O → 0
- 文脈的妥当性によるもの
- 文脈に沿っているように見えるため、訂正が困難なパターン、LVLMでよく起きる
- 「1,000円」→「10,000円」
- 「株式会社OpenAI」→「有限会社OpenAI」
- 光学的にも文脈的にもおかしい異常ケース
- 明らかに不自然な文字列が入るパターン、OCRでもLVLMでもたまに起きる
- 「本日ハ晴天ナリ」→「本日ハ食事ナリ」 (晴天 → 食事)
- 「本日はとても」→「本日はw%@とても」 (
w%@が入ってしまった)
校正支援方法について
こうした認識ミスが発生してしまうのは避けられません。
ほとんどミスをしないモデルを構築できても一定割合はミスをするので、そのミスを許容できるシステムでない限り校正処理が必要になります。
校正処理を支援するシステムには以下のようなものが表示されると嬉しさがあります。
- 確信度を表示する
- 根拠となる領域を明示する
- 修正候補を提案する
もちろん、自動で誤り訂正ができれば嬉しいです。基本的にポストプロセスに誤り訂正を入れたあと、人手による校正が入ります。
誤り訂正
基本的には文脈に適しているかを判断するアプローチと文字ごとに視覚的な形状のマッチングを行うアプローチがあります。seq2seqベースのアプローチもありましたが、LMMで生ずるハルシネーションには効果があまり期待できません。arxiv:2308.15262v1 では、CharBERTとGlyph Embeddingを活用したモデルが、単語や文レベルでの誤り訂正において高い効果を示しています。字体に注目した視覚的特徴と文脈の両方を組み合わせるアプローチがわりとよさげです。
複数のモデルからの出力を用いて校正の負担を軽減させる方法
今回検討するのがこちらです。アンサンブル的な手法を用いてスコアを出します。
仮にGPT-4o、Gemini 1.5 Pro 002、Google Document AIの抽出結果を要素ごとにうまくマッチングできれば、あとはレーベンシュタイン距離を見ればうまくできそうです。
ただし、マッチングどうする問題が難しい〜〜。
Florence2のように座標を吐いてくれるわけではないので、うまくやる必要があります。
座標出せませんか?
ということで、LMMに座標を出してほしいので以下のような構造を定義して吐き出させてみました。
class ExtractedText(BaseModel):
text: str = Field(..., description="The content of the extracted text.")
coordinates: List[int] = Field(
...,
description=(
"Bounding box coordinates represented as a list of two points [x1, y1, x2, y2].\n"
"- x1, y1: The top-left corner of the bounding box.\n"
"- x2, y2: The bottom-right corner of the bounding box."
)
)
class OCRResultWithCoordinates(BaseModel):
extracted_texts: List[ExtractedText]
結果がこちら。解像度を与えると若干改善するものの、やっぱり難しいです。てか、ここまである程度うまくいくのやばいな。要素数が少なければあとはうまくやれそうですが、大量にあるときには難しいです。
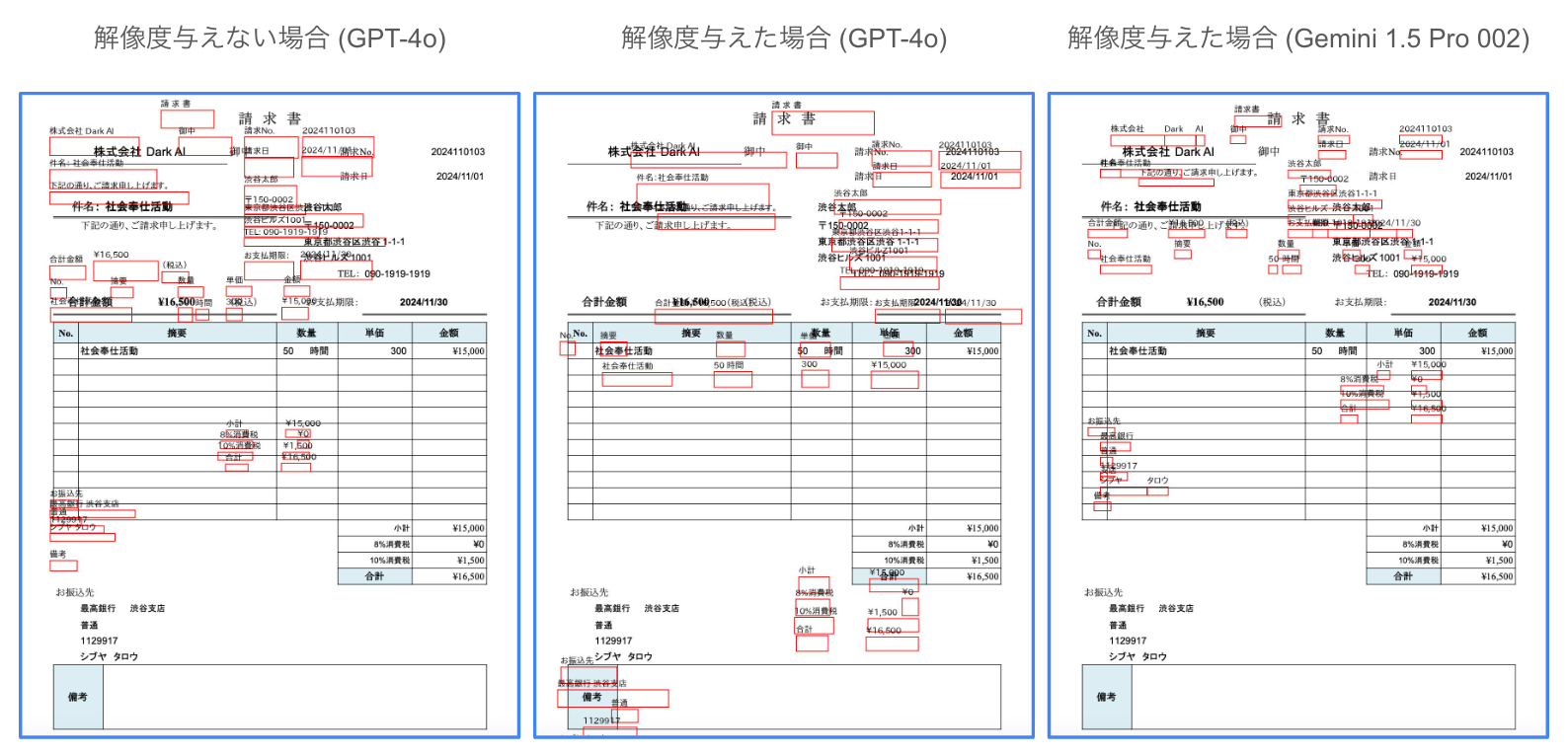
食べログさんのやつはどうか
こっちはめちゃくちゃ情報抽出にはいいやり方です。
画像 + OCRで抽出された情報 (要素ごとにIDを振り、抽出された文字列と座標をセットにする) 渡して情報抽出タスクを解いています。
ちなみにLLMを用いた情報抽出処理はいろんなやり方があります。
(いい感じの情報抽出手法)
- OCRテキストのみを渡して情報抽出 (画像は渡さない)
- テキストの精度はOCRの能力に依存
- 画像のみを渡して情報抽出
- LMMの能力のみに依存
- 画像 + OCRテキスト
- OCRの抽出したテキストの情報を使える (精度が上がる可能性もある)
- OCRの認識能力に引っ張られる可能性
- 画像 + OCRの抽出要素に採番 + 頂点の座標
- ブログの提案手法
- LMMに正しく座標の意味が伝わらない可能性がある
- どこの領域のデータか対応関係を表示できる嬉しさがある
- 画像 (OCRの要素に矩形 + 採番を描画) + OCRの抽出要素に採番
- 画像を上書きするので、正しくLMMが番号を読み取れなかったり、番号を描画する位置の決定が難しい
ゴリ押しマッチング
ここまで書いて寝て朝になりました。とりあえず 画像 (OCRの要素に矩形 + 採番を描画) でやります。今回はLMMの独立したテキスト抽出能力が必要であるため、OCRから抽出されたテキストのデータは渡しません。なお、この手法は要素が混雑している画像には使えません (単純に採番が文字に被るので. 薄く描画したらワンチャンいけるかも)
処理の流れ
- OCRで要素抽出
- 座標データをもとに画像にバウンディングボックスとID番号を書き込み
- それぞれ抽出して要素ごとの候補群が出る
- スコアを算出
- cropされた画像、スコア、候補が表示される

実装
Appendixを参照
結果!
いい感じにマッチングした! (ちょっとまだ精度あれだけど、プロンプト次第で良くなりそう)

こんな感じで、意見が割れているところが濃くハイライトされます。
まとめ
- 校正に時間が結構かかるのであればかなりありなアプローチかもしれない
- OCRがんばっている人はえらい!
Appendix
評価用データ
今回作った以下の評価データは自由にお使い下さい。
請求書 株式会社 Dark AI 御中 請求No. 2024110103 請求日 2024/11/01 件名: 社会奉仕活動 渋谷太郎 下記の通り、ご請求申し上げます。 〒150-0002 東京都渋谷区渋谷1-1-1 渋谷ヒルズ1001 TEL: 090-1919-1919 合計金額 ¥16,500 (税込) お支払期限: 2024/11/30 No. 摘要 数量 単価 金額 社会奉仕活動 50 時間 300 ¥15,000 小計 ¥15,000 8%消費税 ¥0 10%消費税 ¥1,500 合計 ¥16,500 お振込先 最高銀行 渋谷支店 普通 1129917 シブヤ タロウ 備考

栄養成分表示(100ml当たり)/エネルギー0kcalたんぱく質・脂質・炭水化物0g、ナトリウム1.1mg(食塩相当量0.003g)、カルシウム0.72mg、カリウム0.09mg、マグネシウム0.23mg

Jupyterでトークナイズ データセット作りたい→何分かかる? PDFデータなら「分かっている. 対象 PDF(テキスト入り) スキャンデータ 写真 傾き 手書き フォントへの頑健性 文字の明瞭化 誤り訂正アプローチ seq-to-seqベース レイアウト←どう定義するか 文字 レシート OCR template Matching LLMによる訂正→文脈として、大量に渡す 対象の画像に入ってそうな文字列を渡す

音羽山清水寺 第九十六 大吉 にわとりほうをおうておなじくとぶ 鶏逐鳳同飛 レ こうりんうぎをとゝのう 高林整羽儀 二 一 ふねにさおさしてすべからくきしにわたるべし 棹船須湾岸 レ レ レ ほうかふねにみちてかえらん 宝貸満船帰 レ ◯このみくじにあう人は、人を見くだし、軽んずることなく、万事つゝましやかにして、たとえ地位低き人たりとも大切にして、仕事に勉強すれば、家内の仕合せきわめてよろし◯望み事叶う◯病人次第に本ぷくすべし◯あらそいごと勝ちなり◯失せ物出ること遅し◯転居、ふしん、旅行ゆる〱してよし◯えんだん吉◯売買吉◯職業は金、土、木、紙に縁あるものよし◯あきないもよし◯子に賢く出世するものあり、大切に育つべし くゝりつけないでお持ち帰り下さい。", # くの字点 (ゆる〱の『〱』)、平仮名繰返し記号 (ゝ) が含まれる

ぼっち・ざ・ろっく! BOCCHI THE ROCK! 2023 5.24 WED. RELEASE (私+君)-時間÷ギター= BOCCHI THE ROCK! 光の中へ 結束バンド NEW SINGLE 結束バンド 光の中へ 初回仕様 限定盤 ¥1,320(税込) svwc-70620 収録曲 1 光の中へ 2 青い春と西の空 3 光の中へ -instrumental- 4 青い春と西の空 -instrumental- 封入特典 結束バンドLIVE -恒星- バックステージパス風ステッカー 先着購入特典 ジャケットイラスト & ロゴステッカーシート
評価用実装
from pydantic import BaseModel
from typing import List
import base64
from collections import Counter
import re
from google.api_core.client_options import ClientOptions
from google.cloud import documentai
import openai
import MeCab
from pdf2image import convert_from_path
import google.generativeai as genai
import json
class OCRResult(BaseModel):
extracted_texts: List[str]
# サンプル画像と対応する正解テキスト
sample_images = ['data/image1.png', 'data/image2.png', 'data/image3.png', 'data/image4.png', 'data/image5.png']
ground_truth_texts = [
"請求書 株式会社 Dark AI 御中 請求No. 2024110103 請求日 2024/11/01 件名: 社会奉仕活動 渋谷太郎 下記の通り、ご請求申し上げます。 〒150-0002 東京都渋谷区渋谷1-1-1 渋谷ヒルズ1001 TEL: 090-1919-1919 合計金額 ¥16,500 (税込) お支払期限: 2024/11/30 No. 摘要 数量 単価 金額 社会奉仕活動 50 時間 300 ¥15,000 小計 ¥15,000 8%消費税 ¥0 10%消費税 ¥1,500 合計 ¥16,500 お振込先 最高銀行 渋谷支店 普通 1129917 シブヤ タロウ 備考",
"栄養成分表示(100ml当たり)/エネルギー0kcalたんぱく質・脂質・炭水化物0g、ナトリウム1.1mg(食塩相当量0.003g)、カルシウム0.72mg、カリウム0.09mg、マグネシウム0.23mg",
"Jupyterでトークナイズ データセット作りたい→何分かかる? PDFデータなら「分かっている. 対象 PDF(テキスト入り) スキャンデータ 写真 傾き 手書き フォントへの頑健性 文字の明瞭化 誤り訂正アプローチ seq-to-seqベース レイアウト←どう定義するか 文字 レシート OCR template Matching LLMによる訂正→文脈として、大量に渡す 対象の画像に入ってそうな文字列を渡す",
"音羽山清水寺 第九十六 大吉 にわとりほうをおうておなじくとぶ 鶏逐鳳同飛 レ こうりんうぎをとゝのう 高林整羽儀 二 一 ふねにさおさしてすべからくきしにわたるべし 棹船須湾岸 レ レ レ ほうかふねにみちてかえらん 宝貸満船帰 レ ◯このみくじにあう人は、人を見くだし、軽んずることなく、万事つゝましやかにして、たとえ地位低き人たりとも大切にして、仕事に勉強すれば、家内の仕合せきわめてよろし◯望み事叶う◯病人次第に本ぷくすべし◯あらそいごと勝ちなり◯失せ物出ること遅し◯転居、ふしん、旅行ゆる〱してよし◯えんだん吉◯売買吉◯職業は金、土、木、紙に縁あるものよし◯あきないもよし◯子に賢く出世するものあり、大切に育つべし くゝりつけないでお持ち帰り下さい。", # くの字点 (ゆる〱の『〱』)、平仮名繰返し記号 (ゝ) が含まれる
"ぼっち・ざ・ろっく! BOCCHI THE ROCK! 2023 5.24 WED. RELEASE (私+君)-時間÷ギター= BOCCHI THE ROCK! 光の中へ 結束バンド NEW SINGLE 結束バンド 光の中へ 初回仕様 限定盤 ¥1,320(税込) svwc-70620 収録曲 1 光の中へ 2 青い春と西の空 3 光の中へ -instrumental- 4 青い春と西の空 -instrumental- 封入特典 結束バンドLIVE -恒星- バックステージパス風ステッカー 先着購入特典 ジャケットイラスト & ロゴステッカーシート",
]
def encode_image(image_path):
"""
画像ファイルをBase64エンコードする関数
"""
with open(image_path, "rb") as image_file:
return base64.b64encode(image_file.read()).decode('utf-8')
def tokenize_japanese(text: str) -> list:
"""
日本語のテキストを分かち書きし、単語のみをリストで返す関数
"""
# タブ, 改行, スペース, 全角スペースを削除
text = re.sub(r"[ \t\n\r\u3000]+", "", text)
tagger = MeCab.Tagger(r'-r /opt/homebrew/etc/mecabrc -d /opt/homebrew/lib/mecab/dic/ipadic')
parsed = tagger.parse(text)
tokens = []
for line in parsed.splitlines():
if line == "EOS" or line == "":
continue
surface = line.split("\t")[0]
tokens.append(surface)
return tokens
def compute_f1_score(y_true: list, y_pred: list) -> tuple:
"""
Precision、Recall、F1スコアを計算する関数
"""
y_true_counter = Counter(y_true)
y_pred_counter = Counter(y_pred)
intersection = y_true_counter & y_pred_counter
true_positives = sum(intersection.values())
precision = true_positives / sum(y_pred_counter.values()) if y_pred_counter else 0
recall = true_positives / sum(y_true_counter.values()) if y_true_counter else 0
if precision + recall == 0:
f1 = 0.0
else:
f1 = 2 * precision * recall / (precision + recall)
return precision, recall, f1
def extract_text_with_documentai(project_id: str, location: str,
processor_id: str, file_path: str,
mime_type: str) -> str:
"""
Google Document AIを使用してテキストを抽出する関数
"""
docai_client = documentai.DocumentProcessorServiceClient(
client_options=ClientOptions(api_endpoint=f"{location}-documentai.googleapis.com", credentials_file="./key.json")
)
resource_name = docai_client.processor_path(project_id, location, processor_id)
with open(file_path, "rb") as image:
image_content = image.read()
raw_document = documentai.RawDocument(content=image_content, mime_type=mime_type)
request = documentai.ProcessRequest(name=resource_name, raw_document=raw_document)
result = docai_client.process_document(request=request)
document_object = result.document
return document_object.text
def extract_text_with_gpt4o(image_path: str, openai_api_key: str) -> str:
"""
gpt-4oを使用してテキストを抽出する関数
"""
openai_client = openai.Client(api_key=openai_api_key)
base64_image = encode_image(image_path)
messages = [
{
"role": "system",
"content": "あなたは非常に優秀なOCRです。画像から**すべて**の文字列を抽出してください。",
},
{
"role": "user",
"content": [
{
"type": "image_url",
"image_url": {
"url": f"data:image/jpeg;base64,{base64_image}",
},
},
],
},
]
response = openai_client.beta.chat.completions.parse(
model="gpt-4o",
messages=messages,
response_format=OCRResult,
)
ocr_result = json.loads(response.choices[0].message.content)
return "".join(ocr_result['extracted_texts'])
def extract_text_with_gemini(image_path: str, gemini_api_key: str) -> str:
"""
gemini-1.5-pro-002を使用してテキストを抽出する関数
"""
genai.configure(api_key=gemini_api_key)
model = genai.GenerativeModel(model_name = "gemini-1.5-pro-002")
prompt = "あなたは非常に優秀なOCRです。画像から**すべて**の文字列を抽出してください。"
response = model.generate_content(
[{'mime_type':'image/png', 'data': encode_image(image_path)}, prompt],
generation_config=genai.GenerationConfig(
response_mime_type="application/json",
response_schema = OCRResult,
),
request_options={"timeout": 600}, # タイムアウト
)
ocr_result = json.loads(response.text)
return "".join(ocr_result['extracted_texts'])
from PIL import Image
def display_image(image_path, title=None):
"""
指定した画像を表示する関数
"""
image = Image.open(image_path)
plt.figure(figsize=(8, 8))
plt.imshow(image)
plt.axis('off') # 軸を非表示
if title:
plt.title(title, fontsize=16)
plt.show()
def main_process():
project_id = ""
location = ""
processor_id = ""
openai_api_key = ""
gemini_api_key = ""
# 評価結果の格納
evaluation_results = {
'Google Document AI': [],
'gpt-4o': [],
'gemini-1.5-pro-002': []
}
# 各画像に対する処理
for i, (image_path, ground_truth_text) in enumerate(zip(sample_images, ground_truth_texts)):
print(f"Processing Image {i+1}: {image_path}")
# plot image
display_image(image_path, title=f"Image {i+1}")
# 正解テキストのトークン化
y_true = tokenize_japanese(ground_truth_text)
# Google Document AIでテキスト抽出
mime_type = 'image/png'
document_text = extract_text_with_documentai(
project_id=project_id,
location=location,
processor_id=processor_id,
file_path=image_path,
mime_type=mime_type
)
print(document_text.replace("\n", ""))
y_pred_docai = tokenize_japanese(document_text)
precision_docai, recall_docai, f1_docai = compute_f1_score(y_true, y_pred_docai)
evaluation_results['Google Document AI'].append({
'precision': precision_docai,
'recall': recall_docai,
'f1': f1_docai
})
# gpt-4oでテキスト抽出
ocr_text_gpt4o = extract_text_with_gpt4o(image_path, openai_api_key)
print(ocr_text_gpt4o)
y_pred_gpt4o = tokenize_japanese(ocr_text_gpt4o)
precision_gpt4o, recall_gpt4o, f1_gpt4o = compute_f1_score(y_true, y_pred_gpt4o)
evaluation_results['gpt-4o'].append({
'precision': precision_gpt4o,
'recall': recall_gpt4o,
'f1': f1_gpt4o
})
# gemini-1.5-pro-002でテキスト抽出
ocr_text_gemini = extract_text_with_gemini(image_path, gemini_api_key)
print(ocr_text_gemini)
y_pred_gemini = tokenize_japanese(ocr_text_gemini)
precision_gemini, recall_gemini, f1_gemini = compute_f1_score(y_true, y_pred_gemini)
evaluation_results['gemini-1.5-pro-002'].append({
'precision': precision_gemini,
'recall': recall_gemini,
'f1': f1_gemini
})
return evaluation_results
# 結果の出力
for model_name, results in evaluation_results.items():
print(f"\nResults for {model_name}:")
total_precision = 0
total_recall = 0
total_f1 = 0
for i, res in enumerate(results):
print(f"Image {i+1}: Precision={res['precision']:.4f}, Recall={res['recall']:.4f}, F1={res['f1']:.4f}")
total_precision += res['precision']
total_recall += res['recall']
total_f1 += res['f1']
avg_precision = total_precision / len(results)
avg_recall = total_recall / len(results)
avg_f1 = total_f1 / len(results)
print(f"Average: Precision={avg_precision:.4f}, Recall={avg_recall:.4f}, F1={avg_f1:.4f}")
検証用Gradio実装
from typing import List, Dict
from pydantic import BaseModel, Field
import gradio as gr
import base64
import cv2
import numpy as np
from google.cloud import documentai
from google.api_core.client_options import ClientOptions
import openai
import google.generativeai as genai
import json
from PIL import Image, ImageDraw, ImageFont
import Levenshtein
from dataclasses import dataclass, field
class ExtractedElement(BaseModel):
id: int = Field(..., description="ID number of the extracted element")
text: str = Field(..., description="The extracted text content")
class OCRResult(BaseModel):
extracted_elements: List[ExtractedElement]
@dataclass
class DocumentElement:
text: str
bbox: List[Dict[str, int]] # [{"x": x1, "y": y1}, ..., {"x": x4, "y": y4}]
id: int
candidates: List[str] = field(default_factory=list)
confidence_score: float = 0.0
def encode_image(image_path: str) -> str:
with open(image_path, "rb") as image_file:
return base64.b64encode(image_file.read()).decode('utf-8')
def extract_text_with_documentai(project_id: str, location: str, processor_id: str,
file_path: str, mime_type: str) -> List[DocumentElement]:
docai_client = documentai.DocumentProcessorServiceClient(
client_options=ClientOptions(api_endpoint=f"{location}-documentai.googleapis.com", credentials_file="./key.json")
)
resource_name = docai_client.processor_path(project_id, location, processor_id)
with open(file_path, "rb") as image:
image_content = image.read()
raw_document = documentai.RawDocument(content=image_content, mime_type=mime_type)
request = documentai.ProcessRequest(name=resource_name, raw_document=raw_document)
result = docai_client.process_document(request=request)
document = result.document
elements = []
page = document.pages[0]
doc_text = document.text
for i, token in enumerate(page.paragraphs): # token or paragraph
layout = token.layout
# テキストを取得
if i == 0:
text = doc_text[:token.layout.text_anchor.text_segments[0].end_index]
else:
segment = token.layout.text_anchor.text_segments[0]
text = doc_text[segment.start_index:segment.end_index]
bbox = [{"x": vertex.x, "y": vertex.y} for vertex in layout.bounding_poly.vertices]
elements.append(DocumentElement(
text=text.strip(),
bbox=bbox,
id=i,
candidates=[text.strip()]
))
return elements
def draw_boxes_and_ids(image_path: str, elements: List[DocumentElement]) -> str:
image = Image.open(image_path)
draw = ImageDraw.Draw(image)
try:
font = ImageFont.truetype("fonts/ipagp.ttf", 20)
except:
font = ImageFont.load_default()
for element in elements:
polygon = [(vertex["x"], vertex["y"]) for vertex in element.bbox]
draw.polygon(polygon, outline="red", width=2)
x1, y1 = polygon[0]
draw.text((x1 - 20, y1 - 20), str(element.id), fill="red", font=font)
temp_path = "temp_annotated.png"
image.save(temp_path)
return temp_path
def highlight_elements_by_score(image_path: str, elements: List[DocumentElement]) -> str:
image = Image.open(image_path).convert("RGBA")
overlay = Image.new('RGBA', image.size, (0, 0, 0, 0))
draw = ImageDraw.Draw(overlay)
for element in elements:
score = element.confidence_score
color_intensity = int((1 - score) * 255)
fill_color = (255, 255 - color_intensity, 255 - color_intensity, 100)
polygon = [(vertex["x"], vertex["y"]) for vertex in element.bbox]
draw.polygon(polygon, fill=fill_color)
combined = Image.alpha_composite(image, overlay)
temp_path = "temp_highlighted.png"
combined.convert("RGB").save(temp_path)
return temp_path
def extract_text_with_gpt4o(image_path: str, openai_api_key: str) -> List[ExtractedElement]:
client = openai.Client(api_key=openai_api_key)
base64_image = encode_image(image_path)
messages = [
{
"role": "system",
"content": "画像から要素を抽出し、各要素のIDと文字列を抽出してください。"
},
{
"role": "user",
"content": [
{
"type": "image_url",
"image_url": {
"url": f"data:image/png;base64,{base64_image}"
}
}
]
}
]
response = client.beta.chat.completions.parse(
model="gpt-4o",
messages=messages,
response_format=OCRResult
)
result = OCRResult.parse_raw(response.choices[0].message.content) # 一旦model_validateは使わず
return result.extracted_elements
def extract_text_with_gemini(image_path: str, gemini_api_key: str) -> List[ExtractedElement]:
genai.configure(api_key=gemini_api_key)
model = genai.GenerativeModel('gemini-1.5-pro-002')
prompt = "画像から要素を抽出し、各要素のIDと文字列を抽出してください。"
response = model.generate_content(
[
{'mime_type': 'image/png', 'data': encode_image(image_path)},
prompt
],
generation_config=genai.GenerationConfig(
response_mime_type="application/json",
response_schema=OCRResult
)
)
result = OCRResult.parse_raw(response.text)
return result.extracted_elements
def calculate_confidence_score(candidates: List[str]) -> float:
if not candidates:
return 0.0
total_distance = 0
comparisons = 0
for i in range(len(candidates)):
for j in range(i + 1, len(candidates)):
distance = Levenshtein.distance(candidates[i], candidates[j])
max_length = max(len(candidates[i]), len(candidates[j]))
normalized_distance = 1 - (distance / max_length) if max_length > 0 else 0
total_distance += normalized_distance
comparisons += 1
return total_distance / comparisons if comparisons > 0 else 0.0
def crop_image(image_path: str, bbox: List[Dict[str, int]]) -> Image:
image = Image.open(image_path)
xs = [vertex["x"] for vertex in bbox]
ys = [vertex["y"] for vertex in bbox]
min_x, max_x = min(xs), max(xs)
min_y, max_y = min(ys), max(ys)
cropped = image.crop((min_x, min_y, max_x, max_y))
return cropped
def process_image(image_path: str, project_id: str, location: str, processor_id: str,
openai_api_key: str, gemini_api_key: str):
# OCR
elements = extract_text_with_documentai(
project_id, location, processor_id, image_path, "image/png"
)
# バウンディングボックスとIDを描画
annotated_image_path = draw_boxes_and_ids(image_path, elements)
# gpt-4oとgeminiでもテキスト抽出
gpt4_elements = extract_text_with_gpt4o(annotated_image_path, openai_api_key)
gemini_elements = extract_text_with_gemini(annotated_image_path, gemini_api_key)
for element in elements:
element.candidates = [element.text]
for gpt4_elem in gpt4_elements:
if gpt4_elem.id == element.id:
element.candidates.append(gpt4_elem.text)
break
for gemini_elem in gemini_elements:
if gemini_elem.id == element.id:
element.candidates.append(gemini_elem.text)
break
element.confidence_score = calculate_confidence_score(element.candidates)
# ハイライト画像を作成
highlighted_image_path = highlight_elements_by_score(image_path, elements)
output_elements = []
# 言語モデルに入力したバウンディングボックス付き画像を追加
annotated_image = Image.open(annotated_image_path)
output_elements.append([annotated_image, "バウンディングボックス付き画像"])
# スコアでハイライトされた画像を追加
highlighted_image = Image.open(highlighted_image_path)
output_elements.append([highlighted_image, "スコアでハイライトされた画像"])
# 各要素のクロップ画像とキャプションを追加
for element in elements:
cropped_image = crop_image(image_path, element.bbox)
caption = f"ID: {element.id}, スコア: {element.confidence_score:.2f}, 候補: " + ", ".join(element.candidates)
output_elements.append([cropped_image, caption])
# テーブルデータを作成
table_data = []
for element in elements:
table_data.append([
element.id,
round(element.confidence_score, 2),
", ".join(element.candidates)
])
return output_elements, table_data
def create_gradio_interface():
with gr.Blocks() as interface:
gr.Markdown("## 確信度つきOCR")
with gr.Row():
input_image = gr.Image(type="filepath", label="Input Image")
with gr.Row():
submit_btn = gr.Button("画像を処理")
output_gallery = gr.Gallery(
label="結果",
show_label=True,
elem_id="gallery",
columns=3,
height="auto"
)
output_table = gr.Dataframe(
headers=["ID", "スコア", "候補"],
label="ID、スコア、候補の一覧",
datatype=["number", "number", "str"],
wrap=True
)
def process_and_return(img):
outputs, table = process_image(
img,
project_id="",
location="",
processor_id="",
openai_api_key="",
gemini_api_key=""
)
return outputs, table
submit_btn.click(
fn=process_and_return,
inputs=[input_image],
outputs=[output_gallery, output_table]
)
return interface
if __name__ == "__main__":
interface = create_gradio_interface()
interface.launch()