Deep Neural Networksは、独立同分布を前提とした静的なデータセット上で絶大な性能を発揮する一方で、動的な環境下で逐次的に知識を蓄積するContinual Learning (CL)、特にClass-Incremental Learning (CIL) のシナリオでは深刻な課題を抱えています。CILでは、テスト時にタスク識別子が与えられないため、過去のクラスと新しいクラスを区別する必要があり、多くの手法が性能を著しく低下させます。
従来、CILで有効とされてきたのは、過去のサンプルをメモリに保持し、再学習に利用するReplay Methodsのみでした。
しかし、これらの手法も課題を抱えています。下の図1は、代表的なReplay MethodであるDERとFDRが、新しいクラス(縦の点線)を学習した際に、既存クラスに対する精度が一時的に急落し、その後Replayによって回復する様子を示しています。これは、新しいタスクへの最適化が既存タスクの表現を破壊し、それをReplayによって再学習していることを示唆しています。
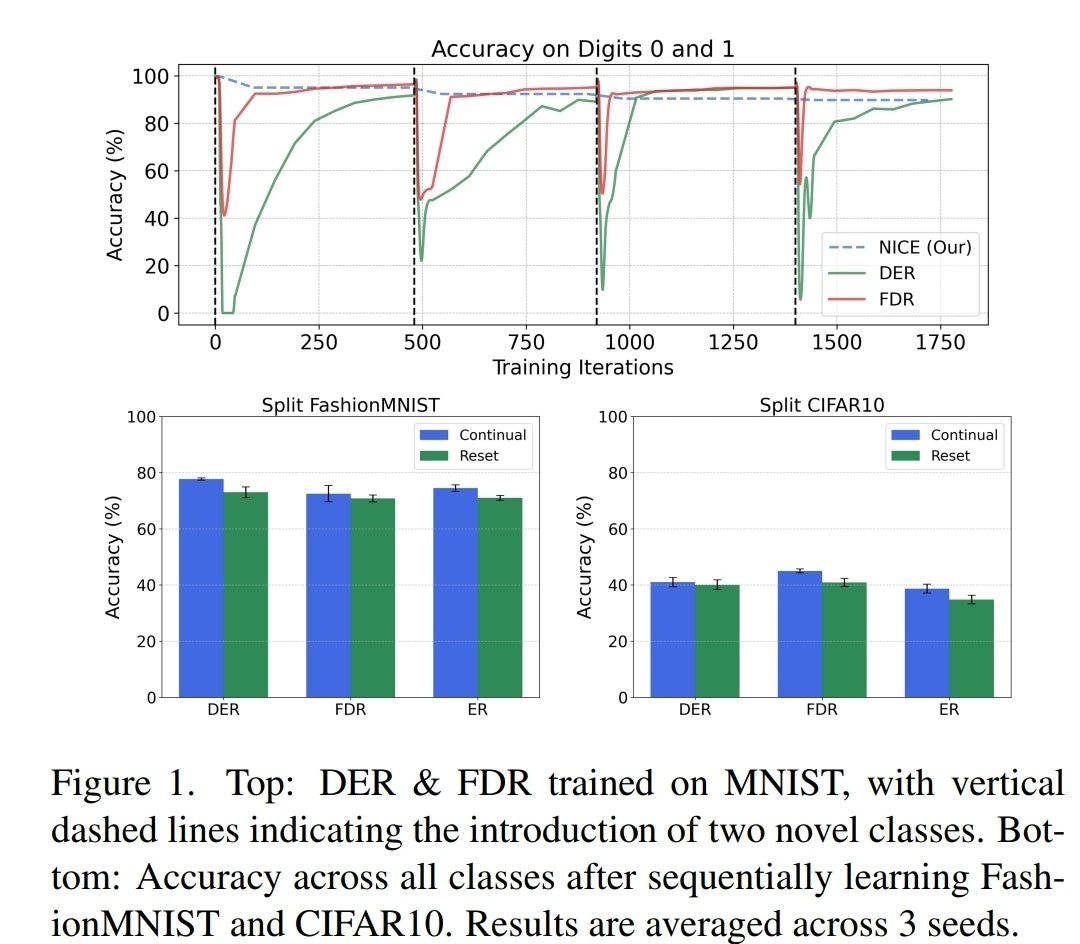
図1: 新規クラス導入時の既存クラスに対する精度変化
一方、ネットワーク構造を変更して知識の干渉を防ぐArchitectural Methodsは、その多くがタスク識別子を必要とするため、Task-Incremental Learning (TIL) にその有効性が限定されていました。
本記事で解説するNICE (Neurogenesis Inspired Contextual Encoding)は、この状況を打破する手法です。NICEはReplay-freeのArchitectural Methodでありながら、CILのシナリオで最先端のReplay Methodsに匹敵、あるいはそれを凌駕する性能を達成しました。その着想は、海馬の歯状回における成体神経新生 (adult neurogenesis) にあります。この神経科学的プロセスは、新しい経験の表現を分離し、文脈の弁別 (contextual discrimination) を可能にすることで、既存の記憶を破壊することなく新しい情報を効率的に統合する上で重要な役割を果たします。
NICEのコアメカニズム
NICEの構造は、**「ニューロンの年齢に基づく可塑性の制御」と「活性化パターンに基づく文脈推論」**という2つの柱で構成されます。
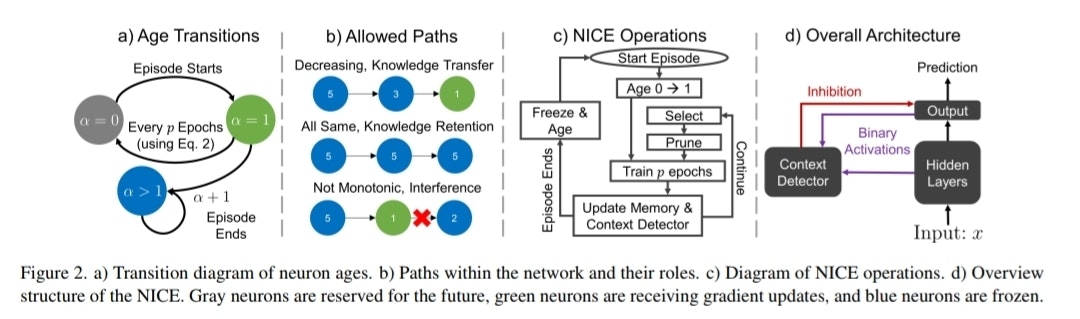
図2: NICEの概要
- ニューロンの年齢と動的な可塑性制御
NICEは、ネットワーク内の全ニューロンに「年齢 (age)」という属性を付与し、その年齢に応じて役割と可塑性を動的に変化させます。
- Age=0 (Surplus Capacity): まだネットワークに統合されていない、将来の学習のための予備ニューロン群。
- Age=1 (Immature & Plastic): 高い可塑性を持ち、現在学習中のエピソードに特化して最適化される未成熟ニューロン。
- Age>1 (Mature & Frozen): 学習を完了し、可塑性を失った成熟ニューロン。過去の知識を安定的に保持するメモリとしての役割を担う。
図2-aが示すように、新しいエピソードが始まると、Age-0のニューロン群が一時的にAge-1に遷移し、学習に参加します。そしてpエポックごとに、各層のAge-1ニューロンの活性度に基づき、寄与の大きい上位ニューロンのみが選択され、残りはAge-0に戻されます。
この選別プロセスは、層の総活性の$\tau$(論文では0.95)を達成する最小のニューロン集合を選択する最適化問題として定式化されます。エピソードが終了すると、生き残ったAge-1ニューロンは1つ歳をとり、Age-2へと成熟します。
2. 干渉の回避とゼロ・フォーゲッティング
過去の知識を保護するため、NICEはネットワーク内の情報伝達パスを厳格に制御します。図2-bに示すように、ニューロンの年齢が単調非増加 (monotonically non-increasing) となるパスのみが許容されます。
- Decreasing Path (年齢減少): 成熟ニューロンから未成熟ニューロンへのパス。過去の知識を現在の学習へ転移させる役割を担います。
- Same-Age Path (同年齢): 特定エピソードの知識表現のバックボーンを形成します。
- Increasing Path (年齢増加): 未成熟ニューロンが成熟ニューロンに影響を与えることを防ぐため、このパスはプルーニングによって完全に遮断されます。
この構造は、以下の2つの操作によって実現されます。 - Age>1のニューロンへの入力接続を全て凍結 (freezing)。
- 若いニューロンから古いニューロンへの接続をプルーニング。
これにより、Age≥2のニューロン群は将来の勾配更新から完全に隔離され、理論上、忘却が全く発生しない (zero forgetting) ことが保証されます。
3. Context-Detectorによる動的なサブネットワーク選択
タスク識別子なしに、入力サンプルに対してどの知識(どの年齢のニューロン群)を使用すべきかを判断するのがContext-Detectorの役割です(図2-d)。
左: Context-Detectorの推論 / 右: ニューロンの活性化パターンの差異
Context-Detectorは、ネットワーク全体の活性化を閾値処理して得られるバイナリベクトルを観測値として利用します。
そして、図3に示すように、この観測値を基に、入力サンプルがどの過去のエピソードに由来するかを確率的に推論します。この推論は、エピソードごとに学習された連鎖的なロジスティック回帰モデルによって行われます。
この推論が可能な根拠は、図5に示されています。これはOut-of-Distribution (OOD) detectionの研究でも指摘されている現象ですが、ニューロンは学習済みのIn-Distribution (ID)データに対しては密で強い活性化パターンを示す一方、未学習のOODデータに対しては疎で弱い活性化パターンを示します。NICEはこの性質を利用し、各エピソードの知識から見て他のエピソードのデータがOODサンプルとして振る舞うことを捉え、文脈を特定します。推論されたエピソードに基づき、対応する年齢の出力ニューロン以外をマスクすることで、適切なサブネットワークを動的に選択し、予測を行います。
実験結果と考察
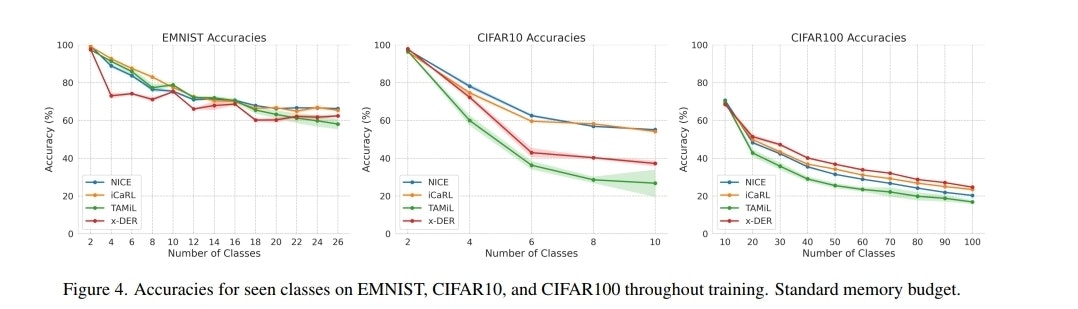
図4: 主要データセットにおける学習進行ごとの精度比較
図4および論文内のTable 2が示すように、NICEは複数のデータセットにおいて、標準的なメモリバジェットでSOTAのReplay Methodsを上回る最終精度を達成しました。これは、タスク識別子に依存しないArchitectural Methodとして驚くべき成果です。
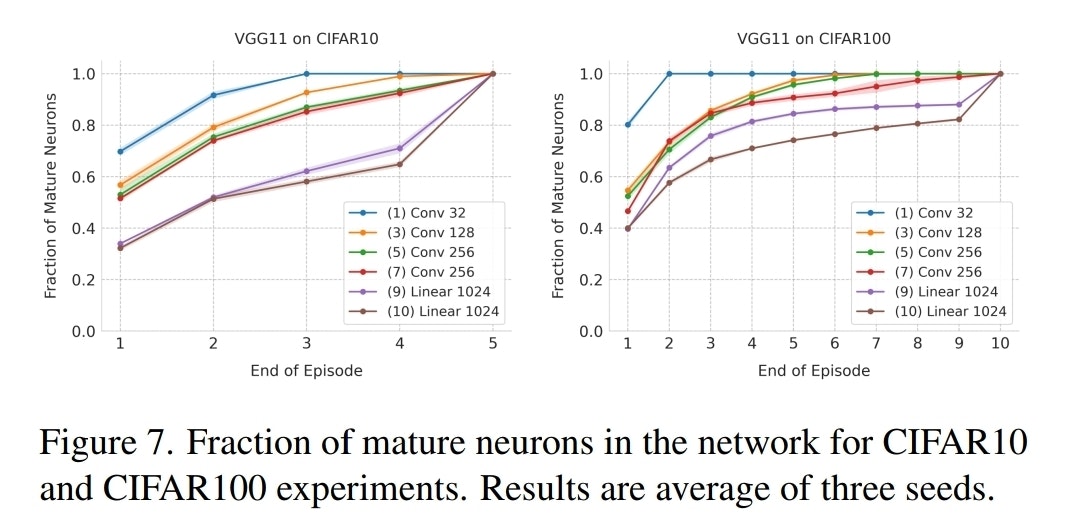
図7: 各層における成熟ニューロンの割合の推移
また、図7は、学習が進むにつれてネットワークのどの層の可塑性が失われていくかを示しています。DNNの初期層(Conv層)が後期層(Linear層)よりも早く成熟(凍結)し、ニューロンリソースを使い切る傾向が見られます。これは、初期層がより汎用的でタスク間で共通する低レベル特徴を学習し、早い段階でその表現が安定することを示唆していると考えられます。
結論と今後の展望
NICEは、成体神経新生という神経科学的知見を計算モデルに昇華させ、Replay-freeなCILへの新たな道筋を示しました。ニューロンの年齢に基づく可塑性の動的制御と、活性化パターンを利用した文脈推論という独創的なアプローチにより、既存の強力なReplay Methodsを超える性能を達成しました。