最近、Transformerに代わる新しいモデルとして「Mamba」が注目されています。
連続的なデータを扱うのが得意で、計算量も少ないのが利点です。
ただ、画像認識の世界、特にスマホのような軽量なデバイスで動かすモデルとしては、これまでのMambaベースの手法は、王道のConvolution (CNN) やTransformerベースのモデルに一歩及ばない感じでした。
そんな中、「Mambaの得意なこと、苦手なことを見極めて、役割分担させればいいんじゃない?」という新しい視点から、効率的で高性能なモデルを開発した論文が登場しました。それが今回ご紹介する「TinyViM」です。
この記事では、TinyViMの秘密に迫っていきたいと思います。
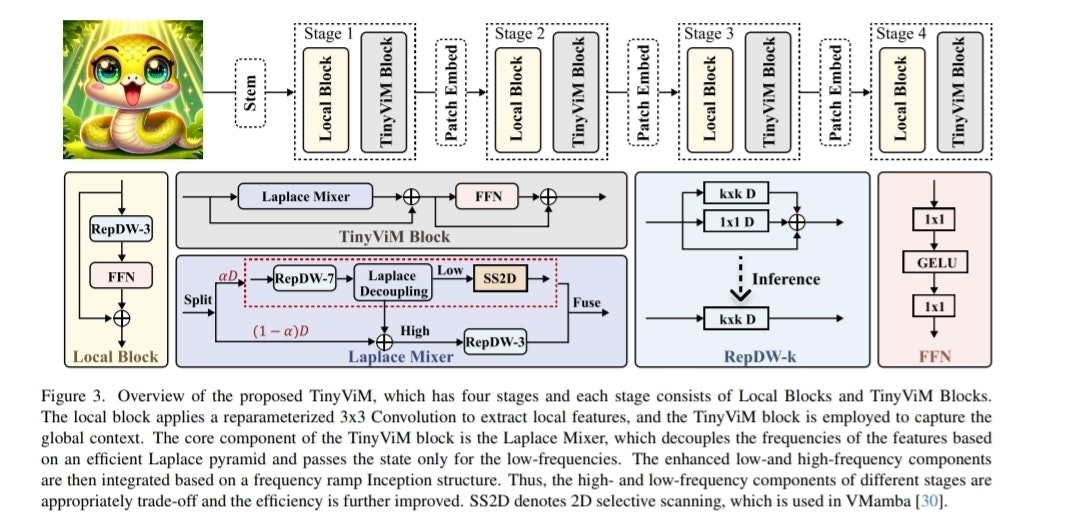
先行研究と比べてどこがすごいのか?
TinyViMのすごさをひとことで言うと、**「Mambaのポテンシャルを最大限に引き出した上で、速い」**これに尽きます。
これまでのVision Mambaの研究は、画像データをどうやって1次元のシーケンスとしてスキャンするかに焦点が当てられていました。でも、この論文の著者たちは「スキャン方法をいじるだけじゃ、Mambaの本当の力は引き出せないんじゃないか?」と考えたんです。
実際に、他の軽量Mambaモデルと比べてみると、その差は歴然です。
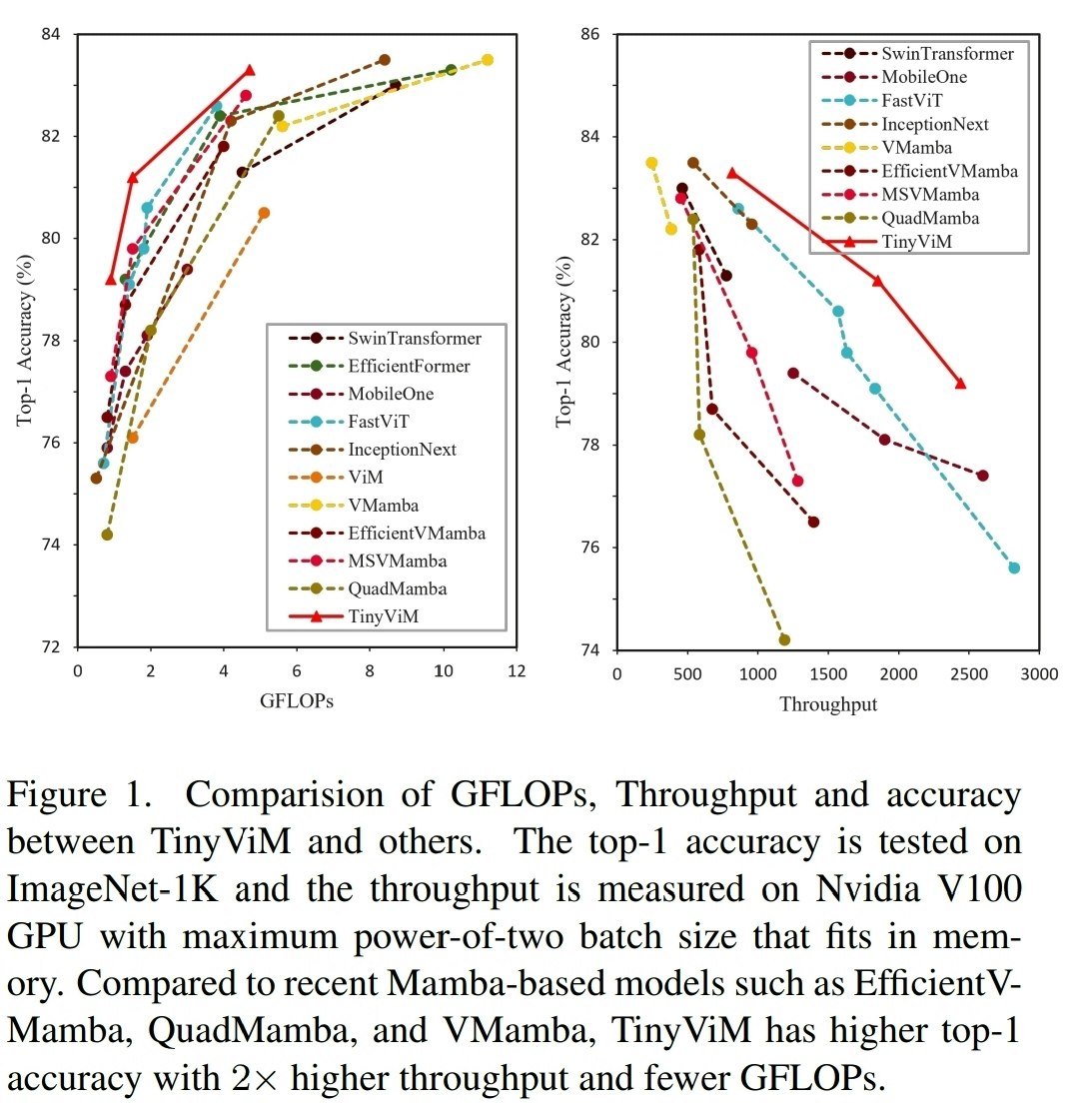
図1:他のモデルとの性能比較。右に行くほど、上に行くほど高性能。TinyViM(赤い線)が頭一つ抜けているのがわかります。
上のグラフを見ると、TinyViMは他のMamba系モデル(VMambaやEfficientVMambaなど)と比べて、同じくらいの計算量(GFLOPs)でより高い精度(Top-1 Accuracy)を達成しています。さらにすごいのがスループット(処理速度)で、他のMambaモデルの2〜3倍も速いです。
技術や手法のキモはどこか?
では、どうしてTinyViMはこんなに速くて賢いんでしょうか?それは、**「周波数分離」**です。
- Mambaは「低周波」が得意?
著者たちがまず行ったのは、CNNとMambaを組み合わせたハイブリッドな構造で、Mambaがどんな情報を処理しているのかを徹底的に分析することでした。
その結果、驚きの事実が判明します。なんと、Mambaブロックは、画像の特徴のうち「低周波」な情報(全体的なぼんやりした情報)を主に捉えていて、「高周波」な情報(エッジやテクスチャなどの細かい情報)はむしろ失われがちだったんです。
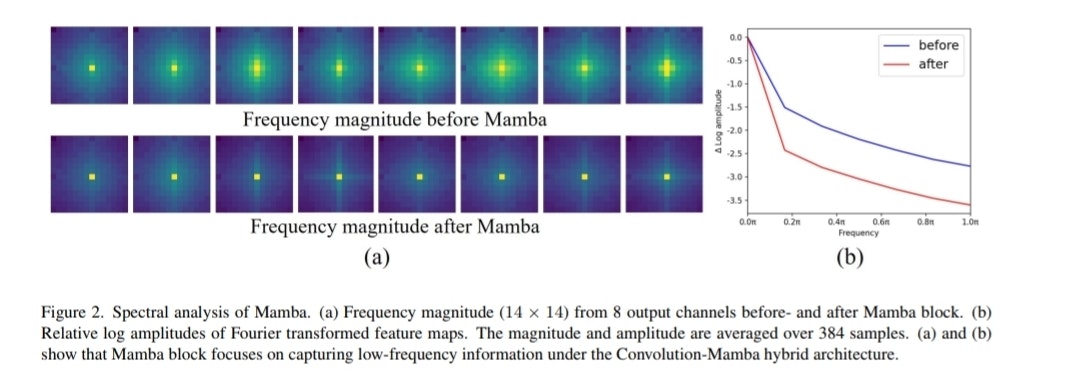
図2:Mambaブロックを通過する前(上段)と後(下段)の特徴の周波数。通過後は中心の低周波成分が強調され、周りの高周波成分が弱まっているのが見て取れます。
この発見が、TinyViMのすべての始まりでした。「それなら、Mambaには得意な低周波の処理だけ任せて、高周波は別の得意なやつに任せれば効率的じゃないか?」というわけです。
- 役割分担の司令塔「Laplace Mixer」
このアイデアを実現するのが、TinyViMの心臓部である「Laplace Mixer」です。
このMixerは、入力された特徴量を効率的に低周波成分と高周波成分に分解します。そして、
- 低周波成分:大域的な情報を捉えるのが得意な Mamba (SS2D) に渡す。しかも、低周波成分は解像度を下げられるので、計算量が減ってスループットが向上します。
- 高周波成分:細かいディテールを捉えるのが得意な Convolution (畳み込み) に渡して、情報を強化する。
という役割分担をさせます。
- 層の深さでバランス調整「Frequency Ramp Inception」
もう一つの工夫が、「Frequency Ramp Inception」です。
深層学習モデルは一般的に**浅い層では細かいディテール(高周波)**を、**深い層では全体的な構造(低周波)**を捉えようとする傾向があります。
そこでTinyViMでは、層が深くなるにつれて、
- 高周波を処理するブランチのチャネル数を減らし
- 低周波を処理するブランチのチャネル数を増やす
という動的な調整を行います。これにより、各ステージで必要な情報処理に計算を集中させ、効率化と性能向上を両立させています。
どうやって有効だと検証したのか?
論文では、このTinyViMの有効性を証明するために、画像認識に関する主要なタスクで実験を行っています。
- 画像分類 (ImageNet-1K)
- TinyViM-S(Smallモデル)は、スループットが2574画像/秒と、似た規模のMambaモデル EfficientVMamba-T(1396画像/秒)の約2倍の速度を持ちながら、精度も上回っています。
- TinyViM-L(Largeモデル)では、精度83.3%を達成し、他の軽量モデルを上回る結果を残しました。
- 物体検出 & インスタンスセグメンテーション (MS-COCO)
- TinyViM-B(Baseモデル)は、EfficientVMamba-Sと比べて、物体検出の精度(AP^{box})で3.0%、インスタンスセグメンテーションの精度(AP^{mask})で2.0%も性能が向上し、スループットも1.7倍になりました。
- セマンティックセグメンテーション (ADE20K)
- ここでも他のモデルを上回る性能を示し、TinyViMが特定のタスクだけでなく、汎用的なバックボーンとしても優れていることを示しました。
議論はあるのか?(Ablation Study)
「そのアイデア、本当に効いてるの?」という疑問に答えるための検証(Ablation Study)もしっかり行われています。
- ここでも他のモデルを上回る性能を示し、TinyViMが特定のタスクだけでなく、汎用的なバックボーンとしても優れていることを示しました。
- 周波数分離の効果は?
- Mambaに入力する情報を「低周波のみ」に絞ってみたところ、精度をほとんど落とさずに(79.1% → 79.0%)、スループットが1.5倍に向上しました。これは、Mambaが低周波の処理に集中することで効率が上がる、という仮説を裏付けています。
- Frequency Ramp Inceptionの効果は?
- 高周波と低周波のチャネル比率を全層で固定してしまうと、精度が低下することが確認されました。層の深さに応じて比率を変えていくランプ構造こそが、精度と効率の最適なバランスを作っています。
まとめ
今回は、「TinyViM」についてご紹介しました。
- Mambaは低周波情報の処理が得意であることを発見。
- Laplace Mixerで処理を分離し、Mambaには低周波を、CNNには高周波を担当させることで適材適所を実現。
- Frequency Ramp Inceptionで層ごとに処理のバランスを調整し、効率を最大化。
- 結果として、他の軽量Mambaモデルを上回る精度と速度を両立しました。
これまでの行き詰まり感を、まったく新しい視点で打ち破った研究だと思います。Mamba自体の構造に手を入れるのではなく、その「使い方」を最適化したというのが面白いです。