はじめに
SpeeDBee Hive 3.4.2(以降Hive) からPythonカスタムコレクタ機能が提供されています。この機能はHiveのコレクタ(データ収集モジュール)を python を使って自由にプログラムすることができます。
Hive にこの機能が追加されたということで、Hive とpythonの機械学習エンジンを組み合わせてリアルタイムのデータ予測が、簡単にできれば面白いかなと思い、今回、Pythonカスタムコレクタ機能と機械学習を使いデータ予測デモを作ってみたので、それを紹介します。
内容として、デモ作成の順番通りに紹介します。
Hive環境およびpython 環境がインストールされていれば、その通りにやったとすると20 分程度で同じものができるとは思います。
このデモの作成環境は、ノートPC i7-9750H 2.6G Mem 16GB windows11 wsl2 ubuntu 20 の環境で確認しました。
データ予測デモ
データ予測テーマ
デモのテーマとしてこれから(現在6月)夏になり 毎年、電力がひっ迫する季節ですので東京電力の電力需要を気象庁の発表される1時間ごとのアメダス情報から予測するデモを考えてみました。
過去の電力需要データとアメダス情報はネット上に公開され、誰でもダウンロードできます。
| 項目 | 内容 |
|---|---|
| 予測する対象 | 東京電力の電力需要 (1時間単位) |
| 予測するための情報 | 観測値 東京のアメダス情報(1時間単位) |
| 機械学習エンジン | python scikit-learnライブラリ ランダムフォレスト回帰 |
説明変数
説明変数の選択は、リアルタイム予測ということで
現在のアメダス情報をあるWEB天気予報サイトからアメダス情報のスクレイピングを行います。
その中から、以下のものを説明変数としました。
説明変数 : 月、日、時間、曜日、温度、降水量、日照時間、風向、風速
準備
学習用データ収集
学習データは、2021年01月~12月までの1年間のデータとします。
電力使用実績およびアメダス情報とも件数は同じ、365日 x 24時間 = 8760 件です。
-
東京電力 2021年の電力使用実績データ
https://www.tepco.co.jp/forecast/html/images/juyo-2021.csv -
気象庁 2021年の東京のアメダス情報
https://www.data.jma.go.jp/gmd/risk/obsdl/index.php#
こちらのサイトでは、必要な情報をダウンロードするために取得項目を選択する必要があり、以下の項目を選びダウンロードしました。また、ダウンロードに容量制限があるため、2021年のデータを期間を区切り、4回に分けてダウンロードしました。
| 選択1 | 選択2 | 内容 |
|---|---|---|
| 地点 | 東京都 | 東京 |
| 項目 | データの種類 | 時別値 |
| 項目 | 項目 | 気温、降水量(前1時間)、日照時間(前1時間)、風向・風速 |
| 期間 | 連続した期間で表示する | ※4回に分けダウンロード 2021年1月1年 ~ 2021年3月 31日 2021年4月1年 ~ 2021年6月 30日 2021年7月1年 ~ 2021年9月 30日 2021年10月1年 ~ 2021年12月 31日 |
| 表示オプション | 利用上注意が必要なデータの扱い | 値を表示(格納)しない。 |
| 表示オプション | 観測環境などの変化の前後で、値が不均質となったデータの扱い | 観測環境などの変化前の値を表示(格納)しない |
| 表示オプション | ダウンロードCSVファイルのデータ仕様 | データ表示画面と同様に、数値以外の記号を含む |
| その他 | 付に曜日を表示(日別値選択時) |
学習用データセットの作成
ダウンロードした「2021年の電力使用実績データ」CSV ファイルの電力実績データはそのまま使えますが、「2021年の東京のアメダス情報」は、そのままでは機械学習に投入できないため、以下の箇所のデータを変換します。また、併せて4ファイルに分割したので1ファイルにマージします。
- 値がない欄には、 0 をセット
- 風向値 「'北', '北北東', '北東', '東北東', ... 」を数値に変換
- 日時データを、年、月、日、時に分解
- アメダスデータの時間表記は 1~24時であるがこの値をマイナス1時間する。(この時間を観測時間とする)
アメダス情報のデータ変換およびファイルマージは、次の python プログラムを使います。
プログラムを実行する際は、あらかじめカレントディレクトに 2021 というディレクトリを作成し、そこにダウンロードしたファイルを置きます。
$ mkdir 2021
$ mv ダウンロードした2021年1月1年 ~ 2021年3月31日CSVファイル 2021/data1.csv
$ mv ダウンロードした2021年4月1年 ~ 2021年6月30日CSVファイル 2021/data2.csv
$ mv ダウンロードした2021年7月1年 ~ 2021年9月30日CSVファイル 2021/data3.csv
$ mv ダウンロードした2021年10月1年 ~ 2021年12月31日CSVファイル 2021/data4.csv
$ mv ダウンロードしたjuyo-2021.csv 2021/.
プログラムを実行し、機械学習用のデータセットを作成します。
# -*- coding: utf-8 -*-
import csv
import re
import datetime
dir16 = ['静穏','北', '北北東', '北東', '東北東', '東', '東南東', '南東',
'南南東', '南', '南南西', '南西', '西南西', '西',
'西北西', '北西', '北北西']
# 出力ファイル
out_path= '2021/2021d.csv'
out_file = open(out_path, "wt", newline = "", encoding = "utf-8")
out_writer = csv.writer(out_file)
#ヘッダー
cols = []
# 1. 月
cols.append("mon")
# 2. 日
cols.append("day")
# 3. 曜日 0-6
cols.append("week")
# 4. 時間 0-23
cols.append("hour")
# 5. 気温
cols.append("temp")
# 6. 降水量
cols.append("prec")
# 7. 日照時間
cols.append("dayl")
# 8. 風速
cols.append("ws")
# 9. 風向 16方位 1-16
cols.append("wd")
out_writer.writerow(cols)
# アメダス情報CSVファイル
wcsv_path= ['2021/data1.csv', '2021/data2.csv', '2021/data3.csv', '2021/data4.csv']
for wcsv in wcsv_path:
wcsv_file = open(wcsv, "rt", newline = "", encoding = "cp932")
wcsv_reader = csv.reader(wcsv_file)
next(wcsv_reader)
next(wcsv_reader)
next(wcsv_reader)
next(wcsv_reader)
next(wcsv_reader)
for row in wcsv_reader:
cols = []
# 単純に数値を抜き出す
dd = re.findall(r"\d+", row[0])
dt = datetime.date(int(dd[0]), int(dd[1]), int(dd[2]))
# 0. 年 同じ値なのでは使わない
# cols.append(dd[0])
# 1. 月
cols.append(dd[1])
# 2. 日
cols.append(dd[2])
# 3. 曜日
cols.append(dt.weekday())
# 4. 時間 (0~23) 発表した時間ではなく対象時間とし -1する
cols.append(int(dd[3]) - 1)
# 5. 気温 6. 降水量 7. 日照時間 8. 風速
for i in range (1, 6):
if row[i] is not None and row[i] != '' and row[i] != '--' and row[i] != '///':
# 9. 風向
if i == 5:
cols.append(dir16.index(row[i]))
else:
cols.append(row[i])
else:
cols.append(0)
out_writer.writerow(cols)
wcsv_file.close()
out_file.close()
実行し、成功すると2021 ディレクトリの下に"2021d.csv" が作成されます。
$ python3 csv2dataset.py
$ ls 2021
2021d.csv data1.csv data2.csv data3.csv data4.csv juyo-2021.csv
このようなデータです。
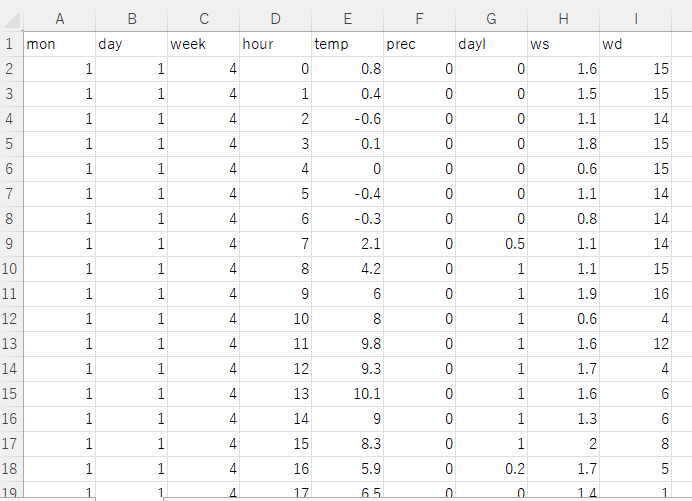
学習
次に作成したデータセットを学習させ、モデルファイルを作成します。
以下のプログラムを実行し、学習を行います。実行時間は、少々かかります。(約1分)
# -*- coding: utf-8 -*-
import csv
import numpy as np
import numpy.random as random
import scipy as sp
import pandas as pd
from pandas import Series, DataFrame
import pickle
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
# データ読み込み 電力使用実績
pcsv_path = '2021/juyo-2021.csv'
pcsv_file = open(pcsv_path, "rt", newline = "", encoding = "cp932")
pcsv_reader = csv.reader(pcsv_file)
next(pcsv_reader)
next(pcsv_reader)
next(pcsv_reader)
y=[]
for row in pcsv_reader:
y.append(row[2])
pcsv_file.close()
# データ読み込み アメダス情報
x = pd.read_csv('2021/2021d.csv')
# テストデータ作成
x_train, x_test, y_train, y_test = train_test_split(x, y, train_size=0.8)
# モデル初期化
model = RandomForestClassifier(max_depth=10, max_features=None, n_estimators=100, random_state=1)
# 学習
model.fit(x_train, y_train)
model.fit(x, y)
# 評価
print("train score:",model.score(x_train,y_train))
print("test score:",model.score(x_test,y_test))
# モデル保存
with open('2021/pw_model2.mod', mode='wb') as f:
pickle.dump(model, f)
成功すると2021 ディレクトリにランダムフォレスト回帰のモデルファイル'pw_model2.mod'ファイルができます。
$ python3 pw2.py
train score: 0.3698630136986301
test score: 0.3829908675799087
$ ls -l 2021/pw_model2.mod
-rwxrwxrwx 1 x x 613015238 Jun 9 10:00 2021/pw_model2.mod
ファイルサイズは、このパラメータの場合(max_depth=10, max_features=None, n_estimators=100, random_state=1)結構大きく約600MBになります。
また、スコアとして、train score: 0.3698630136986301、test score: 0.3829908675799087 このような数値が表示されましたが、今回はSpeeDBee Hiveからの機械学習を使ったデータ予測が目的なので予測モデルや精度を気にせず、このまま進めます。
SpeeDBee Hive 機械学習を使ったデータ予測システム
リアルタイム電力需要予測システム構成
システムイメージとしてこのようなシステムを想定しています。
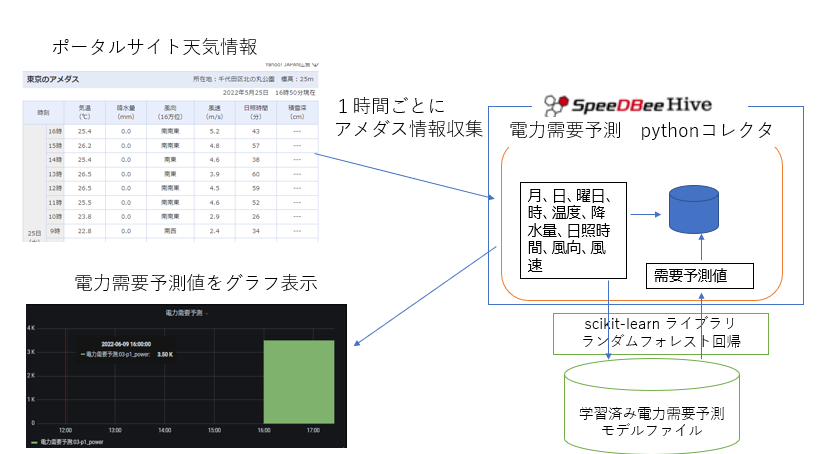
| 構成 | 説明 |
|---|---|
| python コレクタ | 1時間ごとにWEB上のポータルサイトの天気予報から観測地・東京のアメダス情報をスクレイピングし、その情報から予測モデルを機械学習による電力需要予測の予測を行います。併せて、温度、降水量、日照時間、需要予測値を時系列DBに登録します。 |
| scikit-learnランダムフォレスト回帰 | pythonコレクタから取得した現在のアメダス情報を入力し、学習済みモデルファイルにより電力需要予測値を返します。 |
| Hive | コレクタの管理やデータの上位連携、イベント管理、データ集約、データ管理など多彩な処理が可能です。この図のようにグラフツールとの連携も可能です。 |
Hive python コレクタ準備
Python モジュール追加
WEB上の天気予報サイトの情報をスクレイピングし、scikit-learn ランダムフォレスト回帰の予測をするためには、Hive 標準のPythonモジュールでは不足しているため、以下のモジュールを追加します。
| 追加モジュール名 | 説明 |
|---|---|
| scikit-learn | 機械学習ライブラリ |
| lxml | xml や html を扱うためのライブラリ |
| beautifulsoup4 | html から情報を抽出するためのライブラリ |
モジュール追加は、HiveのWEB UI画面から行います。「システム」⇒「コレクタ関連設定」⇒「カスタム(Python)」を選択します。
追加方法はPythonモジュールとある入力フィールドにモジュール名を指定し、追加ボタンを押します。
追加する際の注意ですが、beautifulsoup4 をインストールする前に lxml を先にインストールしてください。(lxmlをインストールしないでbeautifulsoup4をインストールした場合、インストールエラーになります。)
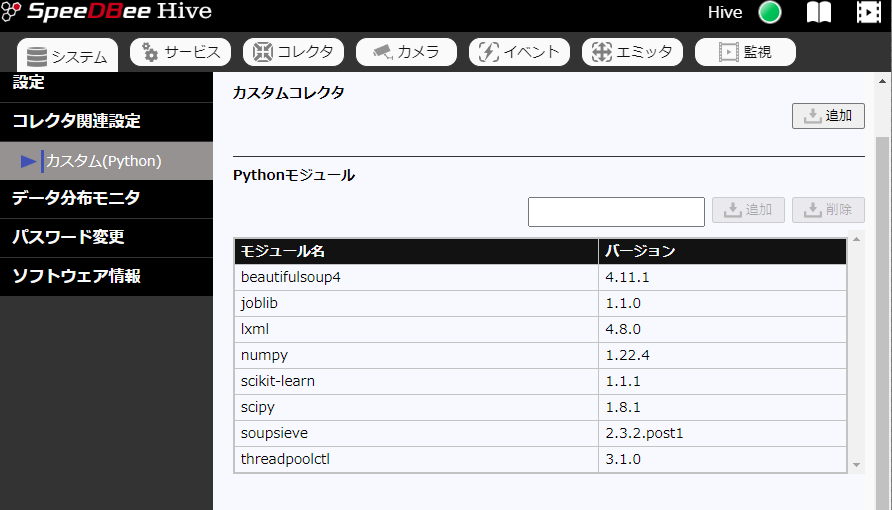
上の画像は、既に上記のモジュールをインストールした後の画像で、表示されているモジュールリストに含まれています。
このリストの中の joblib, numpy, scipy, soupsieve, threadpoolctl は、上記モジュールの依存モジュールで自動にインストールされます。
モデルファイルをHive から読み込みができるパスに移動
Hive から、scikit-learn のデータ予測をコールするため、モデルファイルは Hiveから参照できるディレクトリに移動させます。(参照ができればどこでもよいのですが、/var/speedbee/tmp/の下に置くことにします)
sudo mv 2021/pw_model2.mod /var/speedbee/tmp/.
Hive python コレクタ
python コレクタでは、以下の処理を行います。
-
WEB上の天気予報サイトから観測地・東京のアメダス情報を1時間ごとの最新データを取得します。
- 大手ポータルサイトの観測地・東京のアメダス情報https://weather.yahoo.co.jp/weather/amedas/13/44132.html?m=temp
- 1時間ごとの更新は、いつ行われるかわからないため、30分毎に読み込みます。既に取得済みであれば何もしません。
- html からのデータ取得は butifulsoup4 を使い情報を切り出します。
-
取得したアメダス情報を機械学習のデータ予測に投入し、予測値を取得します。
- 取得したデータは学習時と同様に値の欠損の対応や風向を数値データに変換するなどして、データ予測を実行します。
-
予測した値を観測値とともに時系列DBに登録します。
上記を行うカスタムコレクタは以下になります。
# -*- coding: utf-8 -*-
import urllib.request
import urllib.parse
import sys
import os
import datetime
import time
from bs4 import BeautifulSoup
import re
import pickle
from hive_collector import HiveCollectorBase, HiveColumn
dir16 = ['静穏','北', '北北東', '北東', '東北東', '東', '東南東', '南東',
'南南東', '南', '南南西', '南西', '西南西', '西',
'西北西', '北西', '北北西']
def get_htm(url,out):
time.sleep(1)
try:
res_url = urllib.request.urlopen(url)
except urllib.error.HTTPError as e:
print("error HTTPError [" + str(e.code) + "] " + e.reason + " : " + url )
return False
except urllib.error.URLError as e:
print("error URLError [" + str(e.code) + "] " + e.reason + " : " + url)
return False
else:
# デバッグのため1度ファイルに書く
res_html = res_url.read()
f = open(out, "wb")
f.write(res_html)
f.close()
return True
# HTML読込
def read_htm(htm):
f = open(htm, "rb")
tenki_soup = BeautifulSoup(f.read(), "lxml")
f.close
# 年月日の取得
hizuke = tenki_soup.find_all("p", class_="yjw_note yjSt")[0]
yymmdd = hizuke.text.split(' ')[0]
d = datetime.datetime.strptime(yymmdd, "%Y年%m月%d日")
# 最新アメダスデータの取得
dats = []
dats.append(d)
table = tenki_soup.find_all("table", class_="yjw_table")[0]
rows = table.findAll("tr")
line = 0;
for row in rows:
line += 1
if line == 1:
continue
for cell in row.findAll("td"):
dats.append(cell.find_all("small")[0].text)
break
return dats
def get_data(url, lasta):
tmpfile = '/var/speedbeehive/tmp/tenki.htm'
if get_htm(url, tmpfile) == True:
dats = read_htm(tmpfile)
dd = int(re.sub(r"\D", "", dats[1]))
hh = int(re.sub(r"\D", "", dats[2]))
# 既に登録ずみ
if lasta[0] > 0 and lasta[1] > -1 and lasta[0] == dd and lasta[1] == hh:
return False, None
lasta[0] = dd
lasta[1] = hh
os.remove(tmpfile)
return True, dats
return False, None
class HiveCollector(HiveCollectorBase):
def __init__(self, param):
self.logger.info("init")
self.clm0 = self.makeOutputColumn("p1_temp", HiveColumn.TypeFloat)
self.clm1 = self.makeOutputColumn("p1_prec", HiveColumn.TypeFloat)
self.clm2 = self.makeOutputColumn("p1_dayl", HiveColumn.TypeFloat)
self.clm3 = self.makeOutputColumn("p1_power", HiveColumn.TypeUint32)
self.last = [0, -1]
self.url = 'https://weather.yahoo.co.jp/weather/amedas/13/44132.html?m=temp'
with open('/var/speedbeehive/tmp/pw_model2.mod', mode='rb') as f:
self.model = pickle.load(f)
def mainloop(self):
self.logger.debug("main loop execute")
self.intervalCall(int(1800*1000*1000), self.proc)
def proc(self, ts, skip):
# self.logger.trace("proc execute")
ret, dats = get_data(self.url, self.last)
if ret == True:
day = dats[0]
# 観測対象時間 - 1とする
h = self.last[1] - 1
d = datetime.datetime(day.year, day.month, day.day, h, 0, 0)
d2 = int(time.mktime(d.timetuple())) * 1000000000
pred = []
# 予測データの作成
# 1. 月
pred.append(day.month)
# 2. 日
pred.append(d.day)
# 3. 曜日
pred.append(d.weekday())
# 4. 時間
pred.append(h)
# 5.気温
if dats[3] is not None and dats[3] != '' and dats[3] != "---":
self.clm0.insert(dats[3], Timestamp=d2)
pred.append(float(dats[3]))
else:
self.clm0.insert(0, Timestamp=d2)
pred.append(0)
# 6.降水量
if dats[4] is not None and dats[4] != '' and dats[4] != "---":
self.clm1.insert(dats[4], Timestamp=d2)
pred.append(float(dats[4]))
else:
self.clm1.insert(0, Timestamp=d2)
pred.append(0)
# 7. 日照時間
if dats[7] is not None and dats[7] != '' and dats[4] != "---":
self.clm2.insert(dats[7], Timestamp=d2)
pred.append(float(dats[7]))
else:
self.clm2.insert(0, Timestamp=d2)
pred.append(0)
# 8.風向
if dats[5] is not None and dats[5] != '' and dats[5] != "---":
pred.append(dir16.index(dats[5]))
else:
pred.append(0)
# 9.風速
if dats[6] is not None and dats[6] != '' and dats[6] != "---":
pred.append(float(dats[6]))
else:
pred.append(0)
# 10 電力需要予測
start_time = time.perf_counter()
power = self.model.predict([pred])
end_time = time.perf_counter()
elapsed_time = end_time - start_time
self.logger.info("predict:" + str(power[0]) + " elapsed:" + str(elapsed_time))
self.clm3.insert(power[0], Timestamp=d2)
else:
# false
self.logger.info("power : already registered")
このプログラム内で留意する点は以下になります。
-
python コレクタのinit 時にモデルファイルを読み込む必要があります。
(ランダムフォレストのモデルファイルが大きいため) -
アメダス観測値の時間範囲は 1~24時です。
この予測システム内では、アメダスの時間はマイナス1時間します。 -
スクレイピングのためのサイトアクセスは30分毎にしています。
self.intervalCall(int(180010001000), self.proc)
(短い間隔でアクセスは、接続先のサーバー負荷になりますのでご注意願います)
Hive python カスタムコレクタ登録
上記のプログラムをHive のWEB UI画面からカスタムコレクタ登録します。
メニュー「システム」⇒「カスタム(Python)」
カスタムコレクタ 追加ボタン プログラムファイルを選択します。
成功すると以下の画面が表示されます。
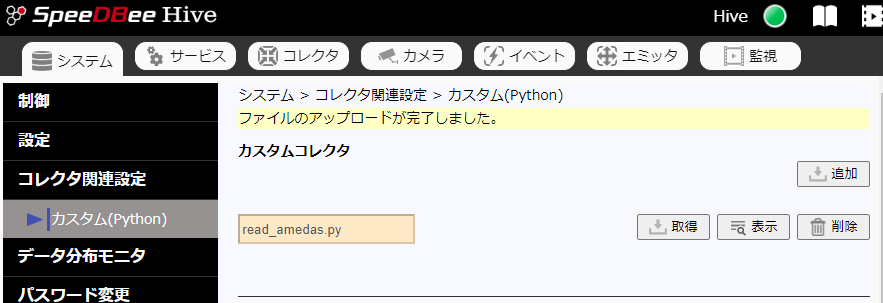
Hive python カスタムコレクタ設定
登録したカスタムコレクタを実際に動作させるためには、コレクタ設定が必要になります。
メニュー「コレクタ」⇒「カスタム +プラス新規作成ボタン」を選択し、
カスタム名を「電力需要予測」と入力し、タイプを「python」を選択します。
ライブラリには前に登録した「read_amedas.py」を選択し、「保存」ボタンを押すと以下の画面が表示され、ここまで成功です。
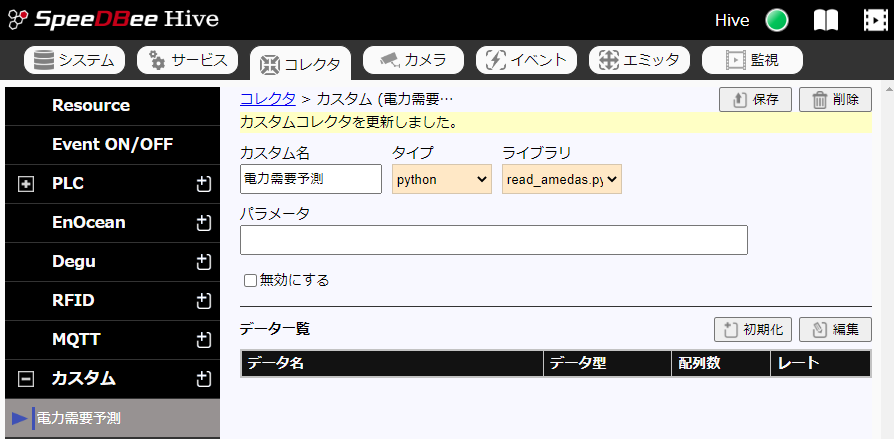
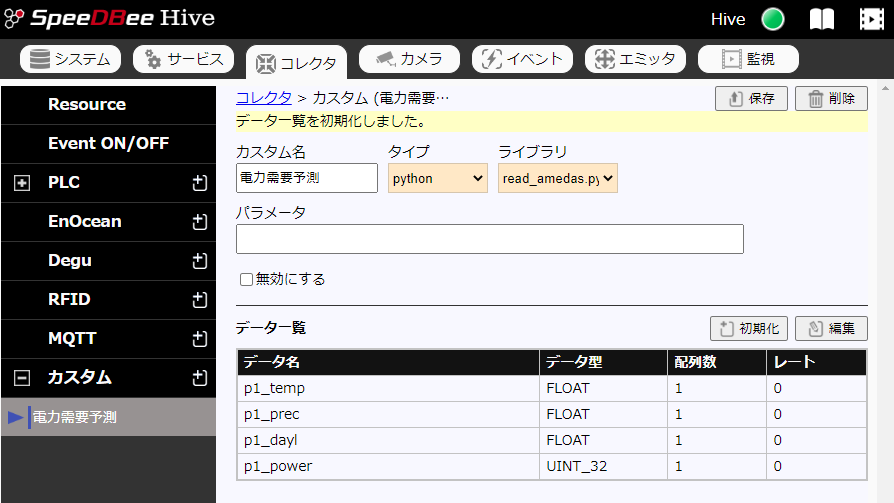
次に、この画面のデータ一覧の右にある「初期化」ボタンを押すと以下の画面が表示され、登録するデータ項目の一覧が表示されます。(初期化は、初回時、1分程度かかる可能性があります。)
「初期化」ボタンを押し、「システムエラーが発生しました(code:96)」 になった場合、モデルファイル"pw_model2.mod"が "/var/speedbeehive/tmp/."の下にあるか確認してください。
登録するデータは以下になります。
| データ名 | 説明 |
|---|---|
| p1_temp | 温度 |
| p1_prec | 降水量 |
| p1_dayl | 日照時間 |
| p1_power | 電力需要予測値 |
コレクタの起動
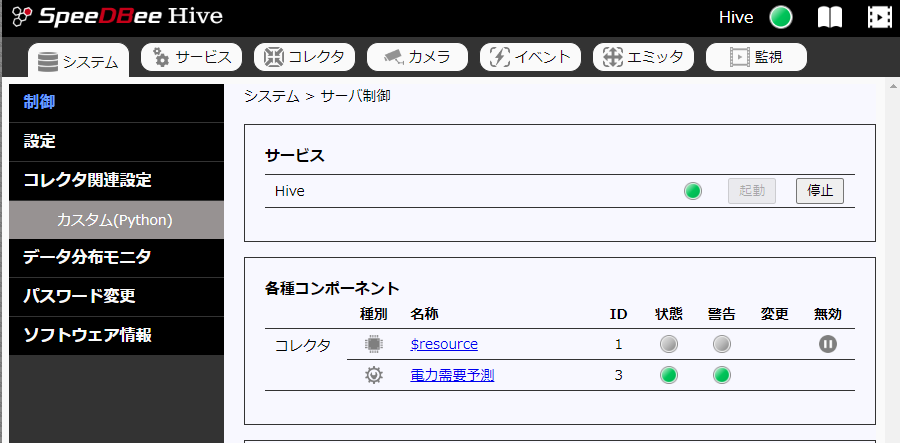
あとは、設定した「電力需要予測」コレクタを起動させるだけです。
メニュー「システム」⇒「制御」を選択し、サービスの「起動」ボタンを押します。
成功するとコレクタ「電力需要予測」の状態が緑に表示されます。(失敗すると状態が赤に表示されます。)
グラフ表示
リアルタイムと言っても1時間に1回の更新であるため、待っている間、予測したデータをオープンソースのグラフツール Grafana を使ってグラフ表示を行いたいと思います。Grafana連携は、Hive の機能に含まれており、Grafanaの画面から選択するだけで簡単にグラフ表示できます。
Grafana連携のため設定方法については、Hiveのマニュアルを参照してください。
おわりに
Hive 内でscikit-learnの予測にどれくらい時間がかかるのか測ってみました。(経過時間はHiveのログに出力させています。)
2022-06-09T16:04:31.414 [INFO] COLLECTOR[電力需要予測]: predict:3496 elapsed:0.01192566700046882
予測時間は 0.01192.. 秒でした。
今回、Hiveからpython の機械学習を使ったデータ予測のデモを作成した感想ですが、計測した予測時間から周期の短いデータにおいてもリアルタイムデータ予測が実用域にあると感じました。
また、Hiveを使うことでデータ収集、上位連携や集計、データ処理、イベント処理、データ出力、データ表示など面倒なところは、Hiveに任せることができ、今回作成したように機械学習に集中ができるため、python の機械学習ライブラリと組み合わせた利用方法に関してもっと探ってみたいと思います。
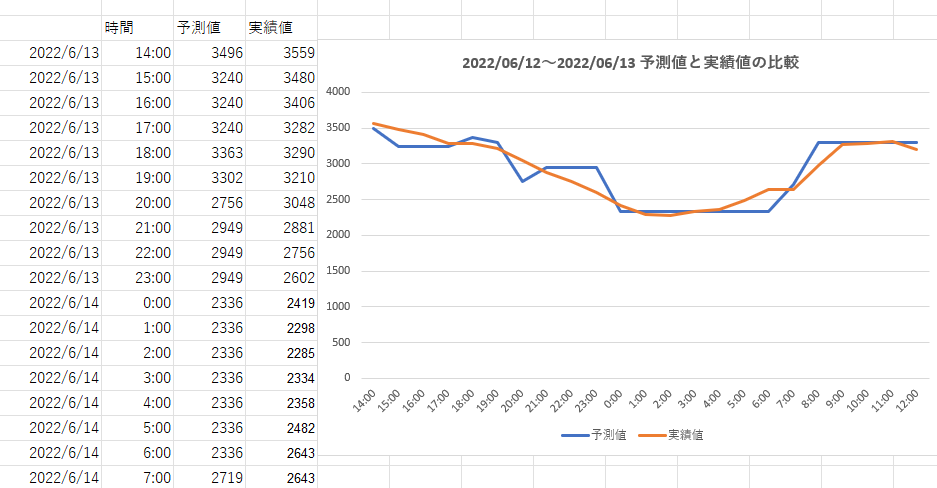
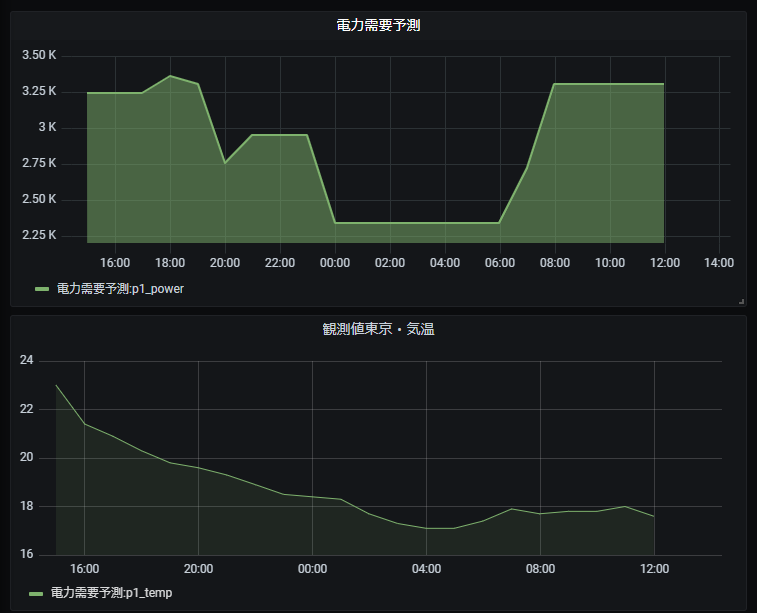
最後に、忘れていましたが電力需要の予測結果ですが、1日予測を動かし、実際の実績と比較した結果を示します。モデルのチューニングもしていませんが、実績値とそれほどずれてはおらず、それらしい数値が得られているようです。