自動並列化とは
まずは、自動並列化についてざっくりと説明します。自動並列化とはプログラム中のループを解析し、その解析結果をもとに並列で実行可能なコードを生成することになります。この自動並列化は様々なやり方があり、コンパイラが並列化コード生成を行うものや別ツールによりOpenMP等のディレクティブを挿入することで実現するものがあったりします。
LLVMの自動並列化について
LLVMの自動並列化機能実装の一つとして、pollyというものがあります。pollyは、LLVMの開発をおこなっているLLVM Projectのサブプロジェクトの一つとなっているものになります。このpollyは、現在LLVMと一体化されており、コンパイルオプションにより自動並列化機能を適用することができます。
pollyによる最適化について
pollyは、プログラム中のループに対して解析を行い自動並列化を含めた最適化を行う機能を持ちます。自動並列化ではOpenMPライブラリの関数を利用する形の並列化コードを生成します。また、自動並列化以外の最適化としてループ交換、ループ融合、タイリング等があります。pollyでは、これらのループ最適化と自動並列化は区別されています。以下ではLLVMのC/C++フロントエンドであるclangからのそれぞれのpolly適用方法について紹介します。
pollyによるループ最適化適用方法
pollyを有効にするためには-mllvm -pollyをしてした上で最適化レベルがO1/O2/O3である必要があります。O3での適用方法は以下のようになります。
clang -O3 -mllvm -polly test.c
pollyによるループ最適化+OpenMP並列化方法
polly適用時と同様に最適化レベルがO1/O2/O3である必要があります。その上でOpenMP並列化を行うためには-mllvm -polly-parallelを指定する必要があります。
clang -O3 -mllvm -polly -mllvm -polly-parallel test.c
pollyの効果
pollyによる最適化効果をpolybenchというベンチマークを使って確認する。polybenchは、様々なアルゴリズムのループ処理が含まれていてループ最適化の効果を計測しやすい。
今回は、-O3での計測時間を基準として最適化効果を確認していきます。
計測方法
- コンパイラ: clang/llvm 15.0.6
- オプション
- 基準:
-O3 -DPOLYBENCH_USE_C99_PROTO -DPOLYBENCH_TIME - pollyループ最適化:
-O3 -mllvm -polly -DPOLYBENCH_USE_C99_PROTO -DPOLYBENCH_TIME - pollyループ最適化+OpenMP並列化:
-O3 -mllvm -polly -mllvm -polly-parallel -DPOLYBENCH_USE_C99_PROTO -DPOLYBENCH_TIME
- 基準:
- OMP_NUM_THREAD: 8
実行時間を3回計測し平均値を算出しました。
-DPOLYBENCH_TIMEをつけることで処理の中心となっている関数のみの実行時間が計測できるようになっています。
計測結果
基準としたオプションでの実行速度を1として各オプションでの実行速度を算出しました。
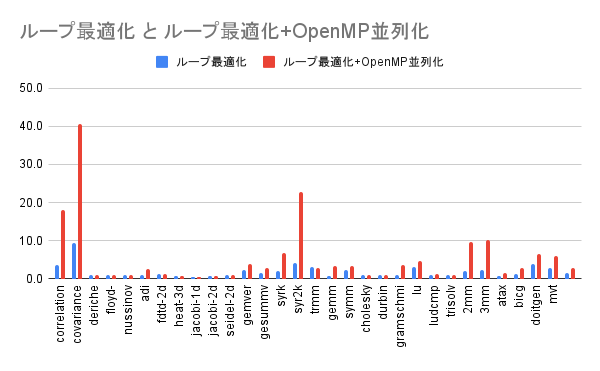
| プログラム名 | pollyループ最適化 | pollyループ最適化 +OpenMP並列化 |
|---|---|---|
| correlation | 3.622 | 18.075 |
| covariance | 9.241 | 40.661 |
| deriche | 0.937 | 1.007 |
| floyd-warshall | 0.996 | 0.997 |
| nussinov | 0.987 | 0.985 |
| adi | 1.085 | 2.640 |
| fdtd-2d | 1.272 | 1.268 |
| heat-3d | 0.638 | 0.636 |
| jacobi-1d | 0.483 | 0.486 |
| jacobi-2d | 0.622 | 0.619 |
| seidel-2d | 1.001 | 0.999 |
| gemver | 2.144 | 3.791 |
| gesummv | 1.566 | 2.804 |
| syrk | 2.098 | 6.825 |
| syr2k | 4.110 | 22.667 |
| trmm | 3.031 | 2.926 |
| gemm | 0.673 | 3.434 |
| symm | 2.351 | 3.287 |
| cholesky | 1.001 | 1.006 |
| durbin | 1.002 | 0.998 |
| gramschmidt | 1.012 | 3.530 |
| lu | 3.032 | 4.521 |
| ludcmp | 0.965 | 1.153 |
| trisolv | 1.013 | 1.022 |
| 2mm | 2.070 | 9.709 |
| 3mm | 2.312 | 10.231 |
| atax | 0.698 | 1.555 |
| bicg | 1.259 | 2.691 |
| doitgen | 3.745 | 6.516 |
| mvt | 2.730 | 6.001 |
| 幾何平均 | 1.487 | 2.689 |
実行速度が大きく伸びるプログラムがある一方で、効果があまりないもの、速度が低下するものが存在します。今回は、速度が低下するプログラムについて要因を探っていきます。
pollyによるループ最適化で遅くなった要因
今回の計測結果をみると、pollyによるループ最適化により実行速度が低下しているプログラムがあります。heat-3d,jacobi-1d,jacobi-2d,gemm,ataxというプログラムの速度低下が目立ちます。以下ではheat-3dについて調査していきます。
heat-3dの処理の中心
以下はheat-3dの処理の中心となっている関数になります。
/* Main computational kernel. The whole function will be timed,
including the call and return. */
static
void kernel_heat_3d(int tsteps,
int n,
DATA_TYPE POLYBENCH_3D(A,N,N,N,n,n,n),
DATA_TYPE POLYBENCH_3D(B,N,N,N,n,n,n))
{
int t, i, j, k;
#pragma scop
for (t = 1; t <= TSTEPS; t++) {
for (i = 1; i < _PB_N-1; i++) {
for (j = 1; j < _PB_N-1; j++) {
for (k = 1; k < _PB_N-1; k++) {
B[i][j][k] = SCALAR_VAL(0.125) * (A[i+1][j][k] - SCALAR_VAL(2.0) * A[i][j][k] + A[i-1][j][k])
+ SCALAR_VAL(0.125) * (A[i][j+1][k] - SCALAR_VAL(2.0) * A[i][j][k] + A[i][j-1][k])
+ SCALAR_VAL(0.125) * (A[i][j][k+1] - SCALAR_VAL(2.0) * A[i][j][k] + A[i][j][k-1])
+ A[i][j][k];
}
}
}
for (i = 1; i < _PB_N-1; i++) {
for (j = 1; j < _PB_N-1; j++) {
for (k = 1; k < _PB_N-1; k++) {
A[i][j][k] = SCALAR_VAL(0.125) * (B[i+1][j][k] - SCALAR_VAL(2.0) * B[i][j][k] + B[i-1][j][k])
+ SCALAR_VAL(0.125) * (B[i][j+1][k] - SCALAR_VAL(2.0) * B[i][j][k] + B[i][j-1][k])
+ SCALAR_VAL(0.125) * (B[i][j][k+1] - SCALAR_VAL(2.0) * B[i][j][k] + B[i][j][k-1])
+ B[i][j][k];
}
}
}
}
#pragma endscop
}
このプログラムを-O3をつけてコンパイルした際の中間言語(IR)が以下になります。
129: ; preds = %104, %129
%130 = phi i64 [ %166, %129 ], [ 0, %104 ]
%131 = or i64 %130, 1
%132 = getelementptr inbounds double, double* %109, i64 %131
%133 = bitcast double* %132 to <2 x double>*
%134 = load <2 x double>, <2 x double>* %133, align 8, !tbaa !5, !alias.scope !20
%135 = getelementptr inbounds double, double* %110, i64 %131
%136 = bitcast double* %135 to <2 x double>*
%137 = load <2 x double>, <2 x double>* %136, align 8, !tbaa !5, !alias.scope !20
%138 = call <2 x double> @llvm.fmuladd.v2f64(<2 x double> %137, <2 x double> <double -2.000000e+00, double -2.000000e+00>, <2 x double> %134)
%139 = getelementptr inbounds double, double* %111, i64 %131
%140 = bitcast double* %139 to <2 x double>*
%141 = load <2 x double>, <2 x double>* %140, align 8, !tbaa !5, !alias.scope !20
%142 = fadd <2 x double> %138, %141
%143 = getelementptr inbounds double, double* %114, i64 %131
%144 = bitcast double* %143 to <2 x double>*
%145 = load <2 x double>, <2 x double>* %144, align 8, !tbaa !5, !alias.scope !20
%146 = call <2 x double> @llvm.fmuladd.v2f64(<2 x double> %137, <2 x double> <double -2.000000e+00, double -2.000000e+00>, <2 x double> %145)
%147 = getelementptr inbounds double, double* %116, i64 %131
%148 = bitcast double* %147 to <2 x double>*
%149 = load <2 x double>, <2 x double>* %148, align 8, !tbaa !5, !alias.scope !20
%150 = fadd <2 x double> %146, %149
%151 = fmul <2 x double> %150, <double 1.250000e-01, double 1.250000e-01>
%152 = call <2 x double> @llvm.fmuladd.v2f64(<2 x double> %142, <2 x double> <double 1.250000e-01, double 1.250000e-01>, <2 x double> %151)
%153 = add i64 %130, 2
%154 = getelementptr inbounds double, double* %110, i64 %153
%155 = bitcast double* %154 to <2 x double>*
%156 = load <2 x double>, <2 x double>* %155, align 8, !tbaa !5, !alias.scope !20
%157 = call <2 x double> @llvm.fmuladd.v2f64(<2 x double> %137, <2 x double> <double -2.000000e+00, double -2.000000e+00>, <2 x double> %156)
%158 = getelementptr inbounds double, double* %110, i64 %130
%159 = bitcast double* %158 to <2 x double>*
%160 = load <2 x double>, <2 x double>* %159, align 8, !tbaa !5, !alias.scope !20
%161 = fadd <2 x double> %157, %160
%162 = call <2 x double> @llvm.fmuladd.v2f64(<2 x double> %161, <2 x double> <double 1.250000e-01, double 1.250000e-01>, <2 x double> %152)
%163 = fadd <2 x double> %137, %162
%164 = getelementptr inbounds double, double* %117, i64 %131
%165 = bitcast double* %164 to <2 x double>*
store <2 x double> %163, <2 x double>* %165, align 8, !tbaa !5, !alias.scope !23, !noalias !20
%166 = add nuw i64 %130, 2
%167 = icmp eq i64 %166, 118
br i1 %167, label %198, label %129, !llvm.loop !25
関数全体のIRですと、長すぎるので一番目の多重ループで行われている処理部分だけのIRになります。ところどころに<2 x double>という部分があると思います。これはdouble型の要素を同時に2つ文処理する命令が存在することになります。これは後にSIMD命令に変換される中間表現となっています。
一方で-O3 -mllvm -pollyでコンパイルしたときのIRが以下になります。
136: ; preds = %111, %136
%137 = phi i64 [ %173, %136 ], [ 0, %111 ]
%138 = or i64 %137, 1
%139 = getelementptr inbounds double, double* %116, i64 %138
%140 = bitcast double* %139 to <2 x double>*
%141 = load <2 x double>, <2 x double>* %140, align 8, !tbaa !5, !alias.scope !20
%142 = getelementptr inbounds double, double* %117, i64 %138
%143 = bitcast double* %142 to <2 x double>*
%144 = load <2 x double>, <2 x double>* %143, align 8, !tbaa !5, !alias.scope !20
%145 = call <2 x double> @llvm.fmuladd.v2f64(<2 x double> %144, <2 x double> <double -2.000000e+00, double -2.000000e+00>, <2 x double> %141)
%146 = getelementptr inbounds double, double* %118, i64 %138
%147 = bitcast double* %146 to <2 x double>*
%148 = load <2 x double>, <2 x double>* %147, align 8, !tbaa !5, !alias.scope !20
%149 = fadd <2 x double> %145, %148
%150 = getelementptr inbounds double, double* %121, i64 %138
%151 = bitcast double* %150 to <2 x double>*
%152 = load <2 x double>, <2 x double>* %151, align 8, !tbaa !5, !alias.scope !20
%153 = call <2 x double> @llvm.fmuladd.v2f64(<2 x double> %144, <2 x double> <double -2.000000e+00, double -2.000000e+00>, <2 x double> %152)
%154 = getelementptr inbounds double, double* %123, i64 %138
%155 = bitcast double* %154 to <2 x double>*
%156 = load <2 x double>, <2 x double>* %155, align 8, !tbaa !5, !alias.scope !20
%157 = fadd <2 x double> %153, %156
%158 = fmul <2 x double> %157, <double 1.250000e-01, double 1.250000e-01>
%159 = call <2 x double> @llvm.fmuladd.v2f64(<2 x double> %149, <2 x double> <double 1.250000e-01, double 1.250000e-01>, <2 x double> %158)
%160 = add i64 %137, 2
%161 = getelementptr inbounds double, double* %117, i64 %160
%162 = bitcast double* %161 to <2 x double>*
%163 = load <2 x double>, <2 x double>* %162, align 8, !tbaa !5, !alias.scope !20
%164 = call <2 x double> @llvm.fmuladd.v2f64(<2 x double> %144, <2 x double> <double -2.000000e+00, double -2.000000e+00>, <2 x double> %163)
%165 = getelementptr inbounds double, double* %117, i64 %137
%166 = bitcast double* %165 to <2 x double>*
%167 = load <2 x double>, <2 x double>* %166, align 8, !tbaa !5, !alias.scope !20
%168 = fadd <2 x double> %164, %167
%169 = call <2 x double> @llvm.fmuladd.v2f64(<2 x double> %168, <2 x double> <double 1.250000e-01, double 1.250000e-01>, <2 x double> %159)
%170 = fadd <2 x double> %144, %169
%171 = getelementptr inbounds double, double* %124, i64 %138
%172 = bitcast double* %171 to <2 x double>*
store <2 x double> %170, <2 x double>* %172, align 8, !tbaa !5, !alias.scope !23, !noalias !20
%173 = add nuw i64 %137, 2
%174 = icmp eq i64 %173, 118
br i1 %174, label %205, label %136, !llvm.loop !25
ということで、ここの部分のIRに違いはありませんでした。また、2番めの多重ループの処理の中身についてもIRの違いはありませんでした。IRの差分として生じていたのは処理の中身でなく外側部分にありました。つまりループの構造自体に変化が生じていました。
ループ構造の変化
どのようにループ構造が変化していたのかを知るために-mllvm -debug-only=polly-opt-islというオプションをつけてコンパイルしてみます。(※ このオプション使用するためにはデバッグ用にビルドしたLLVMが必要になります。)
まず、オリジナルのループ構造は以下のようになります。関数のソースと見比べてみるとなんとなく関連が分かると思いますが、大本のループの中に2つの多重ループがある構造となっています。
Original schedule tree:
domain: "{ Stmt8[i0, i1, i2, i3] : 0 <= i0 <= 499 and 0 <= i1 <= 117 and 0 <= i2 <= 117 and 0 <= i3 <= 117; Stmt3[i0, i1, i2, i3] : 0 <= i0 <= 499 and 0 <= i1 <= 117 and 0 <= i2 <= 117 and 0 <= i3 <= 117 }"
child:
mark: "Loop with Metadata"
child:
schedule: "[{ Stmt8[i0, i1, i2, i3] -> [(i0)]; Stmt3[i0, i1, i2, i3] -> [(i0)] }]"
child:
sequence:
- filter: "{ Stmt3[i0, i1, i2, i3] }"
child:
mark: "Loop with Metadata"
child:
schedule: "[{ Stmt3[i0, i1, i2, i3] -> [(i1)] }]"
child:
mark: "Loop with Metadata"
child:
schedule: "[{ Stmt3[i0, i1, i2, i3] -> [(i2)] }]"
child:
mark: "Loop with Metadata"
child:
schedule: "[{ Stmt3[i0, i1, i2, i3] -> [(i3)] }]"
- filter: "{ Stmt8[i0, i1, i2, i3] }"
child:
mark: "Loop with Metadata"
child:
schedule: "[{ Stmt8[i0, i1, i2, i3] -> [(i1)] }]"
child:
mark: "Loop with Metadata"
child:
schedule: "[{ Stmt8[i0, i1, i2, i3] -> [(i2)] }]"
child:
mark: "Loop with Metadata"
child:
schedule: "[{ Stmt8[i0, i1, i2, i3] -> [(i3)] }]"
これがpollyのループ最適化により以下のようになります。
After post-optimizations:
domain: "{ Stmt3[i0, i1, i2, i3] : 0 <= i0 <= 499 and 0 <= i1 <= 117 and 0 <= i2 <= 117 and 0 <= i3 <= 117; Stmt8[i0, i1, i2, i3] : 0 <= i0 <= 499 and 0 <= i1 <= 117 and 0 <= i2 <= 117 and 0 <= i3 <= 117 }"
child:
mark: "1st level tiling - Tiles"
child:
schedule: "[{ Stmt8[i0, i1, i2, i3] -> [(floor((i0)/32))]; Stmt3[i0, i1, i2, i3] -> [(floor((i0)/32))] }, { Stmt8[i0, i1, i2, i3] -> [(floor((1 + 2i0 + i1)/32))]; Stmt3[i0, i1, i2, i3] -> [(floor((2i0 + i1)/32))] }, { Stmt8[i0, i1, i2, i3] -> [(floor((1 + 2i0 + i2)/32))]; Stmt3[i0, i1, i2, i3] -> [(floor((2i0 + i2)/32))] }, { Stmt8[i0, i1, i2, i3] -> [(floor((1 + 2i0 + i3)/32))]; Stmt3[i0, i1, i2, i3] -> [(floor((2i0 + i3)/32))] }]"
permutable: 1
child:
mark: "1st level tiling - Points"
child:
schedule: "[{ Stmt8[i0, i1, i2, i3] -> [((i0) mod 32)]; Stmt3[i0, i1, i2, i3] -> [((i0) mod 32)] }, { Stmt8[i0, i1, i2, i3] -> [((1 + 2i0 + i1) mod 32)]; Stmt3[i0, i1, i2, i3] -> [((2i0 + i1) mod 32)] }, { Stmt8[i0, i1, i2, i3] -> [((1 + 2i0 + i2) mod 32)]; Stmt3[i0, i1, i2, i3] -> [((2i0 + i2) mod 32)] }, { Stmt8[i0, i1, i2, i3] -> [((1 + 2i0 + i3) mod 32)]; Stmt3[i0, i1, i2, i3] -> [((2i0 + i3) mod 32)] }]"
permutable: 1
child:
sequence:
- filter: "{ Stmt8[i0, i1, i2, i3] }"
- filter: "{ Stmt3[i0, i1, i2, i3] }"
多重ループがある程度解消されて、かつ、タイリングと呼ばれる最適化がかかっている形になっています。
処理の中身は変わらないので、速度低下要因としてはループ構造の変化ではないかと推定できます。
要因となった機能を止めるオプションの探索
速度低下の要因と推定できたループ構造の変化ですが、このループ構造の変化を抑止することができれば要因かどうか確認することはできそうです。ということでpollyのソースを確認した結果以下のようなループ構造を抑止できそうなオプションを見つけました。
static cl::opt<bool> EnableReschedule("polly-reschedule",
cl::desc("Optimize SCoPs using ISL"),
cl::init(true), cl::cat(PollyCategory));
このオプションは以下の部分で使われています。
// Apply ISL's algorithm only if not overriden by the user. Note that
// post-rescheduling optimizations (tiling, pattern-based, prevectorization)
// rely on the coincidence/permutable annotations on schedule tree bands that
// are added by the rescheduling analyzer. Therefore, disabling the
// rescheduler implicitly also disables these optimizations.
if (!EnableReschedule) {
LLVM_DEBUG(dbgs() << "Skipping rescheduling due to command line option\n");
} else if (HasUserTransformation) {
LLVM_DEBUG(
dbgs() << "Skipping rescheduling due to manual transformation\n");
} else {
// Build input data.
int ValidityKinds =
Dependences::TYPE_RAW | Dependences::TYPE_WAR | Dependences::TYPE_WAW;
int ProximityKinds;
どうやらpollyによる再スケジューリングを制御するオプションのようですが、このオプションをoffにすることにより、タイリングを含む最適化を抑止することができそうです。
再スケジューリング抑止効果
このオプションによる再スケジューリング抑止した効果について確認します。
計測方法
- コンパイラ: clang/llvm 15.0.6
- オプション
- 基準:
-O3 -DPOLYBENCH_USE_C99_PROTO -DPOLYBENCH_TIME - pollyループ最適化+再スケジューリング抑止:
-O3 -mllvm -polly -mllvm -polly-reschedule=false -DPOLYBENCH_USE_C99_PROTO -DPOLYBENCH_TIME - pollyループ最適化+OpenMP並列化+再スケジューリング抑止:
-O3 -mllvm -polly -mllvm -polly-parallel -mllvm -polly-reschedule=false -DPOLYBENCH_USE_C99_PROTO -DPOLYBENCH_TIME
- 基準:
- OMP_NUM_THREAD: 8
実行時間を3回計測し平均値を算出しました。
計測結果
基準としたオプションでの実行速度を1として各オプションでの実行速度を算出しました。
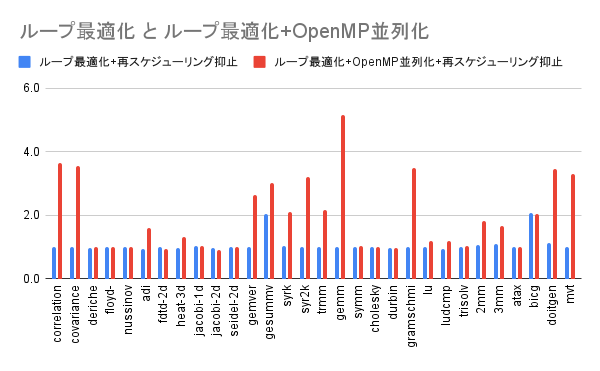
| プログラム名 | ループ最適化 +再スケジューリング抑止 |
ループ最適化 +OpenMP並列化 +再スケジューリング抑止 |
|---|---|---|
| correlation | 0.998 | 3.631 |
| covariance | 0.994 | 3.562 |
| deriche | 0.967 | 1.011 |
| floyd-warshall | 0.994 | 0.998 |
| nussinov | 0.992 | 1.000 |
| adi | 0.938 | 1.590 |
| fdtd-2d | 1.002 | 0.938 |
| heat-3d | 0.967 | 1.299 |
| jacobi-1d | 1.015 | 1.035 |
| jacobi-2d | 0.975 | 0.909 |
| seidel-2d | 0.997 | 1.001 |
| gemver | 0.999 | 2.628 |
| gesummv | 2.037 | 3.030 |
| syrk | 1.019 | 2.096 |
| syr2k | 1.011 | 3.193 |
| trmm | 0.986 | 2.167 |
| gemm | 0.991 | 5.153 |
| symm | 1.008 | 1.021 |
| cholesky | 0.999 | 0.992 |
| durbin | 0.979 | 0.979 |
| gramschmidt | 1.004 | 3.502 |
| lu | 0.990 | 1.179 |
| ludcmp | 0.944 | 1.181 |
| trisolv | 1.009 | 1.022 |
| 2mm | 1.072 | 1.826 |
| 3mm | 1.085 | 1.674 |
| atax | 0.999 | 1.012 |
| bicg | 2.075 | 2.051 |
| doitgen | 1.114 | 3.467 |
| mvt | 1.003 | 3.292 |
| 幾何平均 | 1.051 | 1.673 |
再スケジューリングを抑止することで性能が低下はかなり解消されましたが、性能向上幅も限定されることになってしまいました。結果として幾何平均の結果は再スケジューリングを抑止する前と比較して悪化することになりました。
最後に
LLVMの自動並列化機能についての紹介とその効果について紹介しました。今回紹介したようにすべてのプログラムに対して効果があるわけではありませんが、特定ループ構造には効果が発揮されるものだと思います。今回は性能悪化要因について調査しましたが、次回は改善について何かできればと思っています。
その他
実行環境
CPU: Intel(R) Core(TM) i7-6700K CPU @ 4.00GHz
メモリ: DDR4-3000 64GB
最適化による実行結果差分の確認
polybenchではコンパイラオプションとして-DPOLYBENCH_DUMP_ARRAYを指定することで計算後の配列の中身をダンプすることができる。今回は各最適化オプションごとにダンプしたデータをファイルに保存し、diffコマンドにより実行結果に差分がないかを確認しています。