はじめに
今回はDatabricksのAutoMLのパフォーマンスについてちょっとお話ししたいとおもいます。
DatabricksのAutoMLとは
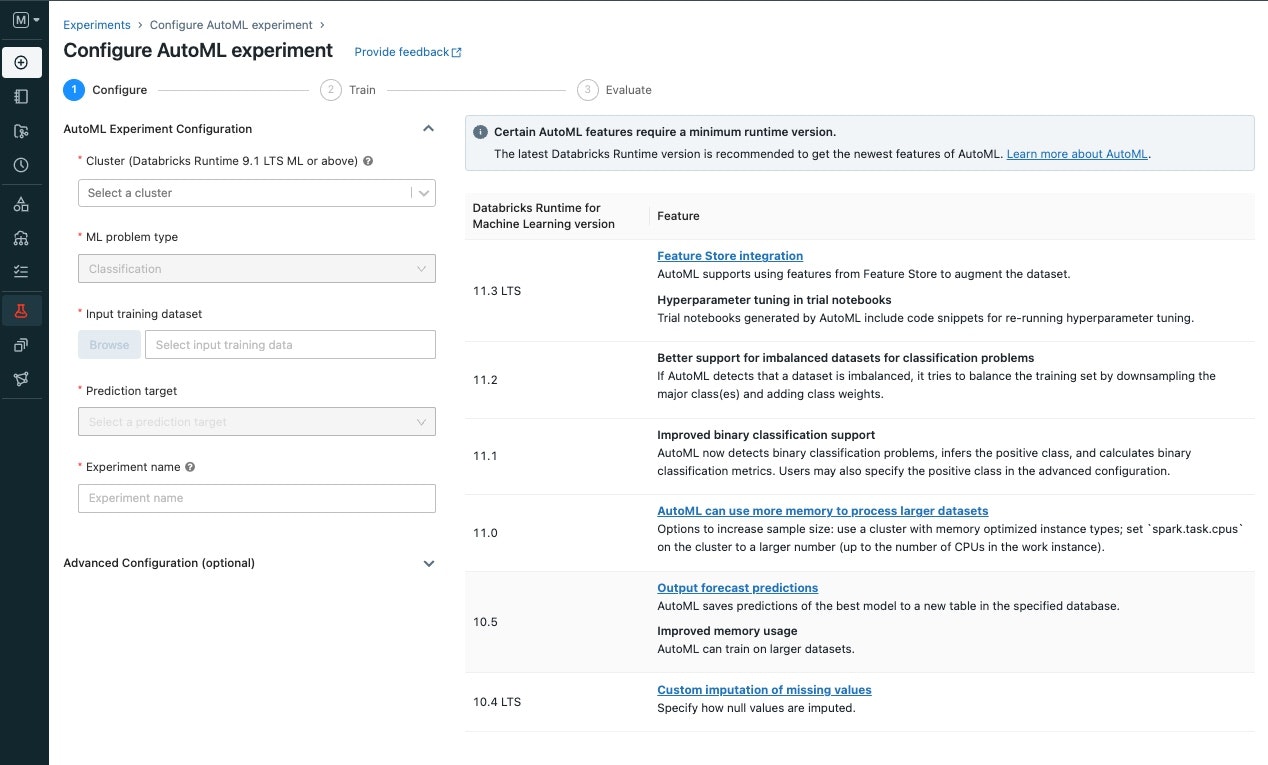
数クリックで実行可能なGUI/CUIベースのAutoML
- clusterの選択
- ML Problem type(回帰、分類、時系列予測)
- データ(テーブルの指定)
- 予測したいfield
AutoMLで生成されたモデルはすべてmlflowで自動でTracking
-
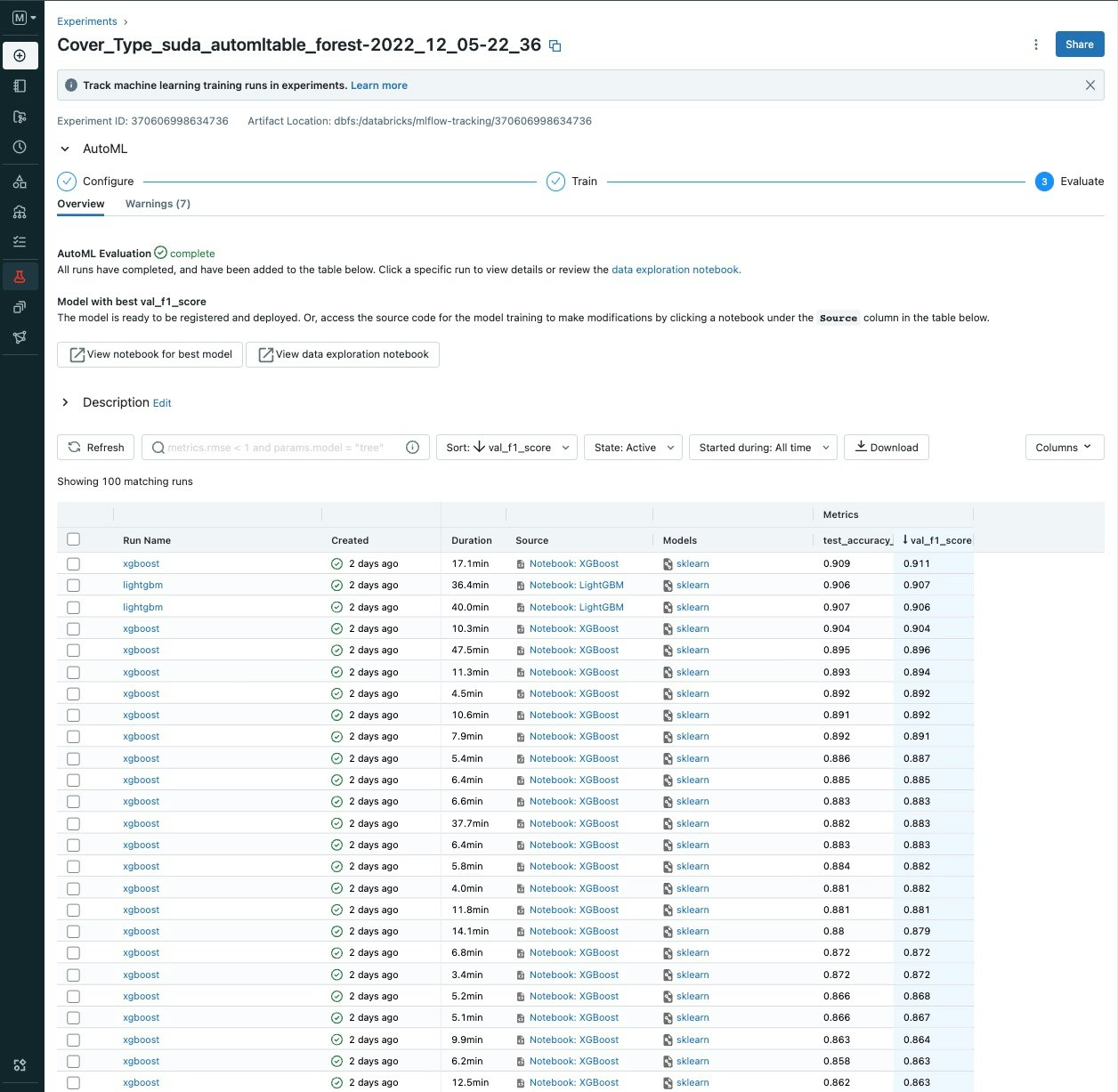
実験結果のOverview
-
各モデルの比較
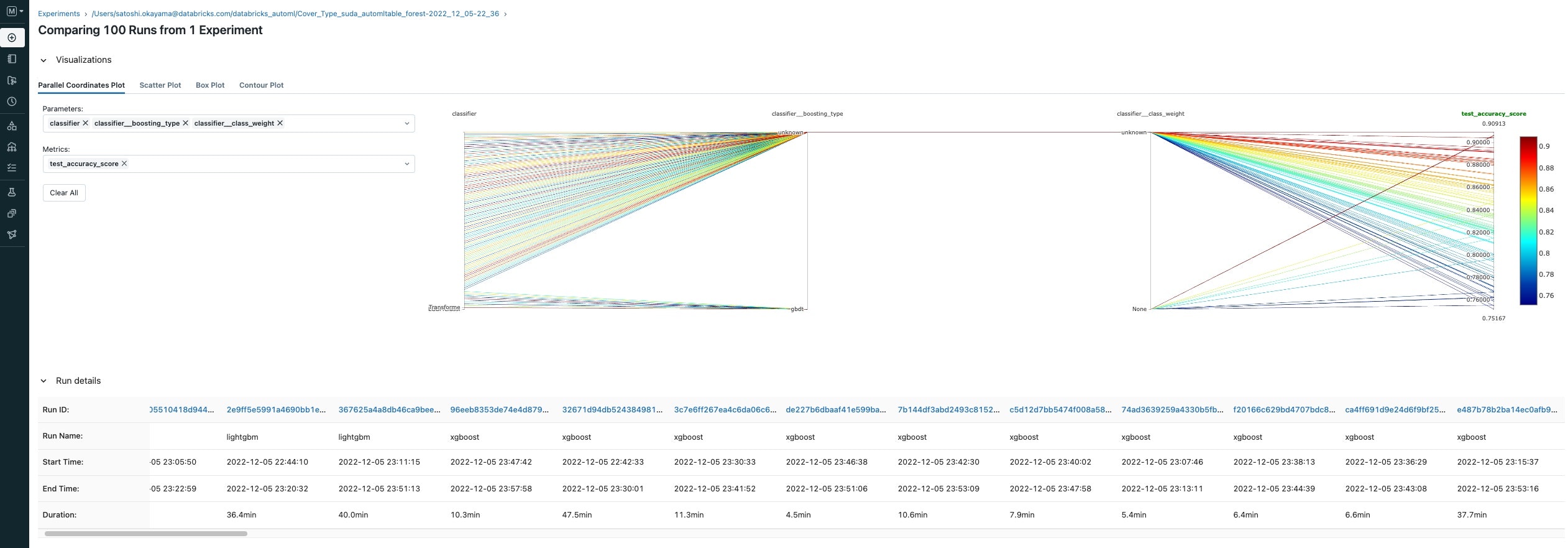
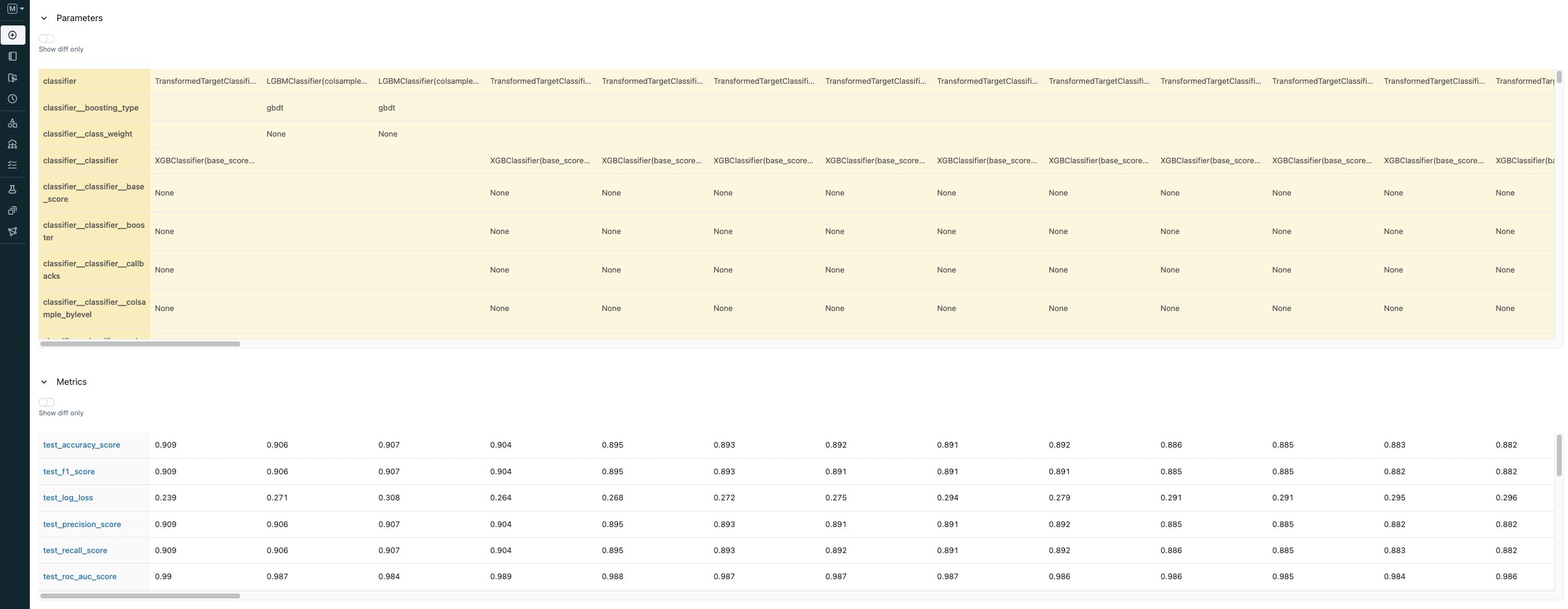
精度の確認
今回、どのくらいの精度がでるかというところで、SIGNATE様が出されているTest用のCompetitionデータを使ってAutoMLを回して見たいと思います。
https://signate.jp/competitions/126
タスクとしてはコロラド州のルーズベルト国有林の樹木観察情報から林形(7種)を分類する多変量のタスクになります。
データ準備
データをSIGNATEのサイトからダウンロードして、DBFSにupload後、automl用にDeltatable化しておきます。
AutoML側で特徴量の抽出をさせるので、特に加工せずにBronze tableとして扱います。
df = (spark.read.option('header', 'true')
.option('sep', '\t')
.option('inferSchema', 'true')
.csv('/FileStore/tmp/train-1.tsv')
)
df.write.mode("append").saveAsTable("suda_automltable_forest")
AutoMLを実行
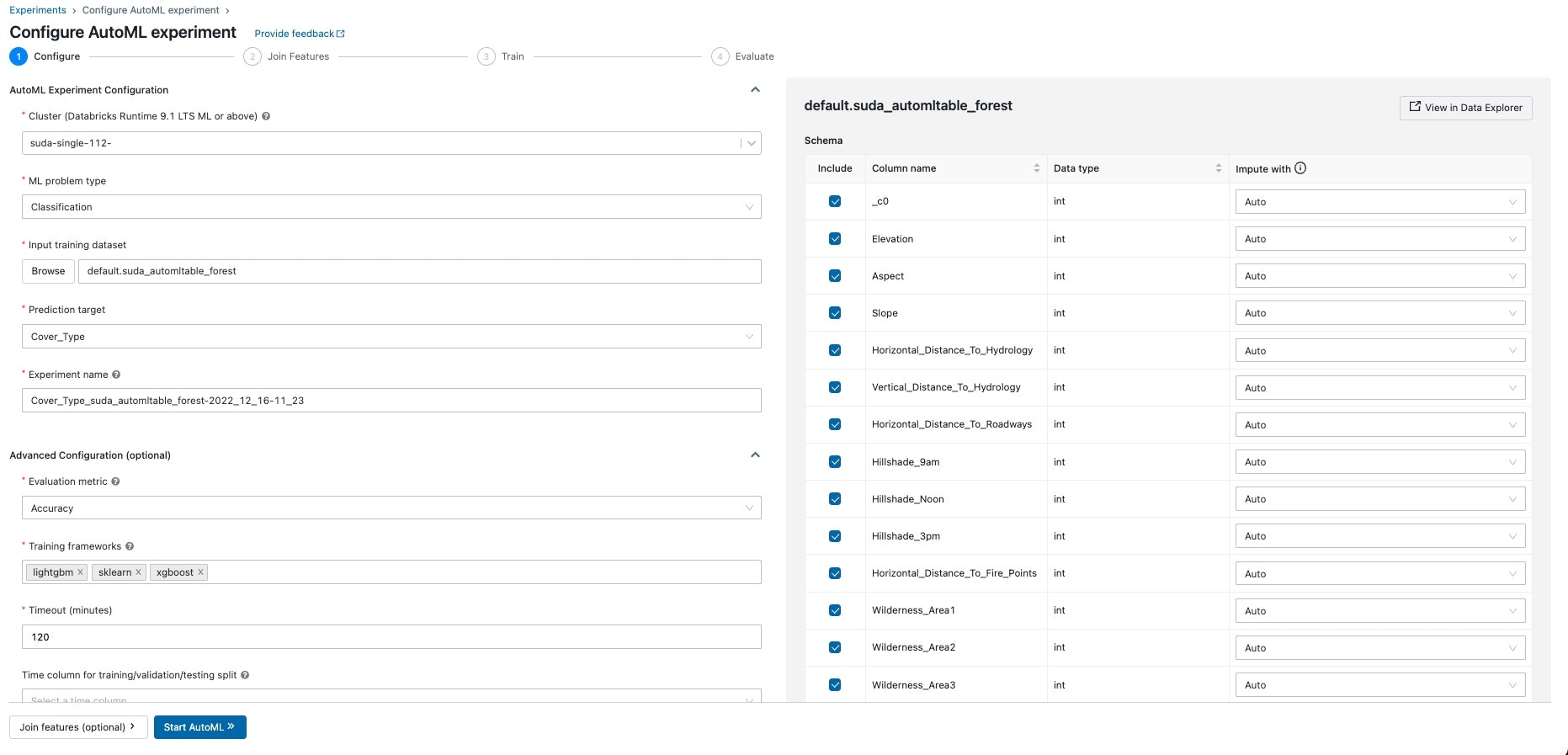
- 選択項目
- Cluster : 利用するCluster(ML Runtime)のものを利用します。(AutoMLを実行した分だけ課金される仕組みです)
- ML problem type : Classfication (他には回帰、時系列予測が使えます)
- Input Training Dataset : ↑で作成したtableを設定
- Prediction Target : 今回はCover typeを選択します(林の型)
- Evaluation Metrics : 今回のテストコンペの評価指標はaccuracyを選択します(他にはf1score、logloss、ROCなどを選択できます)
項目を選択後、Startを押して実行します。
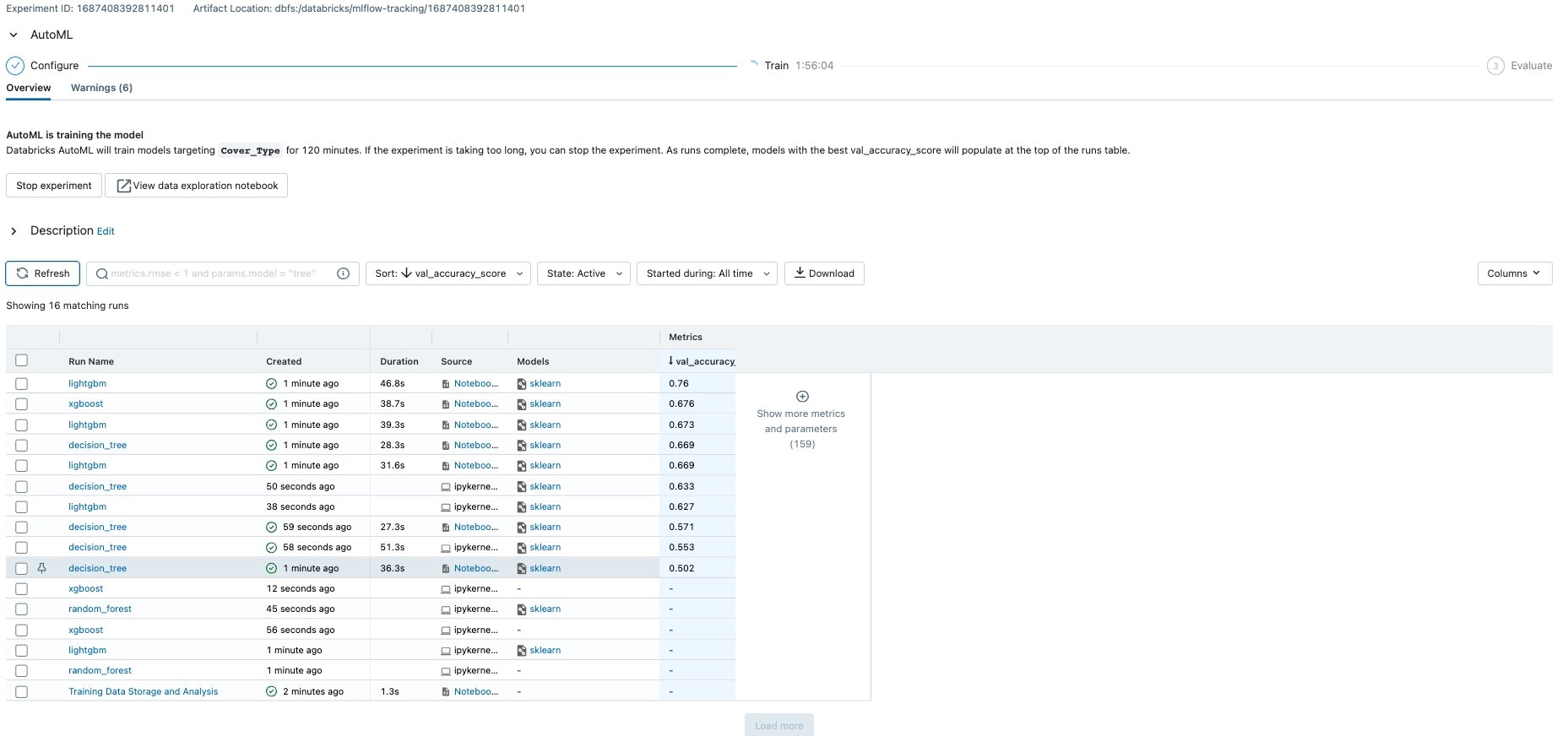
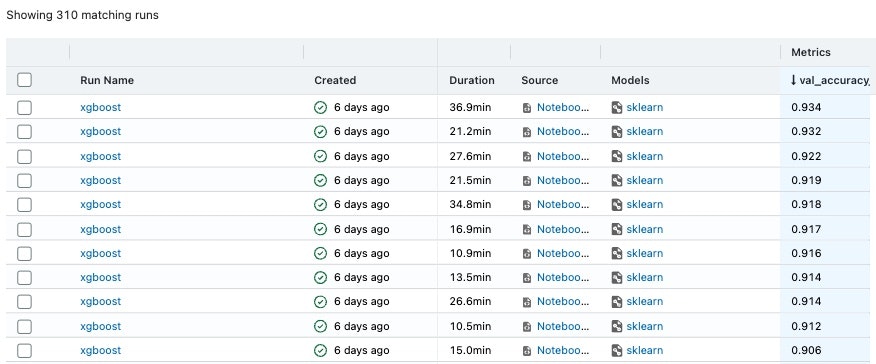
データセットにもよるので、なんとも言えませんが開始5分程度で13個ほどのモデルが学習されている状態になります。
アルゴリズム、ハイパーパラメータチューニングなどを自動で行い、結果300ほどのモデル生成が行われました。
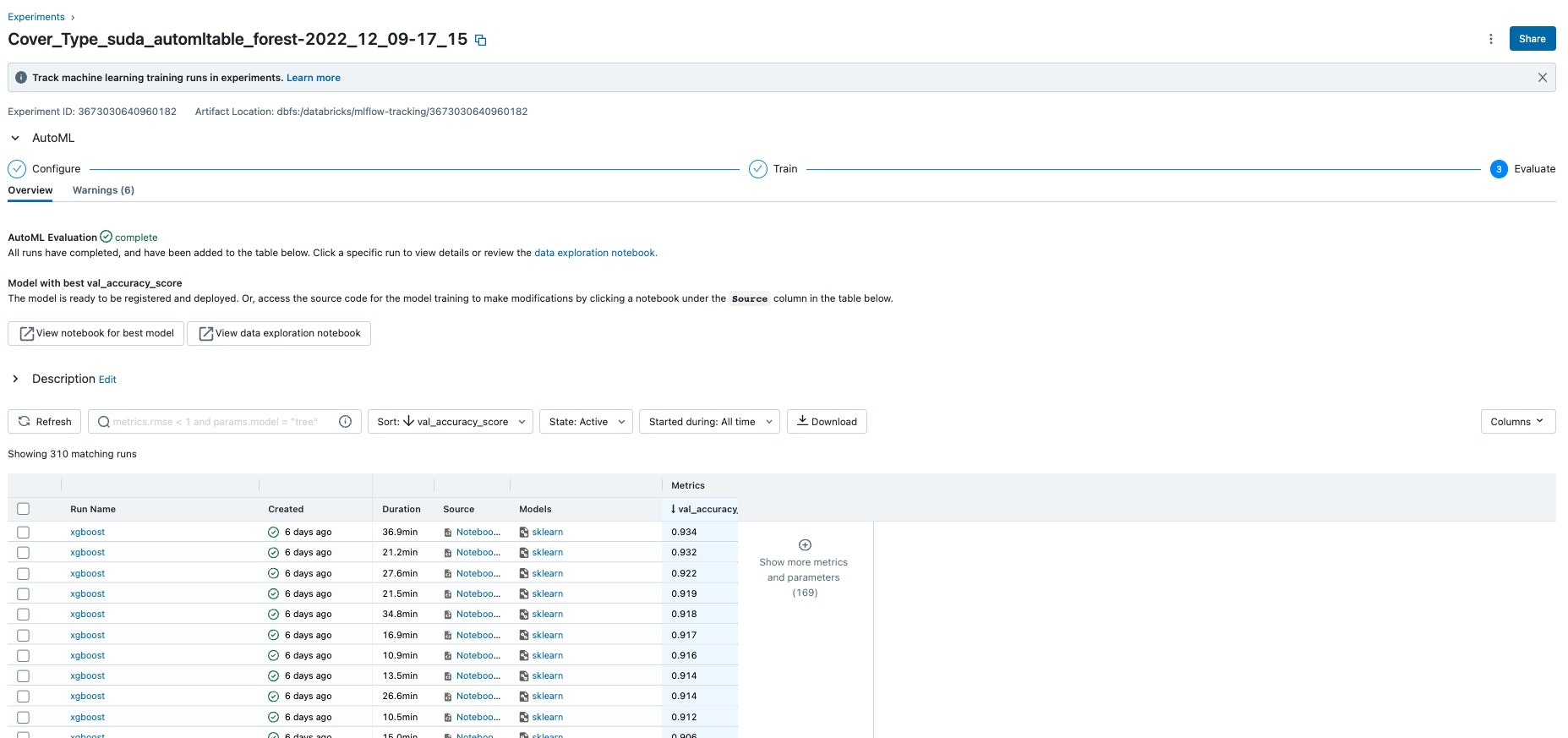
AutoMLを実行したころのaccuracyの値はかなり低いのですが、時間が経つにつれ、精度がよくなっていっていることがわかっていただけるかとおもいます。
・初期のころ
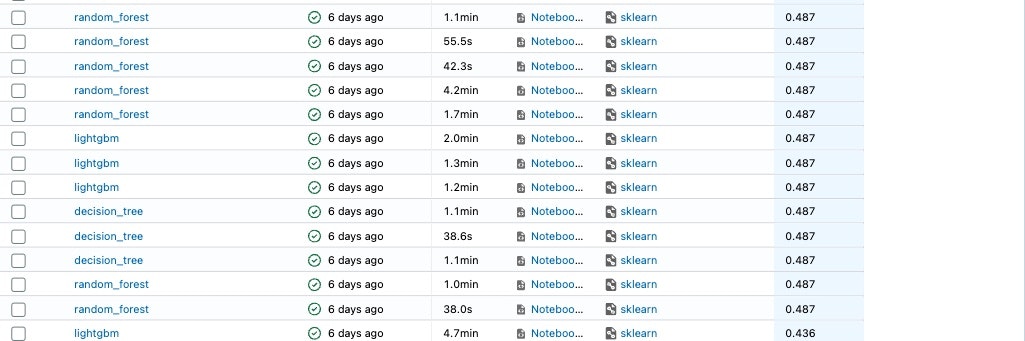
・最終のころ
中身を見てみる
DatabricksのAutoMLでは作成したモデルに対して、notebookが出力されます。
どういうデータをloadしたのか、特徴量の抽出、データ加工、ハイパーパラメータになにを与えていたかなどが全てわかるので、AutoMLでベースラインを作成して、さらにチューニング、mlflowで比較といった流れを作ることができます。
また、作成したmodel自体はartifactとして保存されるので、pyspark、pandasからの呼び出しサンプルコード、pklも生成されており、sagemakerなどとの連携も可能です。
Datbricks側でモデル登録、REST APIを使ったmodel servingも可能ですので、End to EndのMLOPSも対応できます。
精度は?
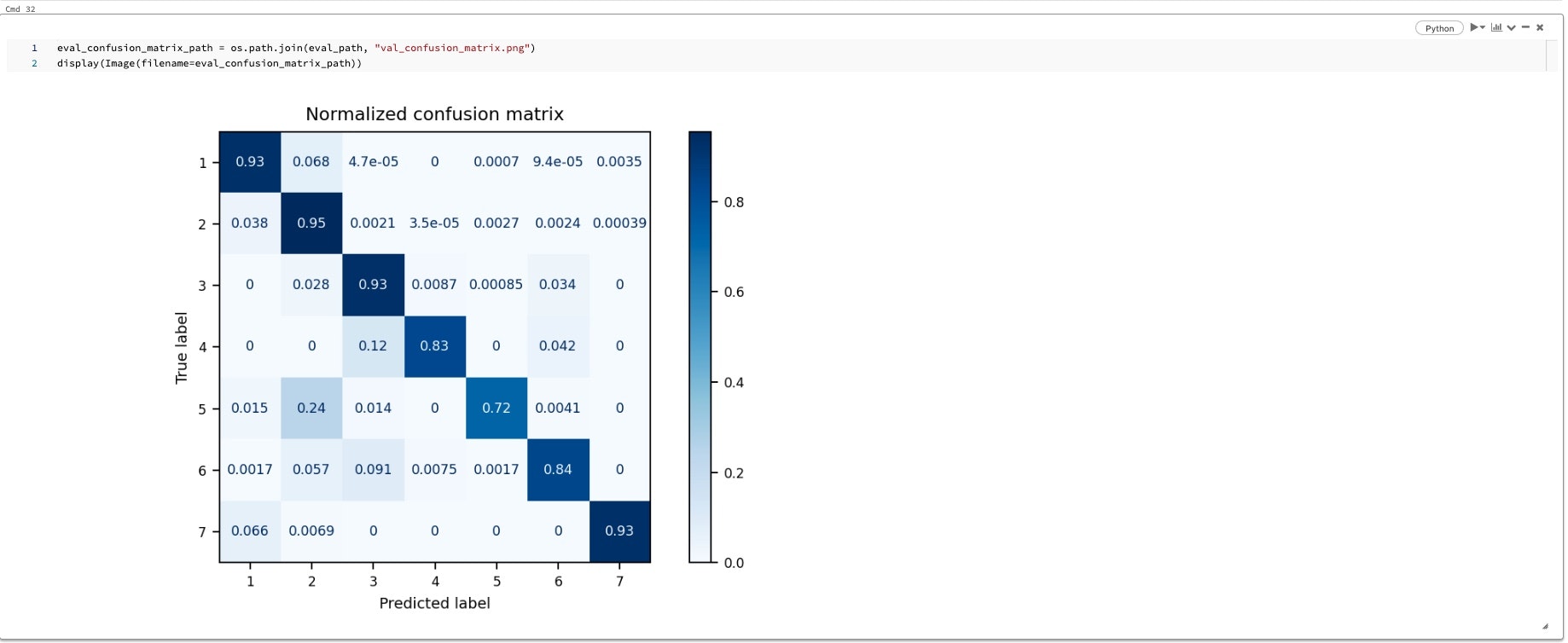
最終的に最もよい精度(accuracy)は0.934を記録しているので、精度としてはいい値かと思います。
コンペの上位の方達も9.7近くの値をだされているので、baselineの作成としてはAutoMLを活用いただけるのでは!
