概要
docker等のコンテナ技術を利用してシステムを構築する場合、アーキテクチャとしてシステムをマイクロサービスに分割して開発・運用するという流れは最近の大きなムーブメントの一つなっているように感じます。
一つ一つ機能を実装してはイメージを作成し雨後のタケノコのごとく増えていくAPI。増大するネットワークトラフィック。デバッグの難しさ。コンテナを管理するために増えていくコンポーネント。
人類にはコンテナは早すぎたのではないか。苦労して構築したマイクロサービスのシステムの運用と監視の事を考えるとまぁそんなことを思わないわけでもないです。
オンプレ、IaaSの環境とコンテナ環境違うところは様々ありますが、コンテナに移行すると基本的な運用の仕方はスクラップアンドビルドです。
そのような運用の仕方は様々なメリット(状態が安定する、スケーラビリティが担保しやすいシステムになりがちetc)がありますが、その副作用として運用上固定IPが利用できない(やりづらい)などのデメリットがあります。
つまり固定のIPが固定のサービスと必ずしも紐づかないことになります。
そのような状態でクライアントはどのように利用可能なコンテナを見つけることができるのでしょうか?
その考え方の一つがService Discoveryというものになります。
Service Discovery
ずいぶんと大げさな言い方をしていますが、オンプレ・IaaSでもクライアントからAPIをリクエストする際に直接IPを指定することは稀で基本的にはホスト名を利用していると思います。
どのようにホスト名からIPを取得しているのでしょうか。はいDNSですね。
つまりService DiscoveryとはDNSのことだったんだよー(ナ、ナンダッテー)
というのは個人的に8割は正解なのではないかなと思っていますが、既存のDNSのシステムはあくまでIPとホスト名を紐づけるシステムであり、実際にそのままDNSをマイクロサービスのServiceRegistry(後述)としてServiceDiscoveryとして使用すると色々と足りない点が出てきます。
例えば、DNSに登録しているIPのコンテナが障害で落ちてしまった場合、どうやって該当のIPを検知してどのようにそのIPをDNSのレコードから削除すればよいでしょうか?
今回はそこら辺のアルゴリズムには一切触れません、がマイクロサービスアーキテクチャにおけるService Discoveryについて、どのような実現方法があるのかをパターンとそれに利用できるOSSやらシステムを紹介していきたいと思います。
Service Registry
そのパターンを紹介する前にService Discoveryの要であるService Registryについて説明します。
読んで字のごとくサービスを登録するコンポーネントです。つまりDNS(ry
よく見る実装方法だとサービスとそのサービスのネットワーク上の場所が管理されているKVSやデータベース、またDNSのMX及びSRVレコードなどを指します。クライアントはそのデータベースからサービスのネットワーク上の位置(IP、ポート番号)そして優先度、weightなどを得ることができ、サービスは現在利用可能なネットワークをサービスレジストリに登録・登録削除することができます。
Healthcheckや生存期間を設定し自動的に登録の削除ができるような機能があれば望ましいです。
またこのコンポーネントがお亡くなりなると内部の通信はすべてお亡くなりになりひいてはサービスごとお亡くなりになるため、高い可用性を求めれます。
加えてデータセンター間でDR等を構築している場合データセンター間でService Registryが保持する情報に整合性を求める必要が出てくる場合もあるかもしれません。
これかの機能を実現する代表的なソフトウェア及びサービスは
が該当するかと思います。
またk8sなどのコンテナオーケストレーションシステムも内部的にdnsをservice registryとして使うこともできます。(多分)
Client-Side/Server-Side Service Discovery Pattern
利用可能なコンテナを見つけるのがサービスディスカバリという話を先ほどしましたが、大きな考え方として2通りの見つけ方があります。サーバー側が見つけるかクライアント側が見つけるかです。
クライアント側が見つける (Client-Side Service Discovery Pattern)
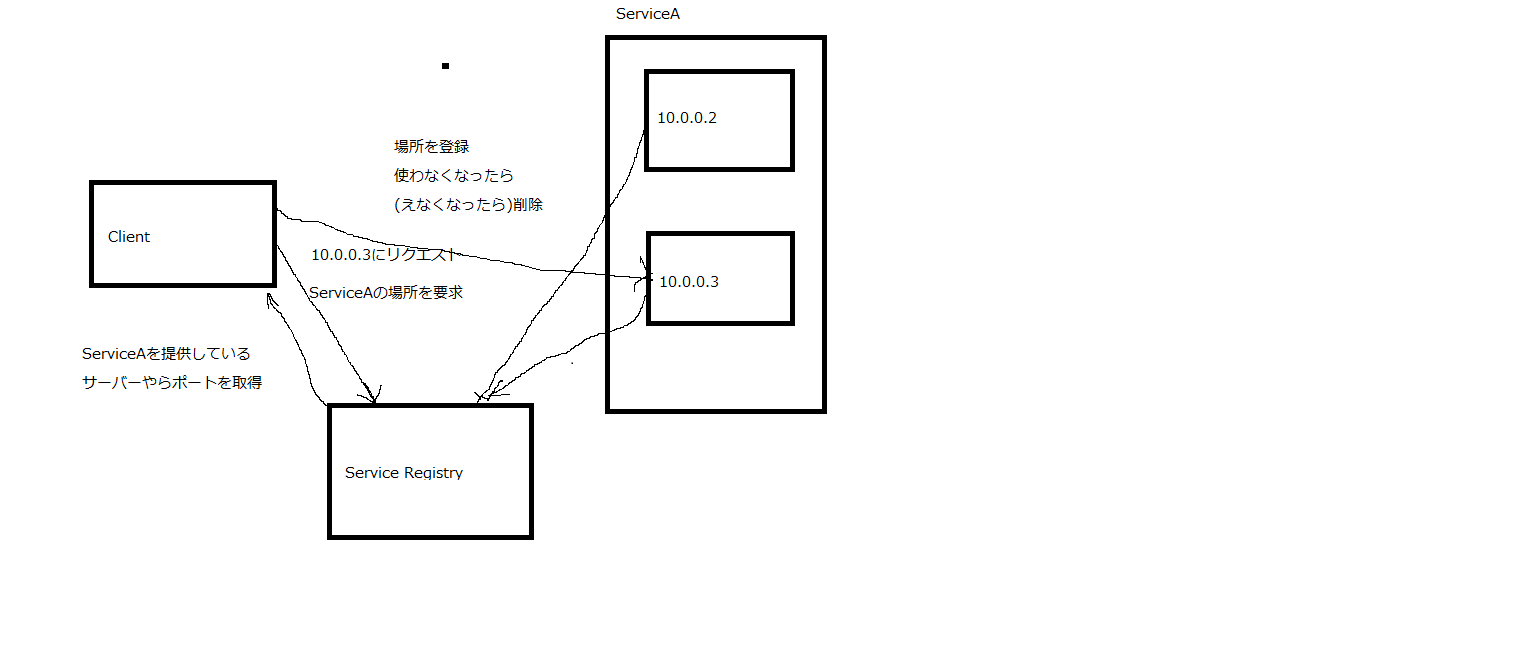
雑な絵だけどだいたいわかるよね!つまりクライアント側がService Registryに問い合わせてその情報からどのホストにリクエストをするか選択し、リクエストを送っています。
重要なことはこのアーキテクチャの場合Client側がServiceを選ぶロジックや場合によってはhealthcheck等を実装しなければならないという点です。
ただし、クライアント側で(実装すれば)ロードバランスの方法が簡単に変更できたりすることや、ネットワークの制限などは後述するサーバーサイドのケースより柔軟に変更ができるというメリットもあります。
サーバー側が見つける (Server-Side Service Discovery Pattern)
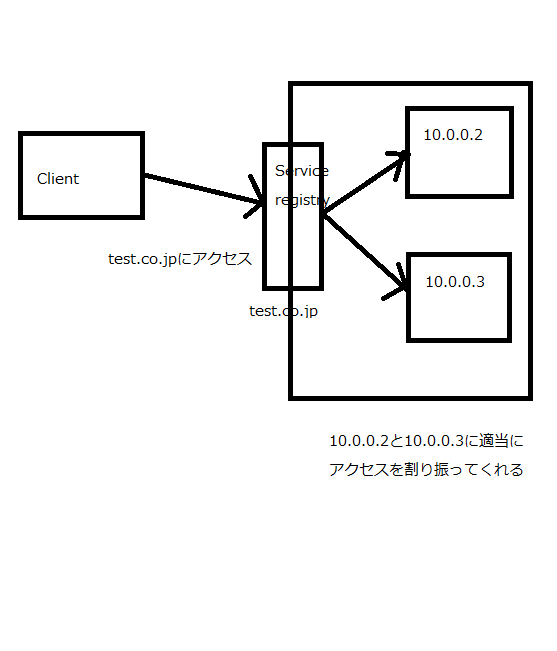
上の図がサーバーサイドサービスレジストリパターンと呼ばれるものでクライアントはただtest.co.jpにアクセスするだけでロードバランスやヘルスチェックなどは一切考える必要はありません。代わりにServiceRegistry側がロードバランス・ヘルスチェック等の必要な機能をすべて賄ってくれます。
クライアントサイドとしては何も考えなくても良い反面、設定の変更などはすべてServiceRegistry側で一元管理され変更する難易度が高かったり、そもそもServiceRegistry自体が死ぬとそのバックエンドのへのアクセスが一切できなくなる構成になってしまい、SPOFな構成になりがちという問題も持っています。
GSLBやHAProxy, VIP等が代表的なServer Side Service Discoveryの構成になるかと思います。
以上がService Discoveryってなんなんだっけというお話でした。
ちょっと長くなってきたので今回はここまで次回Service自体がどのようにService Registryに対して情報をアップデートするのかというお話をまとめたいと思います。
参考資料
https://microservices.io/patterns/service-registry.html
https://microservices.io/patterns/client-side-discovery.html
https://microservices.io/patterns/server-side-discovery.html