概要
これまでの「オンプレ編」では、Azure の仮想マシン(IaaS)を使って、社員番号から名前を検索できるシンプルな社内システムを構築してきました。Active Directory、SQL Server、ADFS などを組み合わせ、オンプレミスの構成を仮想的に再現しています。
※全体構成の詳細は、【第0回】Azureで社内システム再現(オンプレ編)|構成図と動作の流れ をご参照ください。
クラウド編では、これまでの構成をベースにしつつ、Azure のマネージドサービス(PaaS)を中心とした構成へ段階的に移行していきます。
※クラウド移行全体の設計方針については、【第10.5回】Azureで社内システム再現(クラウド編)|オンプレ構成をどうクラウドに移行するか? にまとめています。
システム構成(今回の対象範囲)
今回のテーマは、Azure Automation によって生成された社員情報の CSV ファイルをトリガーに、Azure Data Factory(ADF)で Azure SQL Database へデータを転送する構成を実現することです。
まず、下図は「クラウド編」における全体構成の一部を示したものです。
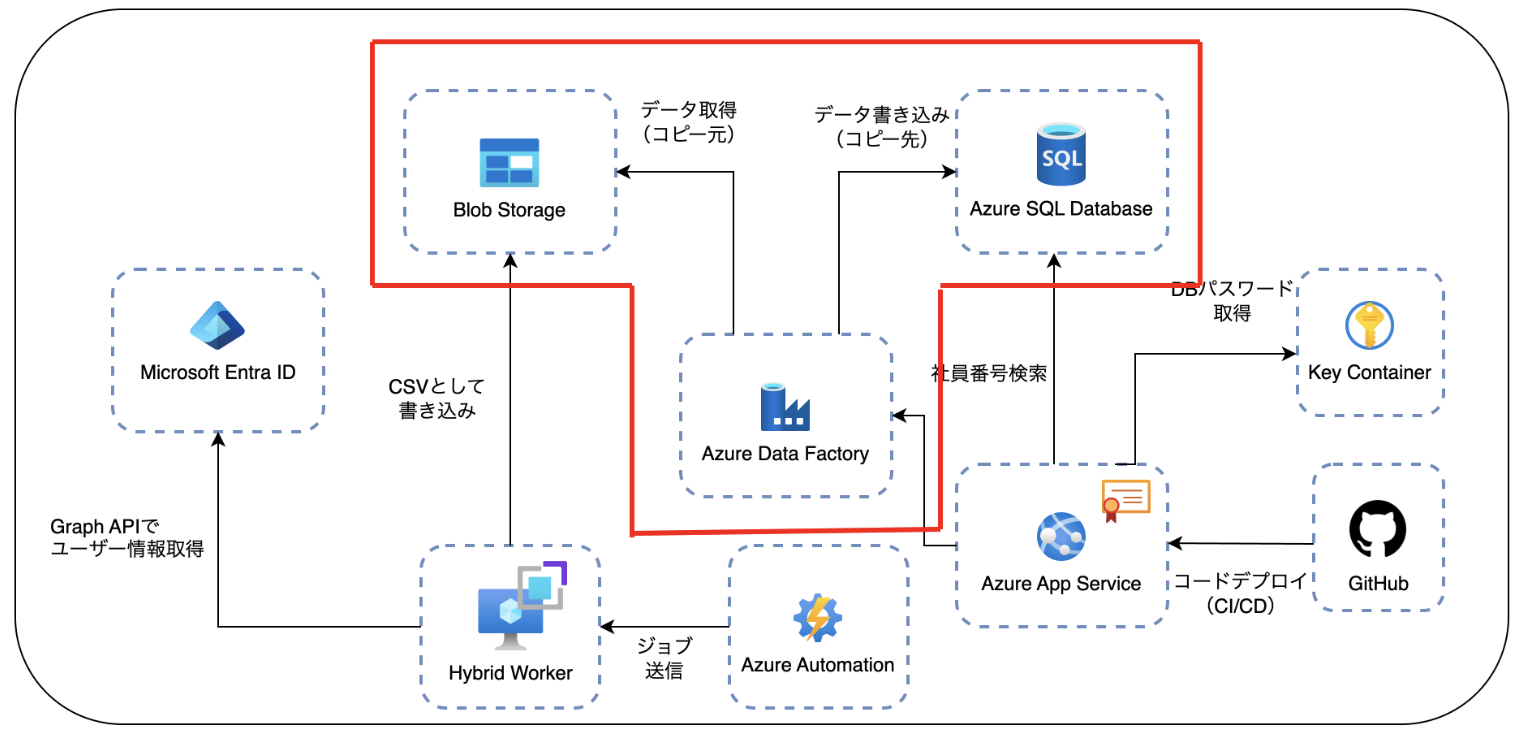
このうち、赤枠で示される「Blob 作成イベント → ADF 起動 → SQL 転送」までの連携処理が、今回の対象範囲です。
今回は以下の作業を行いました:
-
Event Grid & ADF トリガーの設定
Blob へのファイルアップロードを検知して、自動的にパイプラインを起動できるよう構成 -
SQL 側の初期化処理の追加
既存データを削除してから全件挿入するため、Sink に DELETE の事前スクリプトを設定 -
対象ファイルを限定する仕組みの導入
パイプラインとデータセットにパラメーターを追加し、1つのファイルだけを処理する構成へ変更 -
全体構成の検証と動作確認
Automation からのファイル生成 → ADF 実行 → SQL 反映までを通しで確認し、意図したデータ取り込みができることを確認
トリガーの作成
Blob にファイルがアップロードされたタイミングで ADF のパイプラインを自動実行させるために、トリガーを作成します。
その前に、「Event Grid」リソースプロバイダーの登録が必要です。
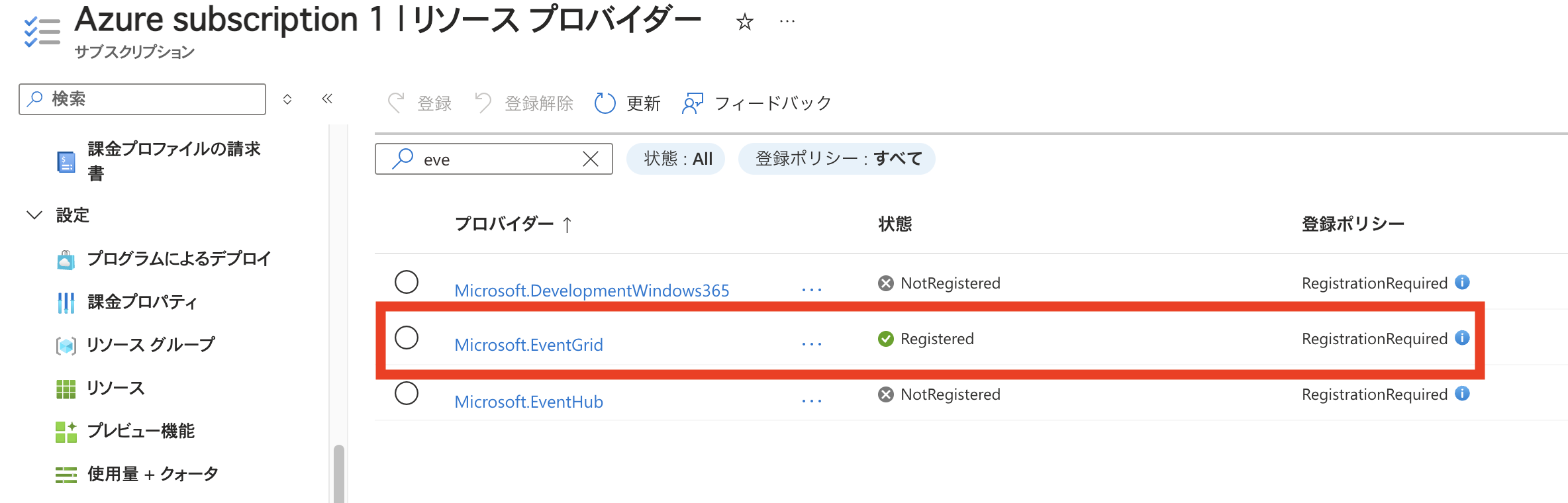
Azure では、サービス間のイベントを受け渡すために「Event Grid」を利用します。
Blob ストレージで発生したイベント(例:ファイル作成)を ADF に通知するには、この Event Grid のリソースプロバイダーが必要となります。
リソースプロバイダーとは?
Azureの各種サービスが Azure Resource Manager と連携するための「機能提供モジュール」のようなものです。
サービスを使う際は、そのサービスを「提供」しているリソースプロバイダーを登録しておく必要があります。
トリガーの追加設定
次に、ADF Studio 上でトリガーを追加します。
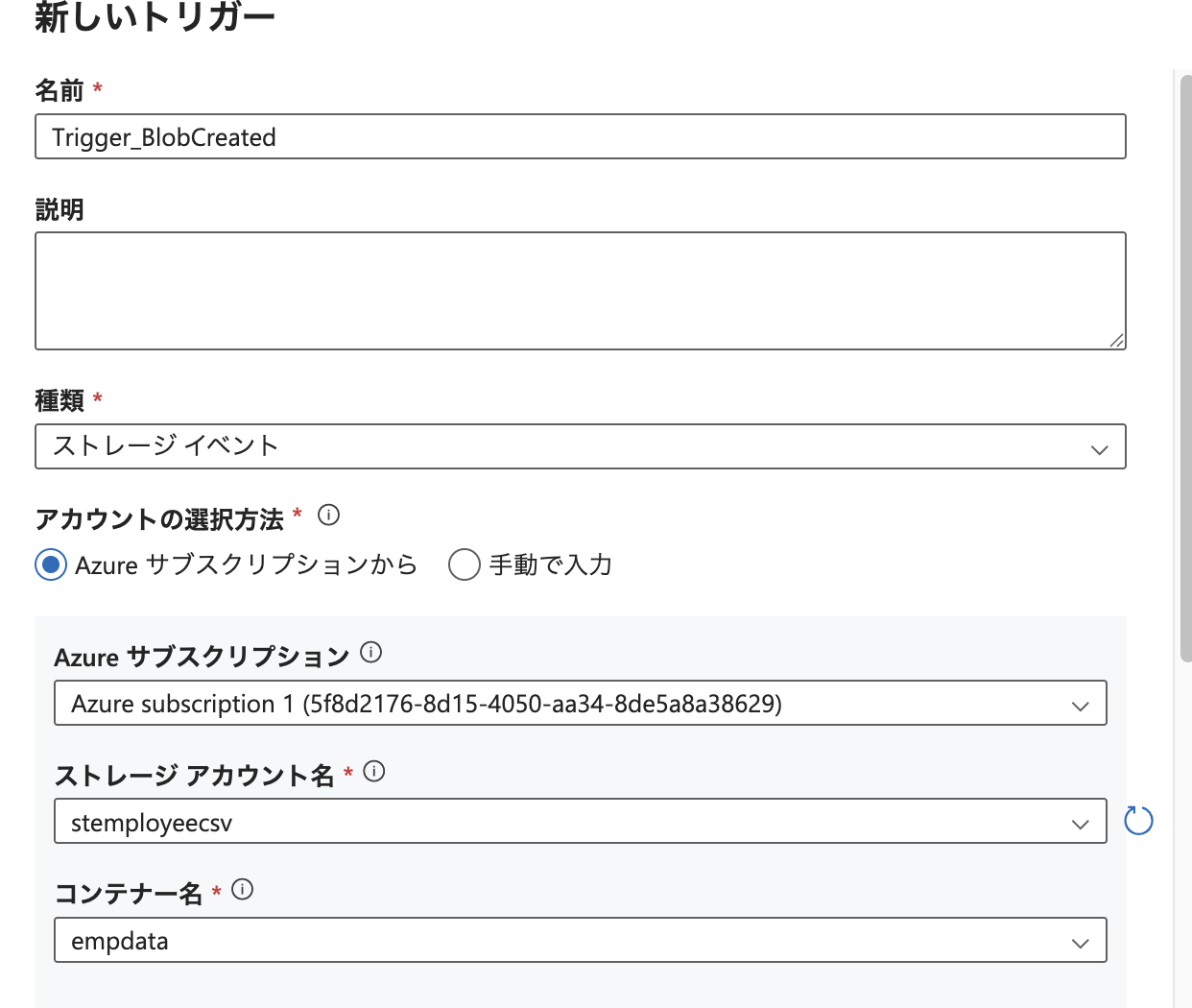
- トリガー名は
Trigger_BlobCreatedとしました - 種類:ストレージイベント を選択します
- 対象の ストレージアカウント名 と Blob コンテナ名 を指定します
パスの指定とフィルタ
Automation がアップロードする CSV ファイルは、バージョン管理ができるように以下のような形式になっています:
employees_20250403_121744.csv
このように、employees_ というプレフィックスに続いて日付・時刻が付き、.csv で終わるファイル名です。
そのため、トリガーの条件には以下のようなパスフィルタを指定しました。

-
先頭文字列:
employees_ -
末尾文字列:
.csv
この設定により、対象となる CSV ファイルがアップロードされたときにのみパイプラインが実行されるようになります。
データのプレビュー確認とトリガーの完成
トリガーのパス指定が正しく設定されているかを確認するため、Blob ストレージ上のファイルをプレビューしてみます。
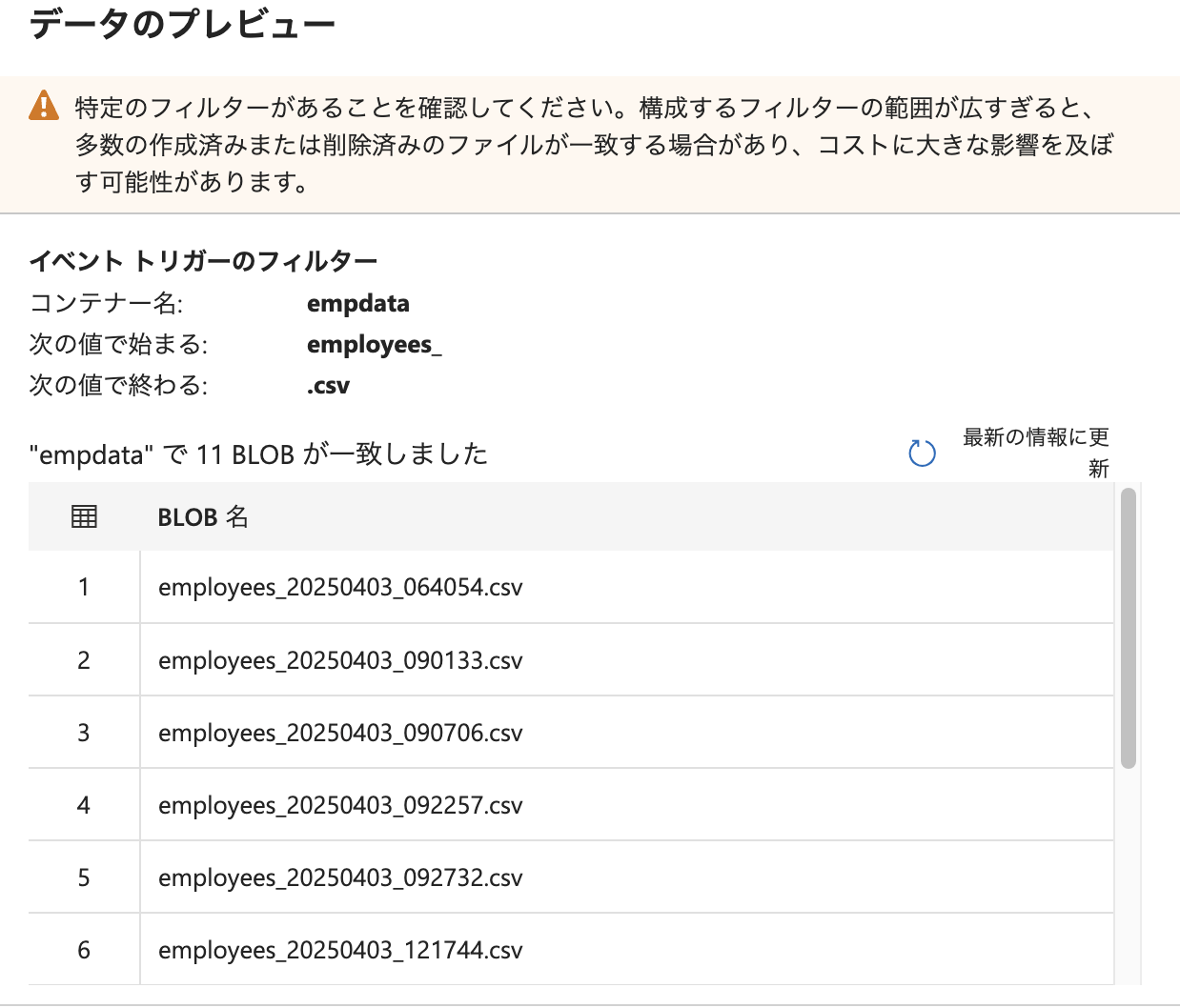
現在ストレージに存在しているファイル名が、指定した employees_ で始まり .csv で終わる条件に一致していることが確認できました。
この時点で、トリガーの作成はひとまず完了です。
Sink(SQL側)の事前スクリプト設定
次に、パイプラインの「Sink(コピー先)」として設定している Azure SQL Database 側の処理を確認します。
今回のパイプラインでは、以下のような設計になっています:
- 処理開始時に 既存のテーブルデータをすべて削除
- その後、Blob Storage の CSV 内容を 全件挿入(INSERT)
そのため、Sink の「事前スクリプト(Pre-copy script)」に、DELETE 文を記述しておく必要があります。
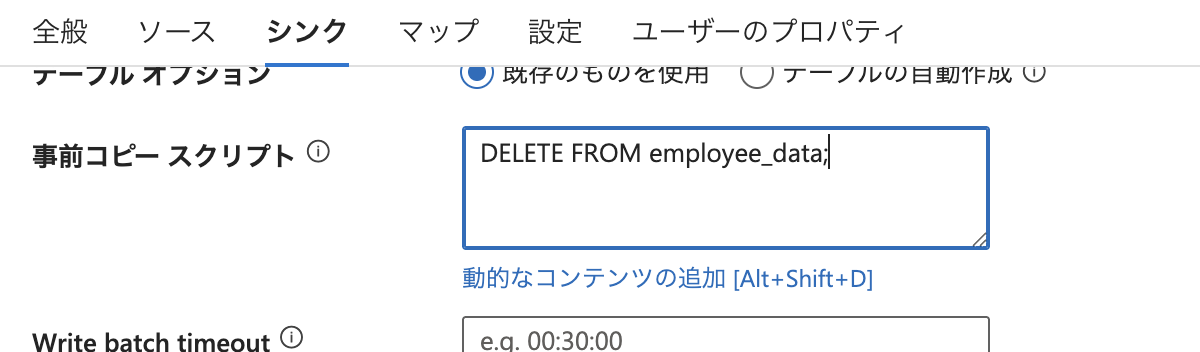
事前スクリプトとは、データコピー処理が開始される前に SQL 側で実行されるクエリを定義できる機能です。
今回は、以下のクエリを指定しました:
DELETE FROM employee_data;
この設定により、常に最新の社員情報が SQL テーブルに上書きされる構成になります。
パイプラインの検証と発行
トリガーとコピーアクティビティの設定が完了したら、パイプライン全体の検証を行います。
ADF Studio には「検証」機能があり、構成ミスや必須項目の未設定などがある場合に事前に警告してくれます。
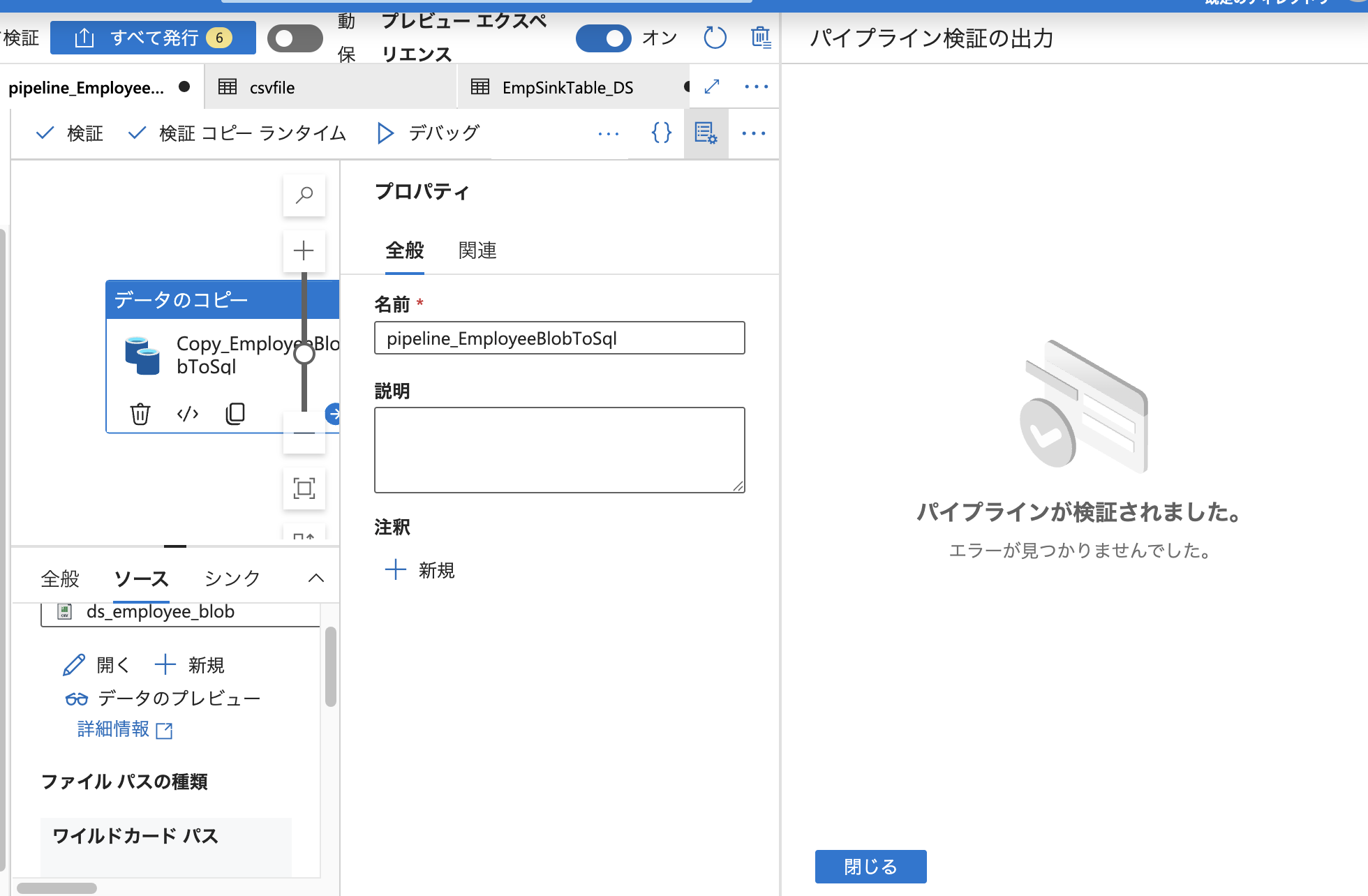
今回のパイプラインでは、**エラーなし(No errors found)**と表示され、構成に問題がないことが確認できました。
検証が完了したら、右上の「発行(Publish)」ボタンをクリックして設定を反映します。
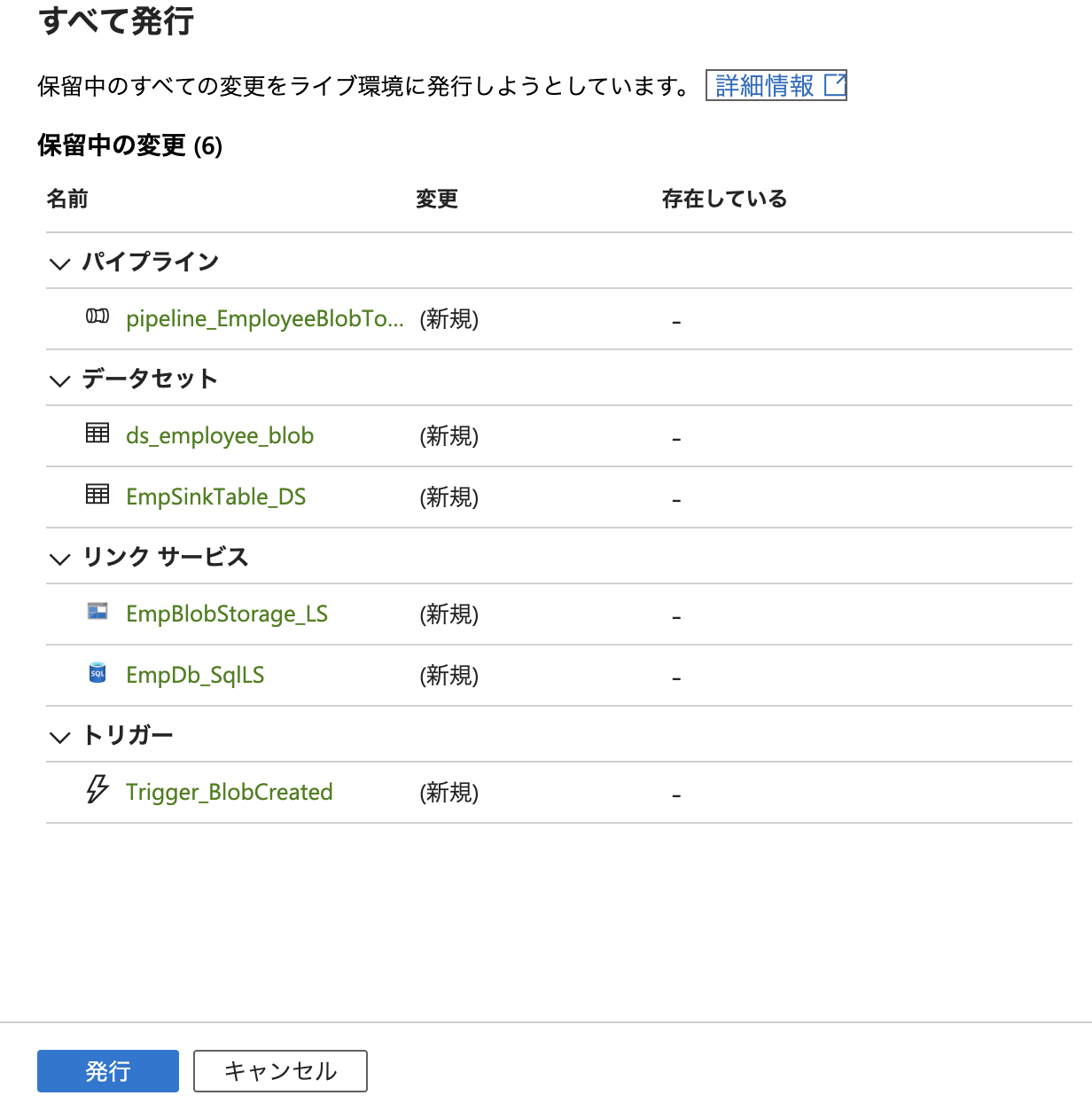
「発行」を行うことで、作成したパイプラインとトリガーの構成が ADF に反映され、以降は 指定の条件(今回の場合は Blob ファイルの作成)に応じて自動実行される状態になります。
動作確認(Automation → Blob → ADF → SQL)
最後に、実際の動作確認を行います。
AutomationからCSV生成ジョブを実行
まずは、Azure Automation の Runbook を実行し、CSV ファイルを Blob Storage に出力します。

ジョブはエラーなく完了しました。
BLOB にファイルが生成されたことを確認
Automation によって、指定のコンテナに CSV ファイルがアップロードされました。

このイベントをトリガーとして、ADF のパイプラインが自動実行されます。
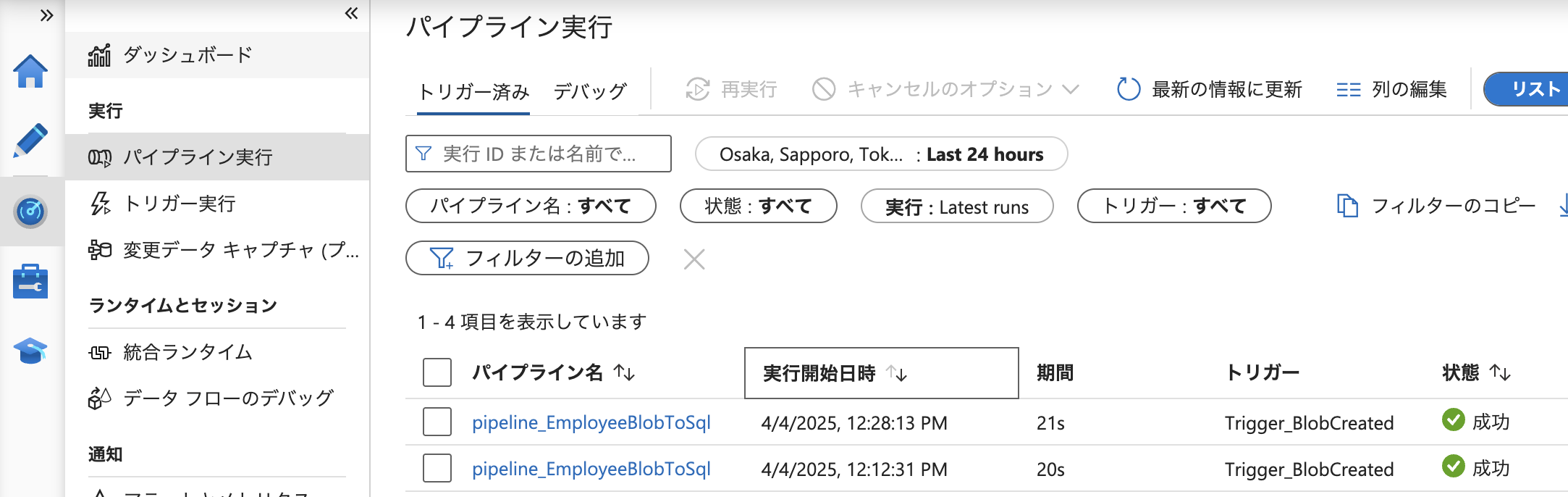
ADF パイプラインの実行結果
パイプラインのモニタリング画面から、処理が正常に実行されたことが確認できました。
SQL Database のデータを確認
実際に SQL Database へ接続し、employee_data テーブルの中身をクエリで表示・確認します。
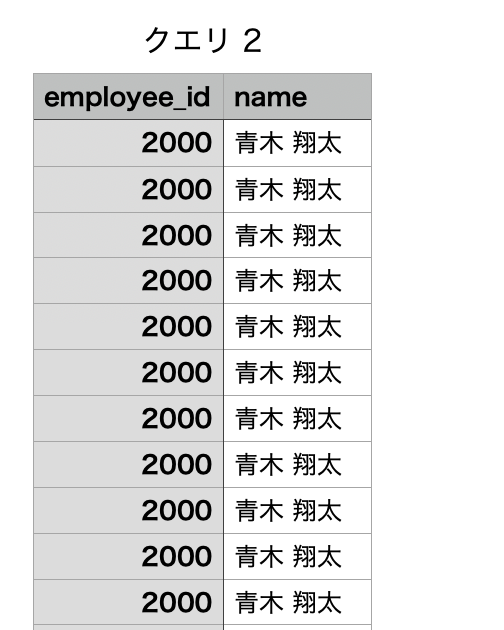
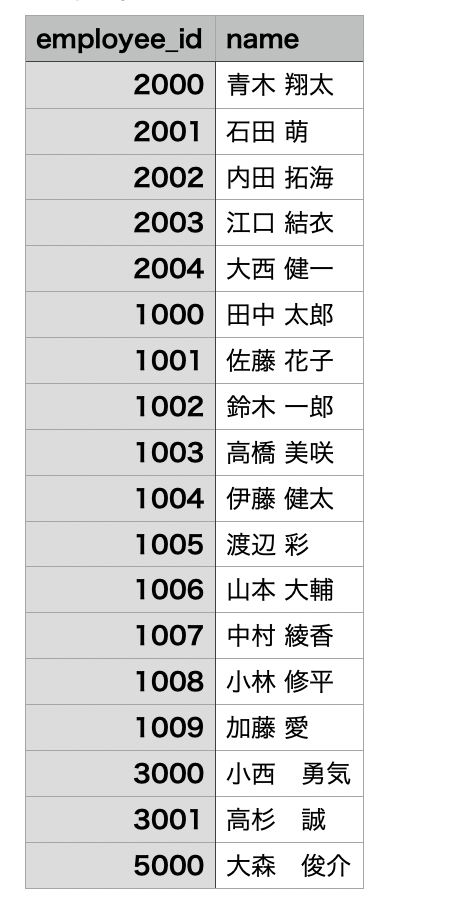
確認の結果、社員番号「2000」の「青木翔太」が 複数レコード登録されている ことがわかりました。
想定外のデータ重複の原因
今回の ADF パイプラインでは、Blob にある employees_ で始まり .csv で終わるすべてのファイルを取り込む設定になっていました。
そのため、過去に出力された古い CSV ファイルも対象に含まれ、同じデータが複数回 INSERT されてしまっていました。
アップロードされた特定のファイルだけを処理対象にする構成
この問題を回避するためには、処理対象となるファイルを明確に限定する必要があります。
そこで今回は、Blob ストレージにアップロードされた特定の 1 ファイルだけを対象に処理する構成へ変更しました。
この構成では、Blob にファイルが作成されたタイミングでトリガーが起動し、
そのファイル名をパイプラインにパラメーターとして渡します。
パイプライン側ではそのファイル名を受け取り、データセットを通じて対象ファイルのパスとして使用します。
このように、処理対象を動的に決定することで、過去のファイルが誤って取り込まれることを防ぎます。
まず、パイプラインに target_blob_name という文字列型のパラメーターを追加しました。
このパラメーターは、トリガーからファイル名を受け取るためのものです。
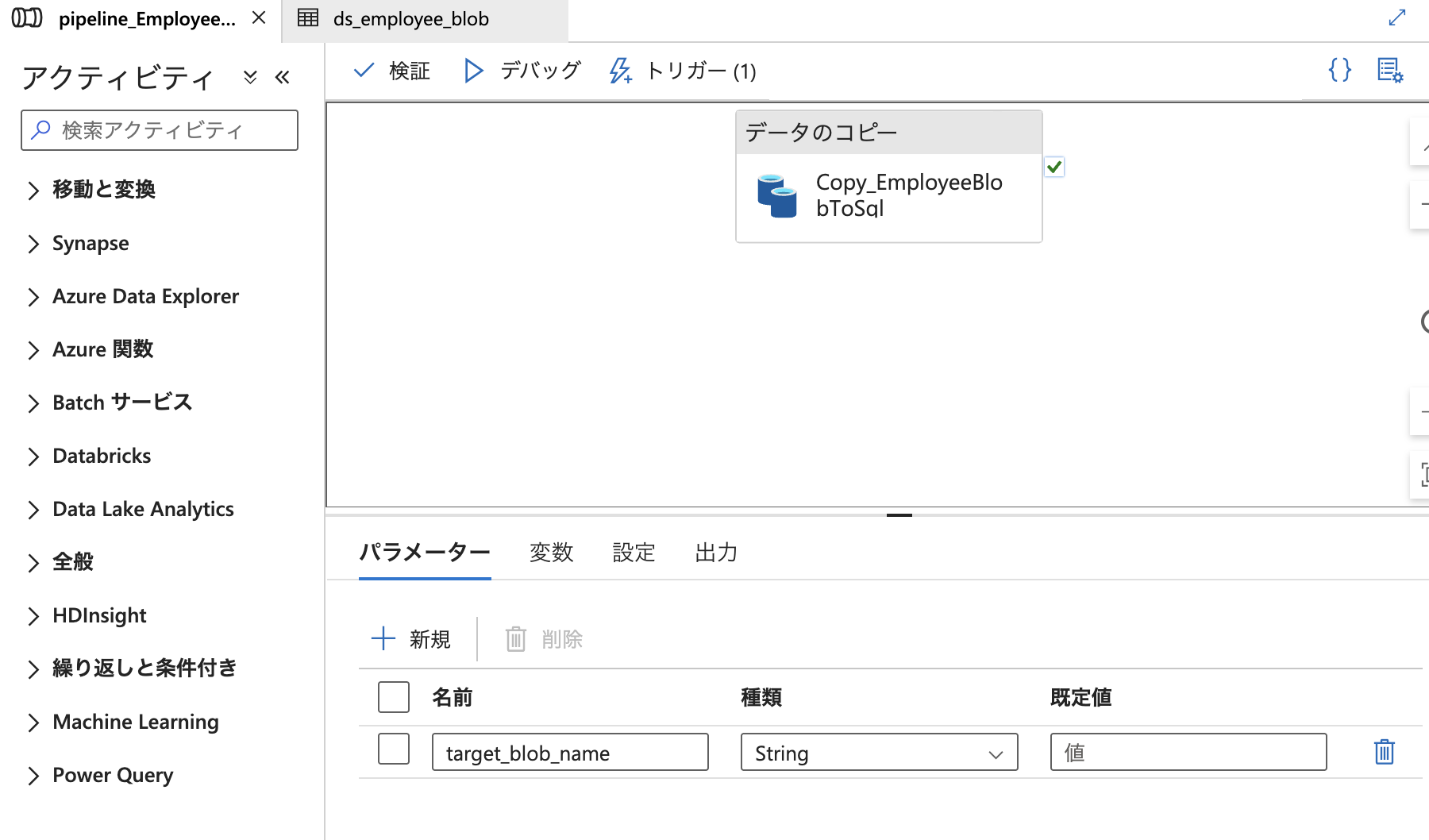
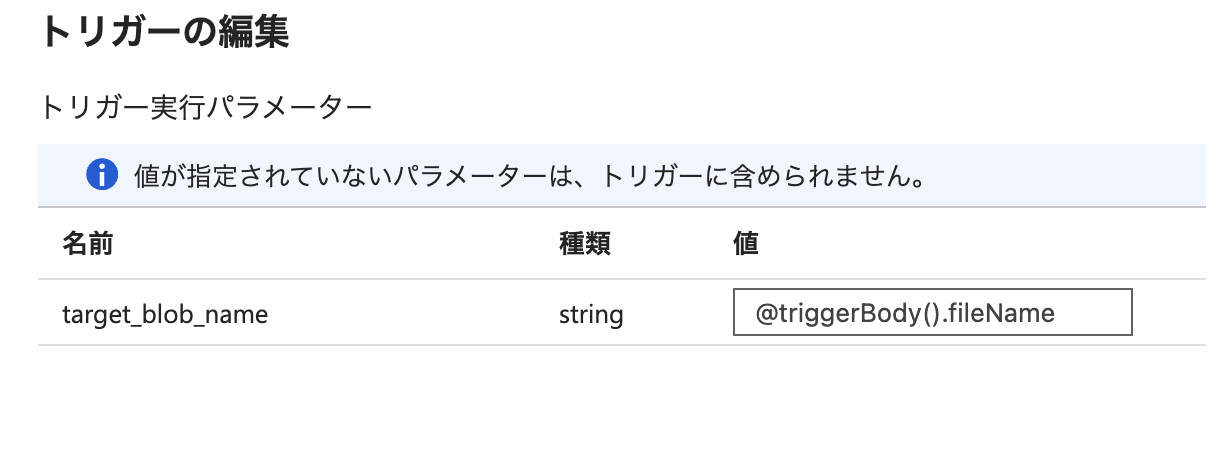
続いて、トリガー側でパイプラインにファイル名を渡す設定を行います。
トリガーイベント(Blob にファイルが作成されたタイミング)には、作成されたファイルの名前が含まれており、
これを @triggerBody().fileName という構文で取得することができます。
今回はこの値を、パイプラインで定義した target_blob_name パラメーターに割り当てました。
この設定により、トリガーの発火時に対象ファイルの名前がパイプラインに渡され、
後続の処理でそのファイル名を動的に使用できるようになります。
次に、ファイル名をもとに、対象のファイルだけを読み込む処理を構成します。
ファイルの読み込みには「データセット」という構成要素を使用します。
データセットは、Data Factory における「どこから・どのような形式でデータを扱うか」を定義するものです。
今回は、Blob ストレージ上の CSV ファイルを読み込むために、DelimitedText 形式のデータセットを使っています。
まず、このデータセットに fileName というパラメーターを追加しました。
このパラメーターは、読み込むファイル名をパイプラインから受け取るためのものです。
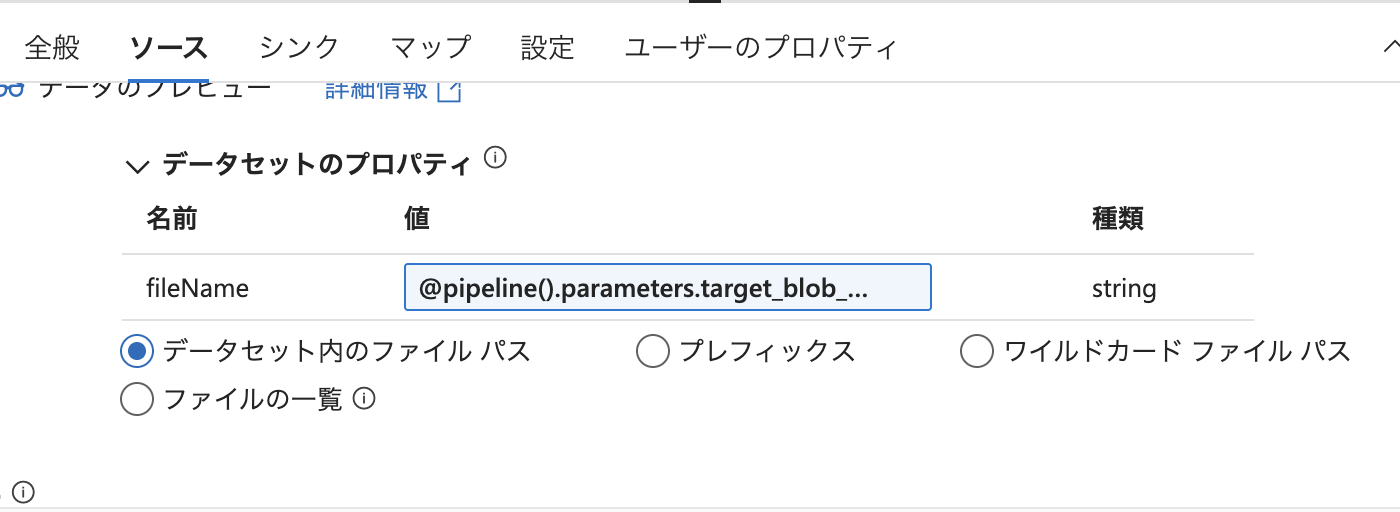
次に、コピーアクティビティの「ソース」タブにて、データセットにパラメーターを渡す設定を行います。
ここでは、データセットで定義した fileName に対して、
パイプラインのパラメーターである target_blob_name を割り当てています。
具体的には、@pipeline().parameters.target_blob_name という式を使用して、
ファイル名の情報をコピーアクティビティ経由でデータセットに引き渡しています。
この設定により、トリガーで検知されたファイル名がそのままデータセットに渡され、
指定された 1 件のファイルだけが読み込みの対象となります。
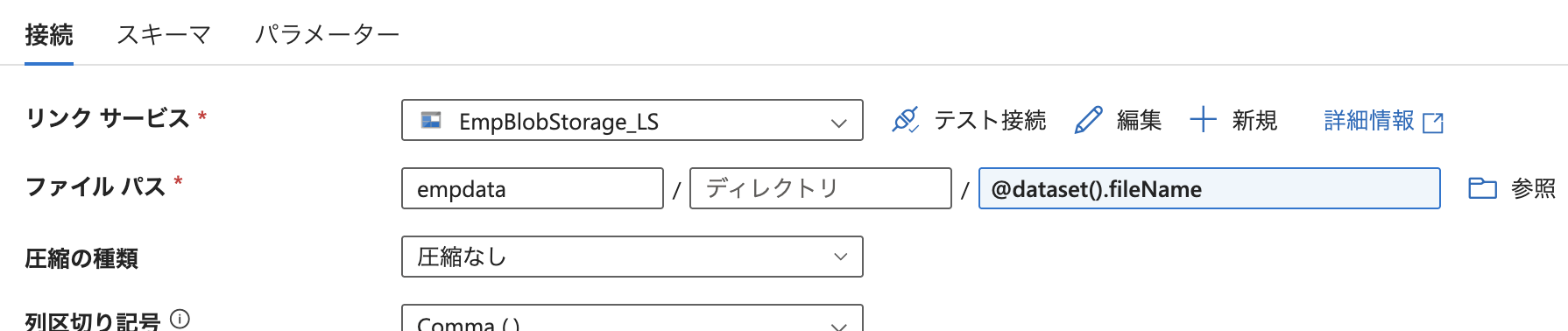
最後に、データセットの「接続」タブにて、ファイルパスを empdata コンテナ配下の
@dataset().fileName に変更しました。
これにより、トリガーから受け取ったファイル名をもとに、対象の CSV ファイルだけを
動的に読み込める構成となりました。
動作確認
構成の検証と発行に問題がないことを確認した上で、実際の動作確認を行いました。
まず、動作確認用として、社員番号「5000」のユーザー(大森俊介)を Entra ID 上に新規作成しました。

次に、Automation ランブックを実行し、Blob ストレージに新しい CSV ファイルが自動生成されたことを確認しました。
そのタイミングで ADF のパイプラインが起動し、対象ファイルが Azure SQL Database に転送される一連の処理が実行されていることも確認できました。
最後に、SQL 側でテーブルの内容を確認したところ、社員番号「5000」の大森俊介が正しく登録されていることを確認できました。
既存データとの重複もなく、トリガーを起点とした 1 ファイル限定の処理構成が想定どおりに機能していることが確認できました。