この記事は NTTテクノクロス Advent Calendar 2022 23日目の記事です。
NTT-TXの定行です。普段はARやVR関連の業務をしたり、たまにデータ解析の業務をしています。
今年もアドベントカレンダーに参加させてもらう事になりました。昨年はUnityで簡単なARアプリの実装手順の記事を書いています。今年はUnityとAWSを連携させたアプリ実装について書いてみようと思います。UnityやAWSを勉強中の人で何かアウトプットをしてみたいと思っている人は是非トライしてみてください。
今回作るアプリはこんな感じです。カメラで撮影した画像をAWSへ送信して画像に移っている物体の解析を行います。そして認識結果ををアプリ上に反映してみようと思います。
今回の構成はAIアプリをとして処理をする流れとしては最適ではなくアプリ上の表示もスムーズではありません。個々の要素を理解するためにとりあえず繋げてみたものになっています。
AWSの構築はすべて”ap-northeast-1”で行っています。

1. Amazon SageMaker Endpointによる物体認識(YOLOv5)
画像上にある物体認識にはYOLOv5を使用しました。YOLOv5の学習済みモデルをAmazon SageMaker EndPointとしてデプロイして外部から呼び出す形になります。構築手順はAWS Service Blogの記事(Amazon SageMaker エンドポイントとAWS Lambdaを使って、YOLOv5の推論をスケールさせる)を参考にしました。
基本的にこの流れを実施すればOpenCVレイヤーが付与されたAWS Lambda関数から推論用のエンドポイント呼び出す事ができます。私自身が構築している最中に詰まった点があるので注意点としていくつか記載します。
1.1 Amazon SageMakerノートブックで実行するカーネル
記事の元になっている英文の方を読んでいるとPytorchが標準で動作するカーネルであれば出来そうに見えたのですが、モデルをデプロイする箇所で失敗しました。私はカーネルに"conda_amazonei_tensorflow2_p36"を選択してPytorchをインストールした後に元の記事の流れを実行する事でEndpointの作成を行いました。
1.2 AWS Lambdaレイヤー追加
AWS Lambda上でOpencCVを使用するためにLayerの追加を行う必要があります。レイヤの作成手順は以下のGitを参考にしています。pyhtonのバージョンを3.7向けに作成しないとLambda実行にライブラリのリンクエラーが発生しました。これに合わせてAWS Lambdaのランタイムも3.7にして関数を作成します。
1.3 AWS Lambdaの設定
メモリと処理時間が標準設定では足りないので以下の2点の設定を変更しました。
-
メモリを512Mに増やす
-
処理時間のタイムアウトを10secに伸ばす
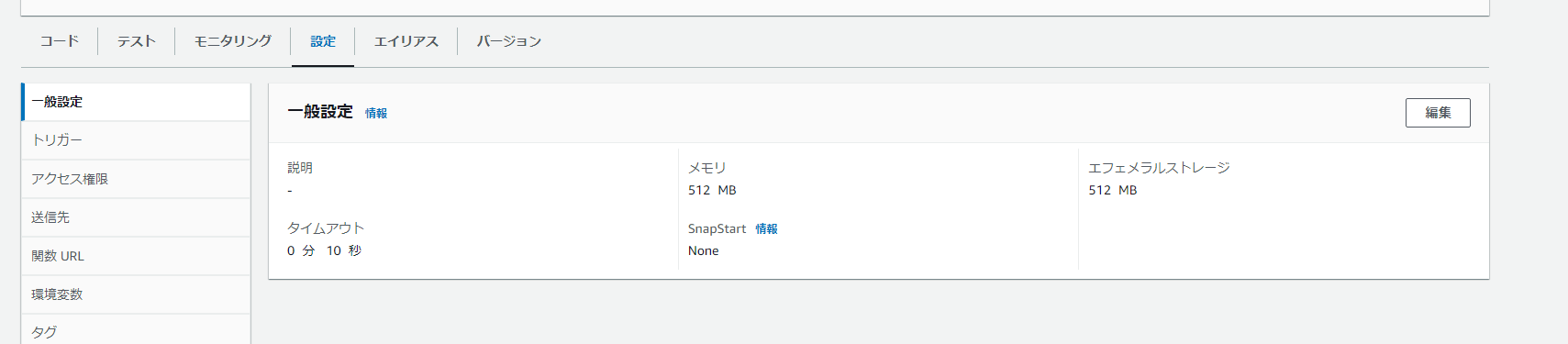
以上の点を気を付けて作業をすればEndPointの作成とAWS Lambdaの実行環境を構築できると思います。
2. AWS Lambda関数実装
次にAmazon Api Gateway経由で呼び出されるAWS Lambdaのコードを実装します。ランタイムは"Python3.7"です。Unityからbase64でエンコードされたpngデータを受け取って、Opencvを使ってYOLOv5が認識できる解像度に変更します。解像度変更したデータをEndpoint経由でYOLOv5の推論モデルに渡します。最後に解析結果をJSONに変換してUnityへ返送します。
import os,json,time,iobase64,uuidboto3,cv2
import numpy as np
#Yolov5で判別できるクラスのリスト
class_names = np.array(['person', 'bicycle', 'car', 'motorcycle', 'airplane', 'bus', 'train', 'truck', 'boat', 'traffic light',
'fire hydrant', 'stop sign', 'parking meter', 'bench', 'bird', 'cat', 'dog', 'horse', 'sheep', 'cow',
'elephant', 'bear', 'zebra', 'giraffe', 'backpack', 'umbrella', 'handbag', 'tie', 'suitcase', 'frisbee',
'skis', 'snowboard', 'sports ball', 'kite', 'baseball bat', 'baseball glove', 'skateboard', 'surfboard',
'tennis racket', 'bottle', 'wine glass', 'cup', 'fork', 'knife', 'spoon', 'bowl', 'banana', 'apple',
'sandwich', 'orange', 'broccoli', 'carrot', 'hot dog', 'pizza', 'donut', 'cake', 'chair', 'couch',
'potted plant', 'bed', 'dining table', 'toilet', 'tv', 'laptop', 'mouse', 'remote', 'keyboard', 'cell phone',
'microwave', 'oven', 'toaster', 'sink', 'refrigerator', 'book', 'clock', 'vase', 'scissors', 'teddy bear',
'hair drier', 'toothbrush'])
def lambda_handler(event, context):
#jsonの設定値を確認
image = json.loads(event.get('body', '{}')).get('image')
if image is None:
return {
'statusCode': 400,
'body': json.dumps("'image' key is not found.")
}
#base64のPngデータをbyte配列に変換
convert_png = base64.b64decode(image.encode("UTF-8"))
#pngのbyte配列をnumpyへ変換
img_buf= np.frombuffer(convert_png, dtype=np.uint8)
#opencvで展開
org_image = cv2.imdecode(img_buf, flags=cv2.IMREAD_COLOR)
# Yolov5エンドポイントへ渡すために解像度を640x640へ変換
modelHeight, modelWidth = 640, 640
yolo_image = cv2.resize(org_image.copy(), (modelWidth, modelHeight), interpolation = cv2.INTER_AREA)
data = np.array(yolo_image.astype(np.float16)/255.)
payload = json.dumps([data.tolist()])
# 推論の実行
ENDPOINT_NAME = 'yolov5l-demo-qita'
runtime = boto3.client('sagemaker-runtime')
start_time_iter = time.time()
response = runtime.invoke_endpoint(EndpointName=ENDPOINT_NAME, ContentType='application/json', Body=payload)
# 結果の取得
result = json.loads(response['Body'].read().decode())
#それぞれのクラスの所属確率が0.3以上の場合だけ抽出
indices = np.where(np.array(result['predictions'][0]['output_1']) > 0.3)
#クラスの所属確率
scores = np.array(result['predictions'][0]['output_1'])[indices]
#クラス名
_classes = np.array(result['predictions'][0]['output_2'],dtype=int)[indices]
classes = class_names[_classes]
#元画像でのバウンディングボックス情報(座標、幅、高さ)
_xywh = np.array(result['predictions'][0]['output_0'])[indices]
xywh = []
for idx,value in enumerate(_xywh):
xywh_str = str(_xywh[idx][0]) + "," + str(_xywh[idx][1]) + "," + str(_xywh[idx][2]) + "," + str(_xywh[idx][2])
xywh.append(xywh_str)
#推論結果をJSONで返信
return {
'statusCode': 200,
"body": json.dumps(
{
"scores":scores.tolist(),
"classes":classes.tolist(),
"position":xywh
})
}
Amazon API Gateway経由呼び出すと以下のようなJSONを返します。結果には"分類したクラスの所属確率","予測したクラスの名前",”バウンディングボックス情報(座標、幅、高さ)”が含まれています。インターネット上にあった猫が映っている画像を推論した結果です。映っている猫は鳥だったようです。。推論結果は撮影物の角度や大きさに影響されるので注意してください。
{
"statusCode": 200,
"body": "{\"scores\": [0.463407546], \"classes\": [\"bird\"], \"position\": [\"0.522866189,0.0956436098,0.815614283,0.815614283\"]}"
}
3. Amazon API Gateway 設定
次に作成したAWS LambdaとAmazon API Gatewayを関連付けます。念のためにAPI-KEYでアクセス制限をかけておきます。UnityアプリからHTTPでアクセスするときにAPI-KEYをヘッダに記載して認証する形になります。
3.1 Amazon API Gateway作成
-
AWS Lambdaの画面で"トリガー追加"をクリック

-
ソースで"API Gateway"を選択
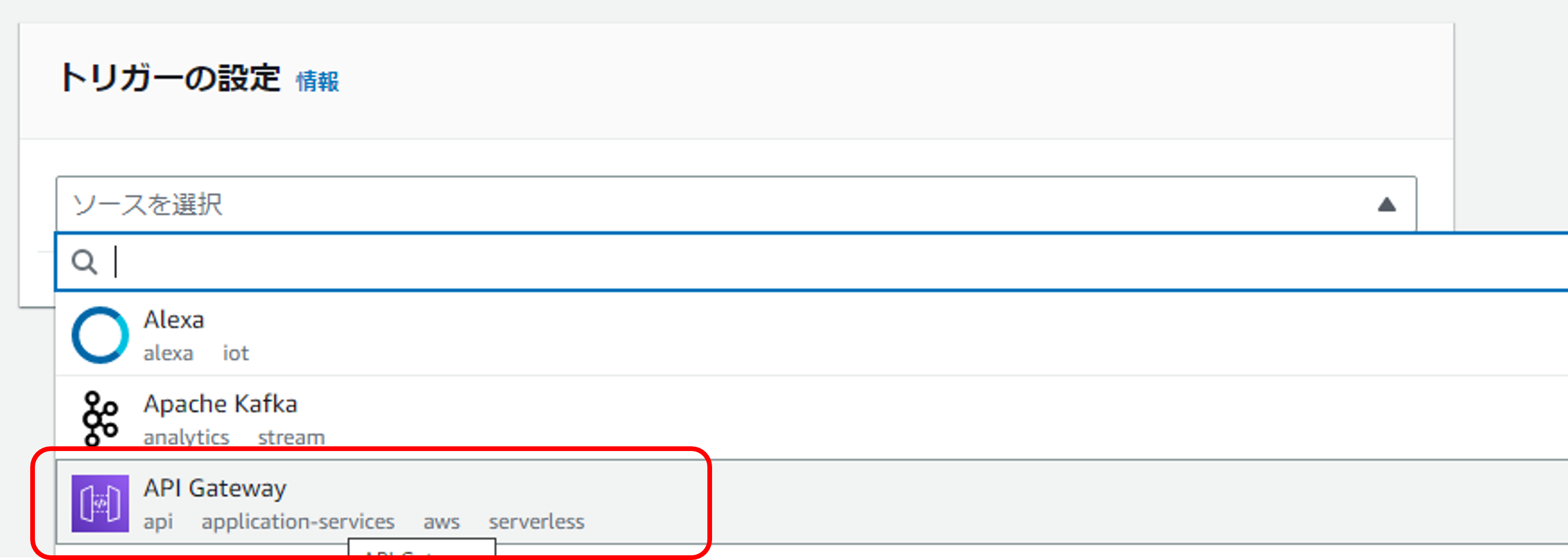
-
"Create a new API" → "REST API"を選択 → Securityで"API-key"を選択

API-KEYに関する詳細は以下を参考にしてください。Amazon API Gatewayを動作させるステージと紐づける形になります。
3.2 疎通確認
ここまで設定できればcurlコマンドで疎通確認ができます。これはUbuntu上でcurlコマンドを使って呼び出した時の結果です。画像データを指定せずに呼び出しただけなので、lambdaがエラーを返してくれます。'x-api-key'と接続先は自身のものに書き換えてください。
$ curl -X POST -H "Content-Type: application/json" -H 'x-api-key:xxxx' -d "{}" https://"url"/dfault/opencv-lambda
"'image' key is not found."
4. Unity側の実装
最後にUnityでのアプリ実装です。実装は"Unity 2020.3.29f"で行い、WindowsとAndroidで動作を確認しました。アプリがやる事はは「カメラ入力をテクスチャ(png)へ変換」と「テクスチャをbase64にエンコードした後にjsonへ格納して送信」です。ほどんとの処理はスクリプトで完結しています。Unity Editor上で作業は「Canvasの配置」,「RawImageの配置」,「スクリプトのアタッチ」の三点です。以下の手順は新規に作成したプロジェクト上で行っています。
-
Canvas配置
"Hierarchy"で右クリック→ "UI" → "Canvas"の順にしてscene上にCanvasを追加。

Canvasの"Inspector"で"Render Mode"に「Screen Space Camera」,"Render Camera"に「Main Camera(Camera)」を選択してください。この設定でアプリ実行時にCanvasがカメラ全体に表示されるように自動調整されます。

-
RawImage配置
"Hierarchy"でCanvasを右クリック→ "UI" → "Raw Image"の順にしてCanvasの配下にRawImageを配置。このRawImageにカメラ入力を表示させます。配置しただけだとサイズが小さく見えますが、サイズはスクリプトで調整します。
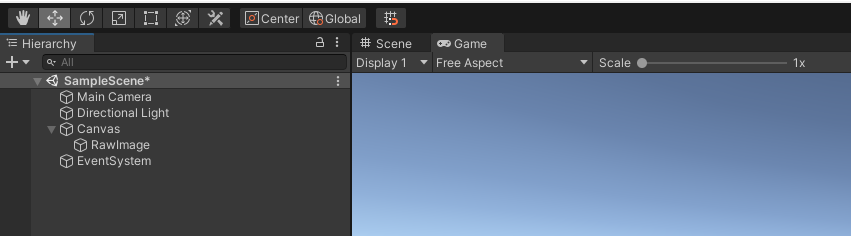
-
スクリプトのアタッチ
以下のコードを"Canvas"の"Inspector"にアタッチします。処理の説明はコメントを参考にしてください。あとは動かすだけです。
using System.Collections;
using UnityEngine;
using UnityEngine.Networking;
using UnityEngine.UI;
public class CameraInput : MonoBehaviour
{
[System.Serializable]
public class UploadJsonImage
{
public string timestamp;
public string image;
}
WebCamTexture webcamTexture;
public RawImage rawImage;
float elapsedTime = 8.0f;
public Text label_text;
//Amazon API Gatewayを呼び出すURL
private readonly string upload_url = "https://xxx.execute-api.ap-northeast-1.amazonaws.com/default/opencv-lambda";
//RawImageをTexture2Dへ変換
Texture2D ConvertRatImagetoTexture2D(RawImage image)
{
var tex = image.texture;
int width = tex.width;
int height = tex.height;
Texture2D result = new Texture2D(width, height, TextureFormat.RGBA32, false);
var currentRT = RenderTexture.active;
RenderTexture rt = new RenderTexture(width, height, 32);
//RawImageのTextureをRenderTextureにコピー
Graphics.Blit(tex, rt);
RenderTexture.active = rt;
// RenderTextureのピクセル情報をTexture2Dにコピー
result.ReadPixels(new Rect(0, 0, rt.width, rt.height), 0, 0);
result.Apply();
RenderTexture.active = currentRT;
return result;
}
//カメラから取得したPNGデータをbase64エンコードして
//jsonへ格納
string MakePngJson()
{
//Webカメラのテクスチャをbyte配列に変換
Texture2D camTexture = ConvertRatImagetoTexture2D(this.rawImage);
byte[] bytes = camTexture.EncodeToPNG();
//BASE64への変換
string encodedText = System.Convert.ToBase64String(bytes);
//AWSへ送信するためにJsonへ変換
UploadJsonImage json = new UploadJsonImage
{
timestamp = Time.deltaTime.ToString(),
image = encodedText
};
return JsonUtility.ToJson(json);
}
//PNGデータが格納されたJsonをAmazon API Gatewayへ送信
//結果として推論結果が格納されたjsonを受信
IEnumerator UploadPngJson(string url)
{
string png_json = MakePngJson();
byte[] postData = System.Text.Encoding.UTF8.GetBytes(png_json);
var request = new UnityWebRequest(url, "POST");
request.uploadHandler = (UploadHandler)new UploadHandlerRaw(postData);
request.downloadHandler = (DownloadHandler)new DownloadHandlerBuffer();
request.SetRequestHeader("Content-Type", "application/json");
//設定したAPI-KEYの文字列をヘッダに記載
request.SetRequestHeader("x-api-key", "xxxx");
yield return request.SendWebRequest();
Debug.Log(request.downloadHandler.text);
string txt = request.downloadHandler.text;
txt = txt.Replace("\r\n", "").Replace("\n", "");
}
//Rawイメージのコンポーネントを取得してカメラから出力されるテクスチャーを割り当てる
void Start()
{
this.rawImage = GetComponentInChildren<RawImage>();
WebCamDevice[] devices = WebCamTexture.devices;
webcamTexture = new WebCamTexture(devices[0].name, 1280, 640, 30);
this.rawImage.texture = webcamTexture;
this.rawImage.enabled = true;
Debug.Log(webcamTexture);
webcamTexture.Play();
}
// Update is called once per frame
void Update()
{
//CanvasのサイズにRawImageのサイズを合わせる
RectTransform canvas_rect = this.GetComponent<RectTransform>();
Vector2 v1 = canvas_rect.sizeDelta;
rawImage.rectTransform.sizeDelta = v1;
//10secに一回Amazon API Gatewayへ送信、ボタン駆動にしようがいいかも
elapsedTime += Time.deltaTime;
if (elapsedTime >= 10.0)
{
Debug.Log("計測中: " + (elapsedTime).ToString());
StartCoroutine(UploadPngJson(upload_url));
elapsedTime = 0.0f;
}
}
}

5. 結果
バウンディングボックスで位置を重畳するところまで到達できなかったので、画面上に推論結果の重畳してます。ペットボトルの大体の位置が特定できています。サンドウィッチがうまく認識できませんでした。ここには載せていませんが人、車、椅子といったものが認識できているのを確認しました。

Unityを使ってAmazon API Gateway+AWS Lambda+Amazon SageMakerエンドポイントを呼び出して、推論結果を画面に反映してみました。繰り返しになりますが今回の試みはアプリから推論エンジンを呼び出す構成としては最適ではないと思います。
UnityやAWS(Amazon API Gateway,AWS Lambda,Amazon SageMaker)を勉強中の方は個々の要素に確認のためにトライしてみれば理解が深まると思います。
明日はアドベンドカレンダー最終日です。@horietakehiroが CloudFormationテンプレートファイルからパラメータシートを自動生成するツールの紹介について投稿します。最終日もNTT-TXのアドベンドカレンダーをお楽しみください。