今回は、Red Hat OpenShift on IBM Cloud (ROKS)を構築した上で、OpenShift AIをアドオンでインストールしてみた際の手順を記載する。
OpenShift AIを構築した後に、KServeがインストールされていて、Single-model servingが有効であることを確認した上で、LLMが正常に起動するかどうかを検証した。
手順の流れ
- OpenShift AI構築
- ROKS構築
- OpenShift AIアドオンインストール
- 検証
- インストール済みOperator確認
- KServeインストール確認
- Single-model serving有効確認
- LLM起動確認
【構成図】
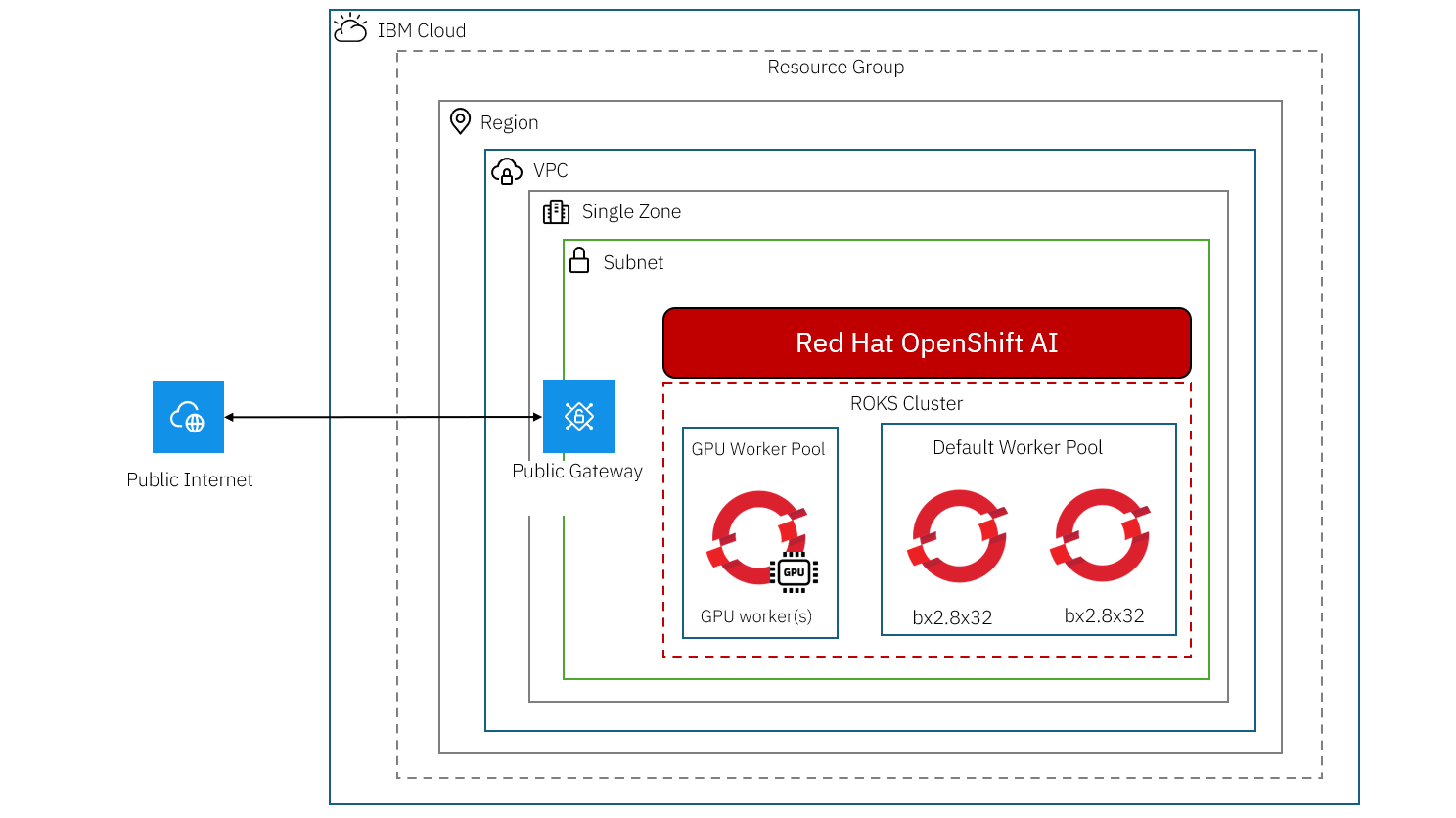
前提条件
- VPC(リソース名:
rhoai-vpc)作成済み。 - Cloud Object Storage(リソース名:
sd-openshiftai-llm)作成済み。
最小要件
IBM Cloud Docsには、要件として以下が記載されている。以下の点に気を付けて、ROKSを構築する。
クラスタのバージョンは 4.16 または 4.17 でなければなりません。
クラスタには少なくとも2つのワーカーノードが必要です。 各ワーカーノードには、最低でも 8vCPU と 32GB メモリが必要です。
ワーカーノードはRHCOSオペレーティングシステムを使用する必要があります。
必要なオペレータをインストールするには、クラスタからの送信トラフィックを許可する必要があります。
OpenShift AI構築
ROKS構築
以下の通り設定したROKSを構築する。
- オーケストレーター
- Red Hat OpenShift
- インフラストラクチャー
- VPC
- 仮想プライベートクラウド
-
rhoai-vpc(作成済み)
-
- ロケーション
- us-south-2(ダラス)
- OpenShiftのバージョン
- 4.17.35(デフォルト)
- OpenShift Container Platform (OCP) ライセンス
- OCP資格を適用する
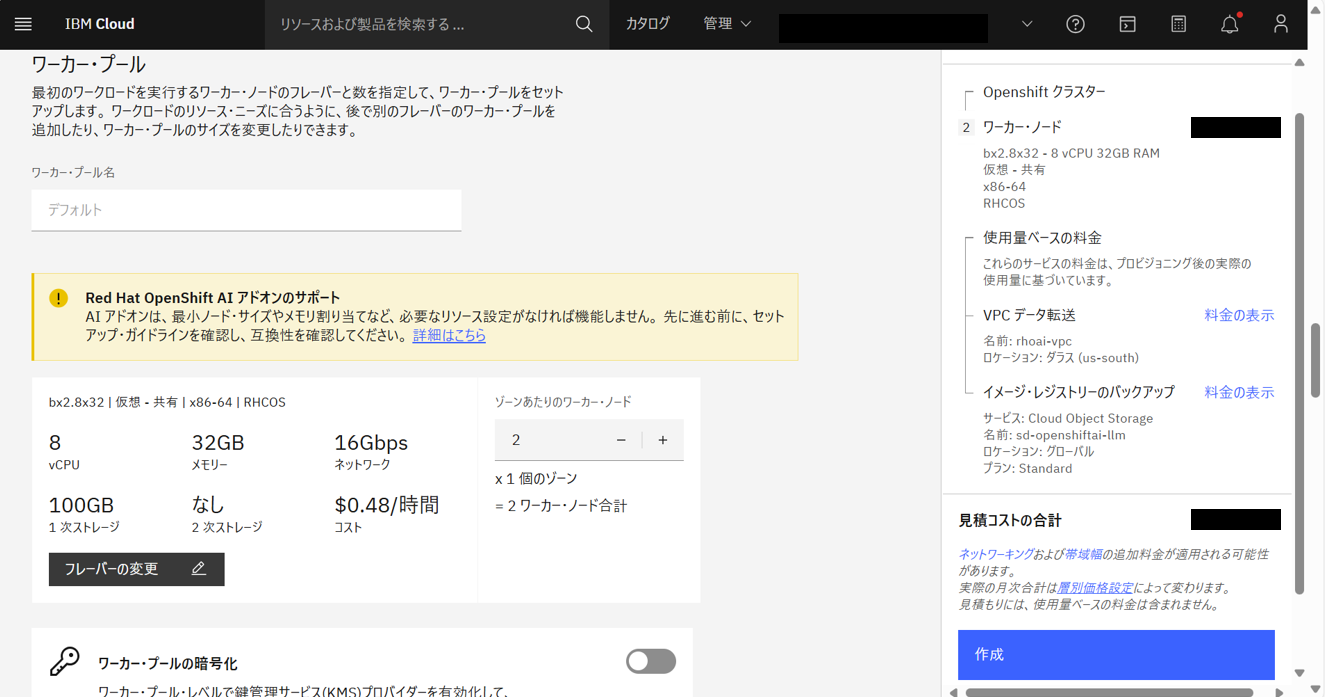
- ワーカープール
- ワーカーノード合計3台
- ワーカープール名:
default- ワーカーノード数:2
- フレーバー:bx2.8x32、RHCOS
- 2次ストレージ:なし
- ワーカープール名:
GPU- ワーカーノード数:1
- フレーバー:gx3.16x80.l4、RHCOS
- 2次ストレージ:300GB(300gb.5iops-tier)
- ワーカープール名:
- ワーカープールの暗号化:無効化
- ワーカーノード合計3台
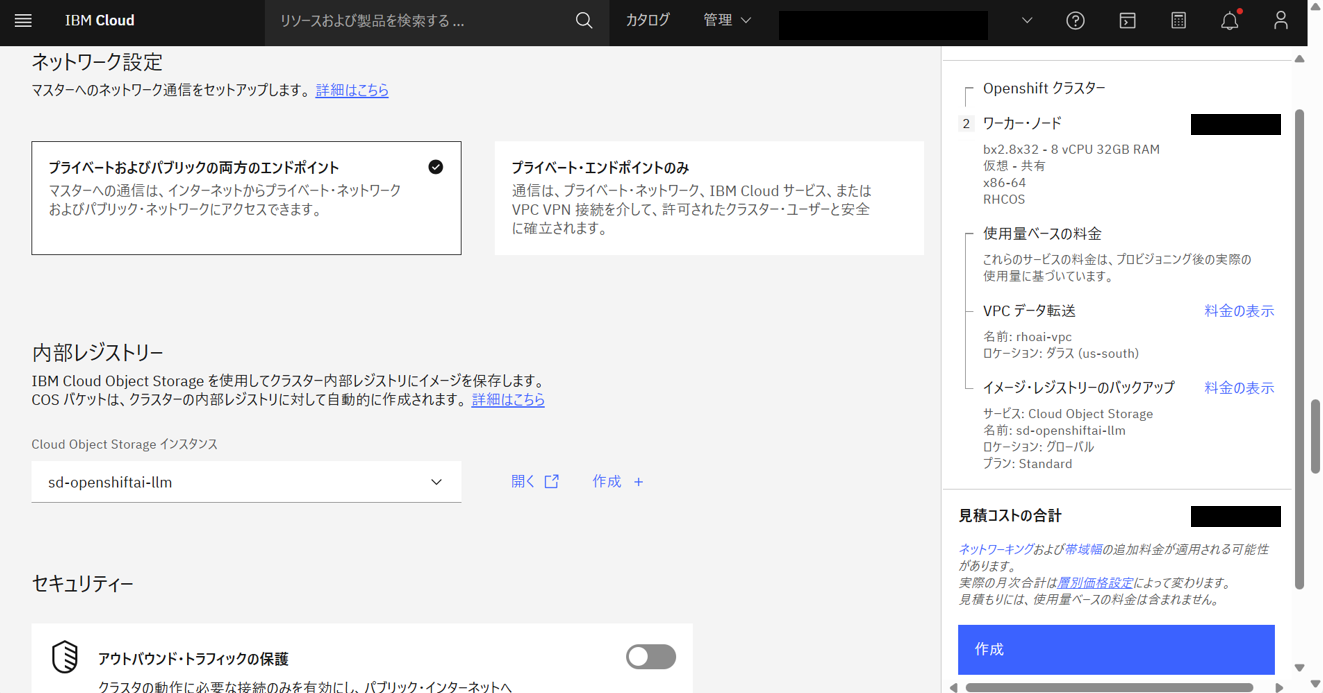
- ネットワーク設定
- プライベートおよびパブリックの両方のエンドポイント
- 内部レジストリ
-
sd-openshiftai-llm(作成済み)
-
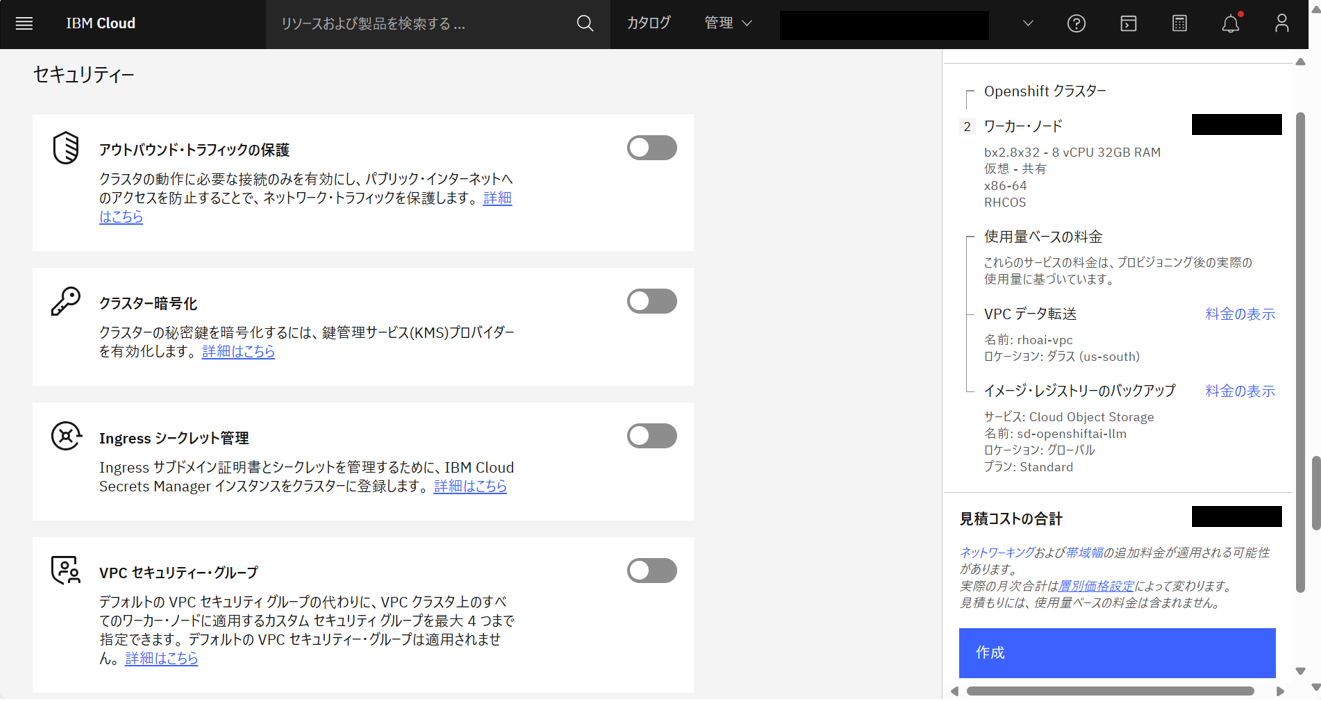
- セキュリティー
- 全て無効化
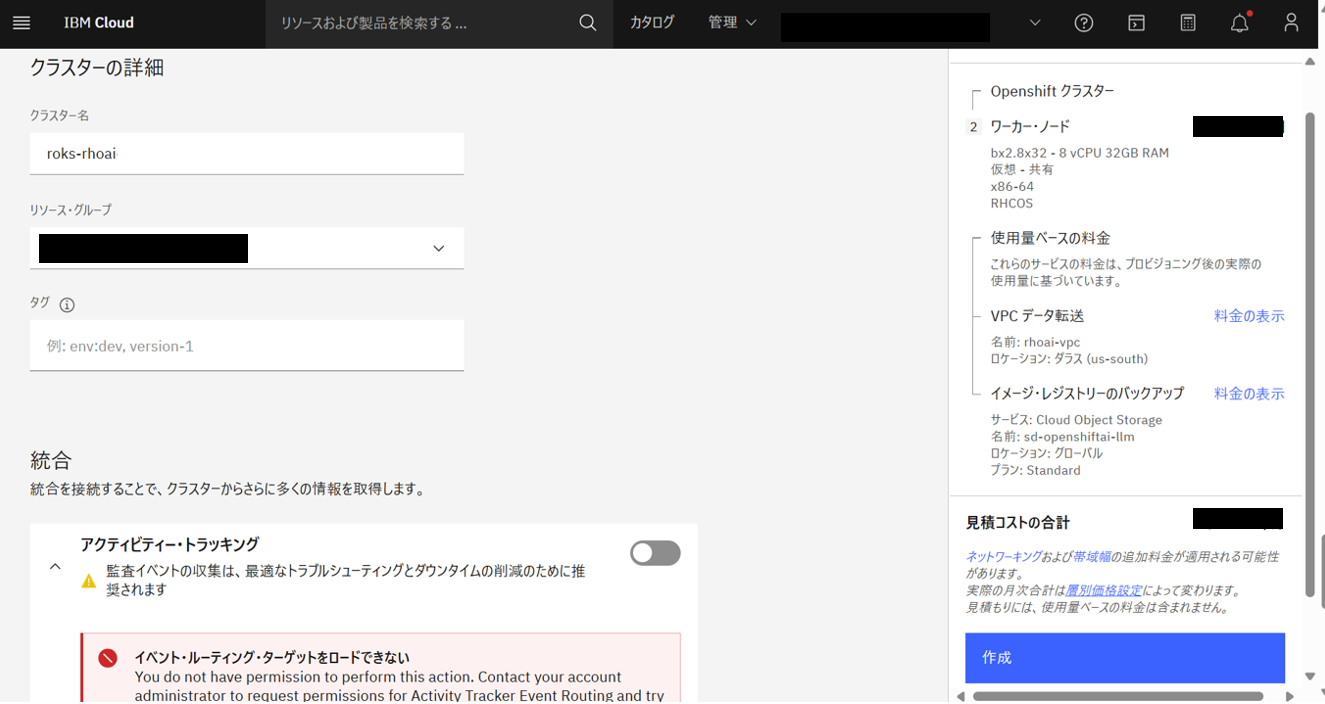
- クラスターの詳細
- クラスター名:
roks-rhoai
- クラスター名:
- 統合
- 全て無効化
注記
ワーカープールのうちGPUは、ROKS作成後に追加する。
重要
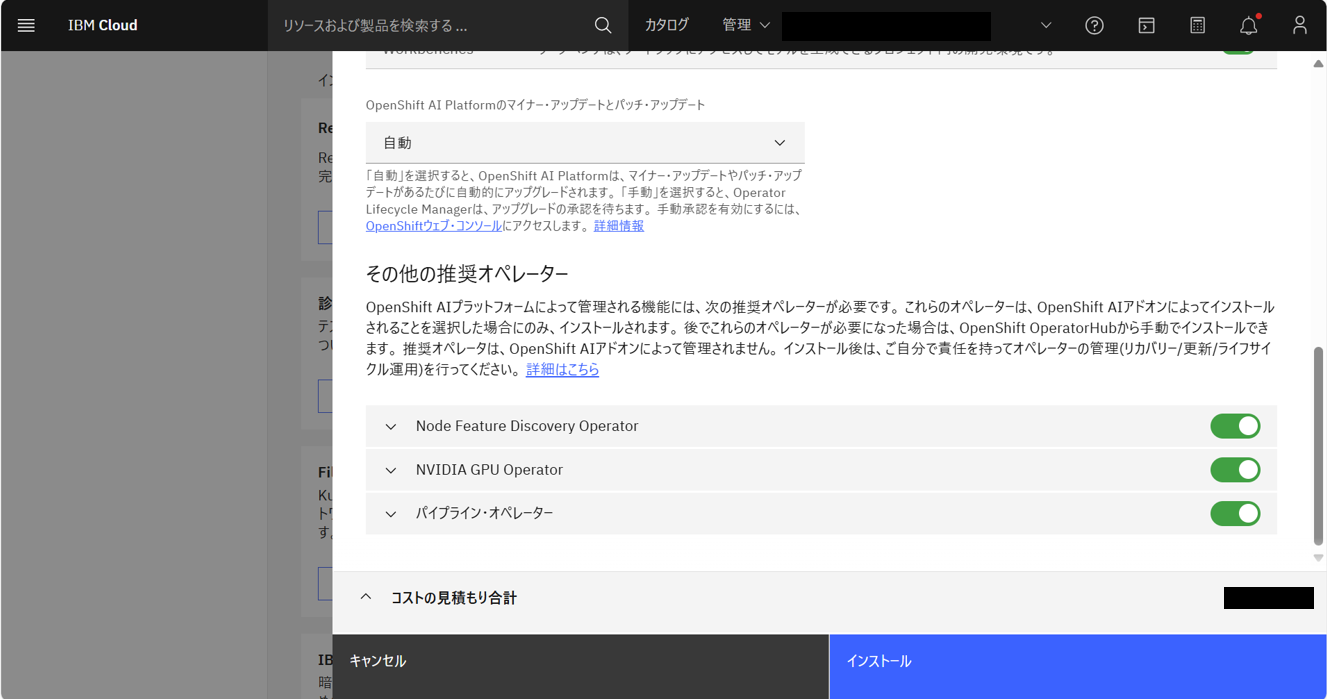
以下の三つの推奨オペレーターをアドオンインストールに含めるためには、セキュリティーのうち「アウトバウンド・トラフィックの保護」を無効にする必要がある。
- Red Hat OpenShift Pipelines
- Node Feature Discovery Operator
- NVIDIA GPU Operator
IBM Cloudコンソール画面の上部の検索バーで、「Red Hat OpenShift on IBM Cloud」と入力して検索し、上記の通りに設定し(GPUワーカープールを除く)、「作成」をクリックする。

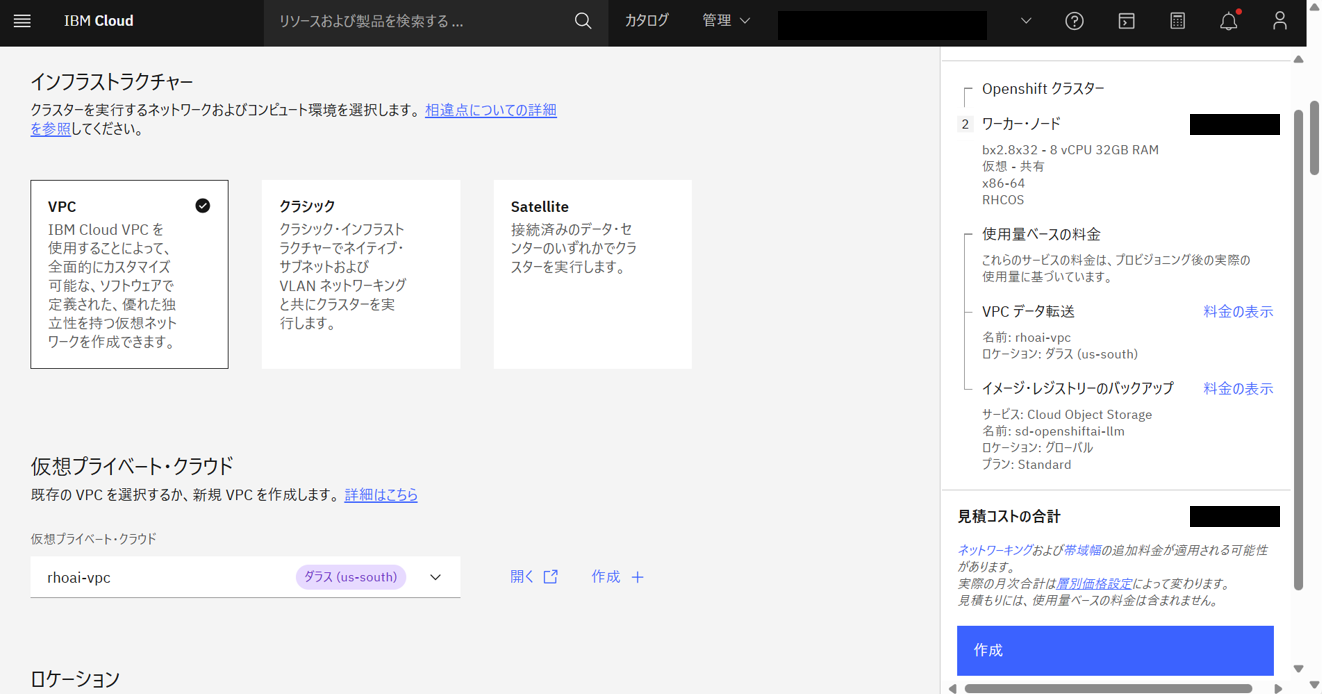
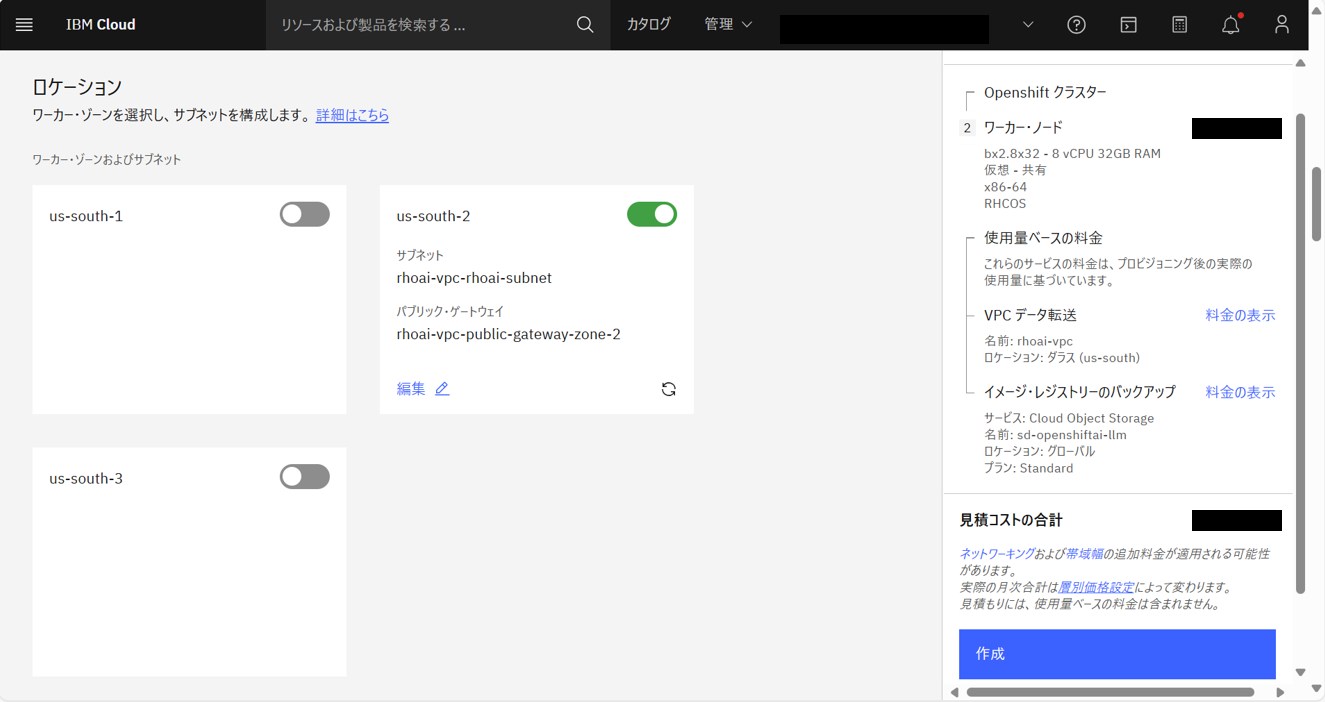
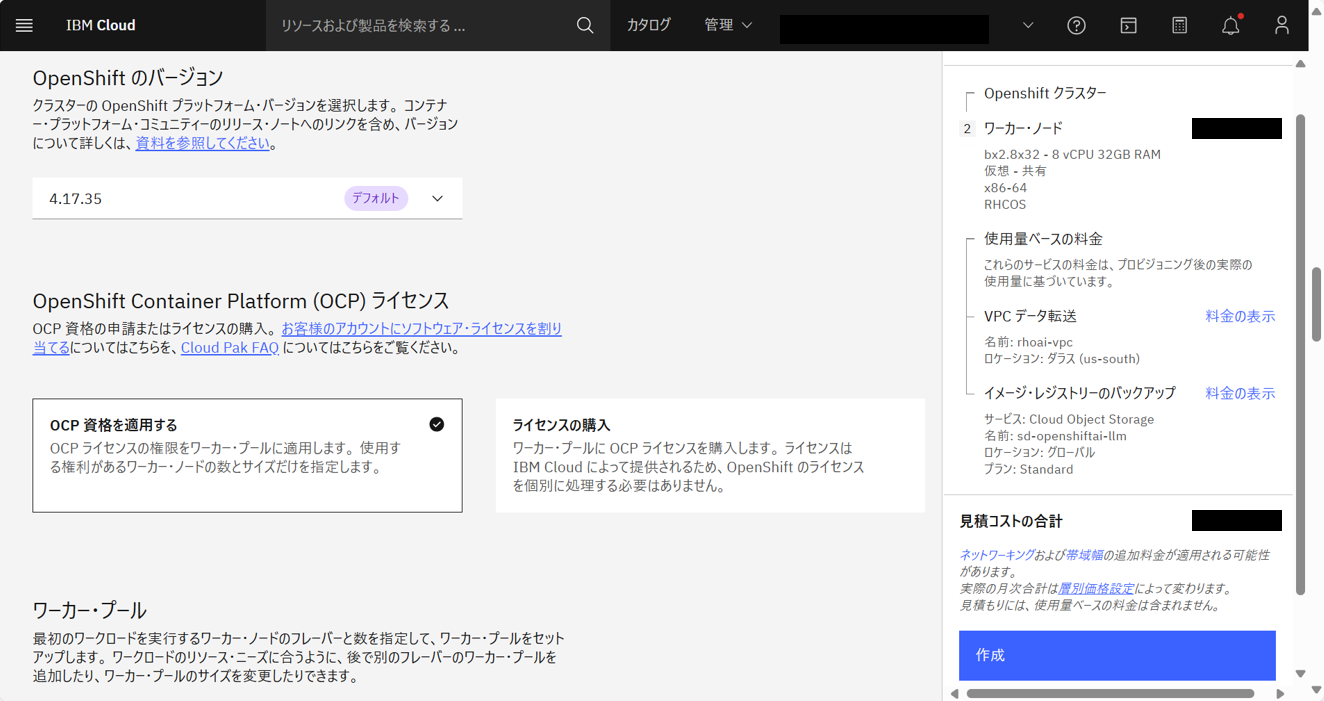
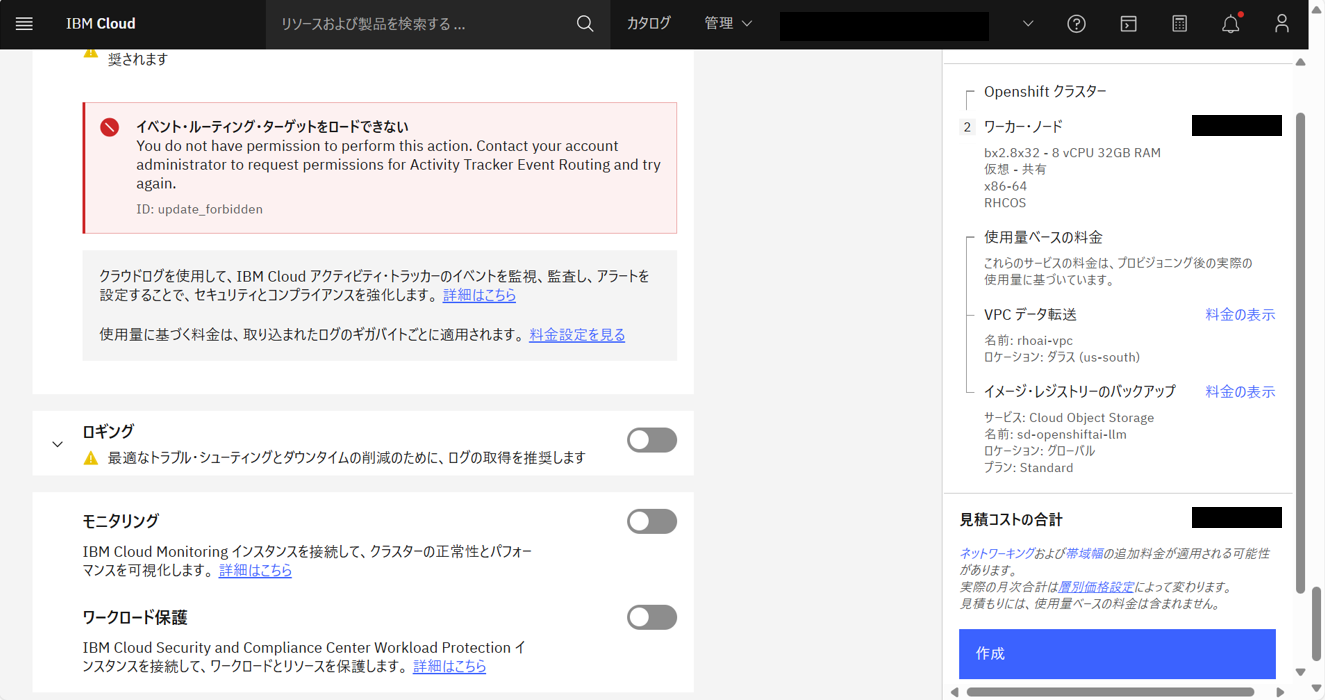
クラスターの作成が開始される。
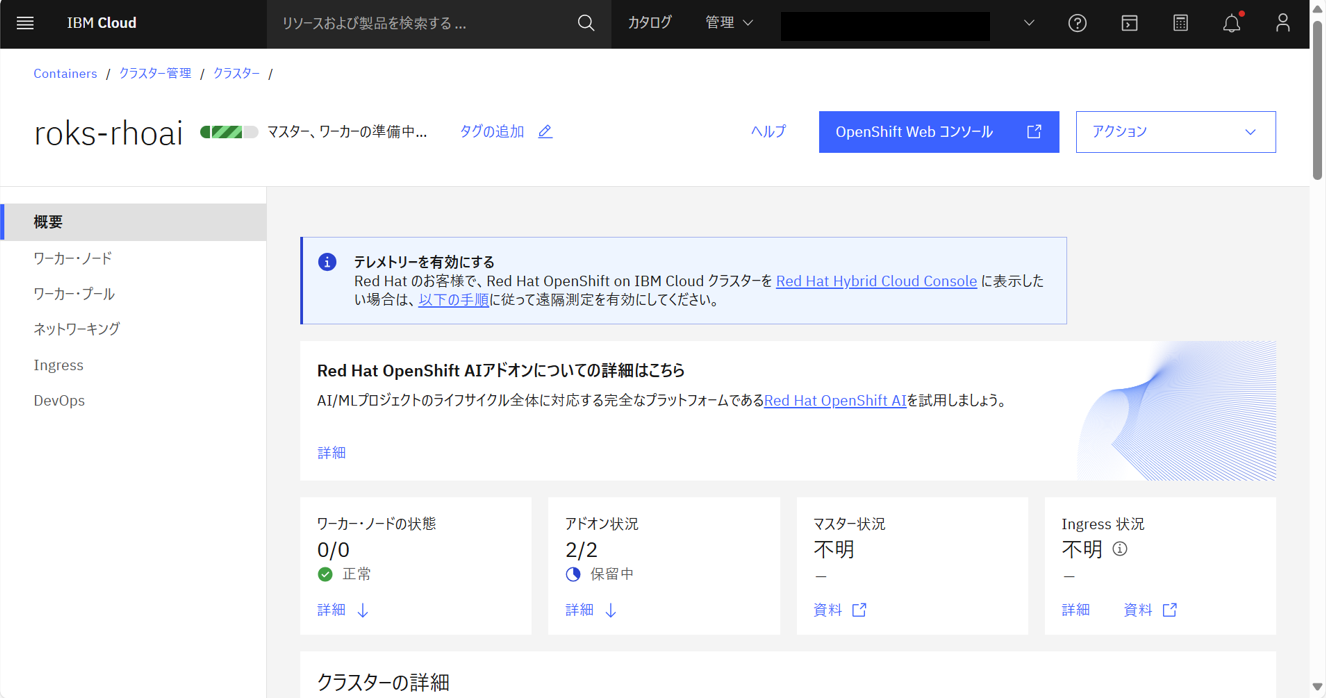
クラスターの状態が標準になる。
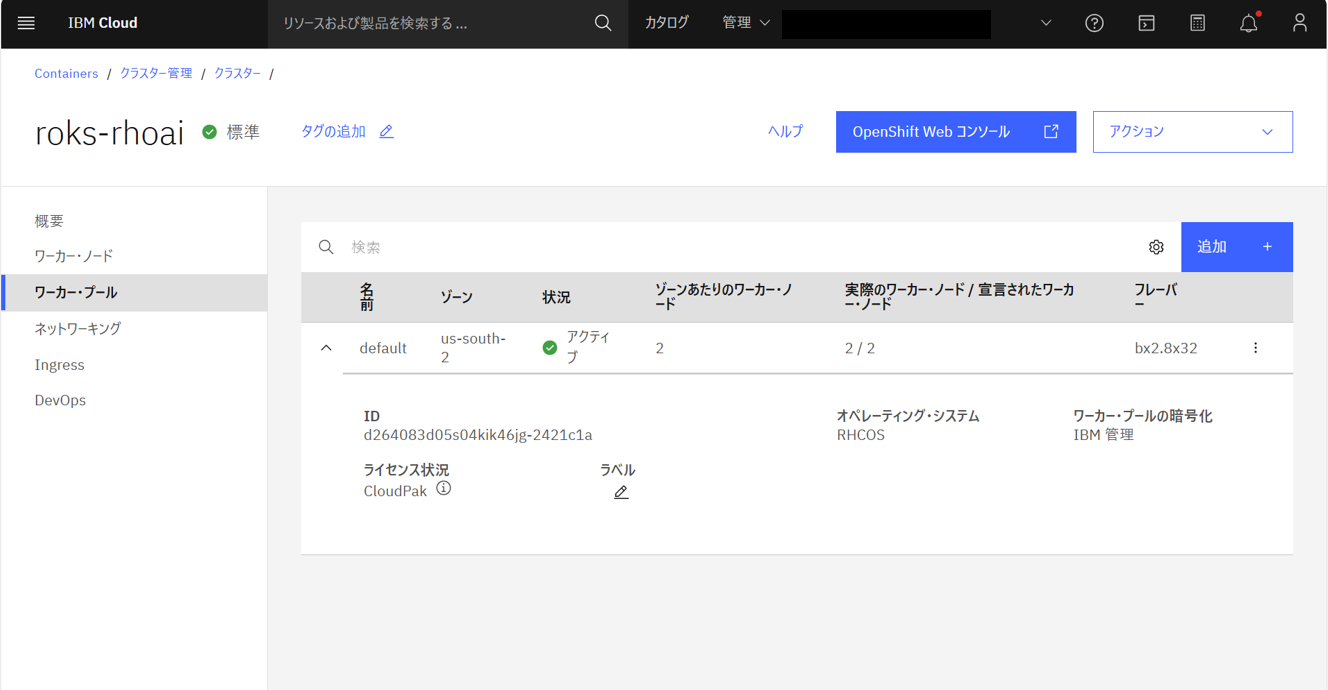
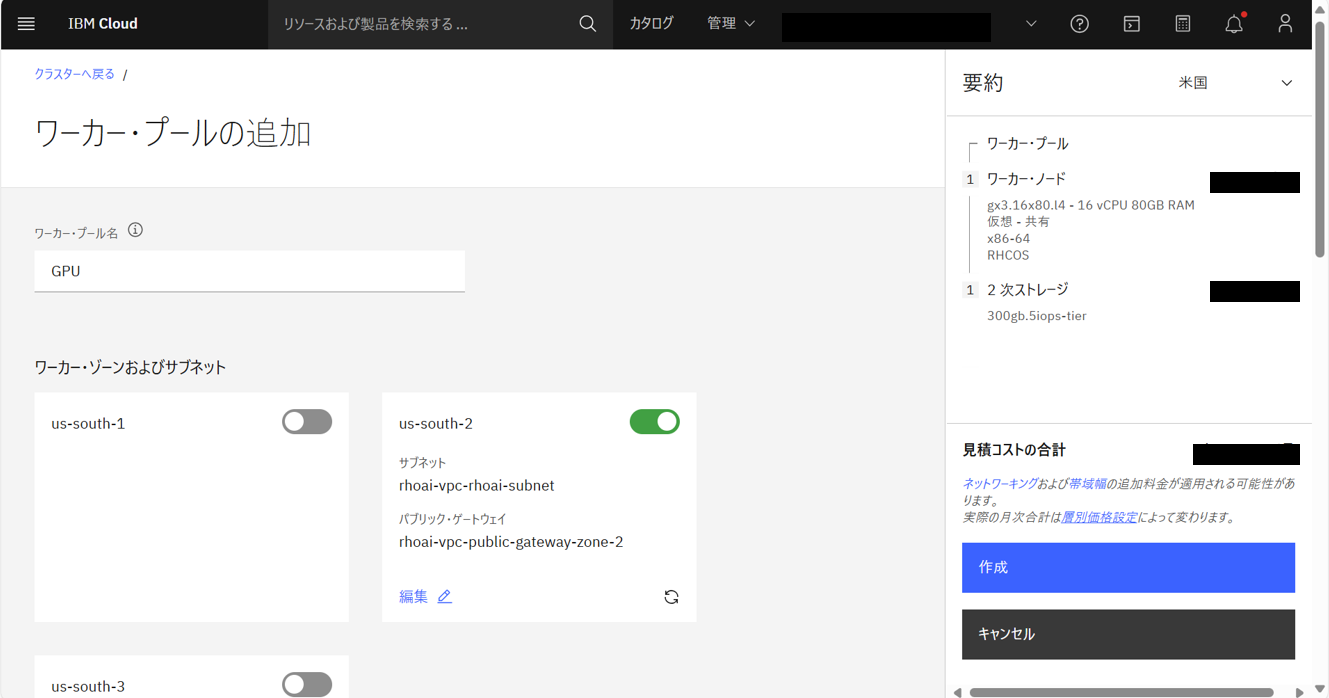
左メニューバーで「ワーカー・プール」を選択し、設定通りにdefaultワーカープールが作成されていることを確認する。追加でGPUワーカープールを作成する必要があるため、右上の「追加」をクリックする。
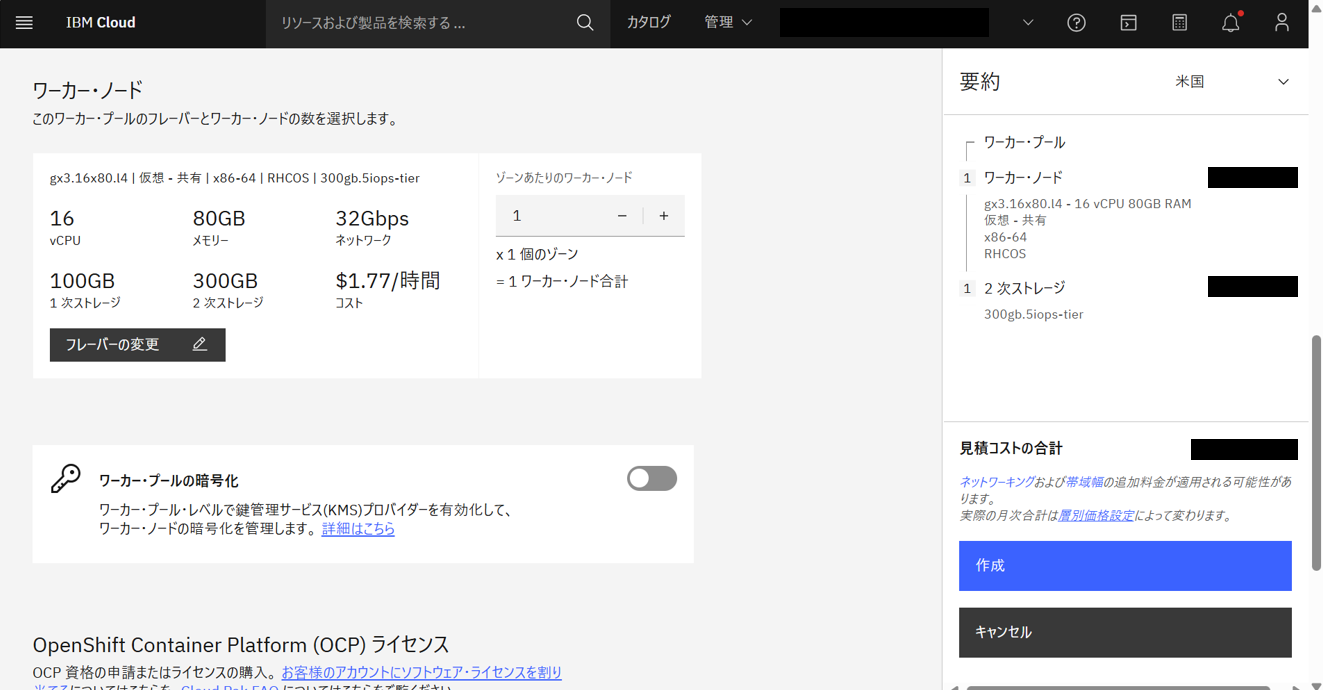
以下の通り設定して、「作成」をクリックする。
- ワーカープール名:
GPU- ワーカーノード数:1
- フレーバー:gx3.16x80.l4、RHCOS
- 2次ストレージ:300GB(300gb.5iops-tier)
GPUワーカープールが作成され、合計3つのワーカーノードになっていることが確認できる。
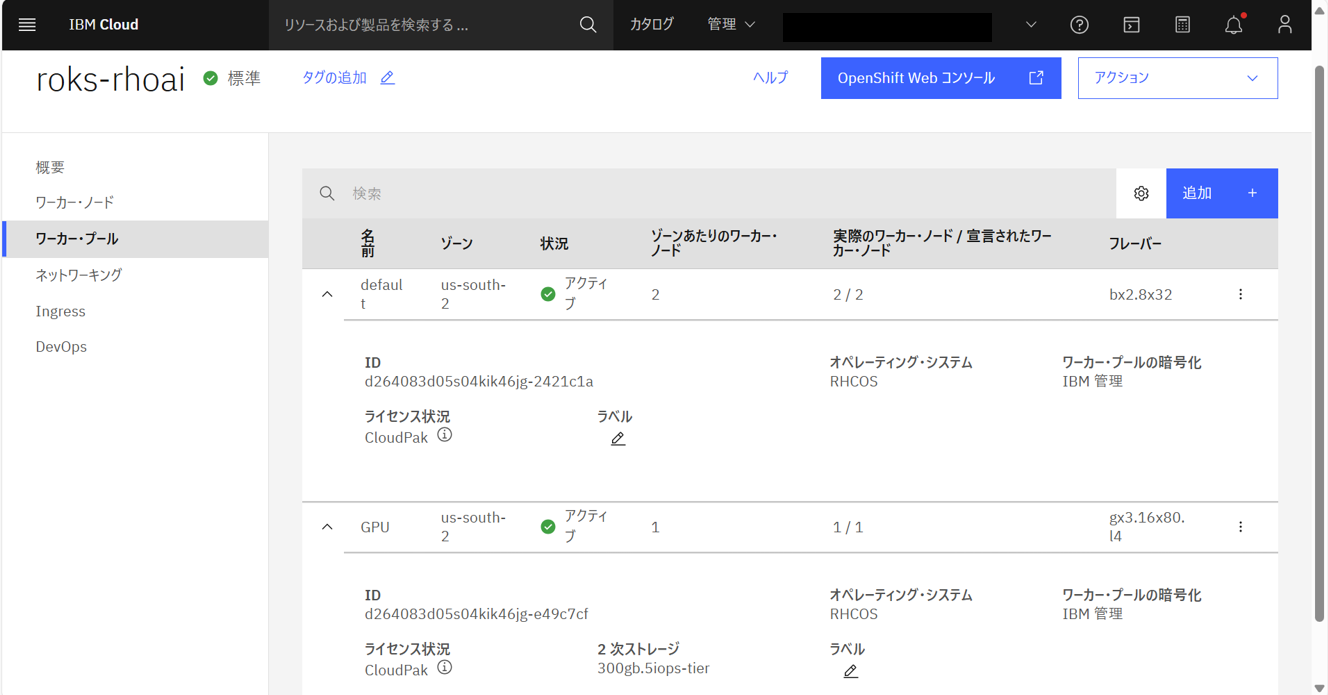
これで、ROKSの準備は完了。
OpenShift AIアドオンインストール
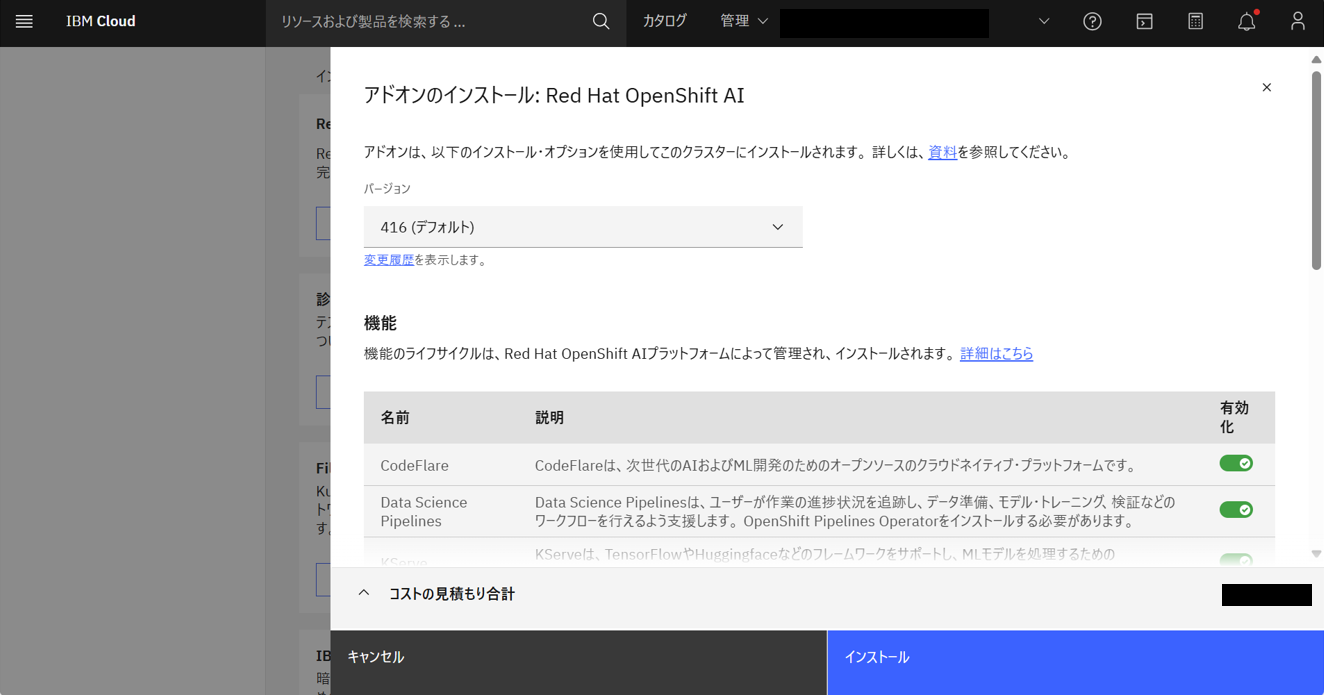
クラスターの「概要」画面を下にスクロールして、アドオンのインストール可能欄にあるRed Hat OpenShift AIの「インストール」をクリックする。
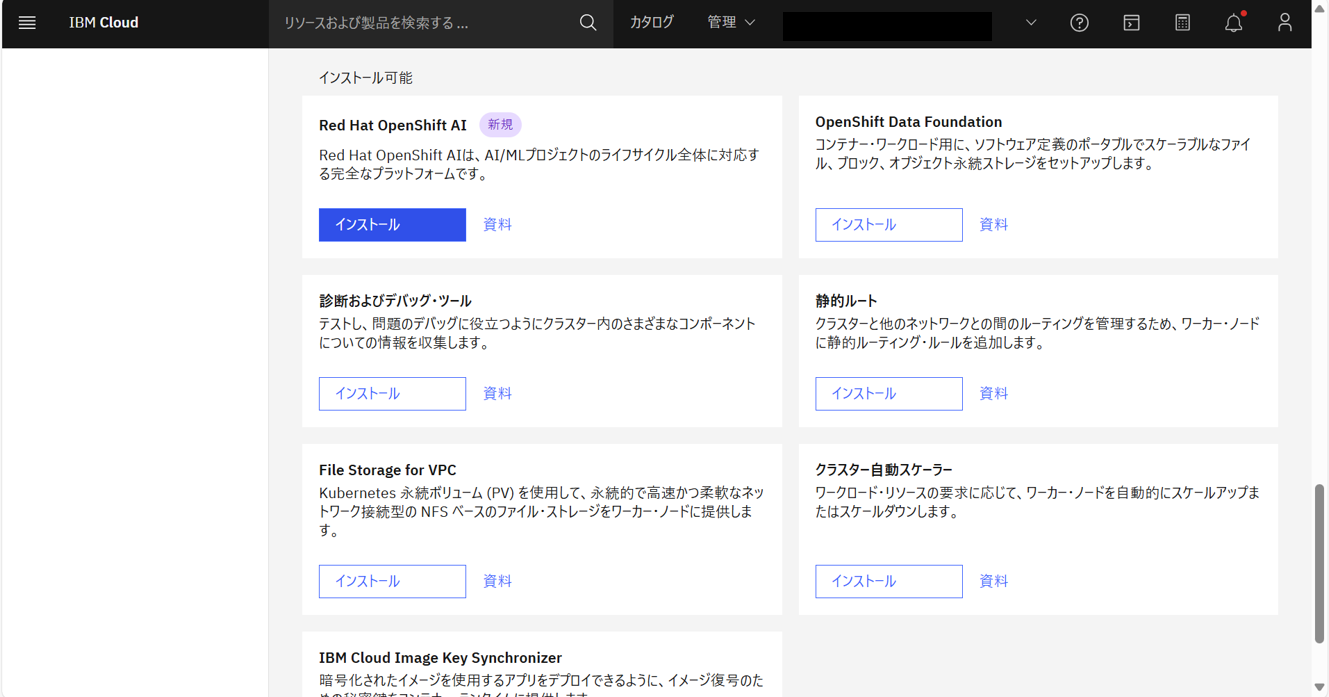
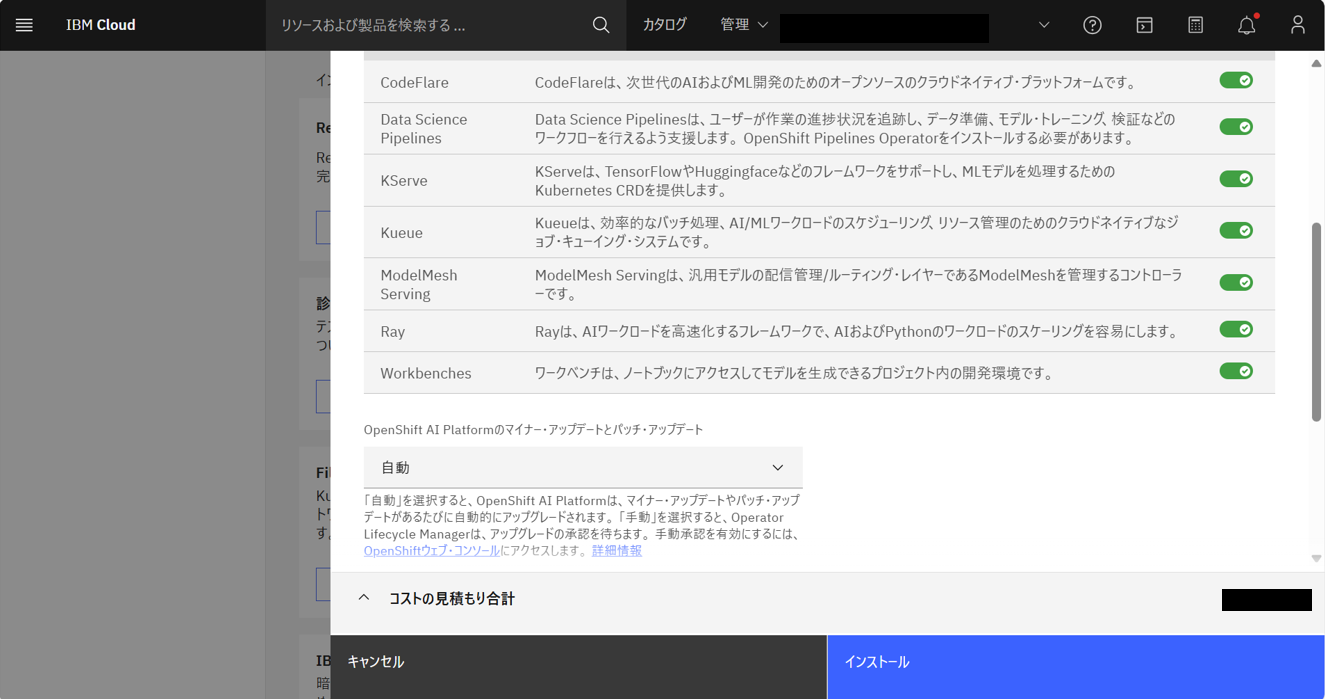
機能と推奨オペレーターはすべて「有効化」にして、「インストール」をクリックする。(ここで、KServeも有効化になっていることを確認)
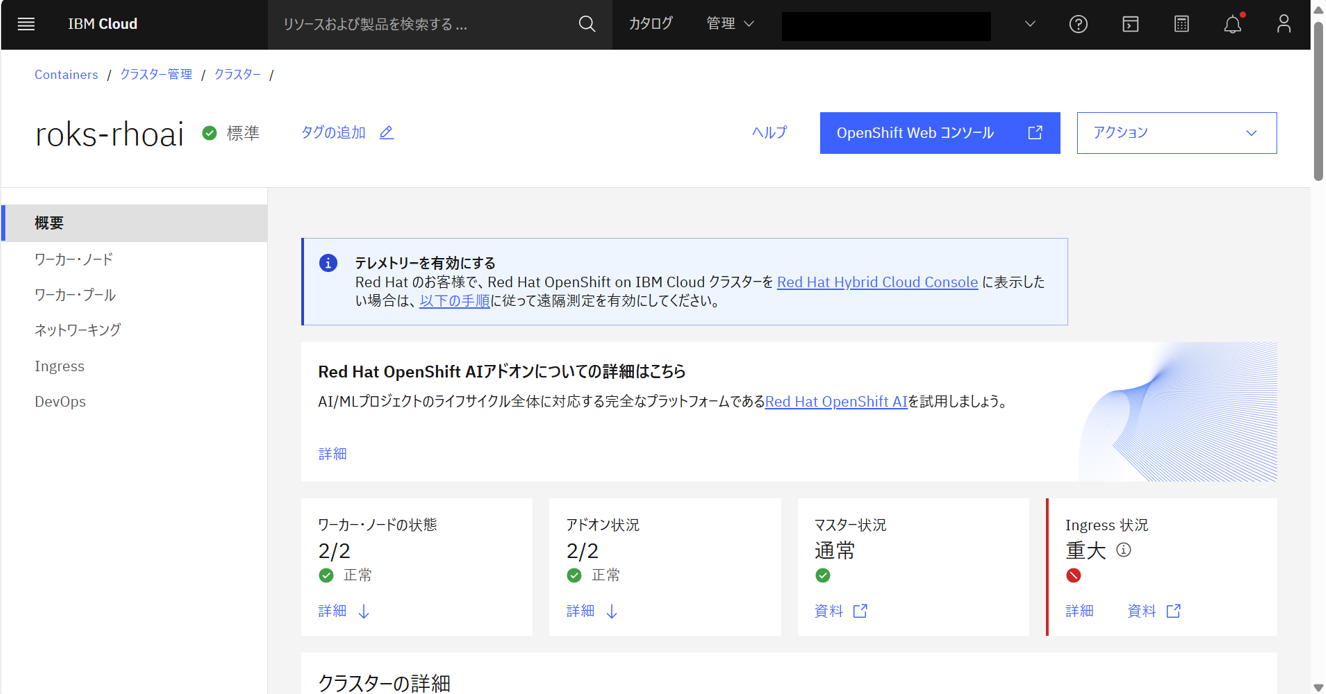
Red Hat OpenShift AIは有効化中になる。
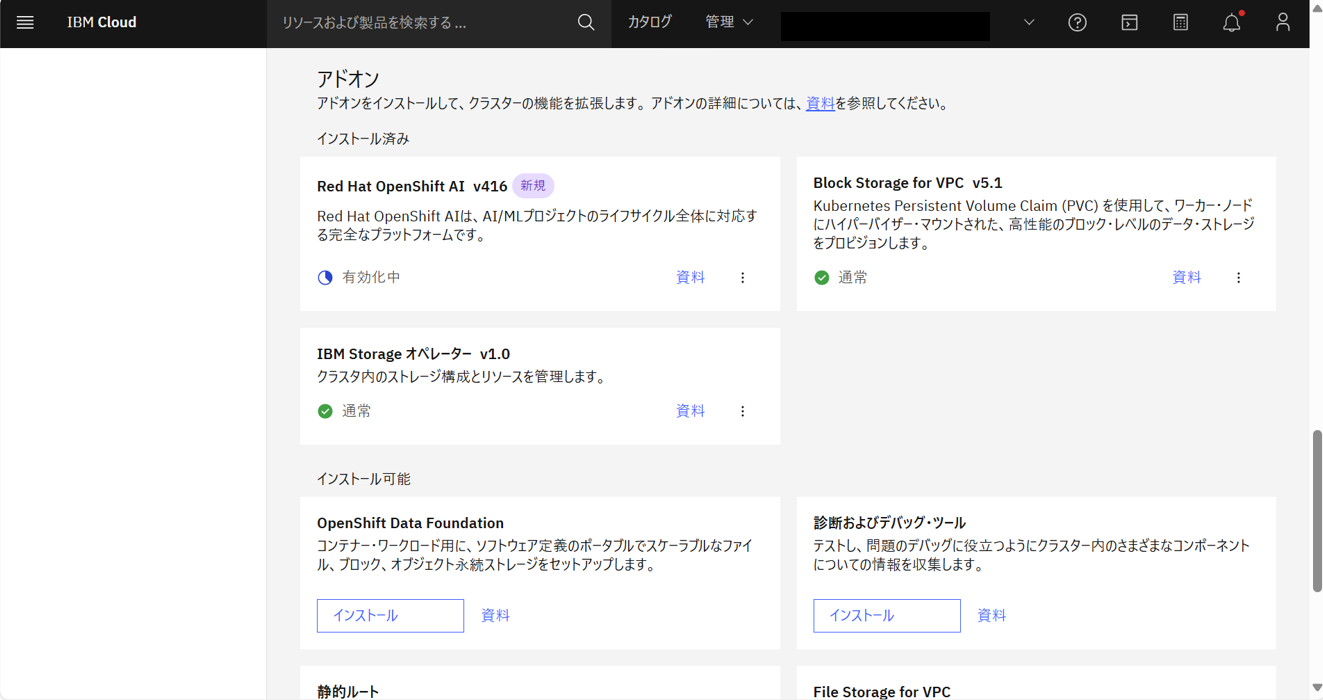
しばらくすると、通常になる。

検証
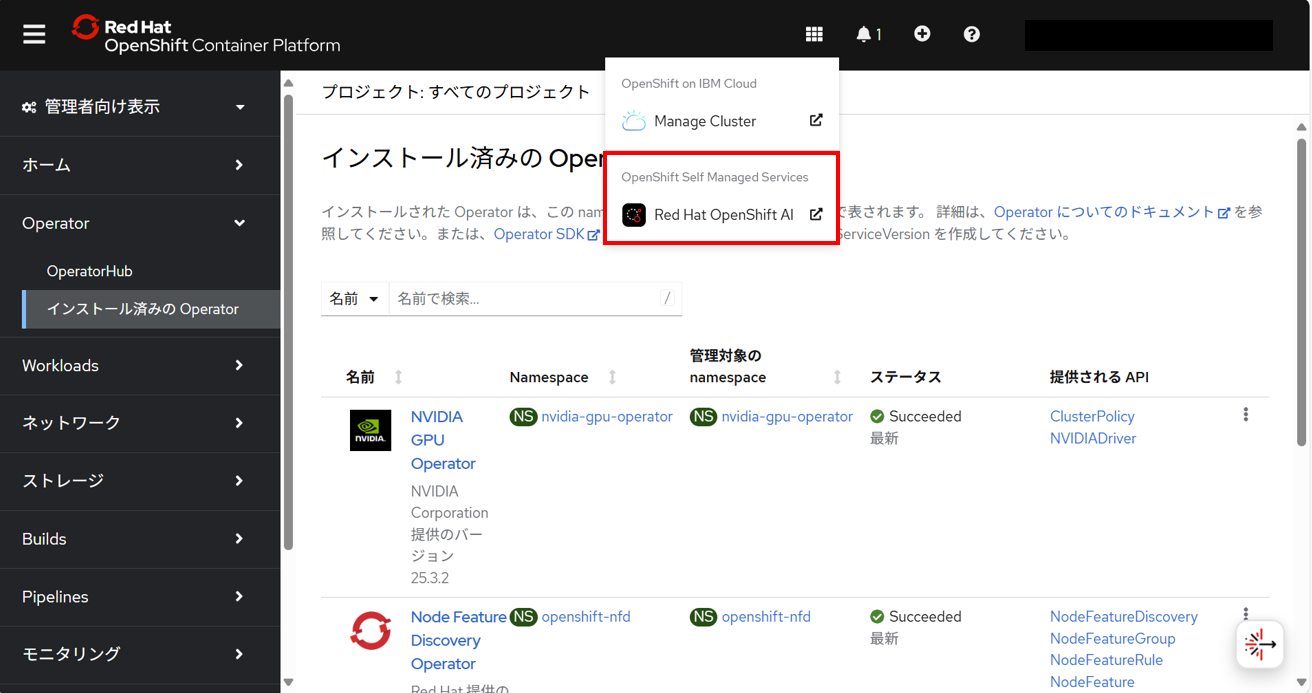
インストール済みOperator確認
OpenShift Webコンソールを開く。
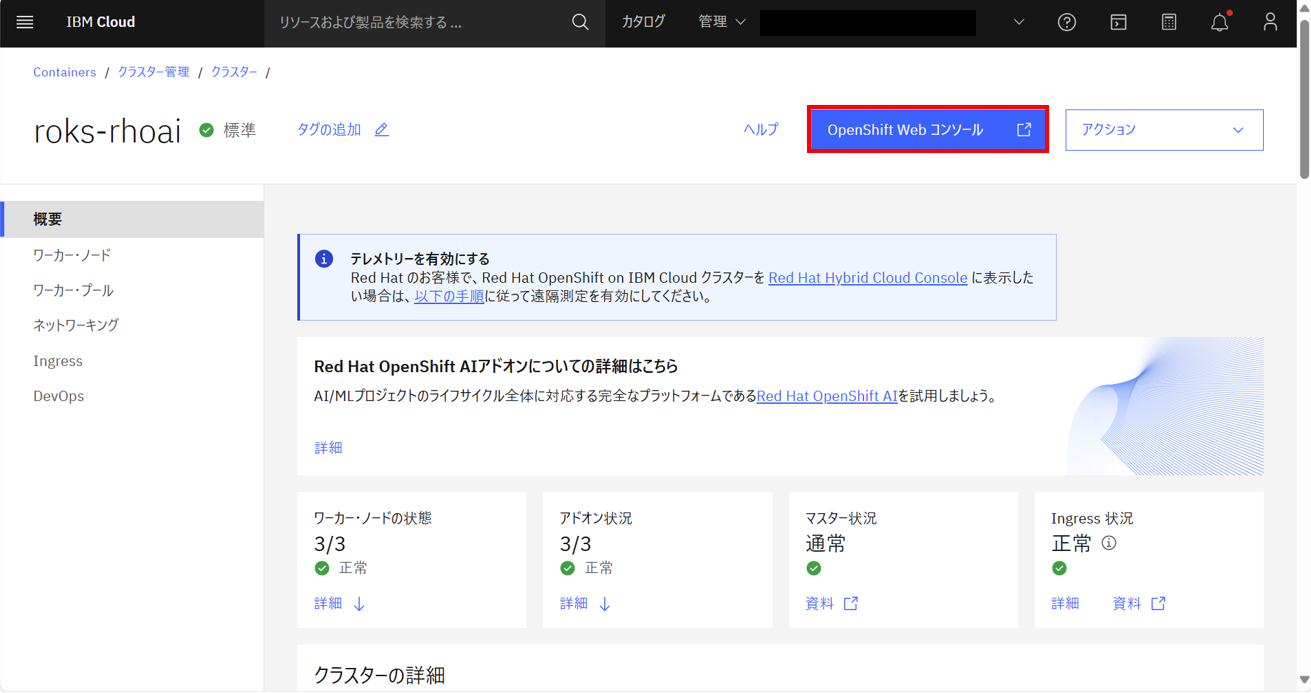
インストール済みOperatorを確認すると、以下がインストールされていた。
- NVIDIA GPU Operator
- Node Feature Discovery Operator
- Red Hat OpenShift Pipelines
- Red Hat OpenShift AI

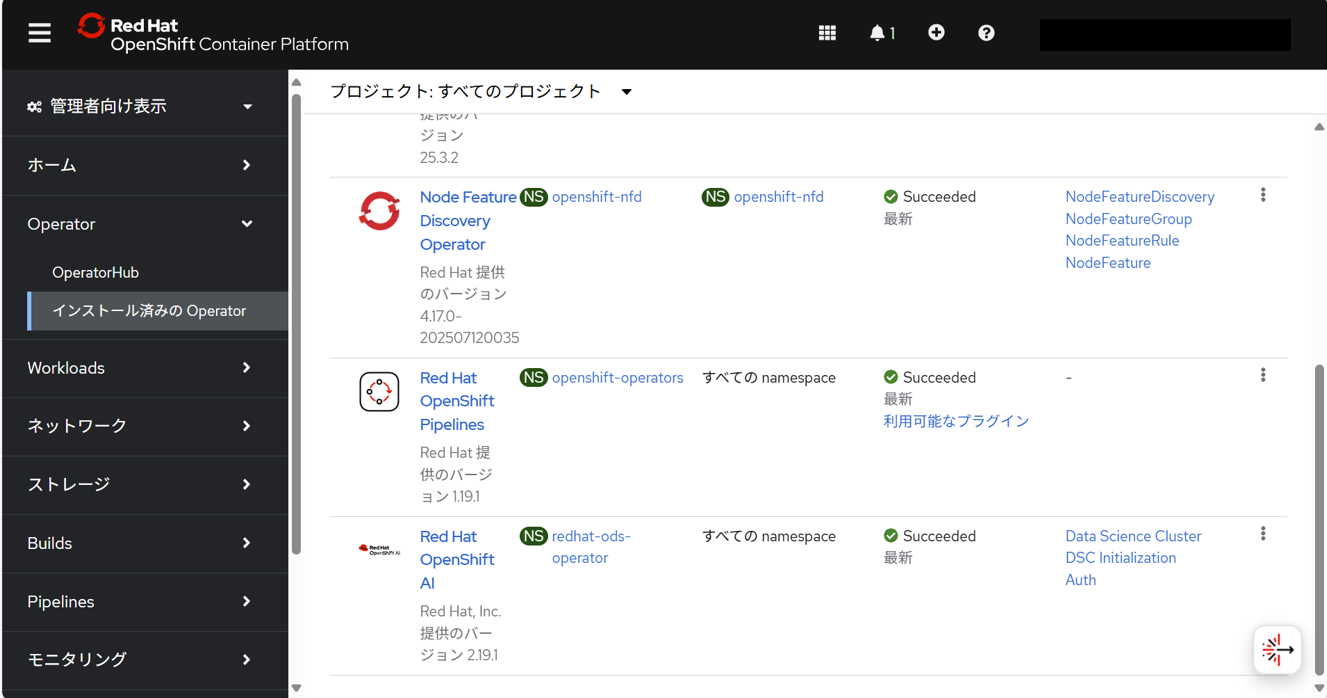
注記
前回の構築時のRed Hat OpenShift AIのバージョンは、2.16.2だったが、今回は2.19.1で、バージョンが異なることを確認できた。
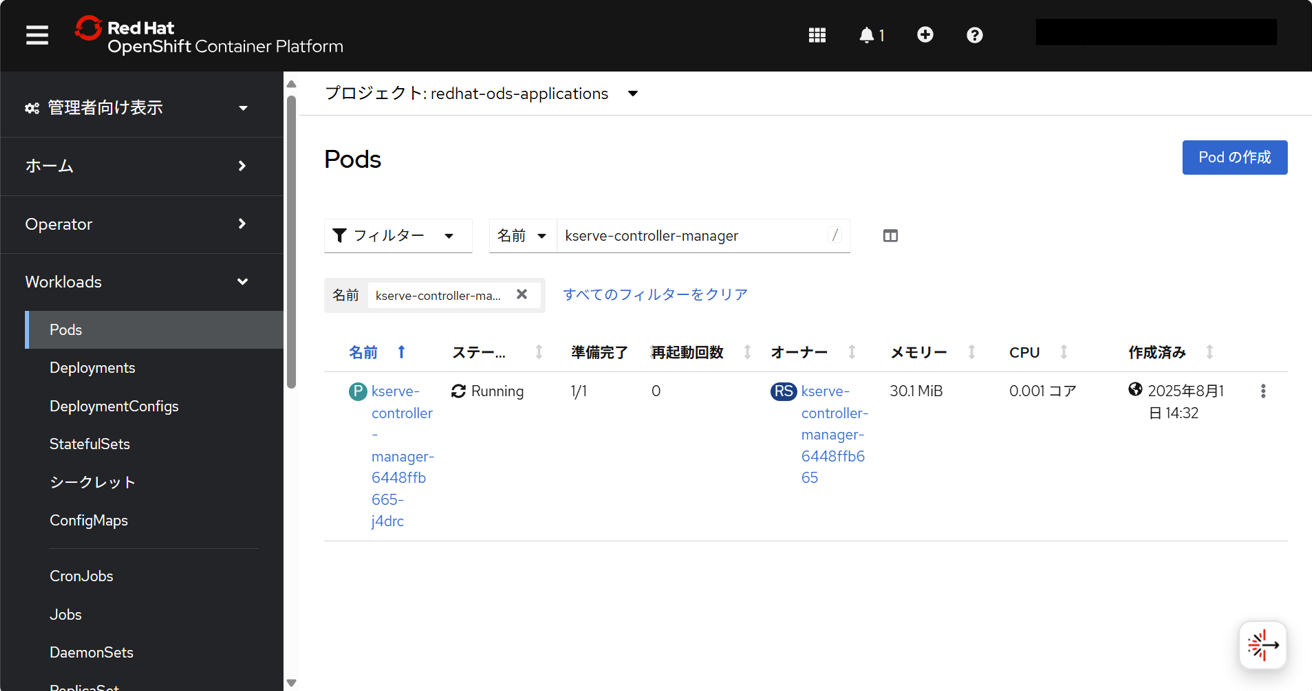
KServeインストール確認
■ KServe:Kubernetes上に機械学習モデルをデプロイするためのモデル推論プラットフォーム。特に、大規模モデルに適している。
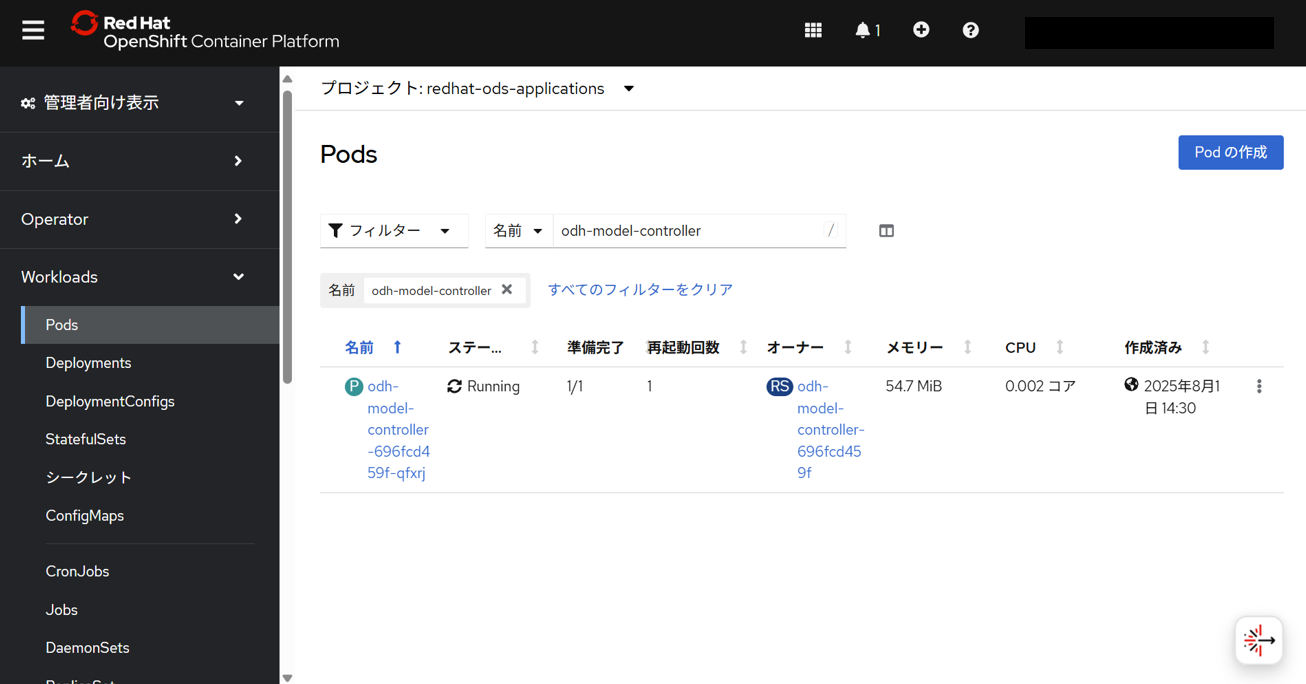
KServeがインストールされていることを確認するため、redhat-ods-applicationsプロジェクトで、以下のpodが存在することを確認する。
- kserve-controller-manager
- odh-model-controller
該当のpodが存在することを確認できた。
Single-model serving有効確認
■ Single-model serving:各モデルが独自のモデルサーバーにデプロイされる。大規模言語モデル (LLM) などの多くのリソースを必要とする大規模モデルに適している。KServeコンポーネントをベースとする。
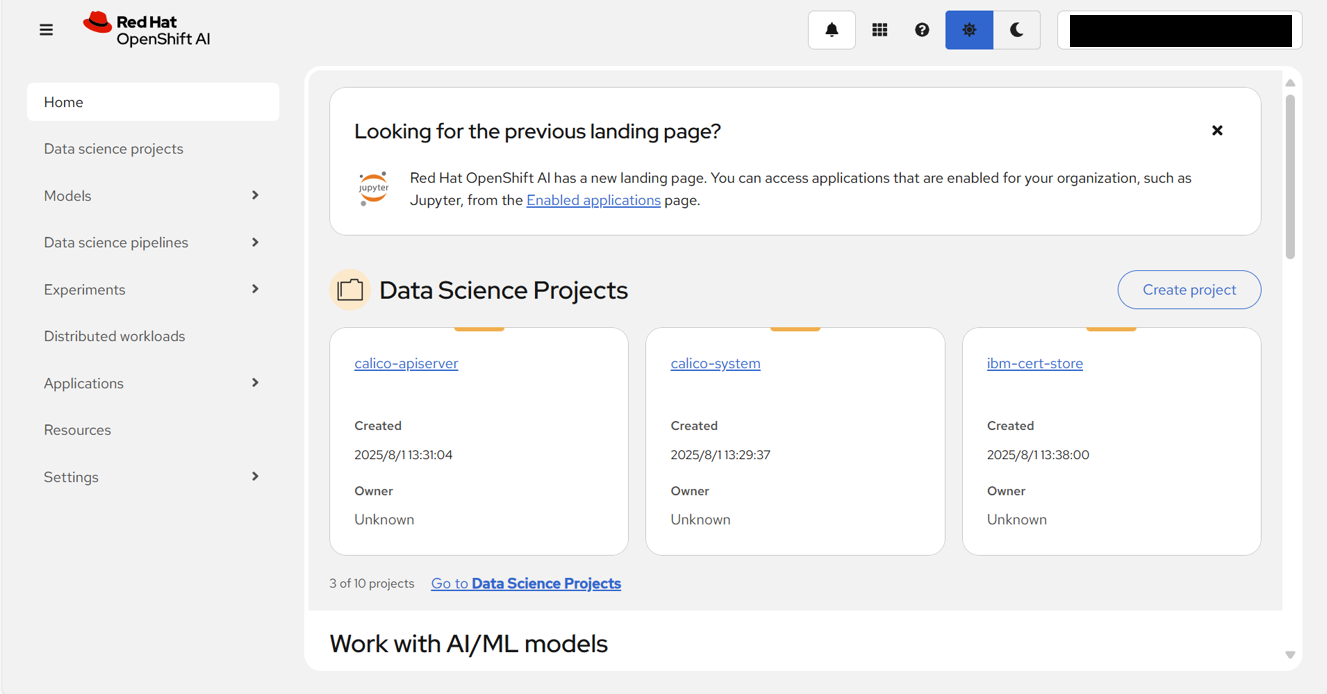
OpenShift AI Webコンソールを開く。
「Data science projects」のうち、一つをクリックする。
上部タブの「Models」をクリックすると、Single-model servingを選択できるようになっていることが確認できる。

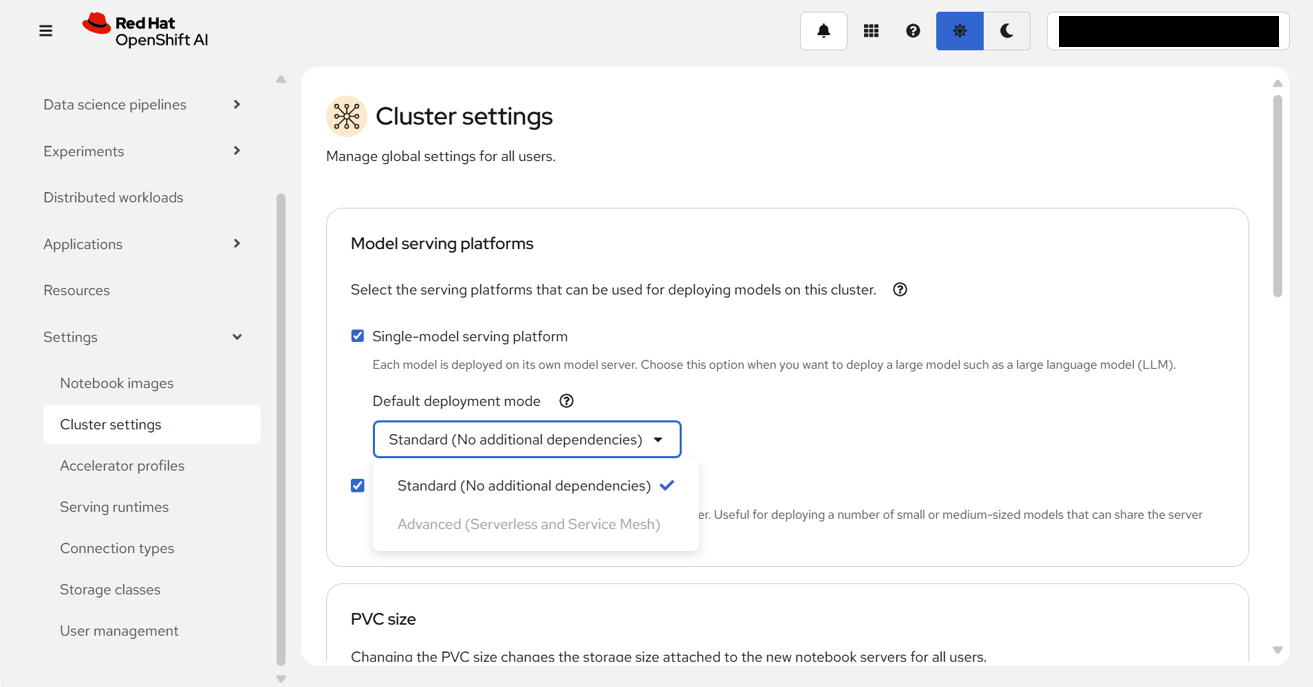
「Cluster settings」画面を確認すると、Model serving platforms欄は、Single-model serving platformと
Multi-model serving platformの両方にチェックが入っていて、Single-model serving platformはDefault deployment modeとして、Standard (No additional dependencies)が設定されていた。また、デプロイメントモードは、Standardのみが有効になっていて、Advancedは選択できないようになっていた。
デプロイメントモードについての概要はそれぞれ以下。
-
advancedモード:Knative Serverless が使用される。Red Hat Serverless、Red Hat Service Meshなどの追加の依存関係が必要。 -
standardモード:KServe RawDeployment モードを使用し、Red Hat Serverless、Red Hat Service Meshなどの追加の依存関係が不要。
LLM起動確認
KServeがインストールされていて、Single-model servingが有効であることを確認できたため、LLM Servingを行う。
前提条件
S3 互換オブジェクトストレージにモデルをアップロード済み。今回は以下を使用。
- S3 互換オブジェクトストレージ:IBM Cloud Object Storage
- モデル:ibm-granite/granite-3.2-8b-instruct
モデルのアップロード方法は、前回のQiita記事の『ICOSへのモデルのインポート』を参照。
Data Science Project作成
「Data Science Project」画面で、「Create project」をクリックし、プロジェクト名「LLM-serving-granite-3.2-8b」を入力する。
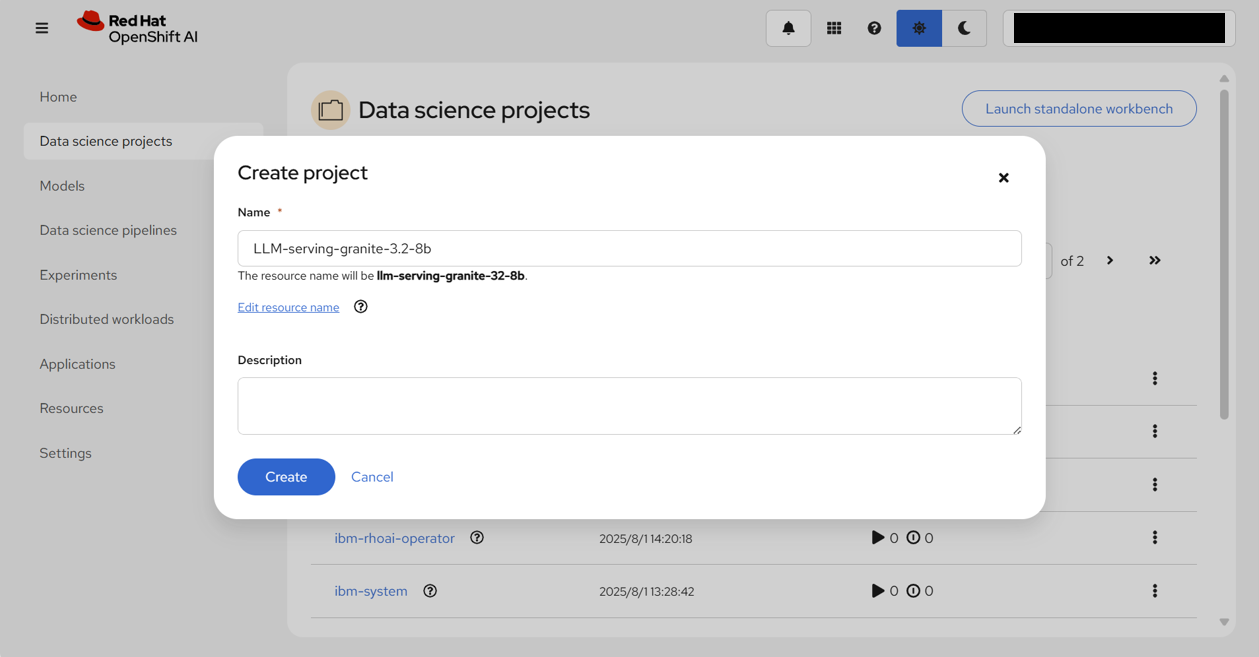
「Create」をクリックすると、無事LLM-serving-granite-3.2-8bプロジェクトが作成される。
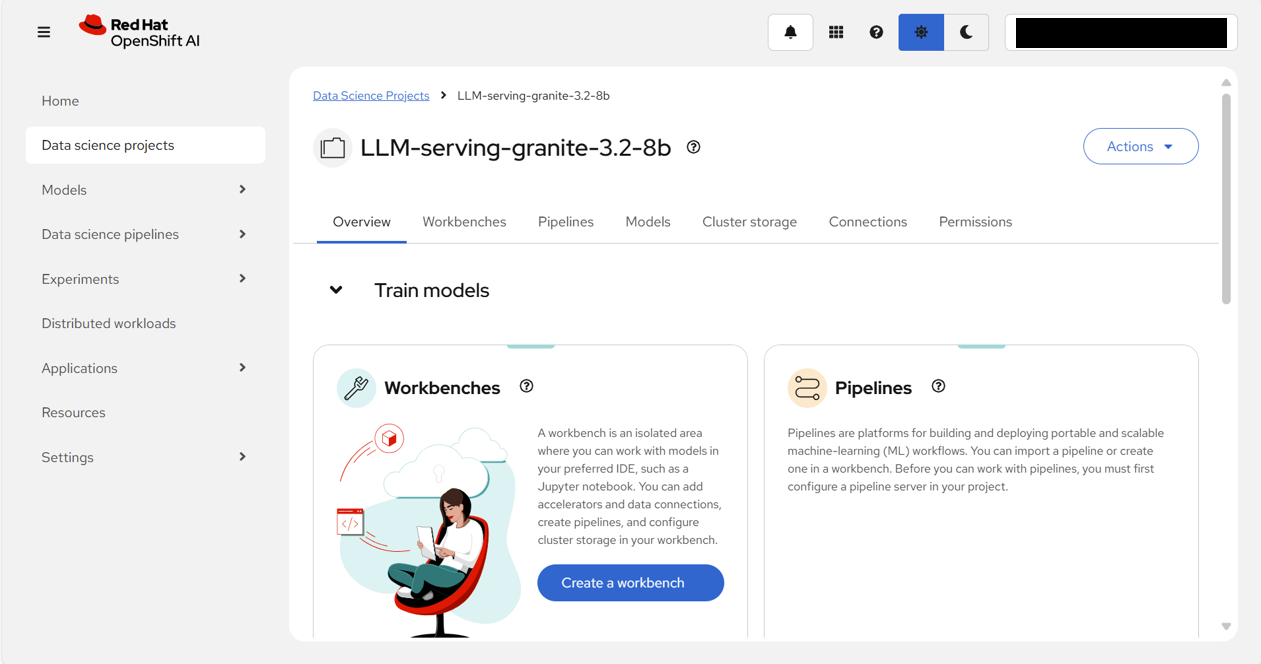
モデルサービング
上部の「Models」タブを選択した上で、「Select single-model」をクリックする。

「Deploy model」をクリックする。
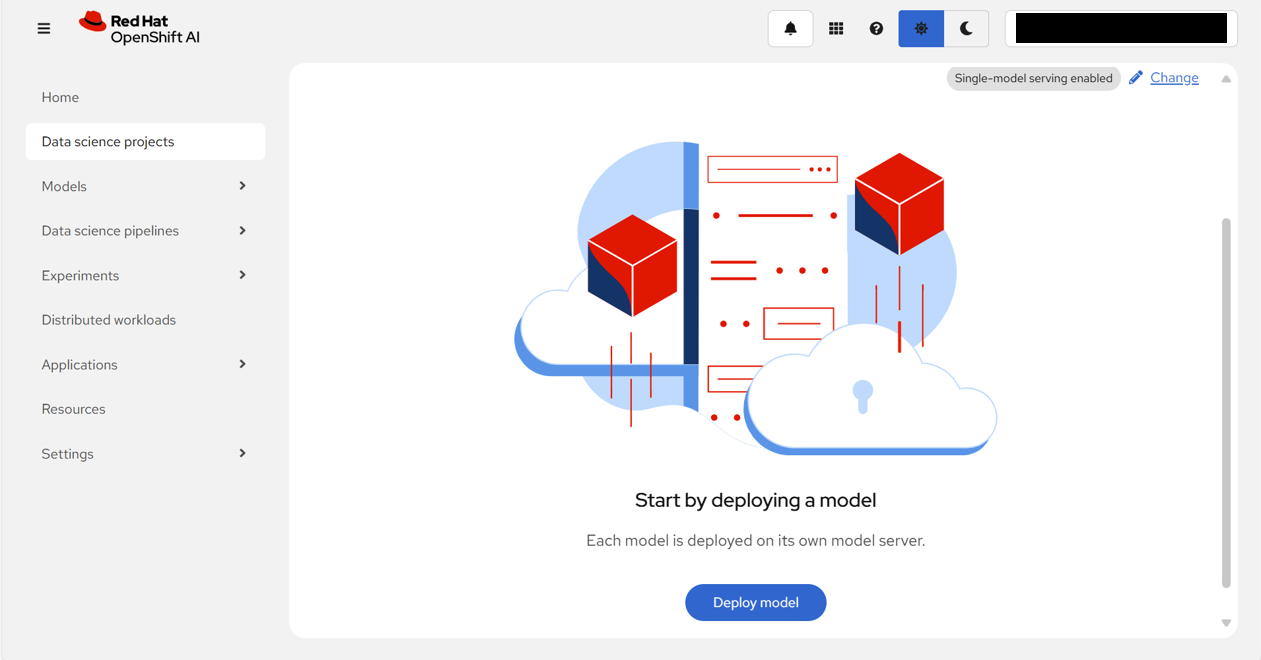
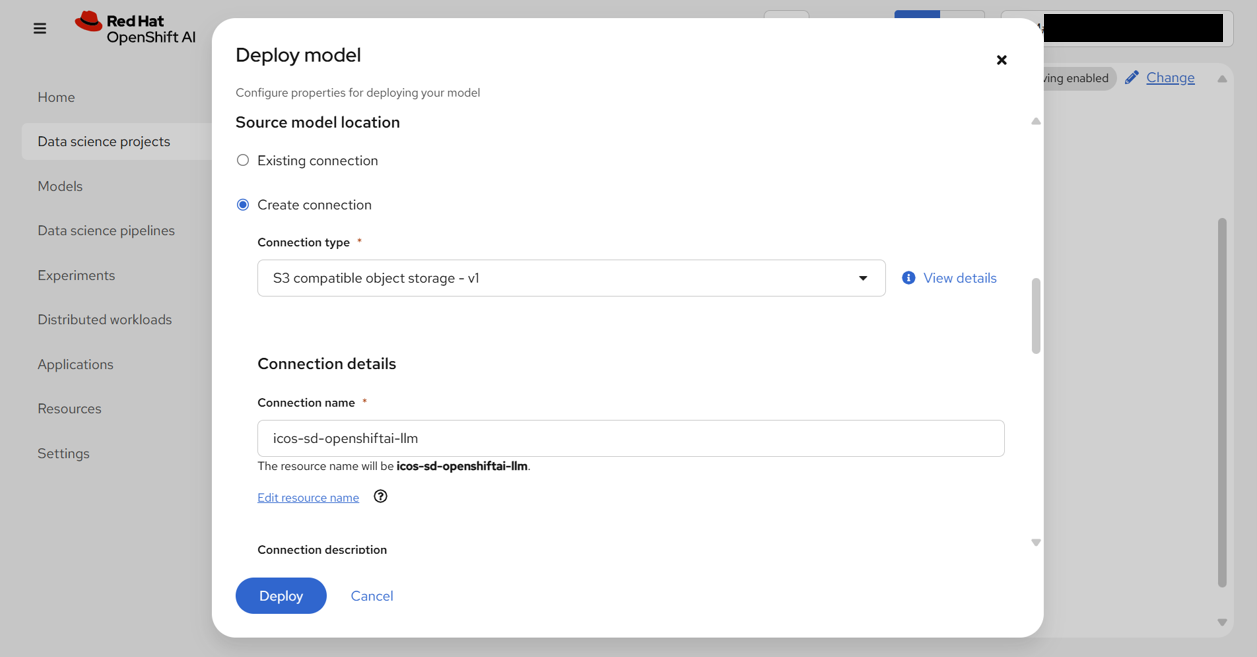
以下の表の通り、入力/選択し、「Deploy」をクリックする。
| フィールド名 | 入力/選択値 | |
|---|---|---|
| Model deployment | Model deployment name | granite-3.2-8b |
| Serving runtime | vLLM NVIDIA GPU ServingRuntime for KServe | |
| Model framework (name - version) | vLLM | |
| Number of model server replicas to deploy | 1 | |
| Model server size | Small | |
| Model route | □ (チェックを外す) | |
| Token Authentication | □ (チェックを外す) | |
| Source model location | Create connection | |
| Connection type | S3 compatible object storage - v1 | |
| Name | icos-sd-openshiftai-llm | |
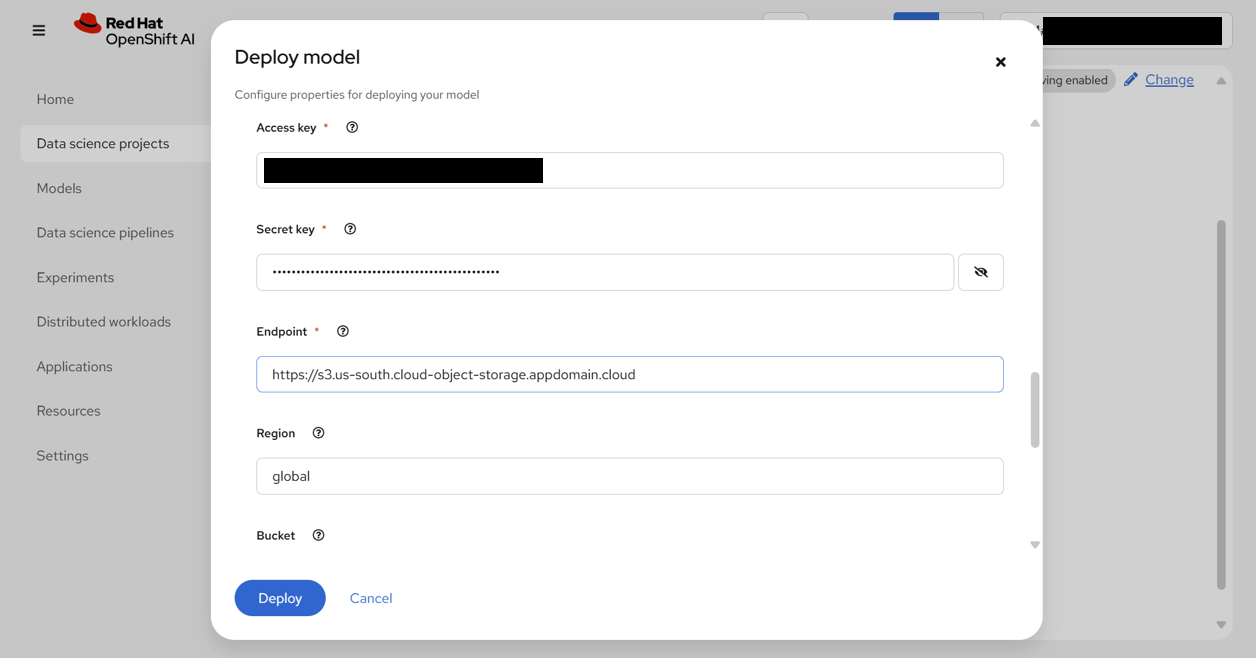
| Access Key | (ICOSの接続情報としてメモしておいたAccess Keyを入力) | |
| Secret Key | (ICOSの接続情報としてメモしておいたSecret Keyを入力) | |
| Endpoint | https://s3.us-south.cloud-object-storage.appdomain.cloud | |
| Region | global | |
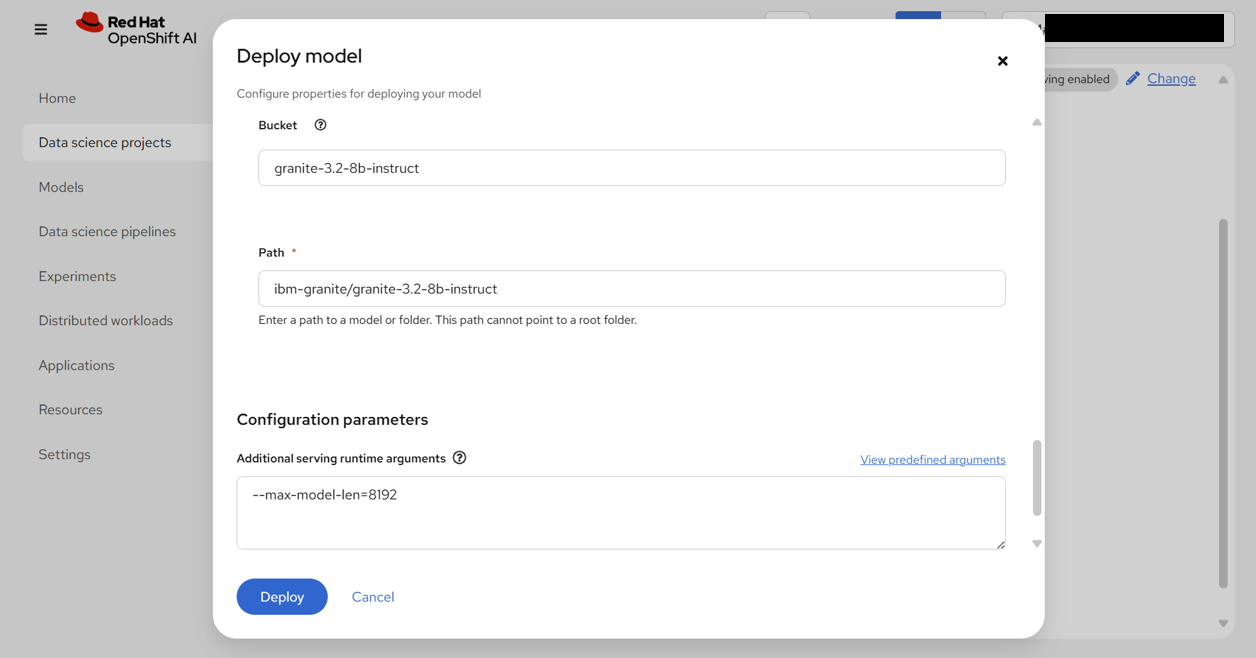
| Bucket | granite-3.2-8b-instruct | |
| Path | ibm-granite/granite-3.2-8b-instruct | |
| Configuration parameters | Additional serving runtime arguments | --max-model-len=8192 |
注記
デフォルトのままだとメモリ不足になるため、パラメーターとして--max-model-len=8192を指定することで、トークン数に制限をかける。
参考:Optimization and Tuning - vLLM
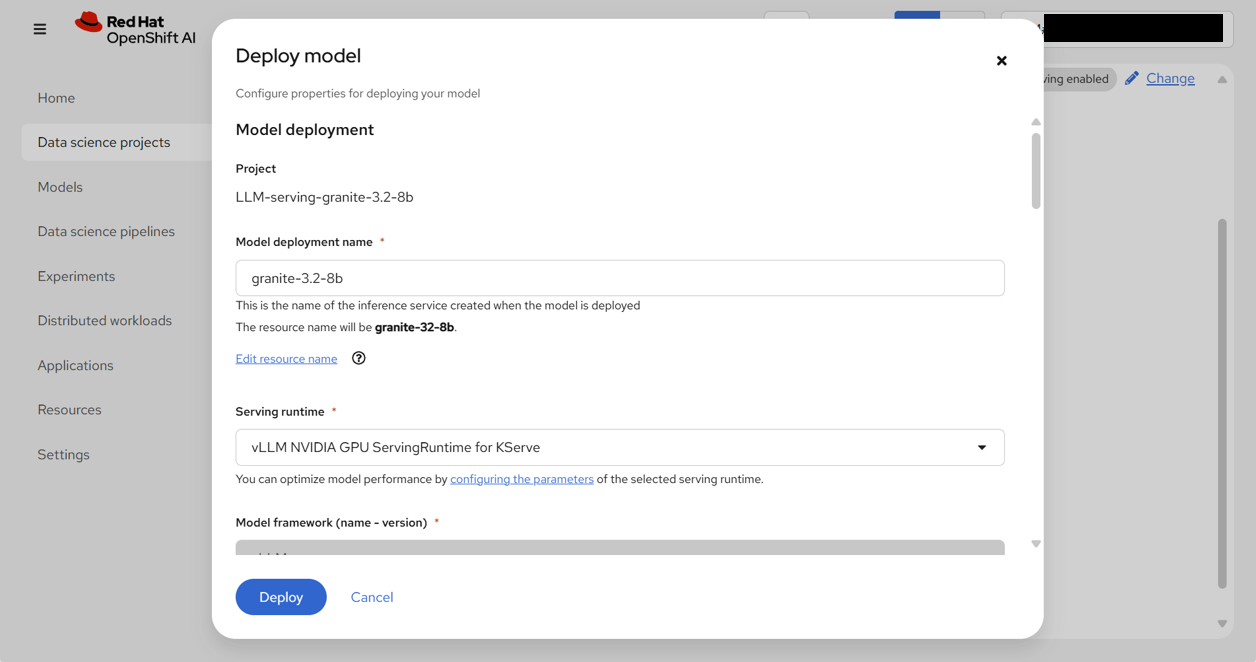

Statusにグリーンのチェックマーク✔が入るのを待つ。
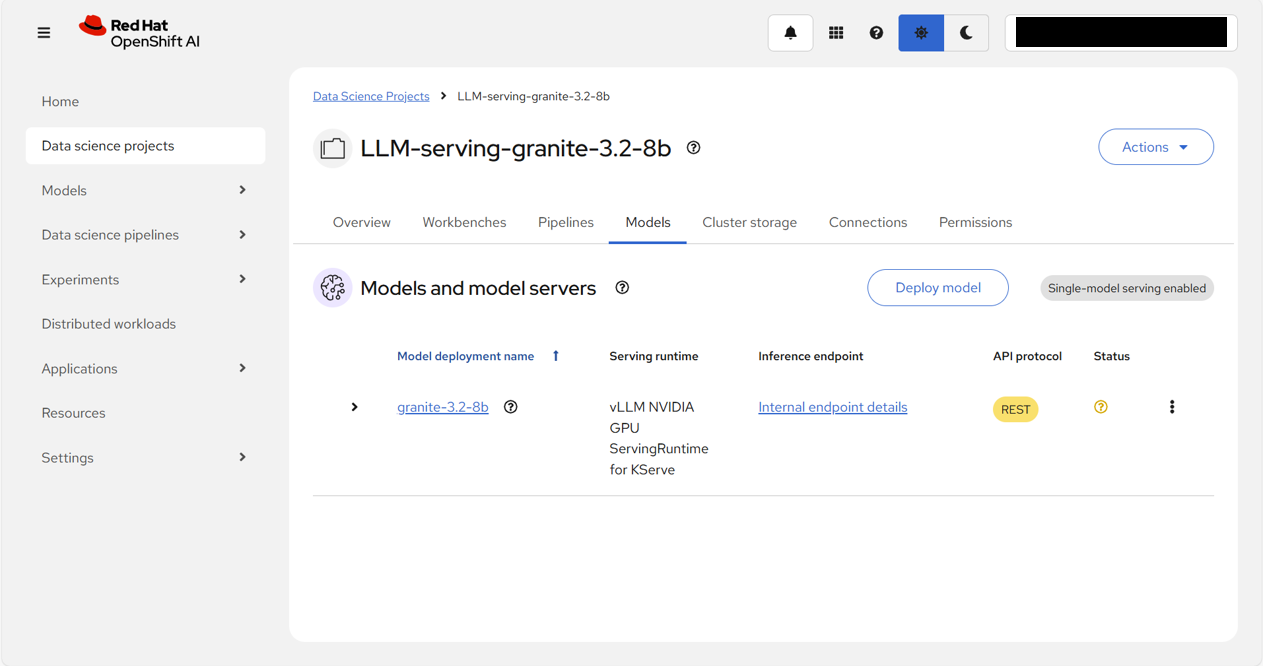
待機するまでの間、進捗・状況を把握するため、OpenShift Webコンソールで、llm-serving-granite-32-8bプロジェクト内にデプロイされたモデルのPodのログを確認する。

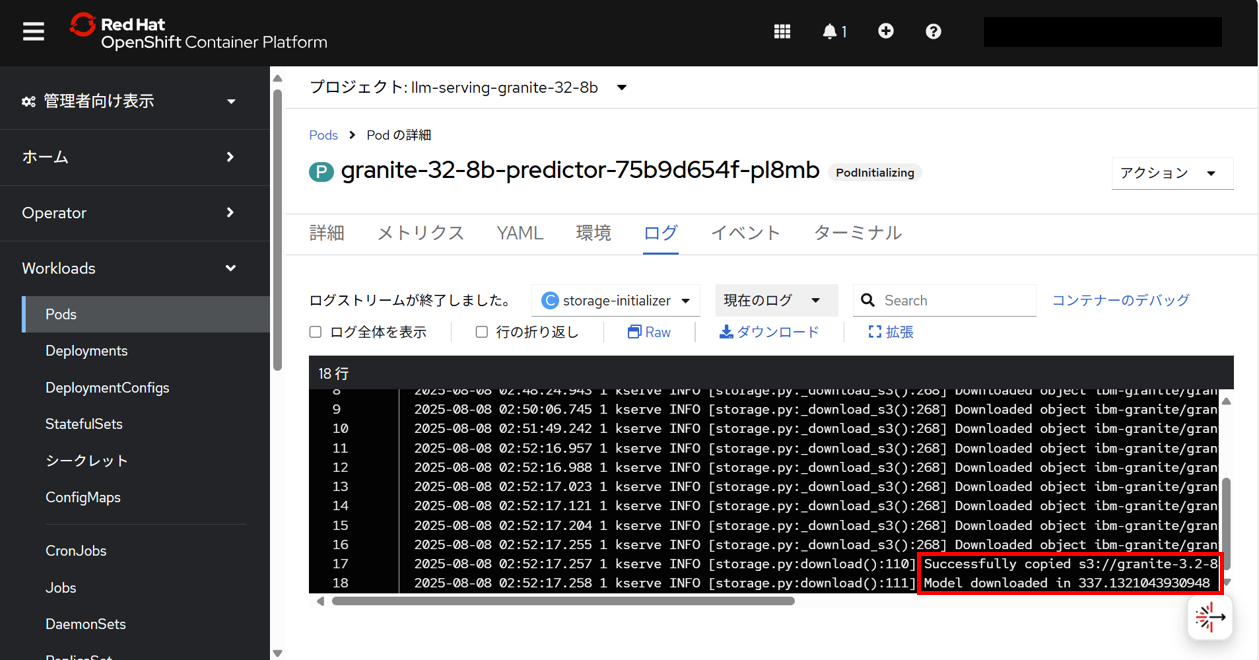
まず、Initコンテナであるstorage-initializerコンテナのログが出力される。以下のログが出力されると、次に、アプリケーションコンテナであるkserve-containerコンテナのログの出力が始まる。
INFO [storage.py:download():110] Successfully copied s3://granite-3.2-8b-instruct/ibm-granite/granite-3.2-8b-instruct to /mnt/models
INFO [storage.py:download():111] Model downloaded in 332.8175340681337 seconds.
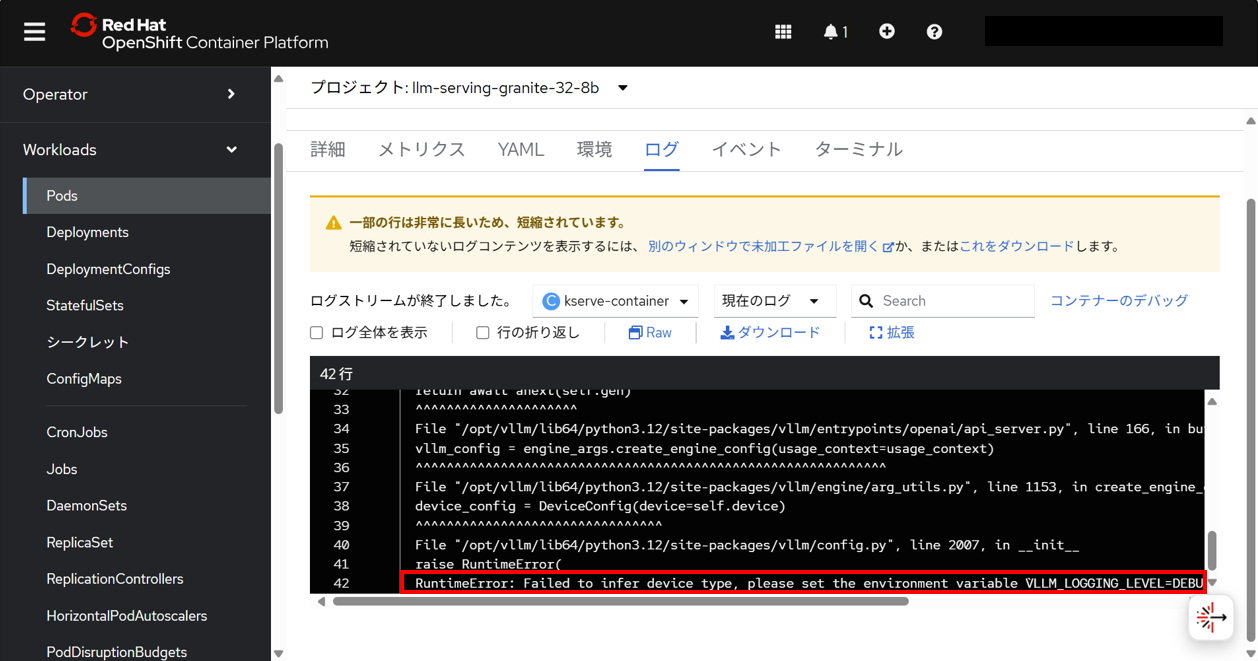
kserve-containerコンテナのログを確認する。最後に、エラーが出力される。
注記
全てのログの内容を確認する場合は、
こちらの矢印をクリック。
INFO 08-08 03:06:58 [__init__.py:243] No platform detected, vLLM is running on UnspecifiedPlatform
INFO 08-08 03:07:00 [api_server.py:1034] vLLM API server version 0.8.5.dev411+g7ad990749
INFO 08-08 03:07:00 [api_server.py:1035] args: Namespace(host=None, port=8080, uvicorn_log_level='info', disable_uvicorn_access_log=False, allow_credentials=False, allowed_origins=['*'], allowed_methods=['*'], allowed_headers=['*'], api_key=None, lora_modules=None, prompt_adapters=None, chat_template=None, chat_template_content_format='auto', response_role='assistant', ssl_keyfile=None, ssl_certfile=None, ssl_ca_certs=None, enable_ssl_refresh=False, ssl_cert_reqs=0, root_path=None, middleware=[], return_tokens_as_token_ids=False, disable_frontend_multiprocessing=False, enable_request_id_headers=False, enable_auto_tool_choice=False, tool_call_parser=None, tool_parser_plugin='', model='/mnt/models', task='auto', tokenizer=None, hf_config_path=None, skip_tokenizer_init=False, revision=None, code_revision=None, tokenizer_revision=None, tokenizer_mode='auto', trust_remote_code=False, allowed_local_media_path=None, load_format='auto', download_dir=None, model_loader_extra_config=None, use_tqdm_on_load=True, config_format=<ConfigFormat.AUTO: 'auto'>, dtype='auto', kv_cache_dtype='auto', max_model_len=8192, guided_decoding_backend='auto', logits_processor_pattern=None, model_impl='auto', distributed_executor_backend=None, pipeline_parallel_size=1, tensor_parallel_size=1, data_parallel_size=1, enable_expert_parallel=False, max_parallel_loading_workers=None, ray_workers_use_nsight=False, disable_custom_all_reduce=False, block_size=None, enable_prefix_caching=None, prefix_caching_hash_algo='builtin', disable_sliding_window=False, use_v2_block_manager=True, num_lookahead_slots=0, seed=None, swap_space=4, cpu_offload_gb=0, gpu_memory_utilization=0.9, num_gpu_blocks_override=None, max_num_batched_tokens=None, max_num_partial_prefills=1, max_long_partial_prefills=1, long_prefill_token_threshold=0, max_num_seqs=None, max_logprobs=20, disable_log_stats=False, quantization=None, rope_scaling=None, rope_theta=None, hf_token=None, hf_overrides=None, enforce_eager=False, max_seq_len_to_capture=8192, tokenizer_pool_size=0, tokenizer_pool_type='ray', tokenizer_pool_extra_config=None, limit_mm_per_prompt=None, mm_processor_kwargs=None, disable_mm_preprocessor_cache=False, enable_lora=False, enable_lora_bias=False, max_loras=1, max_lora_rank=16, lora_extra_vocab_size=256, lora_dtype='auto', long_lora_scaling_factors=None, max_cpu_loras=None, fully_sharded_loras=False, enable_prompt_adapter=False, max_prompt_adapters=1, max_prompt_adapter_token=0, device='auto', num_scheduler_steps=1, multi_step_stream_outputs=True, scheduler_delay_factor=0.0, enable_chunked_prefill=None, speculative_config=None, ignore_patterns=[], preemption_mode=None, served_model_name=['granite-32-8b'], qlora_adapter_name_or_path=None, show_hidden_metrics_for_version=None, otlp_traces_endpoint=None, collect_detailed_traces=None, disable_async_output_proc=False, scheduling_policy='fcfs', scheduler_cls='vllm.core.scheduler.Scheduler', override_neuron_config=None, override_pooler_config=None, compilation_config=None, kv_transfer_config=None, worker_cls='auto', worker_extension_cls='', generation_config='auto', override_generation_config=None, enable_sleep_mode=False, calculate_kv_scales=False, additional_config=None, enable_reasoning=False, reasoning_parser=None, disable_cascade_attn=False, disable_chunked_mm_input=False, disable_log_requests=False, max_log_len=None, disable_fastapi_docs=False, enable_prompt_tokens_details=False, enable_server_load_tracking=False)
Traceback (most recent call last):
File "<frozen runpy>", line 198, in _run_module_as_main
File "<frozen runpy>", line 88, in _run_code
File "/opt/vllm/lib64/python3.12/site-packages/vllm/entrypoints/openai/api_server.py", line 1121, in <module>
uvloop.run(run_server(args))
File "/opt/vllm/lib64/python3.12/site-packages/uvloop/__init__.py", line 109, in run
return __asyncio.run(
^^^^^^^^^^^^^^
File "/usr/lib64/python3.12/asyncio/runners.py", line 195, in run
return runner.run(main)
^^^^^^^^^^^^^^^^
File "/usr/lib64/python3.12/asyncio/runners.py", line 118, in run
return self._loop.run_until_complete(task)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "uvloop/loop.pyx", line 1518, in uvloop.loop.Loop.run_until_complete
File "/opt/vllm/lib64/python3.12/site-packages/uvloop/__init__.py", line 61, in wrapper
return await main
^^^^^^^^^^
File "/opt/vllm/lib64/python3.12/site-packages/vllm/entrypoints/openai/api_server.py", line 1069, in run_server
async with build_async_engine_client(args) as engine_client:
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/lib64/python3.12/contextlib.py", line 210, in __aenter__
return await anext(self.gen)
^^^^^^^^^^^^^^^^^^^^^
File "/opt/vllm/lib64/python3.12/site-packages/vllm/entrypoints/openai/api_server.py", line 146, in build_async_engine_client
async with build_async_engine_client_from_engine_args(
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/lib64/python3.12/contextlib.py", line 210, in __aenter__
return await anext(self.gen)
^^^^^^^^^^^^^^^^^^^^^
File "/opt/vllm/lib64/python3.12/site-packages/vllm/entrypoints/openai/api_server.py", line 166, in build_async_engine_client_from_engine_args
vllm_config = engine_args.create_engine_config(usage_context=usage_context)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/opt/vllm/lib64/python3.12/site-packages/vllm/engine/arg_utils.py", line 1153, in create_engine_config
device_config = DeviceConfig(device=self.device)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/opt/vllm/lib64/python3.12/site-packages/vllm/config.py", line 2007, in __init__
raise RuntimeError(
RuntimeError: Failed to infer device type, please set the environment variable `VLLM_LOGGING_LEVEL=DEBUG` to turn on verbose logging to help debug the issue.
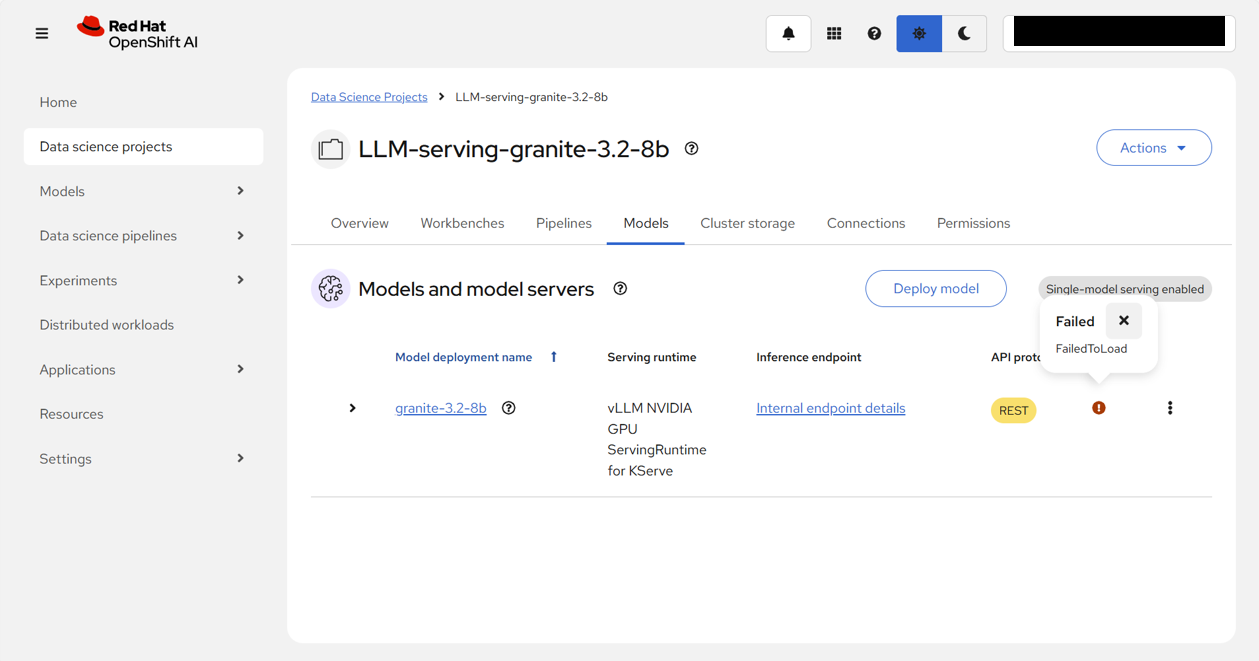
OpenShift AI Webコンソール画面に戻ってステータスを確認すると、!に変わっていて、ロードに失敗していることがわかる。
こちらのKBを参照したところ、アクセラレーターとして、NVIDIA GPUを選択する必要があることが記載されていた。
先程モデルをデプロイするために設定した際には、アクセラレーターの欄が表示されなかった。以下のようにデプロイしたモデルの詳細を確認すると、アクセラレーター欄に、「No accelerator enabled」と記載があることがわかる。
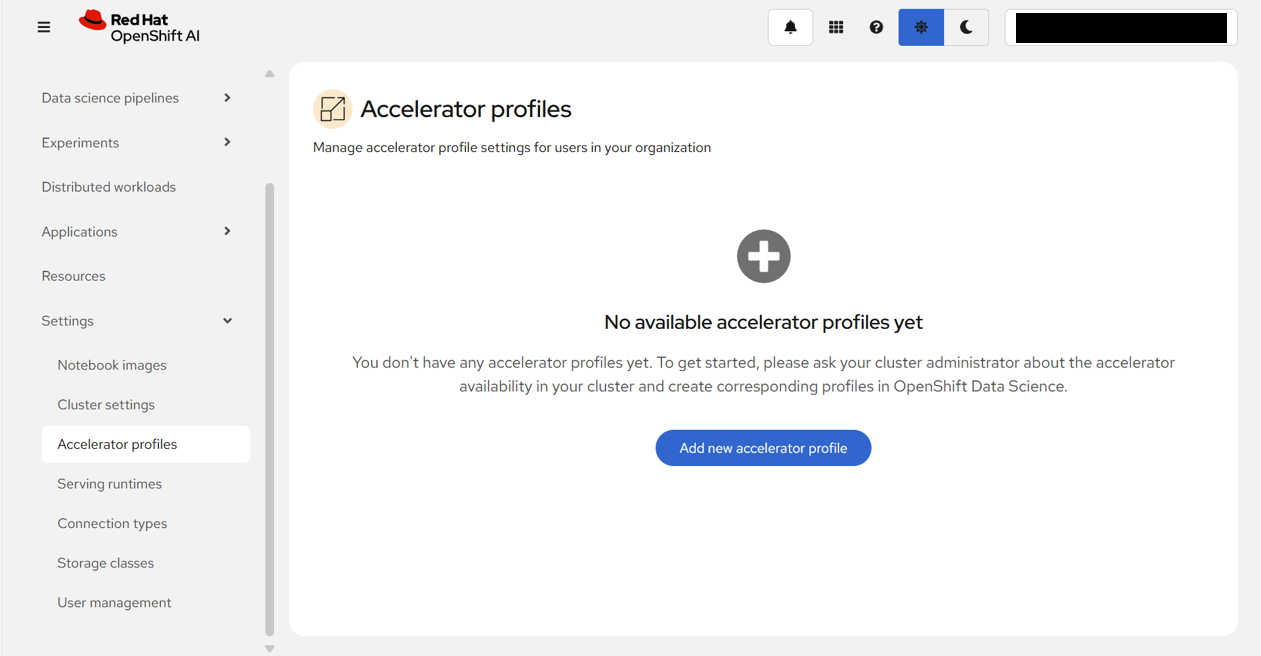
そのため、まずはアクセラレータープロファイルを作成することにする。

「Accelerator profiles」画面で、「Add new accelerator profile」をクリックする。
以下のように設定し、「Create accelerator profile」をクリックする。
| フィールド名 | 入力/選択値 | |
|---|---|---|
| Details | Name | NVIDIA GPU |
| Identifier | nvidia.com/gpu |
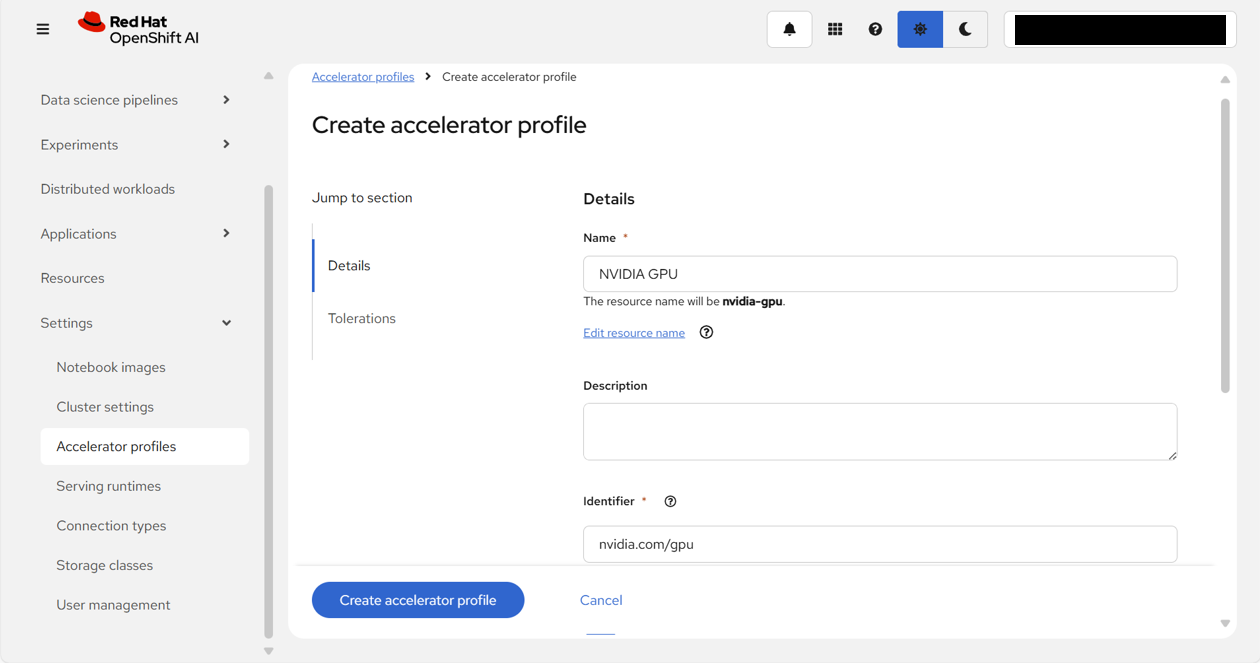
アクセラレータープロファイルの作成が完了し、NVIDIA GPUがEnableになっていることが確認できる。
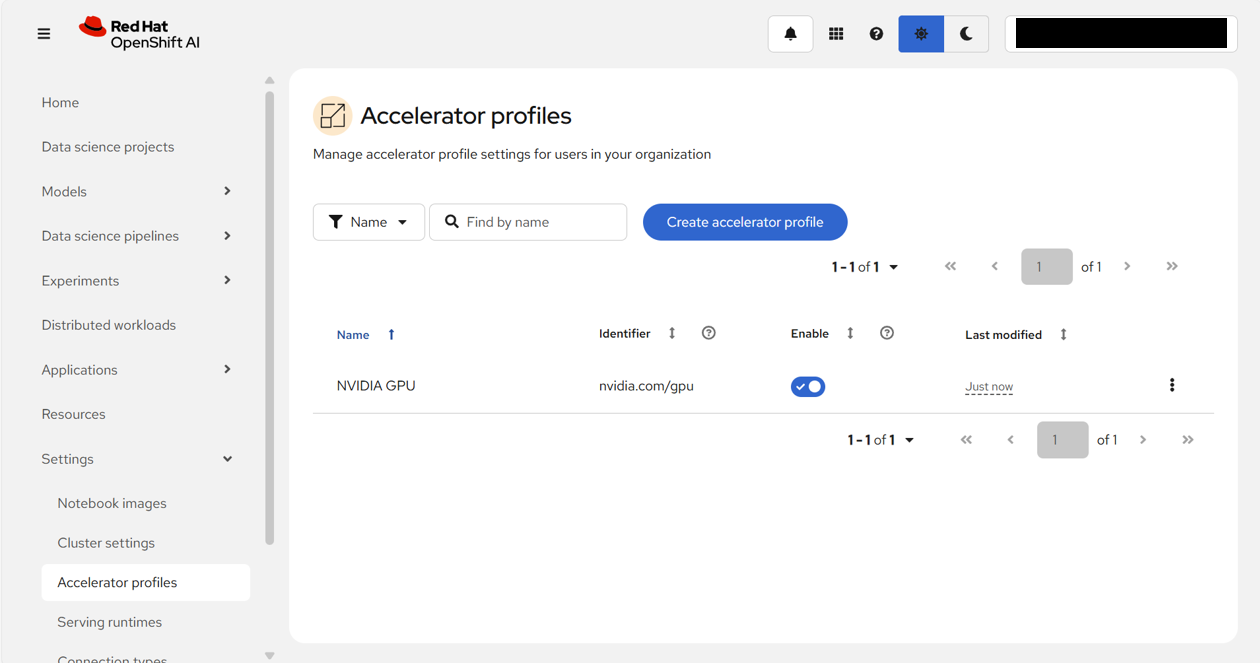
先程のデプロイしたモデルの表示画面に戻り、「3点リーダー(︙)」 > 「Edit」 をクリックする。
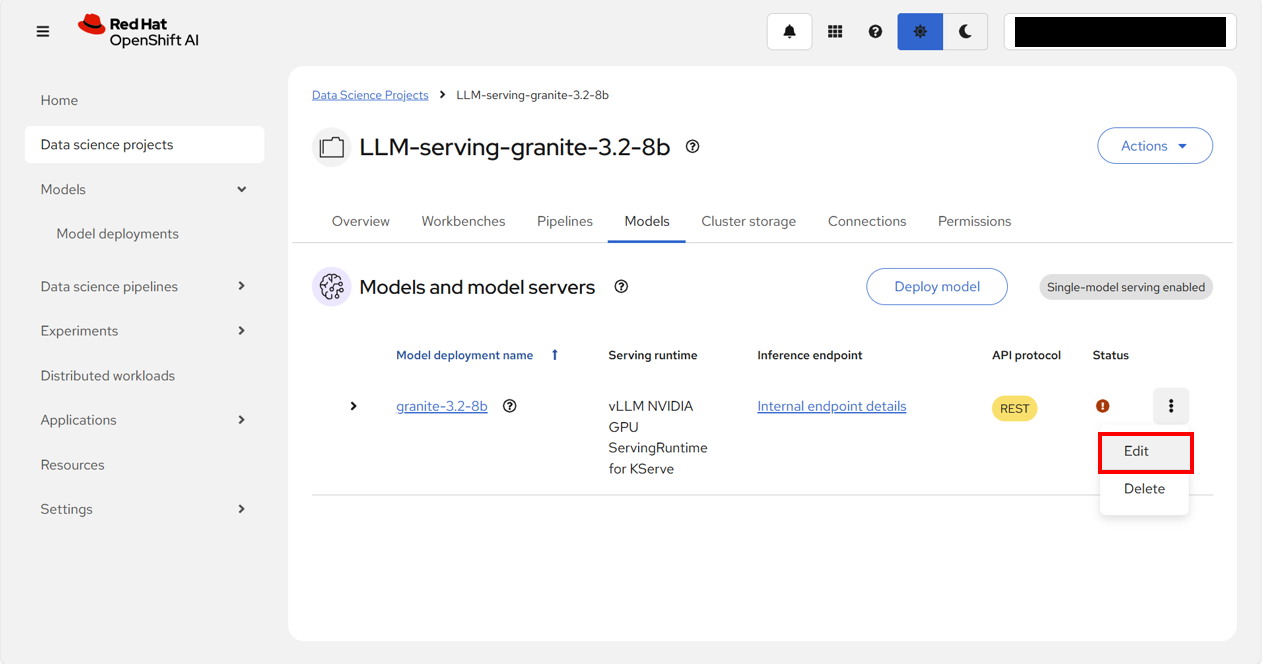
以下のように、アクセラレーター欄が表示されるようになるため、「NVIDIA GPU」を選択し、「Redeploy」をクリックする。
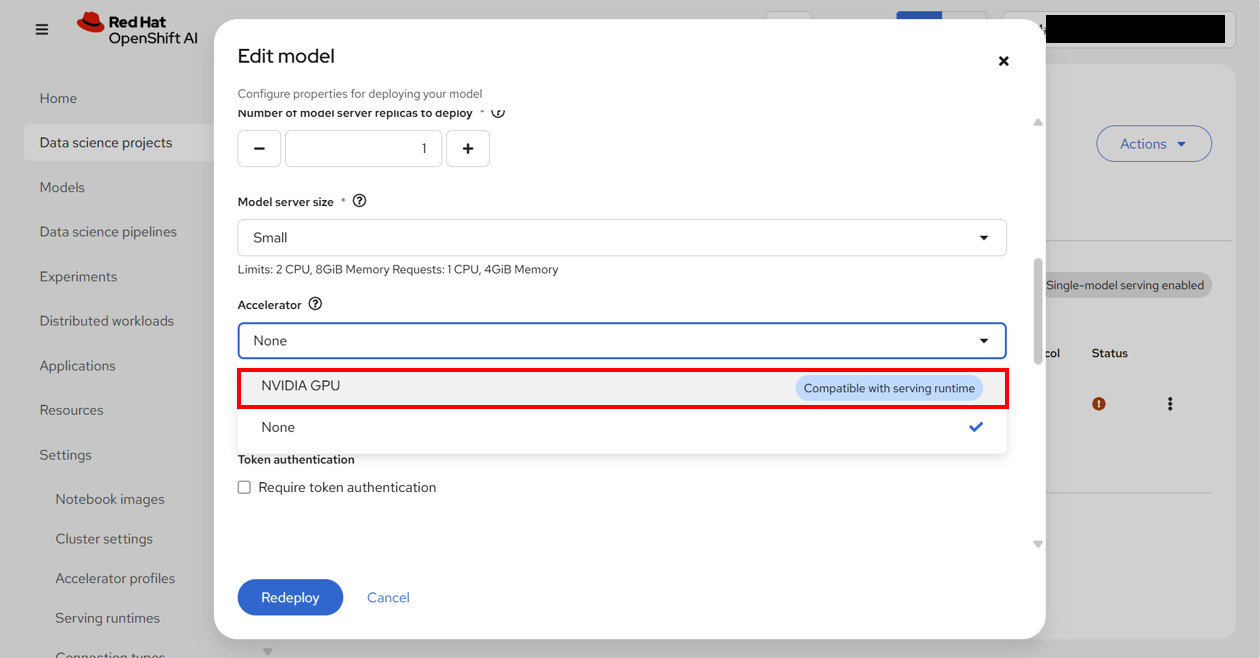
モデルの詳細を確認すると、アクセラレーター欄が、「NVIDIA GPU」に変わっていることがわかる。
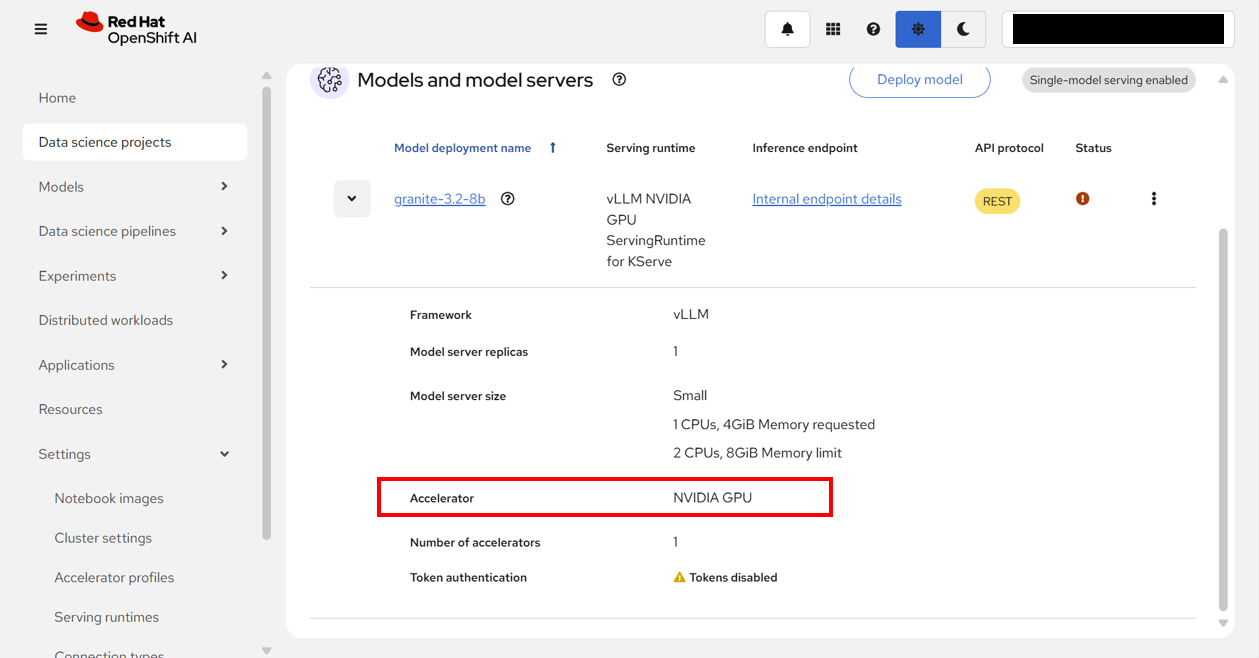
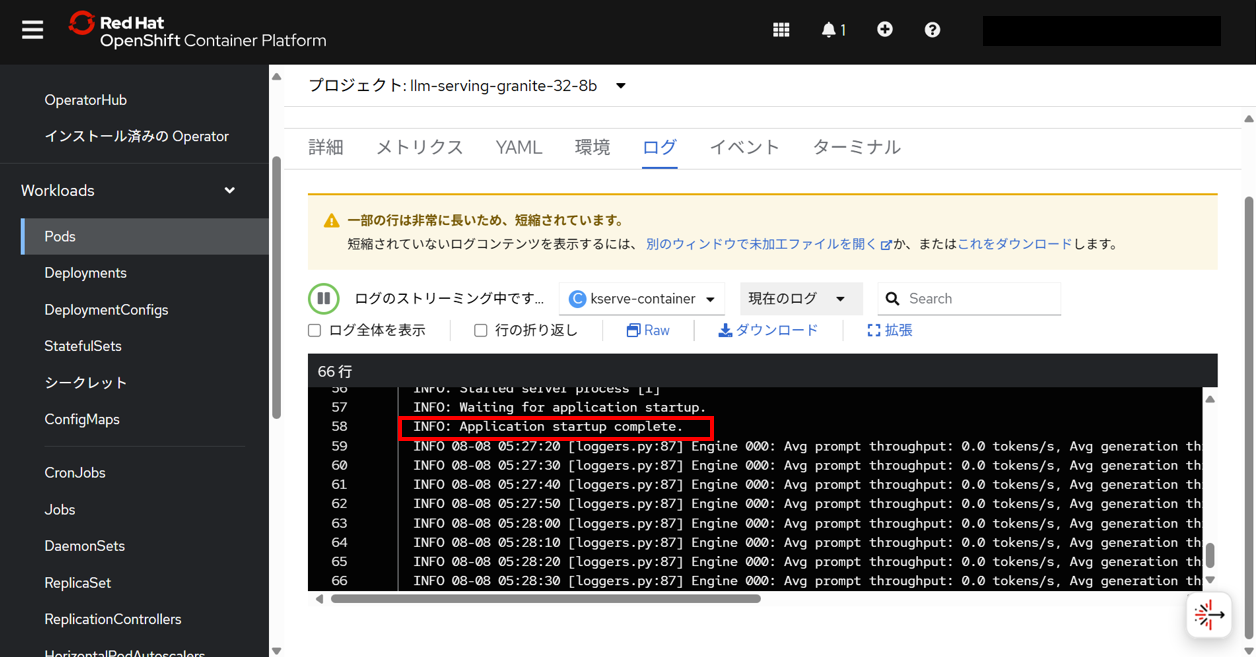
再度、OpenShift Webコンソールで、llm-serving-granite-32-8bプロジェクト内にデプロイされたモデルのPodのログを確認して、進捗・状況を把握する。
kserve-containerコンテナのログをみると、先程とは表示が異なり、途中で、INFO: Application startup complete.というログが出力され、無事にモデルの起動が完了したことがわかる。
注記
全てのログの内容を確認する場合は、
こちらの矢印をクリック。
INFO 08-08 05:19:52 [__init__.py:239] Automatically detected platform cuda.
INFO 08-08 05:19:54 [api_server.py:1034] vLLM API server version 0.8.5.dev411+g7ad990749
INFO 08-08 05:19:54 [api_server.py:1035] args: Namespace(host=None, port=8080, uvicorn_log_level='info', disable_uvicorn_access_log=False, allow_credentials=False, allowed_origins=['*'], allowed_methods=['*'], allowed_headers=['*'], api_key=None, lora_modules=None, prompt_adapters=None, chat_template=None, chat_template_content_format='auto', response_role='assistant', ssl_keyfile=None, ssl_certfile=None, ssl_ca_certs=None, enable_ssl_refresh=False, ssl_cert_reqs=0, root_path=None, middleware=[], return_tokens_as_token_ids=False, disable_frontend_multiprocessing=False, enable_request_id_headers=False, enable_auto_tool_choice=False, tool_call_parser=None, tool_parser_plugin='', model='/mnt/models', task='auto', tokenizer=None, hf_config_path=None, skip_tokenizer_init=False, revision=None, code_revision=None, tokenizer_revision=None, tokenizer_mode='auto', trust_remote_code=False, allowed_local_media_path=None, load_format='auto', download_dir=None, model_loader_extra_config=None, use_tqdm_on_load=True, config_format=<ConfigFormat.AUTO: 'auto'>, dtype='auto', kv_cache_dtype='auto', max_model_len=8192, guided_decoding_backend='auto', logits_processor_pattern=None, model_impl='auto', distributed_executor_backend=None, pipeline_parallel_size=1, tensor_parallel_size=1, data_parallel_size=1, enable_expert_parallel=False, max_parallel_loading_workers=None, ray_workers_use_nsight=False, disable_custom_all_reduce=False, block_size=None, enable_prefix_caching=None, prefix_caching_hash_algo='builtin', disable_sliding_window=False, use_v2_block_manager=True, num_lookahead_slots=0, seed=None, swap_space=4, cpu_offload_gb=0, gpu_memory_utilization=0.9, num_gpu_blocks_override=None, max_num_batched_tokens=None, max_num_partial_prefills=1, max_long_partial_prefills=1, long_prefill_token_threshold=0, max_num_seqs=None, max_logprobs=20, disable_log_stats=False, quantization=None, rope_scaling=None, rope_theta=None, hf_token=None, hf_overrides=None, enforce_eager=False, max_seq_len_to_capture=8192, tokenizer_pool_size=0, tokenizer_pool_type='ray', tokenizer_pool_extra_config=None, limit_mm_per_prompt=None, mm_processor_kwargs=None, disable_mm_preprocessor_cache=False, enable_lora=False, enable_lora_bias=False, max_loras=1, max_lora_rank=16, lora_extra_vocab_size=256, lora_dtype='auto', long_lora_scaling_factors=None, max_cpu_loras=None, fully_sharded_loras=False, enable_prompt_adapter=False, max_prompt_adapters=1, max_prompt_adapter_token=0, device='auto', num_scheduler_steps=1, multi_step_stream_outputs=True, scheduler_delay_factor=0.0, enable_chunked_prefill=None, speculative_config=None, ignore_patterns=[], preemption_mode=None, served_model_name=['granite-32-8b'], qlora_adapter_name_or_path=None, show_hidden_metrics_for_version=None, otlp_traces_endpoint=None, collect_detailed_traces=None, disable_async_output_proc=False, scheduling_policy='fcfs', scheduler_cls='vllm.core.scheduler.Scheduler', override_neuron_config=None, override_pooler_config=None, compilation_config=None, kv_transfer_config=None, worker_cls='auto', worker_extension_cls='', generation_config='auto', override_generation_config=None, enable_sleep_mode=False, calculate_kv_scales=False, additional_config=None, enable_reasoning=False, reasoning_parser=None, disable_cascade_attn=False, disable_chunked_mm_input=False, disable_log_requests=False, max_log_len=None, disable_fastapi_docs=False, enable_prompt_tokens_details=False, enable_server_load_tracking=False)
INFO 08-08 05:20:09 [config.py:689] This model supports multiple tasks: {'classify', 'embed', 'generate', 'reward', 'score'}. Defaulting to 'generate'.
INFO 08-08 05:20:09 [config.py:1901] Chunked prefill is enabled with max_num_batched_tokens=2048.
INFO 08-08 05:20:11 [core.py:61] Initializing a V1 LLM engine (v0.8.5.dev411+g7ad990749) with config: model='/mnt/models', speculative_config=None, tokenizer='/mnt/models', skip_tokenizer_init=False, tokenizer_mode=auto, revision=None, override_neuron_config=None, tokenizer_revision=None, trust_remote_code=False, dtype=torch.bfloat16, max_seq_len=8192, download_dir=None, load_format=LoadFormat.AUTO, tensor_parallel_size=1, pipeline_parallel_size=1, disable_custom_all_reduce=False, quantization=None, enforce_eager=False, kv_cache_dtype=auto, device_config=cuda, decoding_config=DecodingConfig(guided_decoding_backend='auto', reasoning_backend=None), observability_config=ObservabilityConfig(show_hidden_metrics=False, otlp_traces_endpoint=None, collect_model_forward_time=False, collect_model_execute_time=False), seed=None, served_model_name=granite-32-8b, num_scheduler_steps=1, multi_step_stream_outputs=True, enable_prefix_caching=True, chunked_prefill_enabled=True, use_async_output_proc=True, disable_mm_preprocessor_cache=False, mm_processor_kwargs=None, pooler_config=None, compilation_config={"level":3,"custom_ops":["none"],"splitting_ops":["vllm.unified_attention","vllm.unified_attention_with_output"],"use_inductor":true,"compile_sizes":[],"use_cudagraph":true,"cudagraph_num_of_warmups":1,"cudagraph_capture_sizes":[512,504,496,488,480,472,464,456,448,440,432,424,416,408,400,392,384,376,368,360,352,344,336,328,320,312,304,296,288,280,272,264,256,248,240,232,224,216,208,200,192,184,176,168,160,152,144,136,128,120,112,104,96,88,80,72,64,56,48,40,32,24,16,8,4,2,1],"max_capture_size":512}
WARNING 08-08 05:20:12 [utils.py:2444] Methods determine_num_available_blocks,device_config,get_cache_block_size_bytes,initialize_cache not implemented in <vllm.v1.worker.gpu_worker.Worker object at 0x7fa4dc5f52b0>
INFO 08-08 05:20:12 [parallel_state.py:959] rank 0 in world size 1 is assigned as DP rank 0, PP rank 0, TP rank 0
INFO 08-08 05:20:12 [cuda.py:221] Using Flash Attention backend on V1 engine.
INFO 08-08 05:20:12 [gpu_model_runner.py:1276] Starting to load model /mnt/models...
INFO 08-08 05:20:12 [topk_topp_sampler.py:59] Using FlashInfer for top-p & top-k sampling.
Loading safetensors checkpoint shards: 0% Completed | 0/4 [00:00<?, ?it/s]
Loading safetensors checkpoint shards: 25% Completed | 1/4 [01:40<05:01, 100.38s/it]
Loading safetensors checkpoint shards: 50% Completed | 2/4 [03:21<03:21, 100.87s/it]
Loading safetensors checkpoint shards: 75% Completed | 3/4 [05:03<01:41, 101.18s/it]
Loading safetensors checkpoint shards: 100% Completed | 4/4 [05:31<00:00, 72.57s/it]
Loading safetensors checkpoint shards: 100% Completed | 4/4 [05:31<00:00, 82.96s/it]
INFO 08-08 05:25:44 [loader.py:458] Loading weights took 331.88 seconds
INFO 08-08 05:25:44 [gpu_model_runner.py:1291] Model loading took 15.2512 GiB and 332.035054 seconds
INFO 08-08 05:25:54 [backends.py:416] Using cache directory: /home/vllm/.cache/vllm/torch_compile_cache/e0f741ac0f/rank_0_0 for vLLM's torch.compile
INFO 08-08 05:25:54 [backends.py:426] Dynamo bytecode transform time: 9.34 s
[rank0]:W0808 05:25:55.352000 85 torch/_inductor/utils.py:1137] [0/0] Not enough SMs to use max_autotune_gemm mode
INFO 08-08 05:25:56 [backends.py:132] Cache the graph of shape None for later use
INFO 08-08 05:26:22 [backends.py:144] Compiling a graph for general shape takes 28.01 s
INFO 08-08 05:26:36 [monitor.py:33] torch.compile takes 37.35 s in total
INFO 08-08 05:26:37 [kv_cache_utils.py:634] GPU KV cache size: 25,168 tokens
INFO 08-08 05:26:37 [kv_cache_utils.py:637] Maximum concurrency for 8,192 tokens per request: 3.07x
INFO 08-08 05:27:09 [gpu_model_runner.py:1626] Graph capturing finished in 32 secs, took 0.60 GiB
INFO 08-08 05:27:09 [core.py:163] init engine (profile, create kv cache, warmup model) took 85.06 seconds
INFO 08-08 05:27:09 [core_client.py:435] Core engine process 0 ready.
INFO 08-08 05:27:09 [api_server.py:1081] Starting vLLM API server on http://0.0.0.0:8080
INFO 08-08 05:27:09 [launcher.py:26] Available routes are:
INFO 08-08 05:27:09 [launcher.py:34] Route: /openapi.json, Methods: HEAD, GET
INFO 08-08 05:27:09 [launcher.py:34] Route: /docs, Methods: HEAD, GET
INFO 08-08 05:27:09 [launcher.py:34] Route: /docs/oauth2-redirect, Methods: HEAD, GET
INFO 08-08 05:27:09 [launcher.py:34] Route: /redoc, Methods: HEAD, GET
INFO 08-08 05:27:09 [launcher.py:34] Route: /health, Methods: GET
INFO 08-08 05:27:09 [launcher.py:34] Route: /load, Methods: GET
INFO 08-08 05:27:09 [launcher.py:34] Route: /ping, Methods: POST, GET
INFO 08-08 05:27:09 [launcher.py:34] Route: /tokenize, Methods: POST
INFO 08-08 05:27:09 [launcher.py:34] Route: /detokenize, Methods: POST
INFO 08-08 05:27:09 [launcher.py:34] Route: /v1/models, Methods: GET
INFO 08-08 05:27:09 [launcher.py:34] Route: /version, Methods: GET
INFO 08-08 05:27:09 [launcher.py:34] Route: /v1/chat/completions, Methods: POST
INFO 08-08 05:27:09 [launcher.py:34] Route: /v1/completions, Methods: POST
INFO 08-08 05:27:09 [launcher.py:34] Route: /v1/embeddings, Methods: POST
INFO 08-08 05:27:09 [launcher.py:34] Route: /pooling, Methods: POST
INFO 08-08 05:27:09 [launcher.py:34] Route: /score, Methods: POST
INFO 08-08 05:27:09 [launcher.py:34] Route: /v1/score, Methods: POST
INFO 08-08 05:27:09 [launcher.py:34] Route: /v1/audio/transcriptions, Methods: POST
INFO 08-08 05:27:09 [launcher.py:34] Route: /rerank, Methods: POST
INFO 08-08 05:27:09 [launcher.py:34] Route: /v1/rerank, Methods: POST
INFO 08-08 05:27:09 [launcher.py:34] Route: /v2/rerank, Methods: POST
INFO 08-08 05:27:09 [launcher.py:34] Route: /invocations, Methods: POST
INFO: Started server process [1]
INFO: Waiting for application startup.
INFO: Application startup complete.
INFO 08-08 05:27:20 [loggers.py:87] Engine 000: Avg prompt throughput: 0.0 tokens/s, Avg generation throughput: 0.0 tokens/s, Running: 0 reqs, Waiting: 0 reqs, GPU KV cache usage: 0.0%, Prefix cache hit rate: 0.0%
INFO 08-08 05:27:30 [loggers.py:87] Engine 000: Avg prompt throughput: 0.0 tokens/s, Avg generation throughput: 0.0 tokens/s, Running: 0 reqs, Waiting: 0 reqs, GPU KV cache usage: 0.0%, Prefix cache hit rate: 0.0%
INFO 08-08 05:27:40 [loggers.py:87] Engine 000: Avg prompt throughput: 0.0 tokens/s, Avg generation throughput: 0.0 tokens/s, Running: 0 reqs, Waiting: 0 reqs, GPU KV cache usage: 0.0%, Prefix cache hit rate: 0.0%
INFO 08-08 05:27:50 [loggers.py:87] Engine 000: Avg prompt throughput: 0.0 tokens/s, Avg generation throughput: 0.0 tokens/s, Running: 0 reqs, Waiting: 0 reqs, GPU KV cache usage: 0.0%, Prefix cache hit rate: 0.0%
INFO 08-08 05:28:00 [loggers.py:87] Engine 000: Avg prompt throughput: 0.0 tokens/s, Avg generation throughput: 0.0 tokens/s, Running: 0 reqs, Waiting: 0 reqs, GPU KV cache usage: 0.0%, Prefix cache hit rate: 0.0%
INFO 08-08 05:28:10 [loggers.py:87] Engine 000: Avg prompt throughput: 0.0 tokens/s, Avg generation throughput: 0.0 tokens/s, Running: 0 reqs, Waiting: 0 reqs, GPU KV cache usage: 0.0%, Prefix cache hit rate: 0.0%
INFO 08-08 05:28:20 [loggers.py:87] Engine 000: Avg prompt throughput: 0.0 tokens/s, Avg generation throughput: 0.0 tokens/s, Running: 0 reqs, Waiting: 0 reqs, GPU KV cache usage: 0.0%, Prefix cache hit rate: 0.0%
INFO 08-08 05:28:30 [loggers.py:87] Engine 000: Avg prompt throughput: 0.0 tokens/s, Avg generation throughput: 0.0 tokens/s, Running: 0 reqs, Waiting: 0 reqs, GPU KV cache usage: 0.0%, Prefix cache hit rate: 0.0%
OpenShift AI Webコンソール画面に戻ってステータスを確認すると、グリーンのチェックマーク✔に変わっていることがわかる。
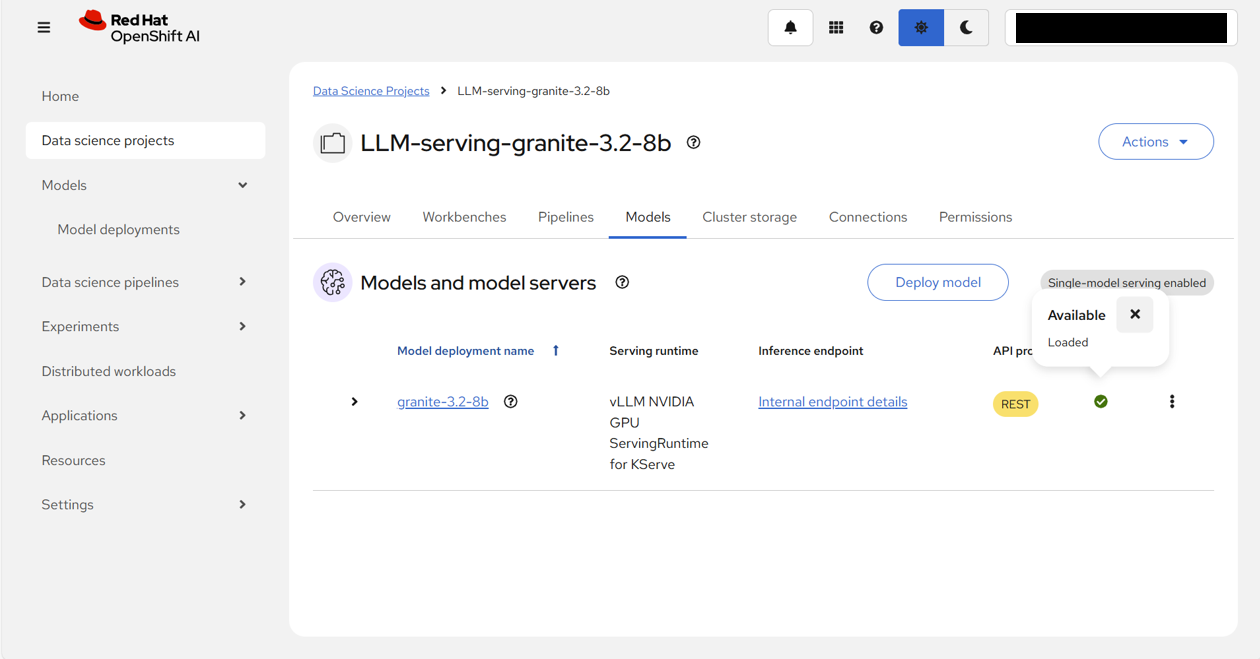
これで、LLMの起動が正常に完了した。